本文通過示例為您介紹如何基于EMR Serverless StarRocks構建分鐘級準實時分析。
前提條件
- 已創建DataFlow集群或自定義集群,具體操作請參見創建集群。
- 已創建EMR Serverless StarRocks實例,具體操作請參見創建實例。
- 已創建RDS MySQL,具體操作請參見創建RDS MySQL實例。
- 已創建EMR Studio集群,并開通了8443、8000和8081端口,具體操作請參見創建EMR Studio集群和添加安全組規則。
說明 本文示例中DataFlow集群為EMR-3.40.0版本、MySQL為5.7版本。
使用限制
- DataFlow集群、StarRocks集群和RDS MySQL實例需要在同一個VPC下,并且在同一個可用區下。
- DataFlow集群和StarRocks集群均須開啟公網訪問。
- RDS MySQL為5.7及以上版本。
場景介紹
該場景與數倉場景:即席查詢構建數倉的邏輯基本一致,都是直接在StarRocks中進行數倉分層建模,區別在于分鐘級準實時場景將即席查詢場景中的視圖部分物化成了表,因此具有更高的計算效率,可以支撐更高的QPS查詢。
方案架構
分鐘級準實時場景的基本架構如下圖所示。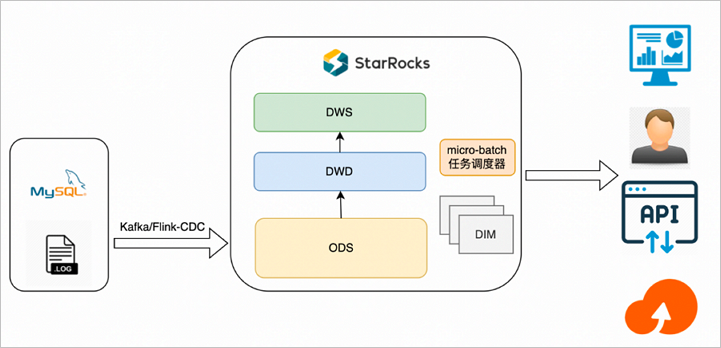
整體數據流如下:
- Flink清洗導入Kafka的日志或者通過Flink-CDC-StarRocks工具讀取MySQL Binlog導入StarRocks,根據需要選用明細、聚合、更新、主鍵各種模型,只物理落地ODS層。
- 利用第三方任務調度器(例如Airflow)將各層數據表按血緣關系進行任務編排,再按具體的分鐘間隔作為一個微批粒度進行任務調度,依次構建ODS之上的各層數據表。
方案特點
該方案主要特點是:計算邏輯在StarRocks側,適用于高頻查詢場景,各層數據表按具體的分鐘間隔時間作為微批粒度的數據同步。
- 將操作層(ODS層)的數據經過簡單的清理、關聯,然后存儲到明細數據,暫不做過多的二次加工匯總,明細數據直接寫入StarRocks。
- DWD或DWS層為實際的物理表,可以通過DataWorks或Airflow等調度工具調度周期性寫入數據。
- StarRocks通過表的形式直接對接上層應用,實現應用實時查詢。
- 前端實時請求實際的物理表,數據的實時性依賴DataWorks或Airflow調度周期配置,例如5分鐘調度、10分鐘調度等。
方案優勢
- 查詢性能強,上層應用只查詢最后匯總的數據,相比View,查詢的數據量更大,性能會更強。
- 數據重刷快,當某一個環節或者數據有錯誤時,重新運行DataWorks或Airflow調度任務即可。因為所有的邏輯都是固化好的,無需復雜的訂正鏈路操作。
- 業務邏輯調整快,當需要新增或者調整各層業務,可以基于SQL所見即所得開發對應的業務場景,業務上線周期縮短。
方案缺點
因為引入了更多的加工和調度,所以時效性低于即席查詢場景。
適用場景
數據來源于數據庫和埋點系統,對QPS和實時性均有要求,適合80%實時數倉場景使用,能滿足大部分業務場景需求。
操作流程
示例操作如下:
步驟一:創建MySQL源數據表
- 創建測試的數據庫和賬號,具體操作請參見創建數據庫和賬號。創建完數據庫和賬號后,需要授權測試賬號的讀寫權限。說明 本文示例中創建的數據庫名稱為flink_cdc,賬號為emr_test。
- 使用創建的測試賬號連接MySQL實例,具體操作請參見通過DMS登錄RDS MySQL。
- 執行以下命令,創建數據庫和數據表。
CREATE DATABASE IF NOT EXISTS flink_cdc; CREATE TABLE flink_cdc.orders ( order_id INT NOT NULL AUTO_INCREMENT, order_revenue FLOAT NOT NULL, order_region VARCHAR(40) NOT NULL, customer_id INT NOT NULL, PRIMARY KEY ( order_id ) ); CREATE TABLE flink_cdc.customers ( customer_id INT NOT NULL, customer_age INT NOT NULL, customer_name VARCHAR(40) NOT NULL, PRIMARY KEY ( customer_id ) );
步驟二:創建StarRocks表
- 連接EMR Serverless StarRocks實例,詳情請參見連接StarRocks實例(客戶端方式)。
- 執行以下命令,創建數據庫。
CREATE DATABASE IF NOT EXISTS `flink_cdc`; - 執行以下命令,創建ODS表。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`customers` ( `timestamp` DateTime NOT NULL COMMENT "", `customer_id` INT NOT NULL COMMENT "", `customer_age` FLOAT NOT NULL COMMENT "", `customer_name` STRING NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`timestamp`, `customer_id`) COMMENT "" DISTRIBUTED BY HASH(`customer_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" ); CREATE TABLE IF NOT EXISTS `flink_cdc`.`orders` ( `timestamp` DateTime NOT NULL COMMENT "", `order_id` INT NOT NULL COMMENT "", `order_revenue` FLOAT NOT NULL COMMENT "", `order_region` STRING NOT NULL COMMENT "", `customer_id` INT NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`timestamp`, `order_id`) COMMENT "" DISTRIBUTED BY HASH(`order_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" ); - 執行以下命令,創建DWD表。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`dwd_order_customer_valid`( `timestamp` DateTime NOT NULL COMMENT "", `order_id` INT NOT NULL COMMENT "", `order_revenue` FLOAT NOT NULL COMMENT "", `order_region` STRING NOT NULL COMMENT "", `customer_id` INT NOT NULL COMMENT "", `customer_age` FLOAT NOT NULL COMMENT "", `customer_name` STRING NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`timestamp`, `order_id`) COMMENT "" DISTRIBUTED BY HASH(`order_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" ); - 執行以下命令,創建DWS表。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`dws_agg_by_region` ( `timestamp` DateTime NOT NULL COMMENT "", `order_region` STRING NOT NULL COMMENT "", `order_cnt` INT NOT NULL COMMENT "", `order_total_revenue` INT NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`timestamp`, `order_region`) COMMENT "" DISTRIBUTED BY HASH(`order_region`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" );
步驟三:同步RDS中的源數據到StarRocks的ODS表
- 下載Flink CDC connector和Flink StarRocks Connector,并上傳至DataFlow集群的/opt/apps/FLINK/flink-current/lib目錄下。
- 拷貝DataFlow集群的/opt/apps/FLINK/flink-current/opt/connectors/kafka目錄下的JAR包至/opt/apps/FLINK/flink-current/lib目錄下。
- 使用SSH方式登錄DataFlow集群,具體操作請參見登錄集群。
- 執行以下命令,啟動集群。重要 本文示例僅供測試,如果是生產級別的Flink作業請使用YARN或Kubernetes方式提交,詳情請參見Apache Hadoop YARN和Native Kubernetes。
/opt/apps/FLINK/flink-current/bin/start-cluster.sh - 編寫Flink SQL作業,并保存為demo.sql。執行以下命令,編輯demo.sql文件。
vim demo.sql文件內容如下所示。CREATE DATABASE IF NOT EXISTS `default_catalog`.`flink_cdc`; -- create source tables CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`orders_src`( `order_id` INT NOT NULL, `order_revenue` FLOAT NOT NULL, `order_region` STRING NOT NULL, `customer_id` INT NOT NULL, PRIMARY KEY(`order_id`) NOT ENFORCED ) with ( 'connector' = 'mysql-cdc', 'hostname' = 'rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = 'emr_test', 'password' = '@EMR!010beijing', 'database-name' = 'flink_cdc', 'table-name' = 'orders' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`customers_src` ( `customer_id` INT NOT NULL, `customer_age` FLOAT NOT NULL, `customer_name` STRING NOT NULL, PRIMARY KEY(`customer_id`) NOT ENFORCED ) with ( 'connector' = 'mysql-cdc', 'hostname' = 'rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = 'emr_test', 'password' = '@EMR!010beijing', 'database-name' = 'flink_cdc', 'table-name' = 'customers' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`orders_sink` ( `timestamp` TIMESTAMP NOT NULL, `order_id` INT NOT NULL, `order_revenue` FLOAT NOT NULL, `order_region` STRING NOT NULL, `customer_id` INT NOT NULL, PRIMARY KEY(`timestamp`,`order_id`) NOT ENFORCED ) with ( 'connector' = 'starrocks', 'database-name' = 'flink_cdc', 'table-name' = 'orders', 'username' = 'admin', 'password' = '', 'jdbc-url' = 'jdbc:mysql://fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:9030', 'load-url' = 'fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:8030', 'sink.properties.format' = 'json', 'sink.properties.strip_outer_array' = 'true', 'sink.buffer-flush.interval-ms' = '15000' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`customers_sink` ( `timestamp` TIMESTAMP NOT NULL, `customer_id` INT NOT NULL, `customer_age` FLOAT NOT NULL, `customer_name` STRING NOT NULL, PRIMARY KEY(`timestamp`,`customer_id`) NOT ENFORCED ) with ( 'connector' = 'starrocks', 'database-name' = 'flink_cdc', 'table-name' = 'customers', 'username' = 'admin', 'password' = '', 'jdbc-url' = 'jdbc:mysql://fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:9030', 'load-url' = 'fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:8030', 'sink.properties.format' = 'json', 'sink.properties.strip_outer_array' = 'true', 'sink.buffer-flush.interval-ms' = '15000' ); BEGIN STATEMENT SET; INSERT INTO `default_catalog`.`flink_cdc`.`orders_sink` SELECT LOCALTIMESTAMP, order_id, order_revenue, order_region, customer_id FROM `default_catalog`.`flink_cdc`.`orders_src`; INSERT INTO `default_catalog`.`flink_cdc`.`customers_sink` SELECT LOCALTIMESTAMP, customer_id, customer_age, customer_name FROM `default_catalog`.`flink_cdc`.`customers_src`; END;涉及參數如下所示:- 創建數據表orders_src和customers_src。
參數 描述 connector 固定值為mysql-cdc。 hostname RDS的內網地址。 您可以在RDS的數據庫連接頁面,單擊內網地址進行復制。例如,rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com。
port 固定值為3306。 username 步驟一:創建MySQL源數據表中創建的賬號名。本示例為emr_test。 password 步驟一:創建MySQL源數據表中創建的賬號的密碼。 database-name 步驟一:創建MySQL源數據表中創建的數據庫名。本示例為flink_cdc。 table-name 步驟一:創建MySQL源數據表中創建的數據表。 - orders_src:本示例為orders。
- customers_src:本示例為customers。
- 創建數據表orders_sink和customers_sink。
參數 描述 connector 固定值為starrocks。 database-name 步驟一:創建MySQL源數據表中創建的數據庫名。本示例為flink_cdc。 table-name 步驟一:創建MySQL源數據表中創建的數據表。 - orders_sink:本示例為orders。
- customers_sink:本示例為customers。
username StarRocks連接用戶名。固定值為admin。 password 不填寫。 jdbc-url 用于在StarRocks中執行查詢操作。 例如,jdbc:mysql://fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:9030。其中,fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com為EMR Serverless StarRocks實例FE節點的內網地址。說明 關于如何獲取EMR Serverless StarRocks實例FE節點的內網地址,請參見查看實例列表與詳情。load-url 指定FE節點的內網地址和HTTP端口,格式為 EMR Serverless StarRocks實例FE節點的內網地址:8030。例如,fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:8030。說明 關于如何獲取EMR Serverless StarRocks實例FE節點的內網地址,請參見查看實例列表與詳情。
- 創建數據表orders_src和customers_src。
- 執行以下命令,啟動Flink任務。
/opt/apps/FLINK/flink-current/bin/sql-client.sh -f demo.sql
步驟四:通過任務調度器,編排各數據層的微批同步任務
將以下兩個Job以10分鐘為一次間隔,編排成定時任務。
- Job 1
-- ODS to DWD INSERT INTO dwd_order_customer_valid SELECT '{start_time}', o.order_id, o.order_revenue, o.order_region, c.customer_id, c.customer_age, c.customer_name FROM customers c JOIN orders o ON c.customer_id=o.customer_id WHERE o.timestamp >= '{start_time}' AND o.timestamp < DATE_ADD('{start_time}',INTERVAL '{interval_time}' MINUTE) AND c.timestamp >= '{start_time}' AND c.timestamp < DATE_ADD('{start_time}',INTERVAL '{interval_time}' MINUTE) - Job 2
-- DWD to DWS INSERT INTO dws_agg_by_region SELECT '{start_time}', order_region, count(*) AS order_cnt, sum(order_revenue) AS order_total_revenue FROM dwd_order_customer_valid WHERE timestamp >= '{start_time}' AND timestamp < DATE_ADD('{start_time}',INTERVAL '{interval_time}' MINUTE) GROUP BY timestamp, order_region;
本示例使用EMR Studio作為任務調度器,您也可以使用自己的任務編排方案。
 圖標。
圖標。
 圖標,運行腳本。
圖標,運行腳本。


步驟五:查看數據庫和表信息
- 連接EMR Serverless StarRocks實例,詳情請參見連接StarRocks實例(客戶端方式)。
- 執行以下命令,查詢數據庫信息。
show databases;返回信息如下所示。+--------------------+ | Database | +--------------------+ | _statistics_ | | information_schema | | flink_cdc | +--------------------+ 3 rows in set (0.00 sec) - 查詢數據表信息。
步驟六:驗證插入后的數據
- 使用步驟一:創建MySQL源數據表中創建的測試賬號連接MySQL實例,具體操作請參見通過DMS登錄RDS MySQL。
- 在RDS數據庫窗口執行以下命令,向表orders和customers中插入數據。
INSERT INTO flink_cdc.orders(order_id,order_revenue,order_region,customer_id) VALUES(1,10,"beijing",1); INSERT INTO flink_cdc.orders(order_id,order_revenue,order_region,customer_id) VALUES(2,10,"beijing",1); INSERT INTO flink_cdc.customers(customer_id,customer_age,customer_name) VALUES(1, 22, "emr_test"); - 連接EMR Serverless StarRocks實例,詳情請參見連接StarRocks實例(客戶端方式)。
- 執行以下命令,查詢ODS層數據。
- 執行以下命令,查詢DWD層數據。
- 執行以下命令,查詢DWS層數據。