EMR Serverless Spark支持連接外部Hive Metastore服務,您可以便捷地訪問存儲在Hive Metastore中的數據。本文將介紹如何在EMR Serverless Spark中配置和連接外部Hive Metastore服務,以便在工作環境中高效管理和利用數據資源。
前提條件
使用限制
使用Hive Metastore需要您重啟工作空間中現有的會話。
設置Hive Metastore為默認Catalog后,您的工作流任務將默認依賴于Hive Metastore。
操作流程
步驟一:準備Hive Metastore服務
本文采用EMR on ECS的Hive Metastore作為外部服務,如果您的VPC內已經有Hive Metastore服務,則請忽略該步驟。
步驟二:新增網絡連接
進入網絡連接頁面。
在左側導航欄,選擇。
在Spark頁面,單擊目標工作空間名稱。
在EMR Serverless Spark頁面,單擊左側導航欄中的網絡連接。
在網絡連接頁面,單擊新增網絡連接。
在新增網絡連接對話框中,配置以下信息,單擊確定。
參數
說明
連接名稱
輸入新增連接的名稱。
專有網絡
選擇與EMR集群相同的專有網絡。
交換機
選擇與EMR集群部署在同一專有網絡下的相同交換機。
當狀態顯示為已成功時,表示新增網絡連接成功。

步驟三:開放Hive Metastore服務端口
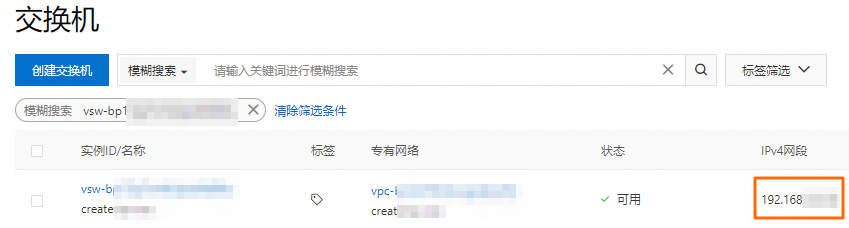
獲取已創建網絡連接中指定交換機的網段。
您可以登錄專有網絡管理控制臺,在交換機頁面獲取交換機的網段。
添加安全組規則。
在EMR on ECS頁面,單擊目標集群的集群ID。
在基礎信息頁面,單擊集群安全組后面的鏈接。
在安全組頁面,單擊手動添加,填寫端口范圍和授權對象,然后單擊保存。
參數
說明
端口范圍
填寫9083端口。
授權對象
填寫前一步驟中獲取的指定交換機的網段。
重要為防止被外部的用戶攻擊導致安全問題,授權對象禁止填寫為0.0.0.0/0。
步驟四:連接Hive Metastore
在EMR Serverless Spark頁面,單擊左側導航欄中的數據目錄。
在數據目錄頁面,單擊添加數據目錄。
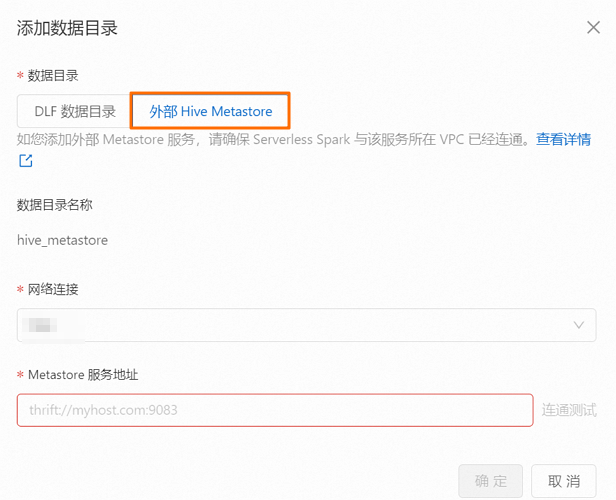
在彈出的對話框中,單擊外部Hive Metastore,配置以下信息,單擊確定。
參數
說明
網絡連接
選擇步驟二中新增的網絡連接。
Metastore服務地址
Hive MetaStore的URI。格式為
thrift://<Hive metastore的IP地址>:9083。<Hive metastore的IP地址>為HMS服務的內網IP地址。本示例為EMR集群Master節點的內網IP,您可以在EMR集群的節點管理頁面中查看。
步驟五:使用Hive Metastore
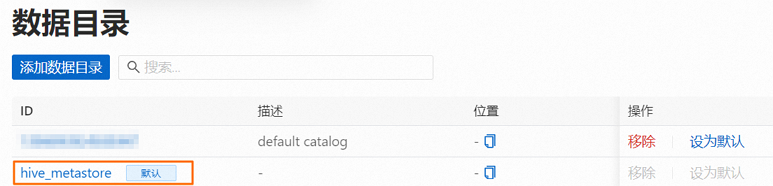
在數據目錄頁面,單擊hive_metastore操作列的設為默認,設置hive_metastore為工作空間的默認數據目錄。
重啟SQL會話。
如果您的工作空間中已有SQL會話,您需先停止SQL會話,然后再啟動SQL會話,以確保hive_metastore生效。
在SQL開發中查詢hive_metastore表的數據。
新建SQL開發,詳情請參見SQL開發。
執行以下命令,查詢hive_metastore中的dw_users表。
SELECT * FROM dw_users;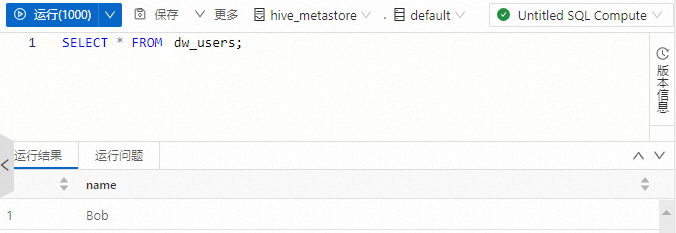
常見問題
根據HDFS集群是否配置了高可用(HA)模式,需要采取不同的配置策略。
非HA HDFS路徑訪問
當表的
location指向一個沒有啟用高可用配置的HDFS路徑時,由于只有一個NameNode負責管理文件系統的命名空間,因此,不需要特別的配置即可直接訪問數據。HA HDFS路徑訪問
如果表的
location指向的是一個啟用了高可用的HDFS路徑,由于存在多個NameNode,需要在會話實例的Spark配置中額外配置以下內容,以確保Java Runtime或Fusion引擎能夠正常訪問數據。Java Runtime訪問HDFS數據
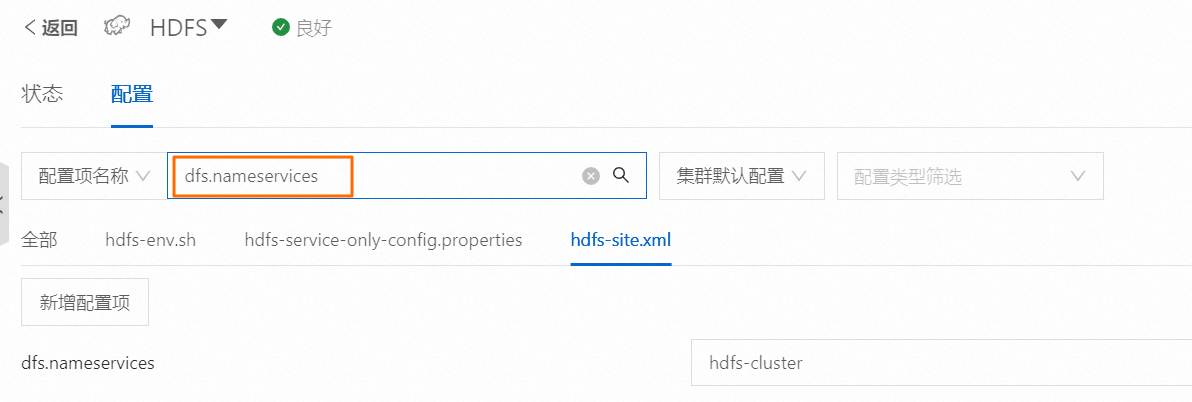
在EMR集群的集群服務頁面的HDFS服務的配置頁簽,參照hdfs-site.xml中內容新增下面的配置。
說明在控制臺查看配置項時,需去掉配置項中的
spark.hadoop.前綴。以下配置項的值僅為示例,具體以控制臺查詢結果為準。
spark.hadoop.dfs.namenode.rpc-address.hdfs-cluster.nn1 master-1-1.<cluster-id>.<region>.emr.aliyuncs.com:*** spark.hadoop.dfs.nameservices hdfs-cluster spark.hadoop.dfs.ha.namenodes.hdfs-cluster nn1,nn2,nn3 spark.hadoop.dfs.client.failover.proxy.provider.hdfs-cluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider例如,在EMR控制臺查看配置信息。
Fusion引擎訪問HDFS數據
在EMR集群的集群服務頁面的HDFS服務的配置頁簽,參照hdfs-site.xml中內容新增下面的配置。
說明在控制臺查看配置項時,需去掉配置項中的
spark.hadoop.前綴。以下配置項的值僅為示例,具體以控制臺查詢結果為準。
spark.hadoop.dfs.namenode.rpc-address.hdfs-cluster.nn1 master-1-1.<cluster-id>.<region>.emr.aliyuncs.com:**** spark.hadoop.dfs.nameservices hdfs-cluster spark.hadoop.dfs.ha.namenodes.hdfs-cluster nn1,nn2,nn3 spark.hadoop.dfs.client.failover.proxy.provider.hdfs-cluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider例如,在EMR控制臺查看配置信息。
將集群的HDFS服務的
hdfs-site.xml文件拷貝到OSS上,并重命名為hdfs-client.xml。例如,oss://<bucket>/tmp/hdfs-client.xml。關于配置文件路徑,請參見常用文件路徑。
再在會話實例的Spark配置中額外新增以下內容。
spark.files oss://<bucket>/tmp/hdfs-client.xml spark.executorEnv.LIBHDFS3_CONF /opt/spark/work-dir/hdfs-client.xml