使用第八代Intel實(shí)例單機(jī)部署Qwen-72B-Chat
本文介紹如何使用阿里云第八代Intel實(shí)例,基于BigDL-LLM單機(jī)部署通義千問(wèn)Qwen-72B-Chat語(yǔ)言模型進(jìn)行AI對(duì)話。
背景信息
通義千問(wèn)-72B(Qwen-72B)是阿里云研發(fā)的通義千問(wèn)大模型系列的720億參數(shù)規(guī)模模型。Qwen-72B的預(yù)訓(xùn)練數(shù)據(jù)類型多樣、覆蓋廣泛,包括大量網(wǎng)絡(luò)文本、專業(yè)書(shū)籍、代碼等。而Qwen-72B-Chat是在Qwen-72B的基礎(chǔ)上,使用對(duì)齊機(jī)制打造的基于大語(yǔ)言模型的AI助手,是通義千問(wèn)對(duì)外開(kāi)源的72B規(guī)模參數(shù)量的經(jīng)過(guò)人類指令對(duì)齊的Chat模型。
BigDL-LLM是一個(gè)專為大型語(yǔ)言模型優(yōu)化設(shè)計(jì)的加速庫(kù),它提供了多種低精度優(yōu)化選項(xiàng)(例如 INT4、INT5、INT8等),并可利用Intel? CPU集成的多種硬件加速技術(shù)(例如AVX、VNNI、AMX等)以及最新的軟件優(yōu)化,從而賦能大語(yǔ)言模型在Intel? 平臺(tái)上實(shí)現(xiàn)更高效的優(yōu)化和更快速的運(yùn)行。
Qwen-72B-Chat模型依照LICENSE開(kāi)源,免費(fèi)商用需填寫商業(yè)授權(quán)申請(qǐng)。您應(yīng)自覺(jué)遵守第三方模型的用戶協(xié)議、使用規(guī)范和相關(guān)法律法規(guī),并就使用第三方模型的合法性、合規(guī)性自行承擔(dān)相關(guān)責(zé)任。
創(chuàng)建ECS實(shí)例
按照界面提示完成參數(shù)配置,創(chuàng)建一臺(tái)ECS實(shí)例。
需要注意的參數(shù)如下,其他參數(shù)的配置,請(qǐng)參見(jiàn)自定義購(gòu)買實(shí)例。
實(shí)例:Qwen-72B-Chat大概需要70 GiB內(nèi)存,為了保證模型運(yùn)行的穩(wěn)定,建議選擇192 GiB內(nèi)存或以上的實(shí)例規(guī)格,本文以ecs.c8i.24xlarge為例。
鏡像:Alibaba Cloud Linux 3.2104 LTS 64位。
公網(wǎng)IP:選中分配公網(wǎng)IPv4地址,帶寬計(jì)費(fèi)模式選擇按使用流量,帶寬峰值設(shè)置為100 Mbps。以加快模型下載速度。
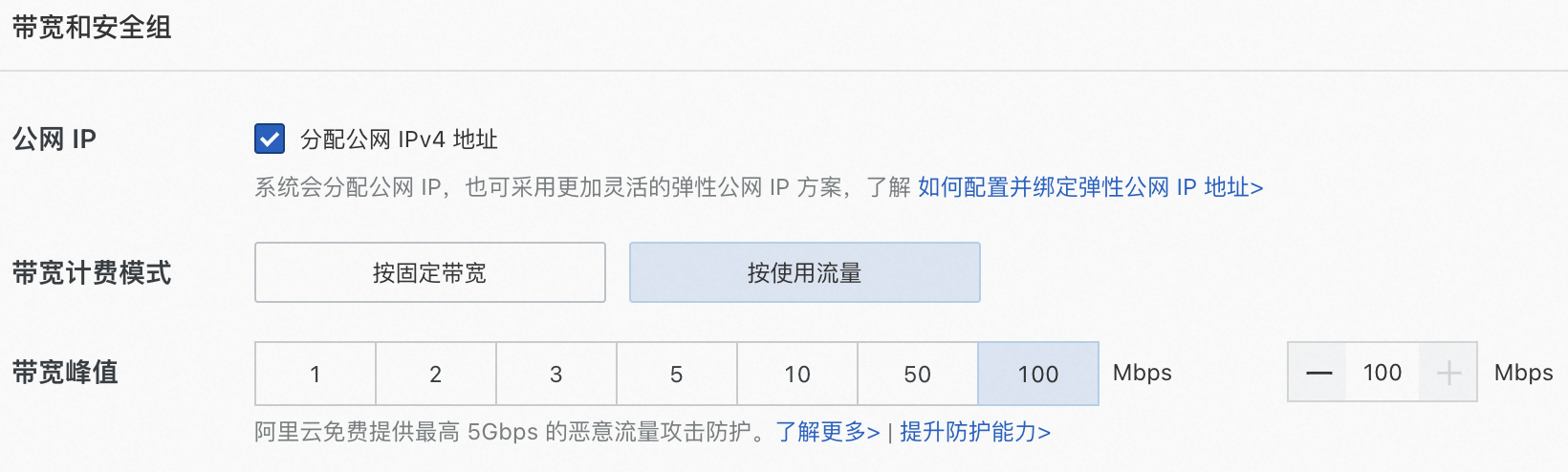
數(shù)據(jù)盤:Qwen-72B-Chat的運(yùn)行需要下載多個(gè)模型文件,會(huì)占用大量存儲(chǔ)空間,為了保證模型順利運(yùn)行,建議數(shù)據(jù)盤設(shè)置為300 GiB。
添加安全組規(guī)則。
在ECS實(shí)例安全組的入方向添加安全組規(guī)則并放行22、443、7860端口(用于訪問(wèn)WebUI服務(wù))。具體操作,請(qǐng)參見(jiàn)添加安全組規(guī)則。
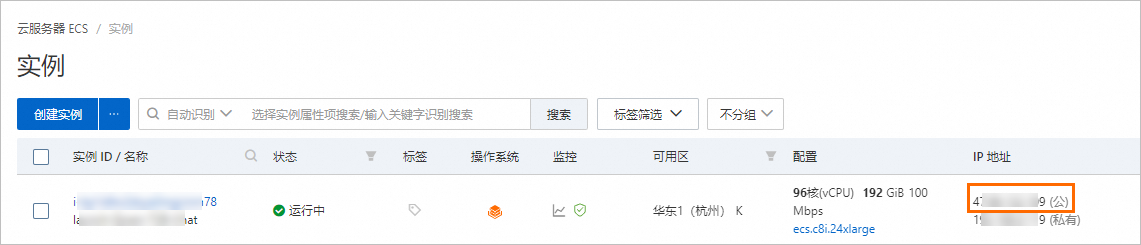
創(chuàng)建完成后,在ECS實(shí)例頁(yè)面,獲取公網(wǎng)IP地址。
說(shuō)明公網(wǎng)IP地址用于進(jìn)行AI對(duì)話時(shí)訪問(wèn)WebUI服務(wù)。
部署Qwen-72B-Chat
步驟一:配置運(yùn)行環(huán)境
遠(yuǎn)程連接ECS實(shí)例。
具體操作,請(qǐng)參見(jiàn)通過(guò)密碼或密鑰認(rèn)證登錄Linux實(shí)例。
安裝Docker。
具體操作,請(qǐng)參見(jiàn)安裝Docker并使用(Linux)。
執(zhí)行以下命令,從
docker hub中下載bigdl-llm-serving-cpu鏡像。說(shuō)明bigdl-llm-serving-cpu鏡像中已包含運(yùn)行通義千問(wèn)所需的環(huán)境,啟動(dòng)容器后可直接使用。
sudo docker pull intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT執(zhí)行以下命令,查看并驗(yàn)證
bigdl-llm-serving-cpu鏡像是否下載成功。sudo docker images若在系統(tǒng)返回信息中,存在如下鏡像,則表示
bigdl-llm-serving-cpu鏡像下載成功。
步驟二:下載Qwen-72B-Chat預(yù)訓(xùn)練模型
執(zhí)行以下命令,安裝
tmux命令。sudo yum install tmux -y執(zhí)行以下命令,創(chuàng)建一個(gè)
tmux session窗口。tmux說(shuō)明下載預(yù)訓(xùn)練模型耗時(shí)較長(zhǎng),且成功率受網(wǎng)絡(luò)情況影響較大,建議在
tmux session中下載,以免ECS斷開(kāi)連接導(dǎo)致下載模型中斷。執(zhí)行以下任一命令,下載Qwen-72B-Chat預(yù)訓(xùn)練模型。
說(shuō)明使用Git方式下載會(huì)產(chǎn)生較大的中間文件,為了節(jié)約數(shù)據(jù)盤空間,建議您使用Python腳本下載。
通過(guò)公網(wǎng)下載Qwen-72B-Chat預(yù)訓(xùn)練模型,因模型數(shù)據(jù)較大,使用100 Mbps帶寬下載時(shí)間大約為3小時(shí),請(qǐng)耐心等待。
使用Python腳本下載
執(zhí)行以下命令,下載
miniconda安裝包。wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh執(zhí)行以下命令,安裝
miniconda。bash Miniconda3-latest-Linux-x86_64.sh執(zhí)行以下命令,激活
miniconda。source ~/.bashrc若命令行首部出現(xiàn)
(base)標(biāo)識(shí),則表示miniconda激活成功。
執(zhí)行以下命令,安裝
pip命令。sudo yum install -y python3-pip依次執(zhí)行以下命令,升級(jí)
pip工具、setuptools和wheel庫(kù)。sudo pip3 install --upgrade pip sudo pip3 install --upgrade setuptools wheelminiconda安裝成功后,在conda環(huán)境中安裝modelscope。pip3 install modelscope執(zhí)行Python腳本,下載Qwen-72B-Chat預(yù)訓(xùn)練模型。
執(zhí)行以下命令,創(chuàng)建Python腳本文件
test.py。sudo vim test.py按i鍵進(jìn)入編輯模式,添加以下內(nèi)容。
from modelscope import snapshot_download model_dir = snapshot_download('qwen/Qwen-72B-Chat') print(model_dir)按
Esc鍵退出編輯模式,然后輸入:wq保存并退出。執(zhí)行以下命令,運(yùn)行Python腳本文件
test.py。python3 test.py
使用Git下載
執(zhí)行以下命令,安裝
Git命令。sudo yum install git -y下載并安裝Git LFS,以確保通過(guò)
Git命令可下載大型文件。curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash sudo yum install -y git-lfs執(zhí)行以下命令,驗(yàn)證Git LFS是否安裝成功。
git lfs version若系統(tǒng)返回Git LFS的版本信息,則表示成功安裝。
執(zhí)行以下命令,下載Qwen-72B-Chat預(yù)訓(xùn)練模型。
sudo git clone https://www.modelscope.cn/qwen/Qwen-72B-Chat.git Qwen-72b-chat
執(zhí)行以下命令,查看Qwen-72B-Chat預(yù)訓(xùn)練模型所在目錄路徑。
ls -l
步驟三:?jiǎn)?dòng)并進(jìn)入BigDL-LLM Docker容器
編寫Docker容器啟動(dòng)腳本文件。
執(zhí)行以下命令,新建并編輯
start-container.sh腳本文件。sudo vim start-container.sh按
i鍵進(jìn)入編輯模式,添加以下信息。export MODEL_PATH=[YOUR_MODEL_PATH] sudo docker run -itd \ --net=host \ --privileged \ --cpuset-cpus="0-47" \ --cpuset-mems="0" \ --name="qwen-llm" \ --shm-size="16g" \ -v $MODEL_PATH:/models \ -e ENABLE_PERF_OUTPUT="true" \ intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT說(shuō)明參數(shù)說(shuō)明如下:
MODEL_PATH:請(qǐng)您根據(jù)實(shí)際情況,將[YOUR_MODEL_PATH]替換為上述步驟二中3.查詢到Qwen-72B-Chat預(yù)訓(xùn)練模型的絕對(duì)路徑。$MODEL_PATH:?jiǎn)?dòng)Docker容器時(shí)會(huì)將Host的模型掛載到容器的/models目錄下。cpuset-cpus:指定使用的CPU核心。cpuset-mems:指定使用的NUMA內(nèi)存節(jié)點(diǎn)編號(hào)。
您可以使用
lscpu命令來(lái)查詢CPU核心數(shù)量和NUMA內(nèi)存節(jié)點(diǎn)編號(hào)。按
Esc鍵退出編輯模式,然后輸入:wq保存并退出。
執(zhí)行以下命令,啟動(dòng)Docker容器。
sudo bash start-container.sh執(zhí)行以下命令,查看Docker容器啟動(dòng)情況。
sudo docker ps -a若系統(tǒng)返回以下信息,則表示Docker容器啟動(dòng)成功。

執(zhí)行以下命令,進(jìn)入Docker容器。
sudo docker exec -it qwen-llm bash
步驟四:基于BigDL-LLM與Qwen-72B-Chat進(jìn)行AI對(duì)話
依次執(zhí)行以下命令,完成優(yōu)化操作。
說(shuō)明在進(jìn)行AI對(duì)話前,您需要對(duì)部分環(huán)境變量進(jìn)行設(shè)置以在Intel CPU上實(shí)現(xiàn)優(yōu)化效果,并對(duì)線程進(jìn)行優(yōu)化。
source bigdl-llm-init -t export OMP_NUM_THREADS=[使用的cpu核心數(shù)] #本示例使用cpu核心數(shù)為48,請(qǐng)根據(jù)實(shí)際情況,將[使用的cpu核心數(shù)]替換為合適的cpu核心數(shù)。與Qwen-72B-Chat進(jìn)行AI對(duì)話。
在實(shí)例內(nèi)部進(jìn)行AI對(duì)話
依次執(zhí)行以下命令,進(jìn)入終端與Qwen-72B-Chat進(jìn)行AI對(duì)話。
cd /llm/portable-zip python3 chat.py --model-path /models/Qwen-72B-Chat說(shuō)明Qwen-72B-Chat預(yù)訓(xùn)練模型會(huì)在加載時(shí)自動(dòng)轉(zhuǎn)換為
int4格式。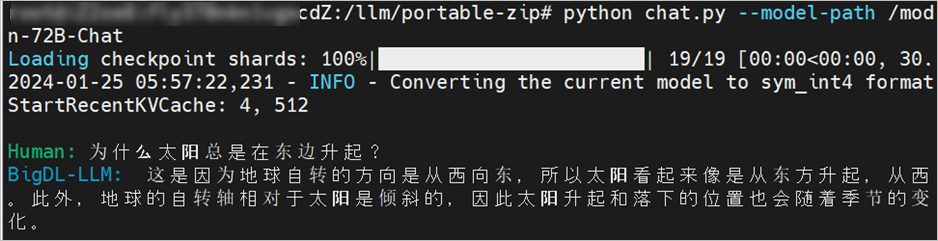
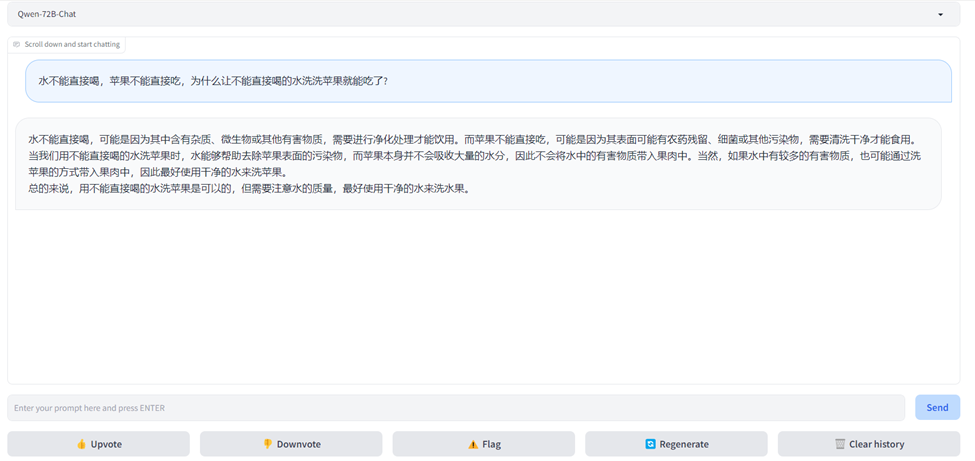
在瀏覽器進(jìn)行AI對(duì)話
執(zhí)行如下命令,開(kāi)啟WebUI服務(wù)。
python3 -m fastchat.serve.controller & python3 -m bigdl.llm.serving.model_worker --model-path /models/Qwen-72B-Chat --device cpu & python3 -m fastchat.serve.gradio_web_server說(shuō)明在加載
model worker時(shí),系統(tǒng)會(huì)自動(dòng)將模型量化為int4格式,無(wú)需進(jìn)行手動(dòng)轉(zhuǎn)換。
在瀏覽器地址欄輸入
http://<ECS公網(wǎng)IP地址>:7860,進(jìn)入Web頁(yè)面。在頁(yè)面對(duì)話框中,輸入對(duì)話內(nèi)容,即可開(kāi)始AI對(duì)話。