我們為您提供了通用模型,是語言基礎模型,如果您在自己的領域積累了豐富的歷史數據,可以使用這些歷史數據作為語料來對自定義的語言模型進行訓練,自定義的語言模型在訓練時,是在通用模型的基礎上進行訓練的,通過對您的訓練語料做模型訓練,可以有效提高您的特有場景的語音識別準確率,尤其是專有名詞和文本中的高頻詞匯,有較好的優化效果。
視頻講解
訓練語料要求及優化建議
語料要求
推薦您使用 業務介紹資料、產品介紹資料、話術資料、培訓資料、 模型效果評測 中進行人工校驗產出的標注結果 作為訓練使用的語料,對于語料文件具體的要求如下:
訓練數據為領域相關的文本,與待識別語音數據越接近,優化效果越好。
以文本文件方式保存,使用UTF-8編碼,無BOM頭;語料文件大小在1MB-20MB,文本過少可能導致訓練失敗,過多會導致超限。
一句話或者一個被加強調優的關鍵詞單獨一行,控制每行的長度在500個字符以內(不是字節)。
文本中的數字最好按照發音替換為對應的漢字。例如:“58.9元”需要轉換為“五十八點九元”。
文件中需要至少有一行為句子(大于4個詞)。
只采用逗號‘,’、句號‘。’、問號‘?’和感嘆號‘!’,句尾需要加標點。像書名號‘《’、‘》’,雙引號‘“’、‘”’等標點應去除。
優化建議
對于識別不準確的關鍵詞,可以將帶這個詞的句子或者關鍵詞(一個關鍵詞在訓練文本中獨占一行)多拷貝幾行,例如10行。如果沒有效果,可以再適當增加拷貝行數。
注意:
需要先確定關鍵詞識別不準確的原因不是因為本身說的不清晰或者個別音頻質量不好。
不要拷貝太多導致影響其他詞識別或者整體識別率,這個只有在實際業務中嘗試后總結經驗。
操作流程
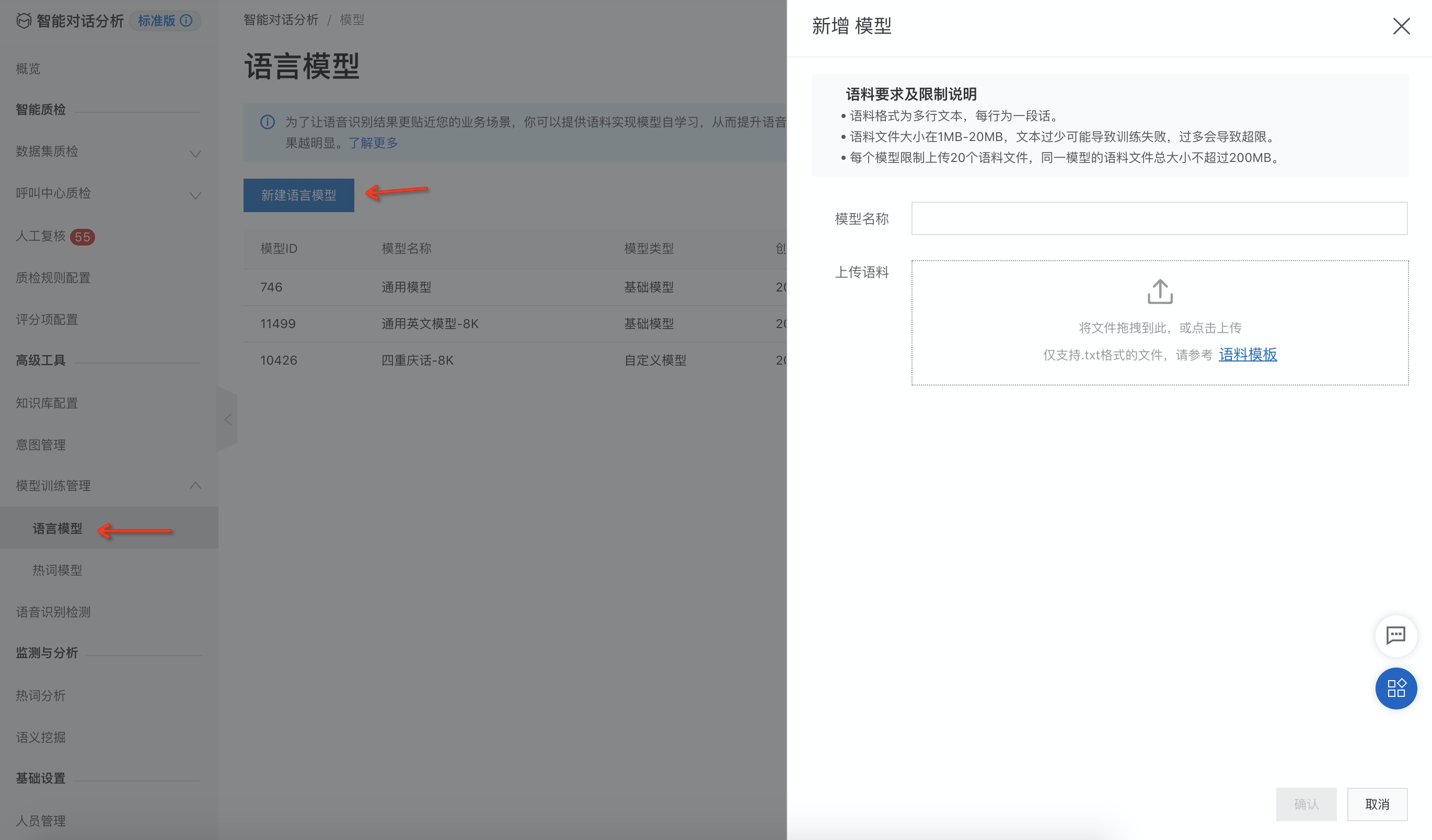
新建自定義語言模型
如下圖所示,按照圖片上標注的步驟進行操作;
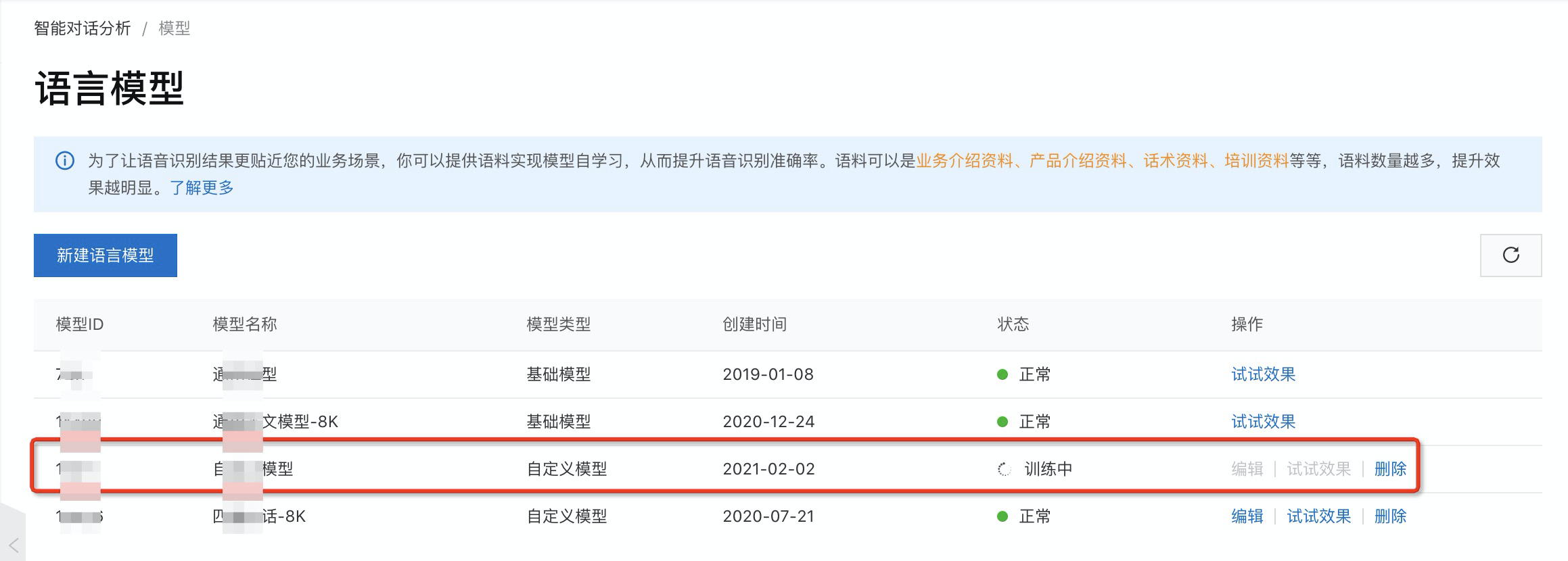
新建成功后,在語言模型列表可以看到,剛剛新建的自定義語言模型已經處于訓練中了;
優化現有的自定義語言模型
通過模型編輯,您可以補充語料進行再次訓練,也可以刪除已經上傳的語料。通用模型不可編輯。
點擊語言模型列表最右側的 編輯 按鈕;
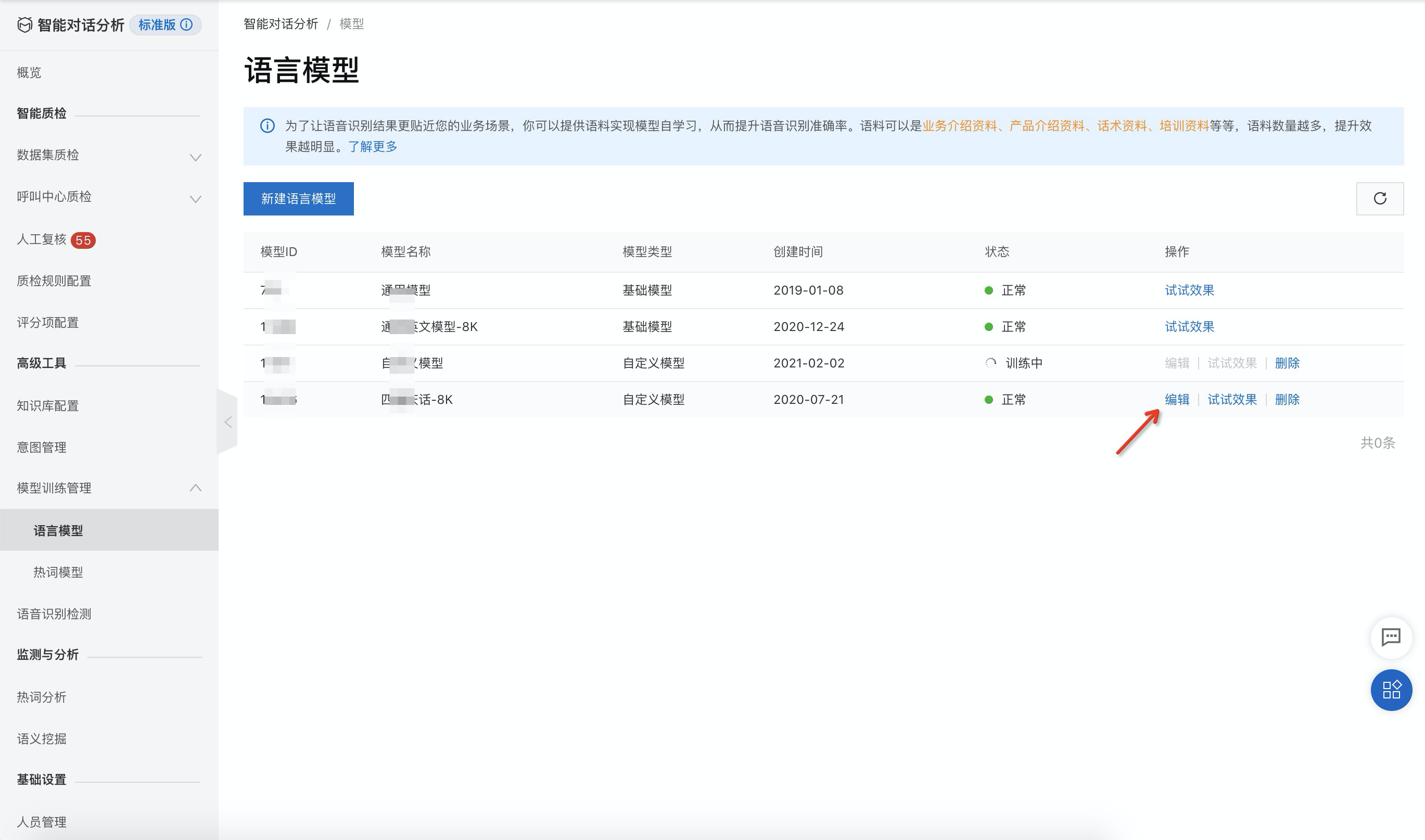
與新建語言模型類似,上傳或刪除語料后提交,該模型將會開始訓練;
試試效果
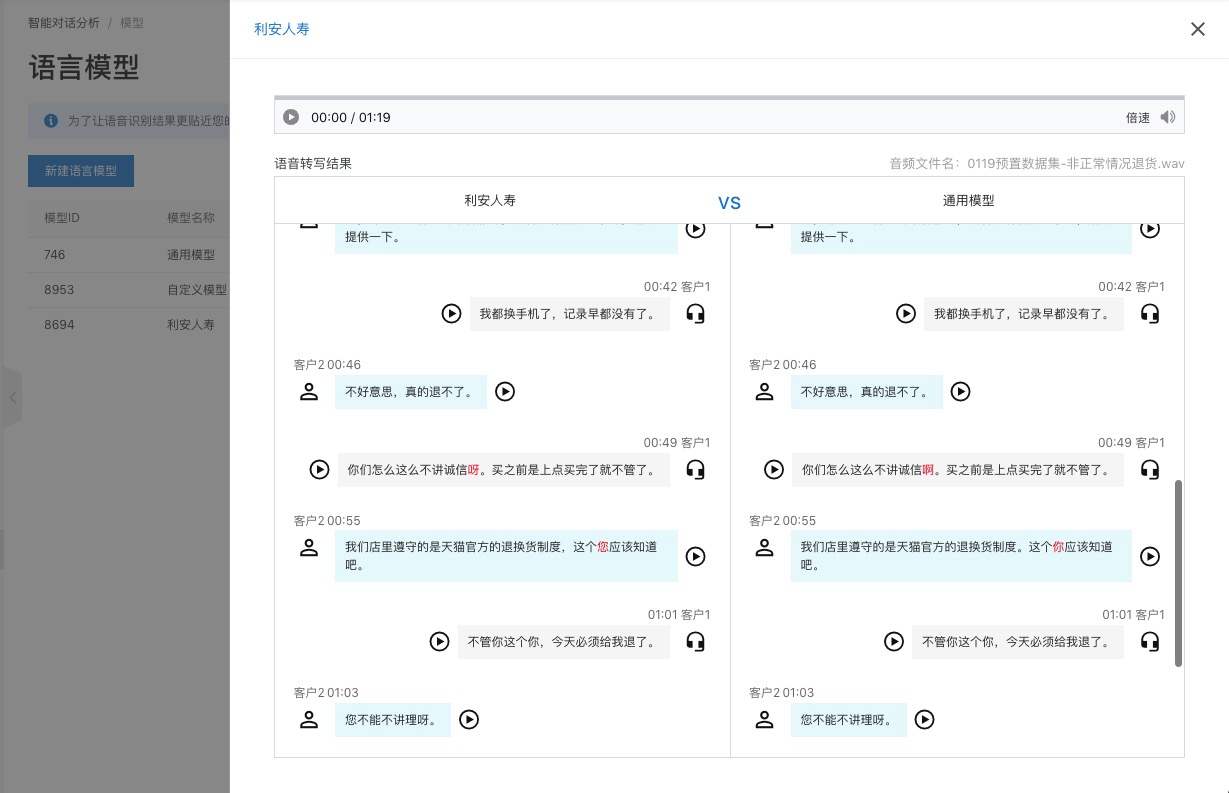
試試效果功能,是使用指定的語言模型對已經上傳的數據集中的文件進行語音轉文字。對于通用模型,試試效果只能查看通用模型自己的轉寫結果,對于自定義模型,可以查看自定義模型與通用模型兩個模型的轉寫結果,可以直觀的看到兩個模型轉寫結果之間的差異,我們以自定義模型來舉例說明
點擊語言模型列表最右側的 試試效果 按鈕;
選擇一個數據集,然后點擊 開始音頻轉寫;
轉寫完成后,對于兩個模型轉寫有差異的部分,會高亮顯示,如下圖: