本文為您介紹如何通過阿里云E-MapReduce(簡稱EMR)控制臺,快速創建EMR Studio集群并開展交互式開發和工作流調度工作。
背景信息
如果您想了解更多Zeppelin、Jupyter和Airflow的信息,請參見以下內容:
前提條件
- 已申請體驗EMR Studio的資格。
- 已創建EMR Studio集群,詳情請參見創建EMR Studio集群。
說明 如果您是第一次創建EMR Studio集群,在創建EMR Studio集群時,控制臺會彈出系統角色授權窗口,請您使用主賬號對系統角色AliyunECSInstanceForEMRStudioRole進行授權。角色授權詳情請參見角色授權。
- 安全組規則已開啟8000、8081和8443端口。
添加安全組規則,詳情請參見添加安全組規則。
- 已添加用戶,詳情請參見添加用戶。
使用限制
EMR Studio僅支持與同一VPC下的EMR計算集群進行關聯。
操作流程
步驟一:進入數據開發工作臺
步驟二:關聯計算集群
重要 EMR Studio僅支持與同一VPC下的EMR計算集群進行關聯。
關聯集群后,EMR Studio集群可以訪問對應EMR集群上的資源并提交Job。
步驟三:使用Zeppelin交互式開發作業
關聯集群后,您可以在Zeppelin Notebook中進行交互式開發。EMR數據開發集群自帶教程,本文以Airflow調度教程1為例介紹。
- 在Zeppelin頁面,選擇。 頁面展示如下圖所示。
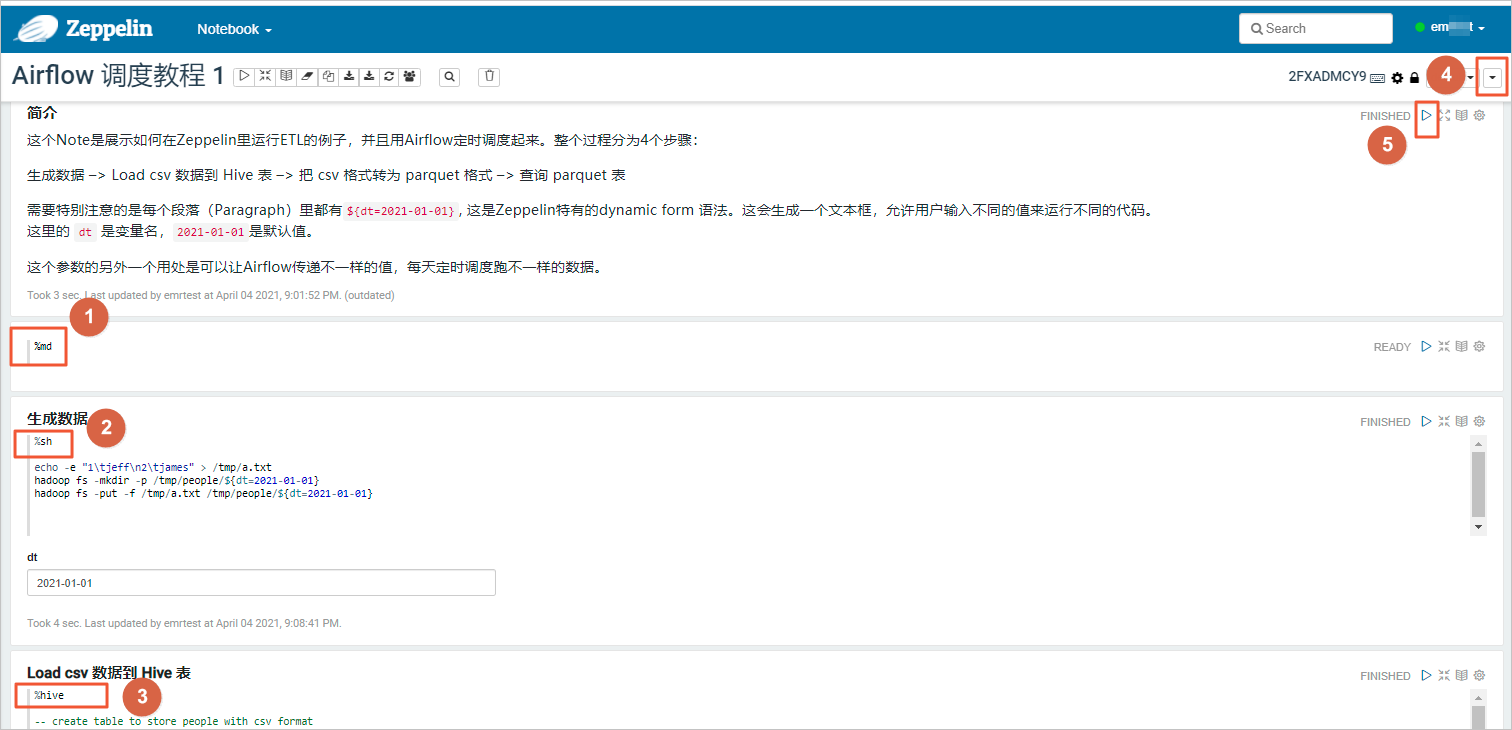
區域 描述 ① Markdown語言(以%md開頭),主要是為了添加一些說明文字。 ② Shell腳本語言(以%sh開頭),您可以運行Shell腳本,生成數據。 ③ Hive(以%hive開頭),您可以執行任意的Hive SQL語句。 ④ 單擊  圖標,可以切換關聯的集群。
圖標,可以切換關聯的集群。
⑤ 單擊  圖標,運行當前段落。
說明 部分解釋器(Interpreter)在第一次使用的時候會去下載依賴,如果提示信息類似
圖標,運行當前段落。
說明 部分解釋器(Interpreter)在第一次使用的時候會去下載依賴,如果提示信息類似Interpreter Setting 'hive' is not ready,說明下載過程還沒結束,請稍后重試。
步驟四:編寫Airflow Python腳本
Airflow的調度需要手動編寫Python腳本來構建DAG,EMR Studio自動將指定OSS路徑內的Python腳本同步至Airflow DAGs,因此,您可以在編輯和上傳完DAG腳本之后,進入數據開發工作臺,在左側導航欄中,單擊Airflow,即可進入DAGs頁面查看您創建的DAG。
EMR Studio自帶調度教程,您可以在Zeppelin頁面,選擇查看。Airflow的基本用法,請參見Apache Airflow。
說明 EMR Studio自帶用于調度Zeppelin Notebook的Operator(ZeppelinOperator),并提供Note和Paragraph兩種級別調度方式。更多信息,請參見定期調度Zeppelin中的作業。
本文以Paragraph級別調度為例,為每個Paragraph構建一個Task,然后串聯起來構成一個鏈式DAG。代碼示例如下。
from airflow import DAG
from datetime import datetime, timedelta
from airflow.providers.apache.zeppelin.operators.zeppelin_operator import ZeppelinOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2018, 1, 1),
'email_on_failure': False,
'email_on_retry': False,
'retries': 0,
'retry_delay': timedelta(minutes=5),
}
with DAG('zeppelin_example_paragraph_dag',
max_active_runs=5,
schedule_interval='0 0 * * *',
default_args=default_args) as dag:
execution_date = "{{ ds }}"
raw_data_task = ZeppelinOperator(
task_id='raw_data_task',
conn_id='zeppelin_default',
note_id='2FXADMCY9',
paragraph_id='paragraph_1613703810025_1489985581',
params= {'dt' : execution_date}
)
csv_data_task = ZeppelinOperator(
task_id='csv_data_task',
conn_id='zeppelin_default',
note_id='2FXADMCY9',
paragraph_id='paragraph_1613705325984_828524031',
params= {'dt' : execution_date}
)
parquet_data_task = ZeppelinOperator(
task_id='parquet_data_task',
conn_id='zeppelin_default',
note_id='2FXADMCY9',
paragraph_id='paragraph_1613709950691_1420422787',
params= {'dt' : execution_date}
)
query_task = ZeppelinOperator(
task_id='query_task',
conn_id='zeppelin_default',
note_id='2FXADMCY9',
paragraph_id='paragraph_1613703819960_454383326',
params= {'dt' : execution_date}
)
raw_data_task >> csv_data_task >> parquet_data_task >> query_task
步驟五:使用Airflow調度Notebook作業
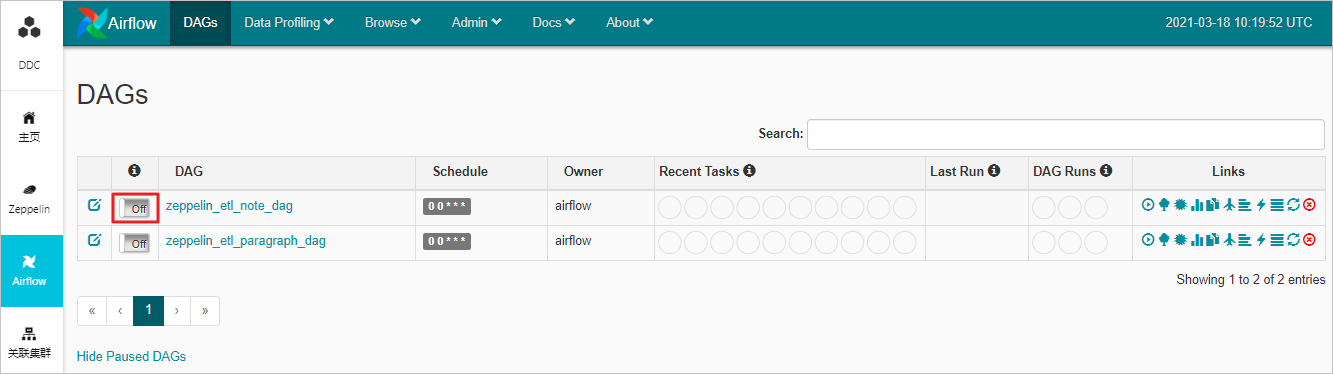
- 啟用DAG調度
在DAGs頁面,打開off開關,即可啟用DAG調度。
- 查看調度任務的詳細信息
在DAGs頁面,單擊待查看調度任務的DAG,進入Tree View頁面。
在Tree View頁面,您可以查看對應DAG運行調度任務的詳細信息。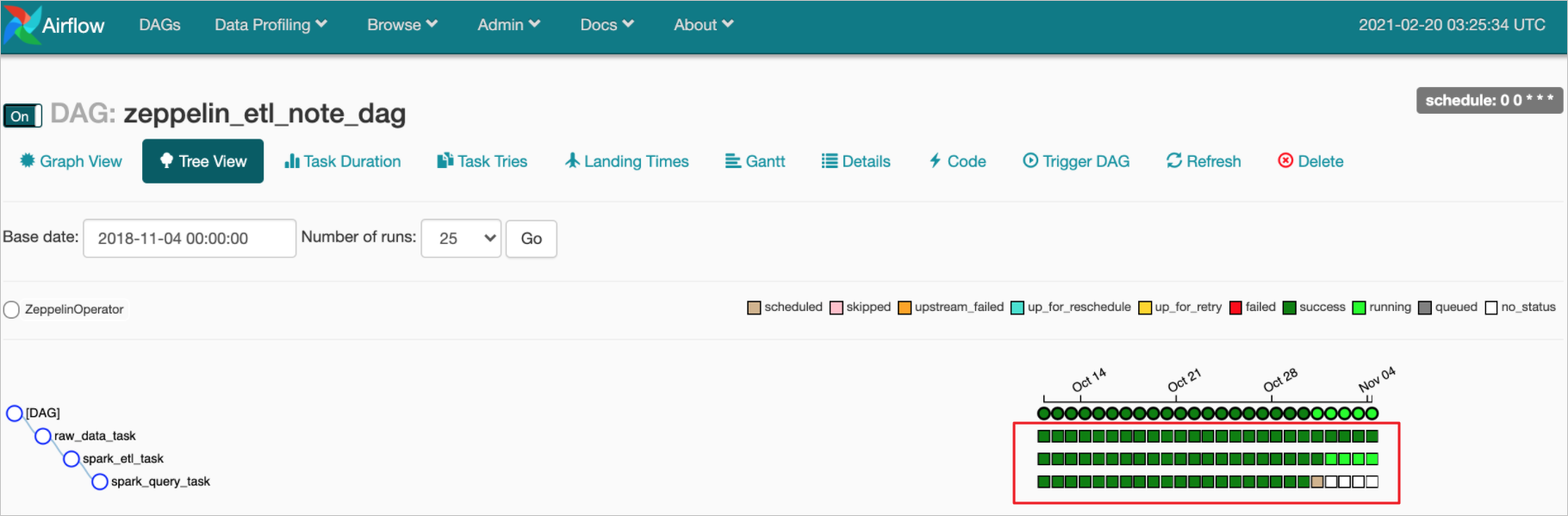
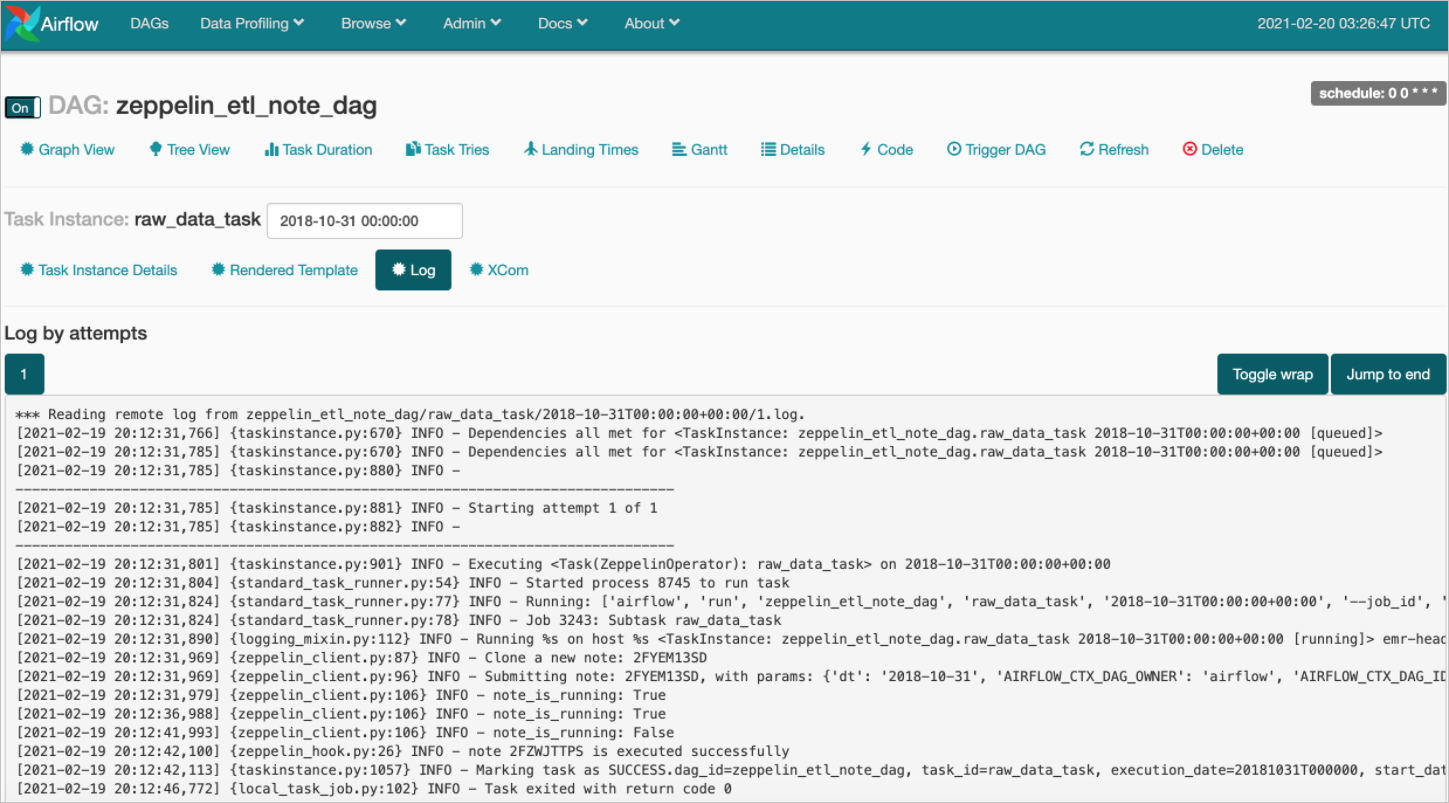
- Task的運行情況
在Tree View頁面,單擊
 圖標,即可查看對應Task的運行情況。
詳細信息如下圖所示。
圖標,即可查看對應Task的運行情況。
詳細信息如下圖所示。