基于Tair與LLM構(gòu)建企業(yè)專屬Chatbot
本文介紹基于Tair(企業(yè)版)與大語言模型(Large Language Model, LLM)構(gòu)建企業(yè)專屬Chatbot的解決方案。
背景信息
大語言模型已具備了相當(dāng)豐富的基礎(chǔ)知識(shí)、閱讀理解和邏輯推理能力。但想在實(shí)際使用過程中充分發(fā)揮它的潛力,仍需提供額外的信息進(jìn)行輔助,原因如下:
不了解私域數(shù)據(jù):盡管大語言模型已通過大量訓(xùn)練樣本,但無法保證其已學(xué)習(xí)、掌握指定的私域數(shù)據(jù)或新知識(shí)。
不具備多輪對(duì)話能力:大語言模型能夠接收的請(qǐng)求大小(即Token數(shù))是有限制的,通常是4 KB~32 KB之間,并且響應(yīng)速度隨著請(qǐng)求變大而變慢。以ChatGLM為例,將用戶的歷史記錄作為請(qǐng)求的一部分持續(xù)追加,當(dāng)超過Token數(shù)限制時(shí)就需要丟棄老的聊天記錄,無法實(shí)現(xiàn)長(zhǎng)期、多輪對(duì)話能力。
因此,可以使用Tair(企業(yè)版)作為大語言模型的外部存儲(chǔ),將私域數(shù)據(jù)和長(zhǎng)期對(duì)話記錄存儲(chǔ)在Tair向量檢索中,結(jié)合Tair高效的向量檢索能力與大語言模型的AI能力,使企業(yè)專屬Chatbot更加智能。
Tair特性與優(yōu)勢(shì)
Tair向量檢索是在Tair(企業(yè)版)的基礎(chǔ)上,以內(nèi)置引擎的方式,為用戶提供實(shí)時(shí)高性能、多模混合檢索、簡(jiǎn)單易用的向量數(shù)據(jù)庫(kù)服務(wù)。
實(shí)時(shí)高性能:所有操作均在內(nèi)存中進(jìn)行,支持FLAT、HNSW索引算法,支持歐式距離、向量?jī)?nèi)積、余弦距離等多種距離函數(shù),索引創(chuàng)建與向量數(shù)據(jù)點(diǎn)查詢的時(shí)延均小于1ms,更多信息請(qǐng)參見TairVector性能白皮書。
多模混合檢索:完全兼容Redis生態(tài)與使用方式,同時(shí)還支持向量檢索、全文檢索及其他多種擴(kuò)展數(shù)據(jù)結(jié)構(gòu),更多信息請(qǐng)參見Tair擴(kuò)展數(shù)據(jù)結(jié)構(gòu)概覽。
簡(jiǎn)單易用:1 GB規(guī)格(低成本)起步,支持在線擴(kuò)、縮容,最高可擴(kuò)容至16 TB集群。
應(yīng)用場(chǎng)景
私域數(shù)據(jù)問答
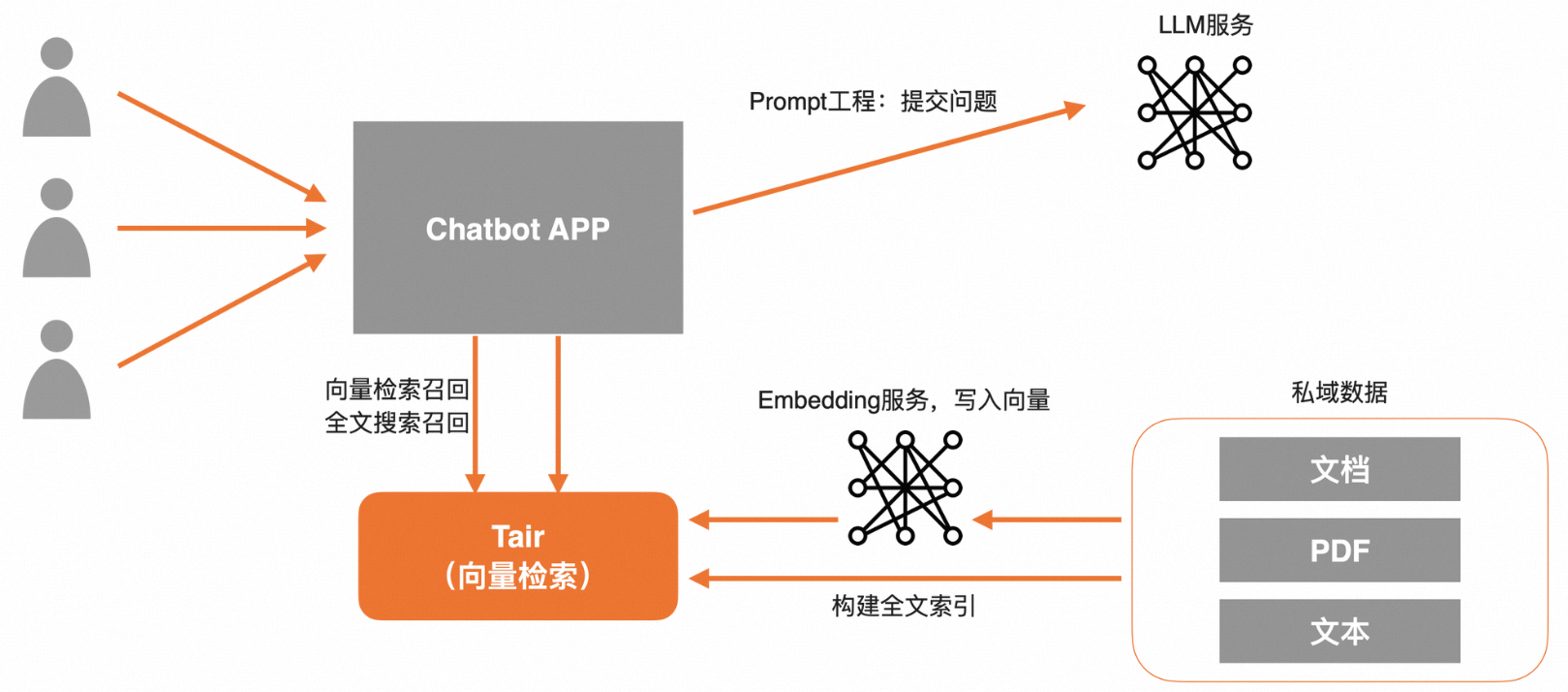
提前將私域數(shù)據(jù)寫入Tair向量中,同時(shí)也可以在Tair中構(gòu)建一份全文索引。在請(qǐng)求LLM前,Tair支持提供向量檢索和全文檢索兩路召回,再通過Prompt潤(rùn)色,一并將問題與私域數(shù)據(jù)提交給LLM,可實(shí)現(xiàn)企業(yè)專屬Chatbot定制。
長(zhǎng)Session會(huì)話
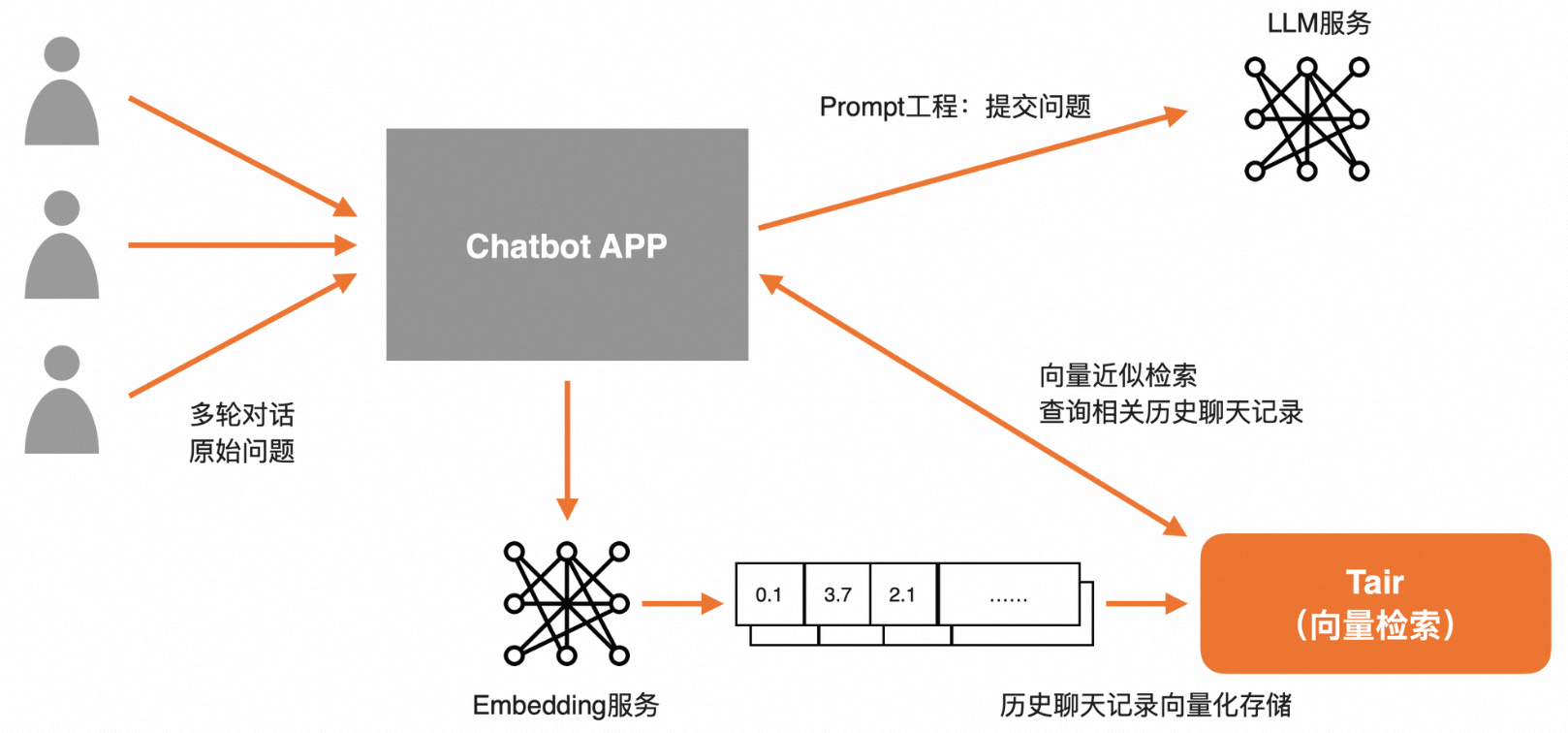
將用戶的歷史會(huì)話記錄存儲(chǔ)在Session中(支持設(shè)置TTL等過期機(jī)制)。在請(qǐng)求LLM前,通過Tair向量檢索技術(shù)將相關(guān)歷史信息檢索出來,再通過Prompt潤(rùn)色后,一并提交給LLM,可實(shí)現(xiàn)基于長(zhǎng)期、多輪對(duì)話下的上下文感知能力。
快速體驗(yàn)
在阿里云云速搭CADT平臺(tái)中已上線大模型結(jié)合Tair構(gòu)建企業(yè)級(jí)專屬Chatbot解決方案。
該方案模板中已預(yù)部署ECS和Tair實(shí)例,預(yù)安裝了前置安裝包,Demo中已實(shí)現(xiàn)了私域數(shù)據(jù)問答、長(zhǎng)Session會(huì)話功能,您可以結(jié)合教程快速體驗(yàn)專屬Chatbot,更多信息請(qǐng)參見大模型結(jié)合Tair構(gòu)建企業(yè)級(jí)專屬Chatbot。
代碼說明
本項(xiàng)目來自于開源項(xiàng)目langchain-ChatGLM,其中向量數(shù)據(jù)庫(kù)使用Tair、模型為ChatGLM-6B,請(qǐng)自覺遵守相關(guān)協(xié)議及法律法規(guī)等。
如下圖所示,灰色箭頭表示文本(TXT)文件經(jīng)過一系列處理,把向量信息以及切分后的原始文本一起寫入到Tair中。橙色箭頭表示在用戶發(fā)起一個(gè)查詢后,先從Tair中檢索出最相似的TopK個(gè)向量,然后與用戶問題進(jìn)行Prompt,一并提交給LLM,讓LLM更好地回答用戶的問題。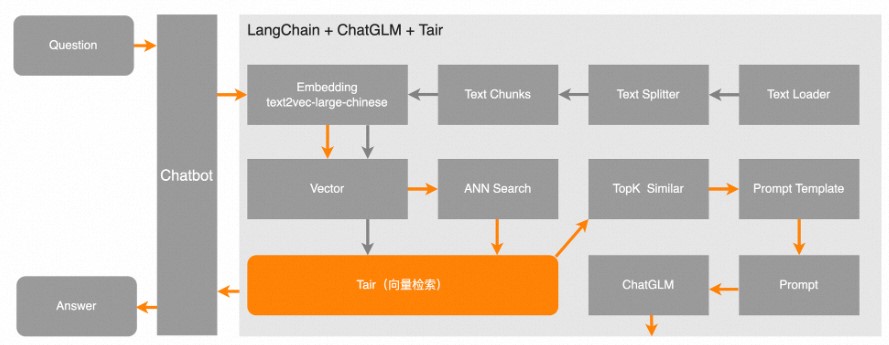
以下代碼僅說明Tair與大語言模型結(jié)合的部分,具體Demo運(yùn)行,請(qǐng)參見快速體驗(yàn)章節(jié)。
# -*- coding: utf-8 -*-
# !/usr/bin/env python
import torch
from langchain.document_loaders import TextLoader
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from transformers import AutoTokenizer, AutoModel
from langchain.vectorstores import Tair
from utils import ChineseTextSplitter
from langchain.schema import Document
from typing import List
from tair import Tair as TairClient
TOPK = 2
EMBEDDING_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
PROMPT_TEMPLATE =
"""
已知信息:
{context}
根據(jù)上述已知信息,簡(jiǎn)潔回答用戶的問題。如果無法從中得到答案,請(qǐng)說 “根據(jù)已知信息無法回答該問題” 或 “沒有提供足夠的相關(guān)信息”,答案請(qǐng)使用中文。 問題是:{question}
"""
PROMPT_TEMPLATE_SESSION =
"""
已知用戶以前提供的問題:
{context}
根據(jù)上述已知信息,簡(jiǎn)潔回答用戶問題。如果無法從中得到答案,請(qǐng)自行回答用戶問題,答案請(qǐng)使用中文。 問題是:{question}
"""
class ChatBot():
"""
使用開源模型,請(qǐng)遵循相關(guān)協(xié)議及法律法規(guī)。參數(shù)說明:
tair_url: Tair的連接地址,例如"redis://account_name:account_password@r-bp10xx****.redis.rds.aliyuncs.com:6379"。
GanymedeNil/text2vec-large-chinese:需下載"https://huggingface.co/GanymedeNil/text2vec-large-chinese",并替換為本地目錄。
THUDM/chatglm-6b:需下載"https://huggingface.co/THUDM/chatglm-6b",并替換為本地目錄。
"""
def __init__(self, tair_url):
self.tair_url = tair_url
self.text_embeddings_model= HuggingFaceEmbeddings(model_name='GanymedeNil/text2vec-large-chinese',
model_kwargs={'device': EMBEDDING_DEVICE})
self.tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
self.llm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
self.tair_session_client = TairClient.from_url(tair_url)
"""
該代碼示例的私域數(shù)據(jù)存儲(chǔ)langchain的index中。
"""
def get_langchain_tair(self, index_name="langchain"):
return Tair(self.text_embeddings_model, self.tair_url, index_name)
"""
結(jié)合EXPIRE可以給某個(gè)index設(shè)置過期時(shí)間。
"""
def expire_index(self, index_name):
return self.tair_session_client.expire(index_name, 1200)
"""
判斷不存在某個(gè)index,不存在返回True, 存在返回False。
"""
def not_exists_index(self, session_id):
index = self.tair_session_client.tvs_get_index(session_id)
if index is not None:
return False
return True
"""
與大模型交互接口,該代碼示例的history為空,LLM中對(duì)history的處理,請(qǐng)參考"https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/webui.py"。
"""
def chat(self, question:str):
response, history = self.llm_model.chat(self.tokenizer, question, history=[])
return response
"""
寫入私域數(shù)據(jù),該方法需輸入文件路徑。
ChineseTextSplitter請(qǐng)參考"https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/textsplitter/chinese_text_splitter.py"。
"""
def insert_text(self,filepath:str):
loader = TextLoader(filepath, autodetect_encoding=True)
textsplitter = ChineseTextSplitter(pdf=False, sentence_size=100)
docs= loader.load_and_split(textsplitter)
self.insert_text_to_tair(docs,filepath)
"""
Tair.from_documents具體實(shí)現(xiàn),請(qǐng)參考"https://github.com/langchain-ai/langchain/blob/master/libs/community/langchain_community/vectorstores/tair.py"。
最終也是調(diào)用Tair的TVS.HSET接口寫入向量與標(biāo)量。
"""
def insert_text_to_tair(self,docs:List[Document]=None,filename:str=""):
Tair.from_documents(docs, self.text_embeddings_model, tair_url=self.tair_url)
"""
結(jié)合私域數(shù)據(jù),做prompt提交給大模型。
"""
def chat_by_prompt(self,query:str,topk:int=TOPK):
context = self.get_langchain_tair().similarity_search(query, k=topk)
context = "\n".join([doc.page_content for doc in context])
prompt = PROMPT_TEMPLATE.replace("{question}", query).replace("{context}", context)
response = self.chat(prompt)
return response
"""
獲取用戶歷史會(huì)話Session,根據(jù)用戶的歷史提示回答問題。
"""
def get_prompt_by_tair_session(self, query, session_id):
if self.not_exists_index(session_id):
prompt = query
return prompt
related_docs_with_score = self.get_langchain_tair(session_id).similarity_search(query, k=self.top_k)
if len(related_docs_with_score)>0:
context = "\n".join([doc.page_content for doc in related_docs_with_score])
prompt = PROMPT_TEMPLATE_SESSION.replace("{question}", query).replace("{context}", context)
else:
prompt = query
return prompt
"""
將用戶歷史回答寫入Session。關(guān)于Session如何存儲(chǔ)仍需不斷探索,您可以根據(jù)自己的需求進(jìn)行定制化開發(fā)。
"""
def insert_tair_session(self, query, resp, session_id):
text = f"{query}"
Tair.from_texts([text], self.embeddings, None, session_id, "content", "metadata", tair_url=self.insert_tair_session, index_type="FLAT")
self.expire_index(session_id)效果展示
私域數(shù)據(jù)問答
下圖展示了上傳私域數(shù)據(jù),回答私域數(shù)據(jù)問題的示例。
長(zhǎng)Session會(huì)話
下圖展示了根據(jù)用戶已提供的信息,回答用戶問題的示例。