通過網絡連接功能,您可以訪問自有VPC(Virtual Private Cloud)內的數據源。本文將以SparkSQL和Application JAR類型任務連接至您的自有VPC的HMS(Hive Metastore)服務為例,為您介紹如何配置并訪問自有VPC內的數據源。
前提條件
已準備好數據源。本文以在EMR on ECS頁面創建包含Hive服務,元數據為內置MySQL的DataLake集群為例,詳情請參見創建集群。
使用限制
當前僅支持創建一個網絡連接。
當前僅支持使用下列可用區的交換機。
地域名稱
地域ID
可用區名稱
華東1(杭州)
cn-hangzhou
杭州 可用區H
杭州 可用區I
杭州 可用區J
華東2(上海)
cn-shanghai
上海 可用區F
上海 可用區G
華北2(北京)
cn-beijing
北京 可用區F
北京 可用區G
北京 可用區H
北京 可用區K
華北3(張家口)
cn-zhangjiakou
張家口 可用區B
華北6(烏蘭察布)
cn-wulanchabu
烏蘭察布 可用區B
華南1(深圳)
cn-shenzhen
深圳 可用區E
地域名稱
地域ID
可用區名稱
新加坡
ap-southeast-1
新加坡 可用區B
新加坡 可用區C
美國(弗吉尼亞)
us-east-1
弗吉尼亞 可用區A
弗吉尼亞 可用區B
德國(法蘭克福)
eu-central-1
法蘭克福 可用區A
法蘭克福 可用區B
步驟一:新增網絡連接
進入網絡連接頁面。
在左側導航欄,選擇。
在Spark頁面,單擊目標工作空間名稱。
在EMR Serverless Spark頁面,單擊左側導航欄中的網絡連接。
在網絡連接頁面,單擊新增網絡連接。
在新增網絡連接對話框中,配置以下信息,單擊確定。
參數
說明
連接名稱
輸入新增連接的名稱。
專有網絡
選擇與EMR集群相同的專有網絡。
如果當前沒有可選擇的專有網絡,請單擊創建專有網絡,前往專有網絡控制臺創建,詳情請參見創建和管理專有網絡。
交換機
選擇與EMR集群部署在同一專有網絡下的相同交換機。
如果當前可用區沒有交換機,請單擊虛擬交換機,前往專有網絡控制臺創建,詳情請參見創建和管理交換機。
重要僅支持選擇特定可用區下的交換機,詳情請參見使用限制。
當狀態顯示為已成功時,表示新增網絡連接成功。

步驟二:為EMR集群添加安全組規則
獲取已創建網絡連接中指定交換機的網段。
您可以登錄專有網絡管理控制臺的交換機頁面,獲取交換機的網段。
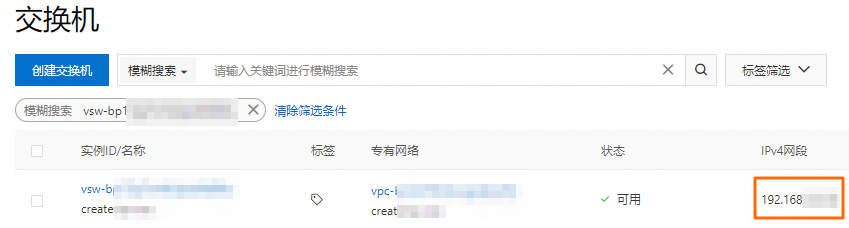
添加安全組規則。
在EMR on ECS頁面,單擊目標集群的集群ID。
在基礎信息頁面的安全區域,單擊集群安全組后面的鏈接。
在安全組詳情頁面的訪問規則區域,單擊手動添加,填寫端口范圍和授權對象,然后單擊保存。
參數
說明
端口范圍
填寫9083端口。
授權對象
填寫前一步驟中獲取的指定交換機的網段。
重要為防止被外部的用戶攻擊導致安全問題,授權對象禁止填寫為0.0.0.0/0。
(可選)步驟三:連接Hive服務并查詢表數據
如果您已有創建并配置好的Hive表,則可以跳過該步驟。
使用SSH方式登錄集群的Master節點,詳情請參見登錄集群。
執行以下命令,進入Hive命令行。
hive執行以下命令,創建表。
CREATE TABLE my_table (id INT,name STRING);執行以下命令,向表中插入數據。
INSERT INTO my_table VALUES (1, 'John'); INSERT INTO my_table VALUES (2, 'Jane');執行以下命令,查詢數據。
SELECT * FROM my_table;
(可選)步驟四:準備并上傳資源文件
如果您后續使用JAR任務類型,則需提前準備好資源文件。如果使用本文的SparkSQL任務類型,則可以跳過該步驟。
在本地新建一個Maven工程。
package com.example; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; public class DataFrameExample { public static void main(String[] args) { // 創建SparkSession。 SparkSession spark = SparkSession.builder() .appName("HMSQueryExample") .enableHiveSupport() .getOrCreate(); // 執行查詢。 Dataset<Row> result = spark.sql("SELECT * FROM default.my_table"); // 打印查詢結果。 result.show(); // 關閉SparkSession。 spark.stop(); } }<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>sparkDataFrame</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <spark.version>3.3.1</spark.version> <scala.binary.version>2.12</scala.binary.version> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> </dependencies> </project>使用
mvn package命令打包,編譯打包后生成sparkDataFrame-1.0-SNAPSHOT.jar文件。在EMR Serverless Spark頁面的目標工作空間下,單擊左側的文件管理。
在文件管理頁面,單擊上傳文件。
上傳本地打包好的
sparkDataFrame-1.0-SNAPSHOT.jar文件。
步驟五:新建并運行任務
JAR任務
在EMR Serverless Spark頁面,單擊左側的數據開發。
單擊新建。
輸入名稱,類型選擇,單擊確定。
在新建的任務開發中,配置以下信息,其余參數無需配置,然后單擊運行。
參數
說明
主jar資源
選擇前一步驟中上傳的資源文件。例如,sparkDataFrame-1.0-SNAPSHOT.jar。
Main Class
提交Spark任務時所指定的主類。本文示例填寫為com.example.DataFrameExample。
Spark配置
配置以下信息。
spark.hadoop.hive.metastore.uris thrift://*.*.*.*:9083 spark.hadoop.hive.imetastoreclient.factory.class org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClientFactory spark.emr.serverless.network.service.name <yourConnectionName>其中,以下信息請您根據實際情況替換:
*.*.*.*為HMS服務的內網IP地址。本示例為EMR集群Master節點的內網IP,您可以在EMR集群的節點管理頁面中查看。<yourConnectionName>為您在步驟一中新增的網絡連接的名稱。
運行任務后,在下方的運行記錄區域,單擊任務操作列的詳情。
在任務歷史的開發任務頁面的日志探查頁簽,您可以查看相關的日志信息。
SparkSQL任務
創建并啟動SQL會話,詳情請參見管理SQL會話。
Spark配置參數需要配置以下信息。
spark.hadoop.hive.metastore.uris thrift://*.*.*.*:9083 spark.hadoop.hive.imetastoreclient.factory.class org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClientFactory spark.emr.serverless.network.service.name <yourConnectionName>其中,以下信息請您根據實際情況替換:
*.*.*.*為HSM服務的內網IP地址。本示例為EMR集群Master節點的內網IP,您可以在EMR集群的節點管理頁面中查看。<yourConnectionName>為您在步驟一中新增的網絡連接的名稱。
在EMR Serverless Spark頁面,單擊左側的數據開發。
單擊新建。
輸入名稱,類型選擇,單擊確定。
在新建的任務開發中,選擇Catalog、數據庫和已啟動的SQL會話實例,輸入以下命令,并單擊運行。
SELECT * FROM default.my_table;說明當您計劃將基于外部Metastore的SQL代碼部署到工作流時,請確保您的SQL語句以
db.table_name的形式指定表名,并且務必在界面右上方“Catalog”選項中選取一個默認庫,其格式應為catalog_id.default。下方的運行結果區域會向您展示返回信息。
