TairVector是基于Tair(企業版)的向量存儲引擎,集存儲、檢索于一體,提供高性能、實時的向量數據庫服務。本文介紹了TairVector的性能測試方法和測試結果。
TairVector支持高性能的向量近似最近鄰(ANN)檢索,可用于非結構化數據的語義檢索、個性化推薦等場景,更多信息請參見Vector。
測試說明
數據庫測試環境
測試環境信息 | 說明 |
地域和可用區 | 華北3(張家口)地域,可用區A。 |
存儲介質 | 內存型(兼容Redis 6.0)。 |
實例版本 | 6.2.8.2 |
實例架構 | 標準版(雙副本)架構,不啟用集群,詳情請參見標準架構。 |
實例規格 | 由于測試結果受規格影響較小,本次測試以16 GB(tair.rdb.16g)規格為例。 |
客戶端測試環境
與實例為同專有網絡(VPC)的ECS實例,且與實例通過專有網絡連接。
Linux操作系統。
已安裝Python 3.7及以上版本。
測試數據
本文使用Sift-128-euclidean、Gist-960-euclidean、Glove-200-angular和Deep-image-96-angular數據集測試HNSW索引,使用Random-s-100-euclidean和Mnist-784-euclidean數據集測試FLAT索引。
數據集名稱 | 數據集介紹 | 向量維度 | 向量總數 | 查詢數量 | 數據總量 | 距離類型 |
該數據集是基于Texmex的數據集整理,使用SIFT算法得到的圖片特征向量。 | 128 | 1,000,000 | 10,000 | 488 MB | L2 | |
該數據集是基于Texmex的數據集整理,使用GIST算法得到的圖片特征向量。 | 960 | 1,000,000 | 1,000 | 3.57 GB | L2 | |
該數據集是互聯網文本數據使用GloVe算法得到的單詞向量。 | 200 | 1,183,514 | 10,000 | 902 MB | COSINE | |
該數據集是ImageNet圖片經過GoogLeNet模型訓練,從最后一層神經網絡提取的向量。 | 96 | 9,990,000 | 10,000 | 3.57 GB | COSINE | |
Random-s-100-euclidean | 該數據集為測試工具隨機生成,不提供下載鏈接。 | 100 | 90,000 | 10,000 | 34 MB | L2 |
該數據集來自于MNIST手寫失敗數據集。 | 784 | 60,000 | 10,000 | 179 MB | L2 |
測試工具與測試方法
在測試服務器上,安裝
tair-py和hiredis。安裝方式:
pip install tair hiredis下載、安裝Ann-benchmarks并解壓。
解壓命令如下:
tar -zxvf ann-benchmarks.tar.gz將Tair實例的連接地址、端口號和賬號密碼配置到
algos.yaml文件中。打開
algos.yaml文件,搜索tairvector找到對應配置項,修改base-args參數項,參數說明如下:url:Tair實例的連接地址及賬號密碼,格式為
redis://user:password@host:port。
parallelism:多線程的并發數,默認為4,建議使用默認值。
示例如下:
{"url": "redis://testaccount:Rp829dlwa@r-bp18uownec8it5****.redis.rds.aliyuncs.com:6379", "parallelism": 4}執行
run.py,啟動完整的測試流程。重要run.py腳本會執行整個測試流程,包括建索引、寫入數據、查詢以及記錄結果等操作,請勿對單個數據集重復執行。示例如下:
# 多線程測試Sift數據集(HNSW索引)。 python run.py --local --runs 3 --algorithm tairvector-hnsw --dataset sift-128-euclidean --batch # 多線程測試Mnist數據集(FLAT索引)。 python run.py --local --runs 3 --algorithm tairvector-flat --dataset mnist-784-euclidean --batch您也可以通過自帶的Web前端執行測試,示例如下:
# 需提前安裝Streamlit依賴。 pip3 install streamlit # 啟動Web前端,啟動后可以在瀏覽器中打開"http://localhost:8501"。 streamlit run webrunner.py執行
data_export.py,導出結果。示例如下:
# 多線程 python data_export.py --output out.csv --batch
測試結果
重點關注寫入性能、KNN查詢性能和內存效率方面的測試結果:
寫入性能:關注吞吐率,吞吐率越高,性能越好。
KNN查詢性能:關注QPS和召回率,QPS反映系統性能,召回率反映結果的準確性。通常召回率越高,相應的QPS也越低。在相同召回率下比較QPS才有參考意義,因此測試結果以“QPS-召回率”曲線的形式展示。對于FLAT索引,由于召回率始終為1,因此只展示QPS。
內存效率:關注向量索引占用內存的情況,內存占用越低越好。
寫入和KNN查詢測試均為4線程并發。
本次分別測試了FLOAT32(默認數據類型)和FLOAT16數據類型的性能。對于HNSW索引,還測試了開啟AUTO_GC功能下的性能表現。
HNSW索引
寫入性能
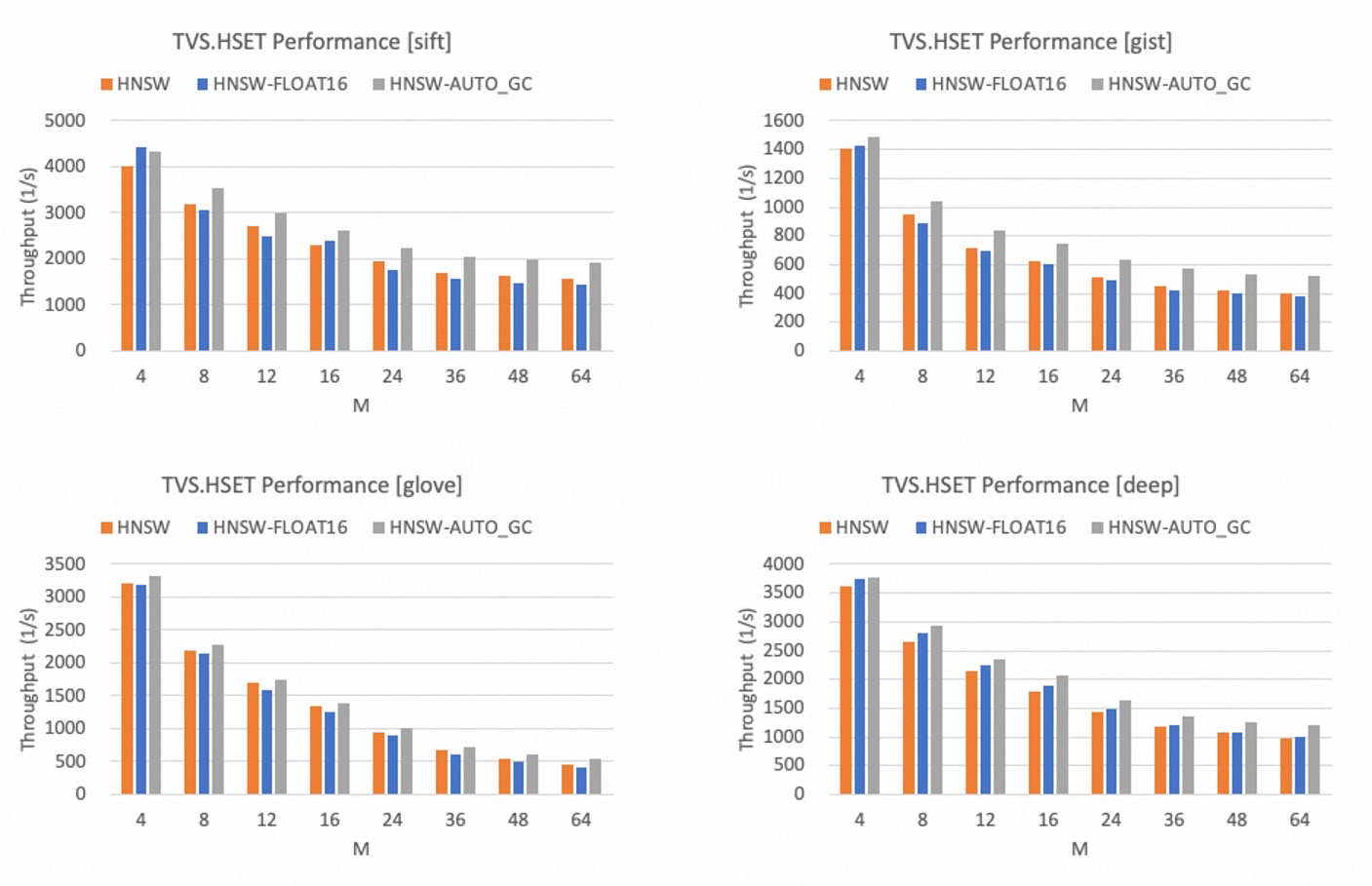
以下為ef_construct = 500時,不同M參數取值下的寫入性能,可以得出:
M值越大,HNSW索引的寫入性能越差。
相比較FLOAT32,FLOAT16數據類型的寫入性能在多數情況下會有所下降,但是下降幅度不大,二者表現非常接近。
開啟AUTO_GC功能后,寫入性能會存在一定幅度提升,提升幅度最大可達30%。
KNN查詢性能
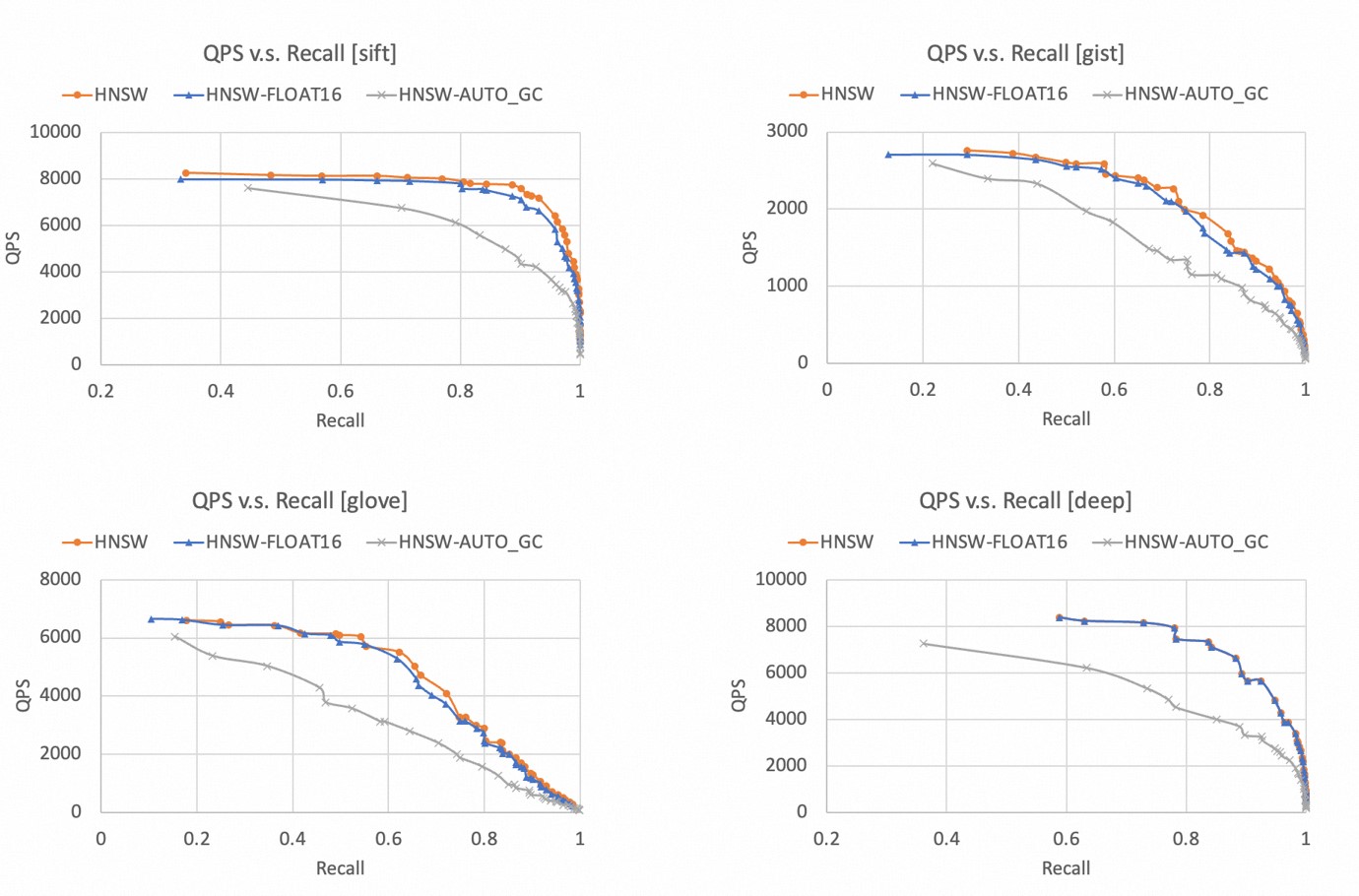
召回率和QPS都是越高越好,因此曲線越靠近右上角,代表算法表現越好。
以下為不同數據集下,TairVector HNSW索引的“QPS-召回率”曲線,可以得出:
在4個數據集下,HNSW索引都可以達到99%以上的召回率。
相比較FLOAT32,FLOAT16數據類型的性能略有下降,但是幅度不大,二者表現非常接近。
開啟AUTO_GC功能后,查詢性能會明顯下降,因此建議您僅在需要刪除大量數據的場景下開啟AUTO_GC功能。
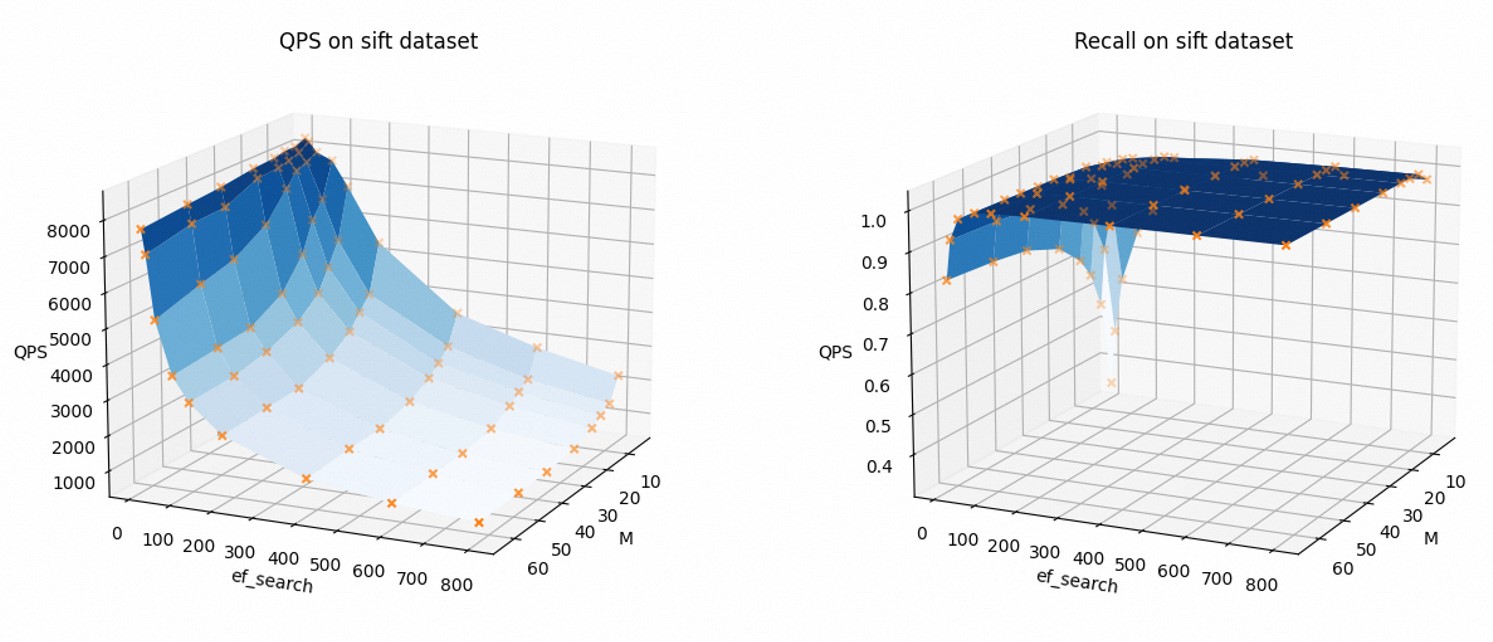
為了直觀地展示索引參數如何影響查詢性能,以下為以Sift數據集為例(FLOAT32,不開啟AUTO_GC),QPS和召回率隨著參數M和ef_search的變化趨勢。
可以看到,隨著M和ef_search的增加,QPS下降,召回率上升。
您在使用過程中可以根據需求調整索引參數,平衡查詢性能與召回率。
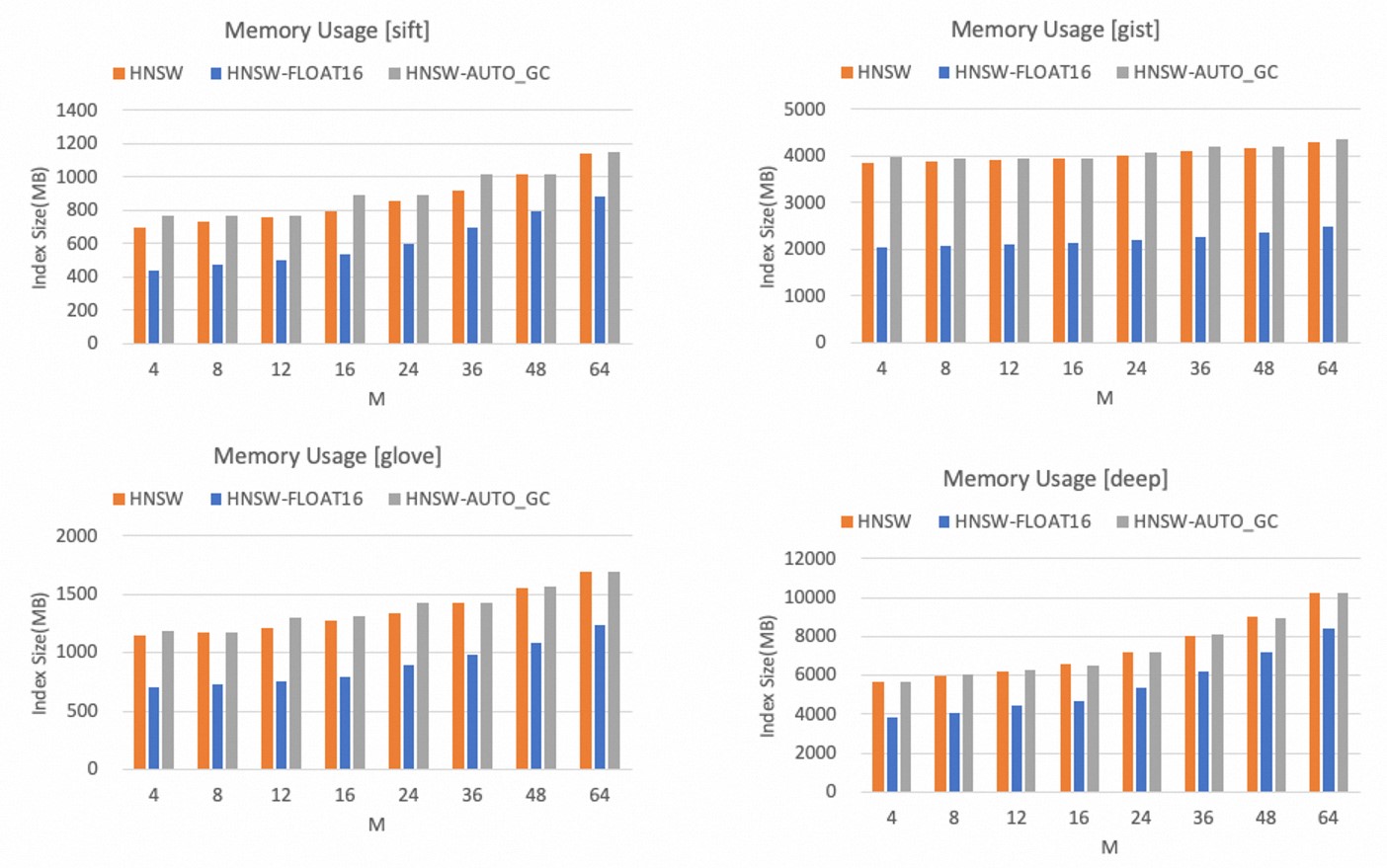
內存效率
HNSW索引的內存使用量只受參數M的影響,M值越大,HNSW索引的內存占用越大。
以下為不同數據集下,TairVector HNSW索引的內存占用量,可以得出:
相比較FLOAT32,FLOAT16數據類型可以顯著減少內存占用量,最大可以減少40%以上。
開啟AUTO_GC功能后,內存占用量有小幅上升,但是幅度不大。
說明您在使用過程中可以根據向量數據維度和內存容量預算選擇合適的M值。同時如果可以接受一定的精度損失,建議使用FLOAT16類型以節省內存空間。
FLAT索引
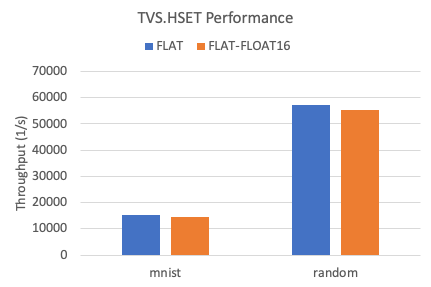
寫入性能
以下是在兩個數據集下,TairVector FLAT索引的寫入吞吐率。
相比較FLOAT32,FLOAT16數據類型的寫入性能略有下降,下降幅度為5%左右。
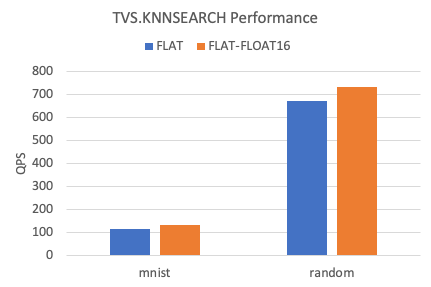
KNN查詢性能
以下是在兩個數據集下,TairVector FLAT索引KNN查詢的QPS。
相比較FLOAT32,FLOAT16數據類型的KNN查詢性能提升約10%左右。
內存效率
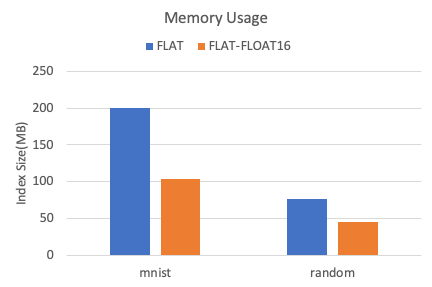
以下是在兩個數據集下,TairVector FLAT索引的內存占用情況。
相比較FLOAT32,FLOAT16數據類型可減少40%以上的內存占用。