本文介紹基于Tair向量檢索(Vector)實現條件過濾、向量檢索、全文檢索融合的混合檢索方案。
背景信息
大語言模型(Large Language Model, LLM)的發展使得文本、圖片、音視頻等非結構化數據都可以通過向量來表示其語義信息,基于向量的KNN檢索在語義搜索、商品推薦、智能問答等領域有非常大的潛力。當前大多數產品通常僅支持經典的條件過濾、全文索引、向量檢索這三類檢索方案的一種或者兩種組合,這三種檢索方案的優缺點非常明顯:
條件過濾:基于多種布爾條件組合過濾,對數據集和使用方式有嚴格的約束,限制了用戶使用場景。
全文檢索:針對用戶通用查詢Query,通過分詞并計算文檔相關度,返回相關性最高的結果列表。一般限于文本類字段的查詢,且難以處理用戶輸入錯誤等語法問題。
向量檢索:首先進行語義編碼,通過計算向量之間相關度,返回相關性最高的結果列表。可以處理文檔、圖片、音視頻等各類非結構化數據,極大拓展了應用場景,不過也存在高度依賴LLM的效果、對私域數據處理不準確等問題。
基于Tair向量檢索可以在數據不出庫情況下實現條件過濾、全文檢索、向量檢索三類檢索方案的任意組合。您僅需通過一條查詢語句即可實現三路結果召回,例如通過待檢索的圖片、文本、音視頻等文件進行向量檢索召回、通過輸入的文本進行全文檢索召回、通過布爾表達式進行條件過濾召回等,Tair向量檢索還會對三路召回結果進行權重排序,返回最終的候選列表。
通過多路召回,可以避免因僅使用一種檢索方案而受到單檢索方案的能力限制,通過多種數據資源提高檢索命中率。同時也支持針對特定的請求,通過hybrid_ratio參數調整不同檢索方式的權重,更多信息請參見Vector。
方案概述
本示例將使用fashion-product-images-small開源數據集演示不同檢索方案的效果。
請自覺遵守開源數據集的相關協議及法律法規等。
數據說明
該數據集包含4.4萬條商品數據,數據格式如下:
id (int64) | gender (string) | masterCategory (string) | subCategory (string) | articleType (string) | baseColour (string) | season (string) | year (float64) | usage (string) | productDisplayName (string) | image (dict) |
15,970 | "Men" | "Apparel" | "Topwear" | "Shirts" | "Navy Blue" | "Fall" | 2,011 | "Casual" | "Turtle Check Men Navy Blue Shirt" | { "bytes": [ 255, 216, 255, ... ], "path": null } |
39,386 | "Men" | "Apparel" | "Bottomwear" | "Jeans" | "Blue" | "Summer" | 2,012 | "Casual" | "Peter England Men Party Blue Jeans" | { "bytes": [ 255, 216, 255, ...], "path": null } |
59,263 | "Women" | "Accessories" | "Watches" | "Watches" | "Silver" | "Winter" | 2,016 | "Casual" | "Titan Women Silver Watch" | { "bytes": [ 255, 216, 255, ...], "path": null } |
數據轉換方案
Tair向量檢索是簡單直觀的Tair向量索引Key-Key-(Key-Value)存儲結構,首先需要創建一個向量索引(例如hybrid_index),用于存儲所有商品數據。再對上述表數據結構進行轉換,按照字段可以分為四類:
id:作為Tair向量檢索中的主鍵,可通過該字段可以實現點查操作(只掃描少量數據的查詢操作)。
image:通過LLM編碼后作為Tair向量檢索的向量信息,通過該向量信息可以實現向量檢索。
productDisplayName:該字段為image的描述信息,可作為Tair向量檢索中的Text文本信息。通過該字段可以實現全文檢索。
其他列:作為Tair向量檢索的最子級鍵值對,沒有限制數量。通過該鍵值對可以實現傳統的屬性過濾檢索。
Tair向量檢索存儲的數據結構示例如下: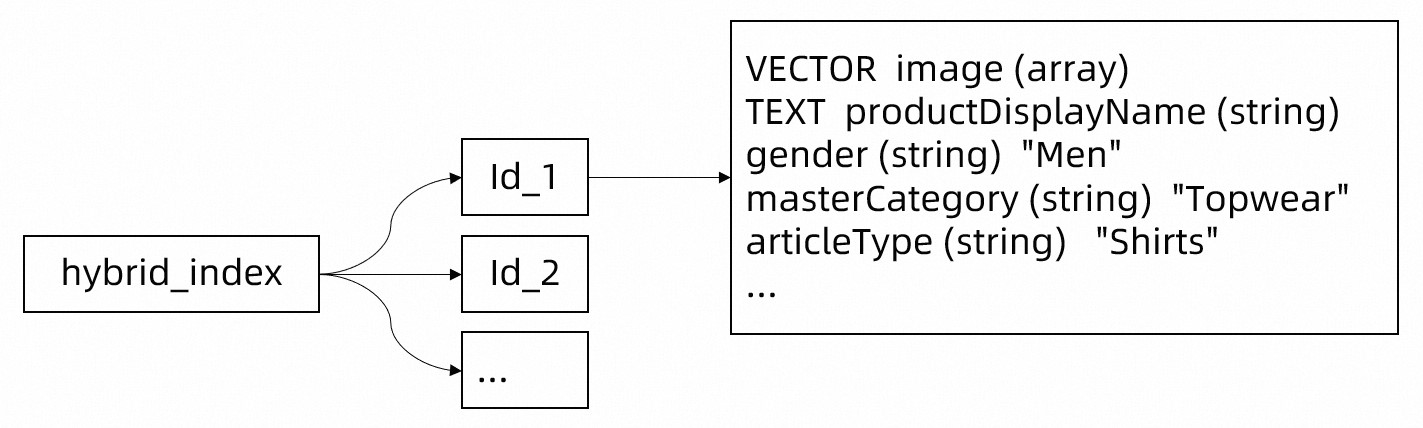
整體流程與示例代碼
本示例的整體流程為:
加載數據集。
Tair環境準備。
導入數據集至Tair。
以不同檢索方案進行查詢。
詳情請參見Hybrid search代碼工程。
該代碼文件為.ipynb文件,使用前需提前執行pip install jupyter命令,安裝相關依賴。
查詢展示
以下代碼僅展示以不同的檢索方案進行查詢與對應效果。以查詢Green Kidswear為例,通過調整hybrid_ratio參數(hybrid_ratio參數為向量檢索的權重,全文檢索的權重為1-hybrid_ratio),分別測試下面四種場景:
純向量檢索:將hybrid_ratio參數設置為0.9999,查詢示例如下。
topk = 20 text = "Green Kidswear" vector = model.encode([text])[0] filter_str = None kwargs = {"TEXT" : text, "hybrid_ratio" : 0.9999} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)執行結果:

純全文檢索:將hybrid_ratio參數設置為0.0001,查詢示例如下。
topk = 20 text = ""Green Kidswear" vector = model.encode([text])[0] filter_str = None kwargs = {"TEXT" : text, "hybrid_ratio" : 0.0001} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)執行結果:
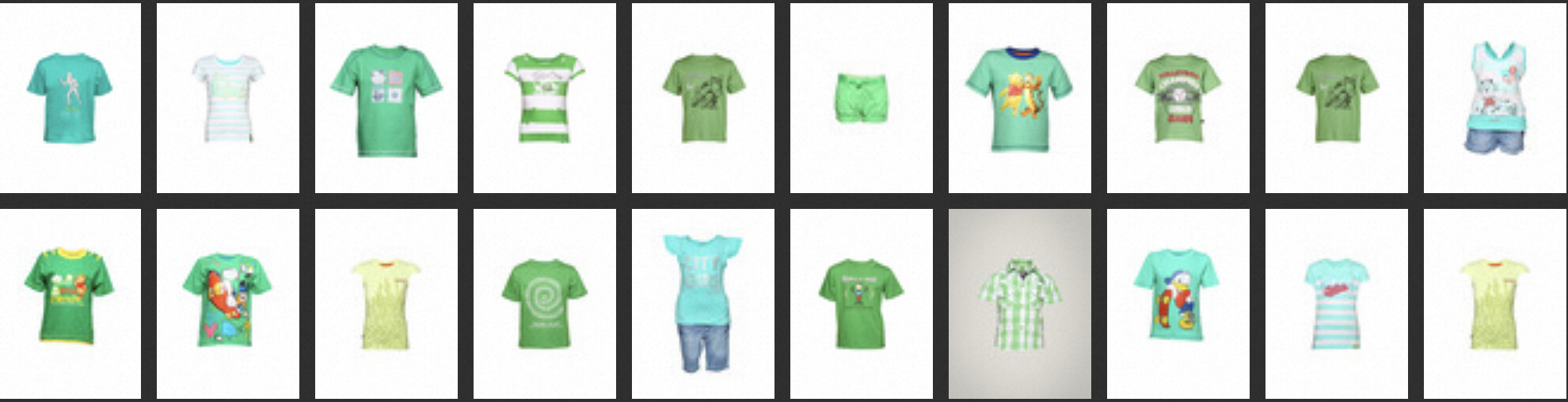
向量、全文混合檢索:將hybrid_ratio參數設置為0.5,查詢示例如下。
topk = 20 text = ""Green Kidswear" vector = model.encode([text])[0] filter_str = None kwargs = {"TEXT" : text, "hybrid_ratio" : 0.5} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)執行結果:

向量、全文、條件過濾混合檢索:將hybrid_ratio參數設置為0.5,同時添加
subCategory == "Topwear"的條件語句,查詢示例如下。topk = 20 text = "Green Kidswear" vector = model.encode([text])[0] filter_str = "subCategory == \"Topwear\"" kwargs = {"TEXT" : text, "hybrid_ratio" : 0.5} result = client.tvs_knnsearch(index_name, topk, vector, False, filter_str, **kwargs) print(result) top_img = [images[id_pos[int(item[0])]] for item in result] display_result(top_img)執行結果:

總結
直觀上看,無論是向量檢索還是全文檢索,整體都比較符合查詢需求。在排名最高的候選集中,全文檢索體驗要略微好于向量檢索。
在混合檢索中,若某一個目標存在于兩個召回結果中,則其最終排名會更加靠前。
通過調整hybrid_ratio參數,可以動態對向量檢索和全文檢索各自召回的結果進行Rerank(重排),以得到更精準的結果。
可以通過條件過濾的方式進一步過濾掉特定的候選集,提高檢索命中率。