本文通過示例為您介紹如何基于StarRocks構建數倉場景-增量數據實時統計。
前提條件
- 已創建DataFlow或自定義集群,具體操作請參見創建集群。
- 已創建EMR Serverless StarRocks實例,具體操作請參見創建實例。
- 已創建RDS MySQL,具體操作請參見創建RDS MySQL實例。說明 本文示例中DataFlow集群為EMR-3.40.0版本、MySQL為5.7版本。
使用限制
- DataFlow集群、StarRocks集群和RDS MySQL實例需要在同一個VPC下,并且在同一個可用區下。
- DataFlow集群和StarRocks集群均須開啟公網訪問。
- RDS MySQL為5.7及以上版本。
場景介紹
因為部分場景對數據延遲非常敏感,數據產生的時候必須完成加工,所以此時您可以通過增量數據實時統計的方式,提前使用Flink將明細層、匯總層等層數據進行匯聚,匯聚之后把結果集存下來再對外提供服務。
方案架構
增量數據實時統計的基本架構如下圖所示。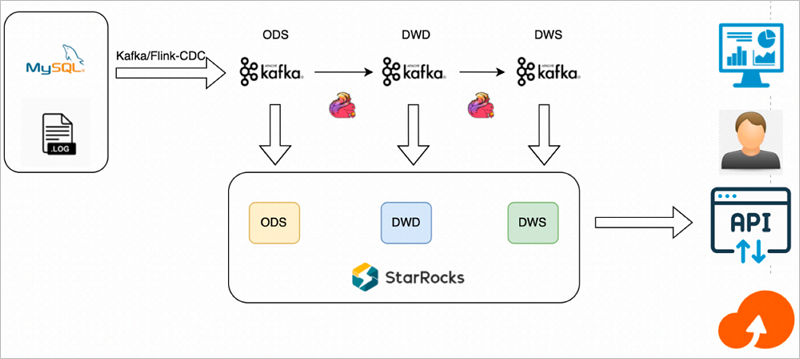
整體數據流如下:
- 直接使用Flink構建實時數倉,由Flink進行清洗加工轉換和聚合匯總,將各層結果集寫入Kafka中。
- StarRocks從Kafka分別訂閱各層數據,將各層數據持久化到StarRocks中,用于之后的查詢分析。
方案特點
該方案主要特點如下:
- 增量計算的數據由Flink進行清洗加工轉換和聚合匯總,各層應用數據通過Kafka分別持久化到StarRocks中。
- Flink加工的結果集可以采取雙寫的方式,一方面繼續投遞給下一層消息流Topic,一方面Sink到同層的StarRocks中;也可以采用單寫Kafka再通過StarRocks實時消費Kafka對應Topic上的數據,方便后續歷史數據的狀態檢查與刷新。
- StarRocks通過表的形式直接對接上層應用,實現應用實時查詢。
- 方案優勢
- 實時性強,能滿足業務對實時性敏感的場景。
- 指標修正簡單,與傳統增量計算方式不一樣的是,該方案將中間的狀態也持久存儲在StarRocks中,提升了后續分析的靈活性,當中間數據質量有問題時,直接對表修正,重刷數據即可。
- 方案缺點
- 大部分實時增量計算依賴于Flink,需要使用者有一定的Flink的技能。
- 不適合數據頻繁更新,無法累加計算的場景。
- 不適合多流Join等計算復雜資源開銷大場景。
- 適用場景
實時需求簡單,數據量不大,以埋點數據統計為主的數據,實時性最強。
操作流程
示例操作如下:
步驟一:創建MySQL源數據表
- 創建測試的數據庫和賬號,具體操作請參見創建數據庫和賬號。創建完數據庫和賬號后,需要授權測試賬號的讀寫權限。說明 本文示例中創建的數據庫名稱為flink_cdc,賬號為emr_test。
- 使用創建的測試賬號連接MySQL實例,具體操作請參見通過DMS登錄RDS MySQL。
- 執行以下命令,創建數據表。
CREATE DATABASE IF NOT EXISTS flink_cdc; CREATE TABLE flink_cdc.orders ( order_id INT NOT NULL AUTO_INCREMENT, order_revenue FLOAT NOT NULL, order_region VARCHAR(40) NOT NULL, customer_id INT NOT NULL, PRIMARY KEY ( order_id ) ); CREATE TABLE flink_cdc.customers ( customer_id INT NOT NULL, customer_age INT NOT NULL, customer_name VARCHAR(40) NOT NULL, PRIMARY KEY ( customer_id ) );
步驟二:創建Kafka的Topic
- 使用SSH方式登錄DataFlow集群,具體操作請參見登錄集群。
- 執行以下命令,創建對應的Topic。
cd $KAFKA_HOME kafka-topics.sh --create --topic ods_order --replication-factor 1 --partitions 1 --bootstrap-server "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092" kafka-topics.sh --create --topic ods_customers --replication-factor 1 --partitions 1 --bootstrap-server "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092" kafka-topics.sh --create --topic dwd_order_customer_valid --replication-factor 1 --partitions 1 --bootstrap-server "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092" kafka-topics.sh --create --topic dws_agg_by_region --replication-factor 1 --partitions 1 --bootstrap-server "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092"說明 本文代碼示例中的192.168.**.**為DataFlow集群的內網IP地址,您可以在E-MapReduce控制臺DataFlow集群的節點管理頁簽查看。
步驟三:創建StarRocks表和導入任務
- 連接EMR Serverless StarRocks實例,詳情請參見連接StarRocks實例(客戶端方式)。
- 執行以下命令,創建ODS表。
CREATE DATABASE IF NOT EXISTS `flink_cdc`; CREATE TABLE IF NOT EXISTS `flink_cdc`.`customers` ( `customer_id` INT NOT NULL COMMENT "", `customer_age` FLOAT NOT NULL COMMENT "", `customer_name` STRING NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`customer_id`) COMMENT "" DISTRIBUTED BY HASH(`customer_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" ); CREATE TABLE IF NOT EXISTS `flink_cdc`.`orders` ( `order_id` INT NOT NULL COMMENT "", `order_revenue` FLOAT NOT NULL COMMENT "", `order_region` STRING NOT NULL COMMENT "", `customer_id` INT NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`order_id`) COMMENT "" DISTRIBUTED BY HASH(`order_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" ); - 執行以下命令,創建DWD表。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`dwd_order_customer_valid`( `order_id` INT NOT NULL COMMENT "", `order_revenue` FLOAT NOT NULL COMMENT "", `order_region` STRING NOT NULL COMMENT "", `customer_id` INT NOT NULL COMMENT "", `customer_age` FLOAT NOT NULL COMMENT "", `customer_name` STRING NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`order_id`) COMMENT "" DISTRIBUTED BY HASH(`order_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" ); - 執行以下命令,創建DWS表。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`dws_agg_by_region` ( `order_region` STRING NOT NULL COMMENT "", `order_cnt` INT NOT NULL COMMENT "", `order_total_revenue` INT NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`order_region`) COMMENT "" DISTRIBUTED BY HASH(`order_region`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" ); - 執行以下命令,創建Routine Load導入任務,訂閱Kafka數據源的數據。
CREATE ROUTINE LOAD flink_cdc.routine_load_orders ON orders COLUMNS (order_id, order_revenue, order_region, customer_id) PROPERTIES ( "format" = "json", "jsonpaths" = "[\"$.order_id\",\"$.order_revenue\",\"$.order_region\",\"$.customer_id\"]" ) FROM KAFKA ( "kafka_broker_list" = "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092", "kafka_topic" = "ods_order" ); CREATE ROUTINE LOAD flink_cdc.routine_load_customers ON customers COLUMNS (customer_id, customer_age, customer_name) PROPERTIES ( "format" = "json", "jsonpaths" = "[\"$.customer_id\",\"$.customer_age\",\"$.customer_name\"]" ) FROM KAFKA ( "kafka_broker_list" = "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092", "kafka_topic" = "ods_customers" ); CREATE ROUTINE LOAD flink_cdc.routine_load_dwd_order_customer_valid ON dwd_order_customer_valid COLUMNS (order_id, order_revenue, order_region, customer_id, customer_age, customer_name) PROPERTIES ( "format" = "json", "jsonpaths" = "[\"$.order_id\",\"$.order_revenue\",\"$.order_region\",\"$.customer_id\",\"$.customer_age\",\"$.customer_name\"]" ) FROM KAFKA ( "kafka_broker_list" = "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092", "kafka_topic" = "dwd_order_customer_valid" ); CREATE ROUTINE LOAD flink_cdc.routine_load_dws_agg_by_region ON dws_agg_by_region COLUMNS (order_region, order_cnt, order_total_revenue) PROPERTIES ( "format" = "json", "jsonpaths" = "[\"$.order_region\",\"$.order_cnt\",\"$.order_total_revenue\"]" ) FROM KAFKA ( "kafka_broker_list" = "192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092", "kafka_topic" = "dws_agg_by_region" );
步驟四:執行Flink任務,啟動數據流
- 下載Flink CDC connector和Flink StarRocks Connector,并上傳至DataFlow集群的/opt/apps/FLINK/flink-current/lib目錄下。
- 拷貝DataFlow集群的/opt/apps/FLINK/flink-current/opt/connectors/kafka目錄下的JAR包至/opt/apps/FLINK/flink-current/lib目錄下。
- 使用SSH方式登錄DataFlow集群,具體操作請參見登錄集群。
- 執行以下命令,啟動集群。重要 本文示例僅供測試,如果是生產級別的Flink作業請使用YARN或Kubernetes方式提交,詳情請參見Apache Hadoop YARN和Native Kubernetes。
/opt/apps/FLINK/flink-current/bin/start-cluster.sh - 編寫Flink SQL作業,并保存為demo.sql。執行以下命令,編輯demo.sql文件。
vim demo.sql文件內容如下所示。CREATE DATABASE IF NOT EXISTS `default_catalog`.`flink_cdc`; -- create source tables CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`orders_src`( `order_id` INT NOT NULL, `order_revenue` FLOAT NOT NULL, `order_region` STRING NOT NULL, `customer_id` INT NOT NULL, PRIMARY KEY(`order_id`) NOT ENFORCED ) with ( 'connector' = 'mysql-cdc', 'hostname' = 'rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = 'emr_test', 'password' = 'Yz12****', 'database-name' = 'flink_cdc', 'table-name' = 'orders' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`customers_src` ( `customer_id` INT NOT NULL, `customer_age` FLOAT NOT NULL, `customer_name` STRING NOT NULL, PRIMARY KEY(`customer_id`) NOT ENFORCED ) with ( 'connector' = 'mysql-cdc', 'hostname' = 'rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = 'emr_test', 'password' = 'Yz12****', 'database-name' = 'flink_cdc', 'table-name' = 'customers' ); -- create ods dwd and dws tables CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`ods_order_table` ( `order_id` INT, `order_revenue` FLOAT, `order_region` VARCHAR(40), `customer_id` INT, PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'ods_order', 'properties.bootstrap.servers' = '192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092', 'key.format' = 'json', 'value.format' = 'json' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`ods_customers_table` ( `customer_id` INT, `customer_age` FLOAT, `customer_name` STRING, PRIMARY KEY (customer_id) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'ods_customers', 'properties.bootstrap.servers' = '192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092', 'key.format' = 'json', 'value.format' = 'json' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`dwd_order_customer_valid` ( `order_id` INT, `order_revenue` FLOAT, `order_region` STRING, `customer_id` INT, `customer_age` FLOAT, `customer_name` STRING, PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'dwd_order_customer_valid', 'properties.bootstrap.servers' = '192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092', 'key.format' = 'json', 'value.format' = 'json' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`dws_agg_by_region` ( `order_region` VARCHAR(40), `order_cnt` BIGINT, `order_total_revenue` FLOAT, PRIMARY KEY (order_region) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'dws_agg_by_region', 'properties.bootstrap.servers' = '192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092', 'key.format' = 'json', 'value.format' = 'json' ); USE flink_cdc; BEGIN STATEMENT SET; INSERT INTO ods_order_table SELECT * FROM orders_src; INSERT INTO ods_customers_table SELECT * FROM customers_src; INSERT INTO dwd_order_customer_valid SELECT o.order_id, o.order_revenue, o.order_region, c.customer_id, c.customer_age, c.customer_name FROM customers_src c JOIN orders_src o ON c.customer_id=o.customer_id WHERE c.customer_id <> -1; INSERT INTO dws_agg_by_region SELECT order_region, count(*) as order_cnt, sum(order_revenue) as order_total_revenue FROM dwd_order_customer_valid GROUP BY order_region; END;涉及參數如下所示:- 創建數據表orders_src和customers_src。
參數 描述 connector 固定值為mysql-cdc。 hostname RDS的內網地址。 您可以在RDS的數據庫連接頁面,單擊內網地址進行復制。例如,rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com。
port 固定值為3306。 username 步驟一:創建MySQL源數據表中創建的賬號名。本示例為emr_test。 password 步驟一:創建MySQL源數據表中創建的賬號的密碼。本示例為Yz12****。 database-name 步驟一:創建MySQL源數據表中創建的數據庫名。本示例為flink_cdc。 table-name 步驟一:創建MySQL源數據表中創建的數據表。 - orders_src:本示例為orders。
- customers_src:本示例為customers。
- 創建數據表ods_order_table、ods_customers_table、dwd_order_customer_valid和dws_agg_by_region。
參數 描述 connector 固定值為upsert-kafka。 topic 步驟二:創建Kafka的Topic中創建的Topic名稱。 - ods_order_table:本示例為ods_order。
- ods_customers_table:本示例為ods_customers。
- dwd_order_customer_valid:本示例為dwd_order_customer_valid。
- dws_agg_by_region:本示例為dws_agg_by_region。
properties.bootstrap.servers 固定格式為 192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092。
- 創建數據表orders_src和customers_src。
- 執行以下命令,啟動Flink任務。
/opt/apps/FLINK/flink-current/bin/sql-client.sh -f demo.sql
步驟五:查看數據庫和表信息
- 連接EMR Serverless StarRocks實例,詳情請參見連接StarRocks實例(客戶端方式)。
- 執行以下命令,查詢數據庫信息。
show databases;返回信息如下所示。+--------------------+ | Database | +--------------------+ | _statistics_ | | information_schema | | flink_cdc | +--------------------+ 3 rows in set (0.00 sec) - 查詢數據表信息。
步驟六:驗證插入后的數據
- 使用步驟一:創建MySQL源數據表中創建的測試賬號連接MySQL實例,具體操作請參見通過DMS登錄RDS MySQL。
- 在RDS數據庫窗口執行以下命令,向表orders和customers中插入數據。
INSERT INTO flink_cdc.orders(order_id,order_revenue,order_region,customer_id) VALUES(1,10,"beijing",1); INSERT INTO flink_cdc.orders(order_id,order_revenue,order_region,customer_id) VALUES(2,10,"beijing",1); INSERT INTO flink_cdc.customers(customer_id,customer_age,customer_name) VALUES(1, 22, "emr_test"); - 連接EMR Serverless StarRocks實例,詳情請參見連接StarRocks實例(客戶端方式)。
- 執行以下命令,查詢ODS層數據。
- 執行以下命令,查詢DWD層數據。