EMR Serverless Spark支持通過Notebook進行交互式開發。本文帶您快速體驗Notebook的創建、運行等操作。
前提條件
已準備阿里云賬號,詳情請參見賬號注冊。
已完成角色授權,詳情請參見阿里云賬號角色授權。
已創建工作空間和Notebook會話實例,詳情請參見創建工作空間和管理Notebook會話。
操作步驟
步驟一:準備測試文件
本快速入門為了帶您快速熟悉Notebook任務,為您提供了測試文件,您可以直接下載待后續步驟使用。
單擊employee.csv,直接下載測試文件。
employee.csv文件中定義了一個包含員工姓名、部門和薪水的數據列表。
步驟二:上傳測試文件
上傳數據文件(employee.csv)到阿里云對象存儲OSS控制臺,詳情請參見文件上傳。
步驟三:開發并運行Notebook
在EMR Serverless Spark頁面,單擊左側的數據開發。
新建Notebook。
在開發目錄頁簽下,單擊新建。
在彈出的對話框中,輸入名稱,類型使用,然后單擊確定。
在右上角選擇已創建并啟動的Notebook會話實例。
您也可以在下拉列表中選擇創建Notebook會話,新建一個Notebook會話實例。關于Notebook會話更多介紹,請參見管理Notebook會話。
說明當前Notebook會話實例同一時間僅支持被單個Notebook占用,如果當前無可用Notebook會話實例,您可以在Notebook會話下拉列表中解綁Notebook與Notebook會話實例,或新建Notebook會話實例。
數據處理與可視化。
運行PySpark作業
拷貝如下代碼到新增的Notebook的Python單元格中。
# 創建一個簡單的DataFrame,其中OSS路徑需要替換為步驟二中上傳的文件路徑。 df = spark.read.option("delimiter", ",").option("header", True).csv("oss://path/to/file") # 顯示DataFrame的前幾行 df.show(5) # 執行一個簡單的聚合操作:計算每個部門的總薪資 sum_salary_per_department = df.groupBy("department").agg({"salary": "sum"}).show()單擊運行所有單元格,執行創建的Notebook。
您也可以使用不同的單元格,然后單擊單元格前面的
 圖標。
圖標。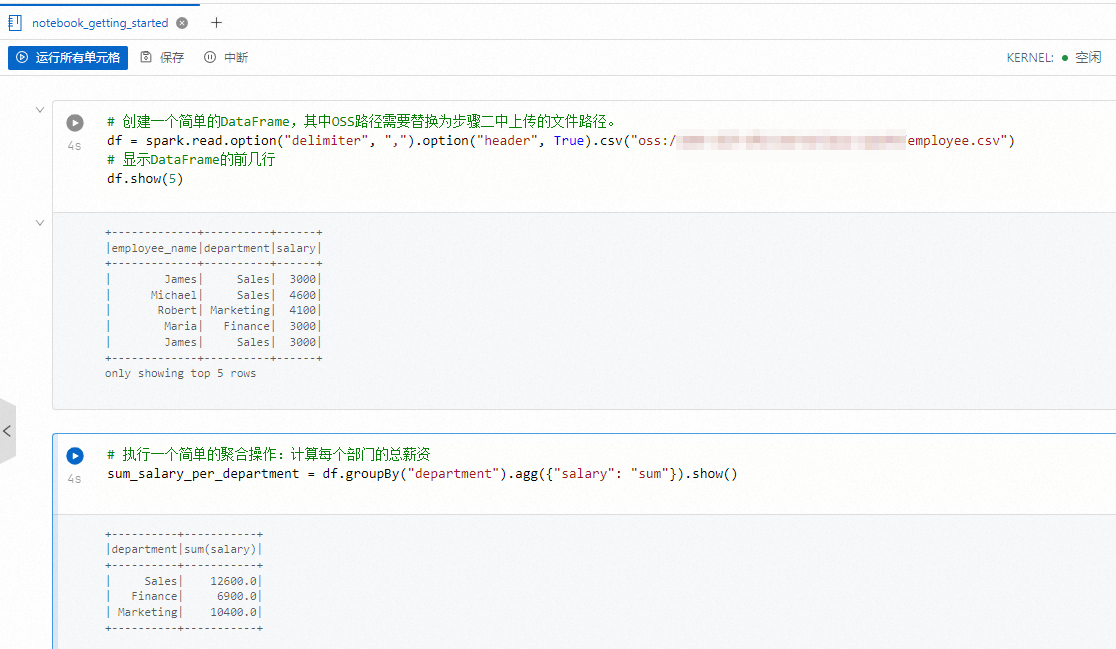
(可選)查看Spark UI。
您可以在會話下拉列表中,將鼠標懸停在當前任務的Notebook會話實例的
 上,然后單擊Spark UI跳轉至Spark Jobs頁面,可以查看Spark任務的信息。
上,然后單擊Spark UI跳轉至Spark Jobs頁面,可以查看Spark任務的信息。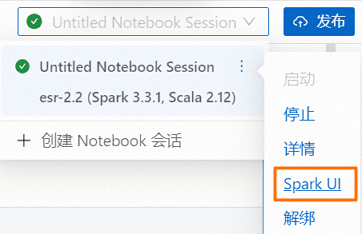
通過第三方庫進行可視化分析
說明Notebook會話已預裝matplotlib、numpy、pandas庫,如果需要使用其他第三方庫,請參見在Notebook中使用Python第三方庫。
使用matplotlib庫進行數據可視化。
import matplotlib.pyplot as plt l = sc.parallelize(range(20)).collect() plt.plot(l) plt.ylabel('some numbers') plt.show()單擊運行所有單元格,執行創建的Notebook。
您也可以使用不同的單元格,然后單擊單元格前面的
圖標。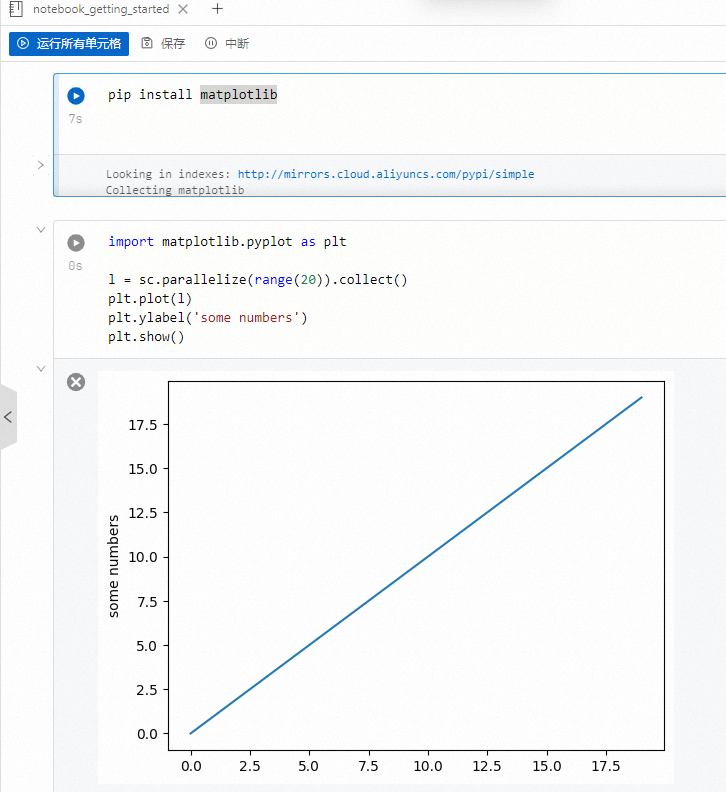
步驟四:發布Notebook
運行完成后,單擊右上角的發布。
在發布對話框,輸入發布信息,然后單擊確定,保存為一個版本。