EasyTransfer旨在幫助自然語言處理(NLP)場景的遷移學習開發者方便快捷地構建遷移學習模型。本文以文本分類為例,為您介紹如何在DSW中使用EasyTransfer,包括啟動訓練、評估模型、預測模型及導出并部署模型。
前提條件
已創建DSW實例,且該實例滿足版本限制,詳情請參見創建及管理DSW實例和使用限制。
建議創建DSW實例時選擇GPU規格。
背景信息
遷移學習(Transfer Learning)的核心的思想是將一個環境中學到的知識應用到新環境的學習任務中。面向自然語言處理(NLP)場景的遷移學習在工業上擁有大量需求,且不斷涌現新的領域,而傳統的機器學習需要對每個領域都積累大量訓練數據,這將耗費大量的人力和物力。如果能夠利用現有的訓練數據幫助學習新領域的學習任務,將會大幅度減少標注的人力和物力。為了方便用戶快速搭建面向NLP場景的遷移學習模型,PAI團隊推出了深度遷移學習框架EasyTransfer。
使用限制
EasyTransfer僅支持如下Python版本和鏡像版本:
Python版本:Python 2.7或Python 3.4及其以上版本。
鏡像版本:選擇官方鏡像tensorflow:1.12PAI-gpu-py36-cu101-ubuntu18.04。
步驟一:準備數據
進入DSW開發環境。
登錄PAI控制臺
在左側導航欄單擊工作空間列表,在工作空間列表頁面中單擊待操作的工作空間名稱,進入對應工作空間內。
在頁面左上方,選擇使用服務的地域。
在左側導航欄,選擇。
可選:在交互式建模(DSW)頁面的搜索框,輸入實例名稱或關鍵字,搜索實例。
單擊需要打開的實例操作列下的打開。
在DSW開發環境,單擊頂部菜單欄中的Terminal,按照界面操作指引打開Terminal。
在Terminal中,使用如下命令下載Demo數據集。
wget http://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/tutorial/ez_text_classify/zqkd_sample/train.csv wget http://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/tutorial/ez_text_classify/zqkd_sample/dev.csv說明此處僅使用少量樣本進行演示,您訓練自己的新聞分類模型時,需要使用更多的樣本進行模型訓練。
步驟二:啟動訓練任務(在當前目錄)
使用如下命令,啟動訓練任務。
easy_transfer_app \
--mode=train \
--modelName=text_classify_bert \
--inputTable="./train.csv,./dev.csv" \
--inputSchema=content:str:1,label:str:1 \
--firstSequence=content \
--labelName=label \
--labelEnumerateValues="教育,三農,娛樂,健康,美文,搞笑,美食,財經,科技,旅游,汽車,時尚,科學,文化,房產,熱點,母嬰,家居,體育,國際,育兒,寵物,游戲,健身,職場,讀書,藝術,動漫" \
--sequenceLength=128 \
--checkpointDir=./classify_models \
--batchSize=64 \
--numEpochs=3 \
--optimizerType=adam \
--learningRate=3e-5 \
--advancedParameters='\
pretrain_model_name_or_path=pai-bert-base-zh \
'命令中的訓練參數介紹如下表所示。
參數 | 是否必選 | 描述 | 默認值 | 類型 |
mode | 是 | 模式,取值包括:
| 無 | STRING |
modelName | 否 | App模型名稱,支持以下模型:
| text_match_bert | STRING |
inputTable | 是 | 輸入的訓練表,使用英文逗號(,)分隔。例如 | 無 | STRING |
inputSchema | 是 | 輸入文件的列Schema,取值格式為列名:類型:長度。其中:
| 無 | STRING |
firstSequence | 是 | 第一個文本序列在輸入格式中對應的列名。 | 無 | STRING |
labelName | 否 | 標簽在輸入格式中對應的列名。 | 空字符串('') | STRING |
labelEnumerateValues | 否 | 標簽枚舉值,支持以下兩種格式:
| 空字符串('') | STRING |
sequenceLength | 否 | 序列整體最大長度,取值范圍1~512。 | 128 | INT |
checkpointDir | 是 | 模型存儲路徑所在目錄。例如 | 無 | STRING |
batchSize | 否 | 訓練時的批處理大小。如果是多卡訓練,則為每個GPU上的批處理大小。 | 32 | INT |
numEpochs | 否 | 訓練總Epoch的數量。 | 1 | INT |
optimizerType | 否 | 優化器類型,取值包括:
| adam | STRING |
learningRate | 否 | 學習率。 | 2e-5 | FLOAT |
advancedParameters | 否 | 其他高級參數,詳情請參見下方的高級參數表格。 | 不涉及 | STRING |
關于高級參數的介紹如下表所示。
參數 | 是否必選 | 描述 | 默認值 | 類型 |
pretrain_model_name_or_path | 否 | 預訓練模型。不僅支持EasyTransfer下的所有預訓練模型,也支持用戶自己的預訓練模型OSS地址。 | pai-bert-base-zh | STRING |
步驟三:評估模型
訓練完成后,您可以使用如下命令測試或評估訓練結果。
easy_transfer_app \
--mode=evaluate \
--inputTable=./dev.csv \
--checkpointPath=./classify_models/model.ckpt-64 \
--batchSize=10命令中的參數介紹如下表所示。
參數 | 是否必選 | 描述 | 默認值 | 類型 |
mode | 是 | 模式,取值包括:
| 無 | STRING |
inputTable | 是 | 輸入的評估表,使用英文逗號(,)分隔。例如 重要 評估集的列Schema必須與訓練集的保持一致。 | 無 | STRING |
checkpointPath | 是 | 模型CKPT存儲路徑所在的目錄。例如 | 無 | STRING |
batchSize | 否 | 評估時的批處理大小。如果是多卡場景,則為每個GPU上的批處理大小。 | 32 | INT |
步驟四:預測模型
訓練完成后,您可以使用如下命令對文件(可以沒有標簽)進行預測。
easy_transfer_app \
--mode=predict \
--inputSchema=content:str:1,label:str:1 \
--inputTable=dev.csv \
--outputTable=dev.pred.csv \
--firstSequence=content \
--appendCols=label \
--outputSchema=predictions,probabilities,logits \
--checkpointPath=./classify_models/ \
--batchSize=100命令中的參數介紹如下表所示。
參數 | 是否必選 | 描述 | 默認值 | 類型 |
mode | 是 | 模式,取值包括:
| 無 | STRING |
inputTable | 是 | 輸入的待預測表。例如 | 無 | STRING |
outputTable | 是 | 預測結果的輸出表。例如 | 無 | STRING |
inputSchema | 是 | 輸入文件的列Schema,取值格式為列名:類型:長度。其中:
| 無 | STRING |
firstSequence | 是 | 第一個文本序列在輸入格式中對應的列名。 | 無 | STRING |
appendCols | 否 | 輸入表中需要添加到輸出表的列。 | 空字符串('') | STRING |
outputSchema | 否 | 選擇輸出數據中需要的預測值,多個選擇項之間以英文逗號(,)分隔。支持以下三種格式:
| predictions | STRING |
checkpointPath | 是 | 模型存儲路徑所在目錄。例如 | 無 | STRING |
batchSize | 否 | 訓練時的批處理大小。如果是多卡訓練,則為每個GPU上的批處理大小。 | 32 | INT |
步驟五:導出模型并在線部署EAS服務
導出模型。
訓練結束后,默認會導出最后一個Checkpoint生成的variables和saved_model.pb文件。如果您需要導出其他Checkpoint的訓練結果,則可以使用如下命令。
easy_transfer_app \ --mode=export \ --exportType=app_model \ --checkpointPath=./classify_models/model.ckpt-64 \ --exportDirBase=./export_model \ --batchSize=100命令中的參數介紹如下表所示。
參數
是否必選
描述
默認值
類型
mode
是
模式,取值包括:
train:訓練
evaluate:評估
predict:預測
export:導出
無
STRING
exportType
是
導出的類型,取值包括:
app_model: 導出Finetune模型。
ez_bert_feat:導出文本向量化組件所需模型。
無
STRING
checkpointPath
是
模型CKPT存儲路徑所在的目錄。
無
STRING
exportDirBase
是
導出模型的目錄。
無
STRING
batchSize
否
評估時的批處理大小。如果是多卡場景,則為每個GPU上的批處理大小。
32
INT
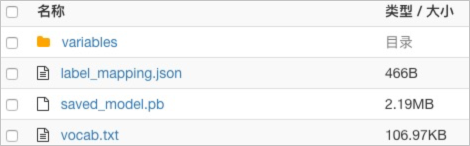
打包模型文件。
打包輸出目錄中的variables、saved_model.pb、vocab.txt及定義用戶輸入的label_mapping文件。例如本文中新聞分類的label_mapping文件為label_mapping.json,該文件中的標簽ID必須為INT類型,且順序與訓練時的labelEnumerateValues參數的順序一致。label_mapping.json的內容示例如下。
{"教育": 0, "三農": 1, ..., "動漫": 27}您也可以從訓練指定的checkpointDir目錄下找到label_mapping.json文件。
打包得到的文件如下所示。
上傳模型文件至OSS,得到模型的OSS地址。例如
oss://xxx/your_model.zip。部署模型,詳情請參見EasyTransfer Processor。