使用第八代Intel實(shí)例部署Qwen-7B-Chat
本文以搭建AI對(duì)話(huà)機(jī)器人為例,介紹如何使用基于英特爾CPU的c8i實(shí)例,基于xFasterTransformer框架部署Qwen-7B-Chat語(yǔ)言模型。
背景信息
通義千問(wèn)-7B(Qwen-7B-Chat)
通義千問(wèn)-7B(Qwen-7B)是阿里云研發(fā)的通義千問(wèn)大模型系列的70億參數(shù)規(guī)模模型。Qwen-7B是基于Transformer的大語(yǔ)言模型,在超大規(guī)模的預(yù)訓(xùn)練數(shù)據(jù)上進(jìn)行訓(xùn)練得到。預(yù)訓(xùn)練數(shù)據(jù)類(lèi)型多樣,覆蓋廣泛,包括大量網(wǎng)絡(luò)文本、專(zhuān)業(yè)書(shū)籍、代碼等。同時(shí),在Qwen-7B 的基礎(chǔ)上,使用對(duì)齊機(jī)制打造了基于大語(yǔ)言模型的AI助手Qwen-7B-Chat。
阿里云第八代Intel CPU實(shí)例
阿里云八代實(shí)例(g8i/c8i/r8i/hfc8i/hfg8i/hfr8i)采用Intel? Xeon? Emerald Rapids或者Intel? Xeon? Sapphire Rapids,該實(shí)例支持使用新的AMX(Advanced Matrix Extensions)指令來(lái)加速AI任務(wù)。相比于上一代實(shí)例,八代實(shí)例在Intel? AMX的加持下,推理和訓(xùn)練性能大幅提升。
xFasterTransformer
xFasterTransformer是由Intel官方開(kāi)源的推理框架,為大語(yǔ)言模型(LLM)在CPU X86平臺(tái)上的部署提供了一種深度優(yōu)化的解決方案,支持多CPU節(jié)點(diǎn)之間的分布式部署方案,使得超大模型在CPU上的部署成為可能。此外,xFasterTransformer提供了C++和Python兩種API接口,涵蓋了從上層到底層的接口調(diào)用,易于用戶(hù)使用并將xFasterTransformer集成到自有業(yè)務(wù)框架中。xFasterTransformer目前支持的模型如下:
Models | Framework | Distribution | |
Pytorch | C++ | ||
ChatGLM | √ | √ | √ |
ChatGLM2 | √ | √ | √ |
ChatGLM3 | √ | √ | √ |
Llama | √ | √ | √ |
Llama2 | √ | √ | √ |
Baichuan | √ | √ | √ |
QWen | √ | √ | √ |
SecLLM(YaRN-Llama) | √ | √ | √ |
Opt | √ | √ | √ |
xFasterTransformer支持多種低精度數(shù)據(jù)類(lèi)型來(lái)加速模型部署。除單一精度以外,還支持混合精度,以更充分地利用CPU的計(jì)算資源和帶寬資源,從而提高大語(yǔ)言模型的推理速度。以下是xFasterTransformer支持的單一精度和混合精度類(lèi)型:
FP16
BF16
INT8
W8A8
INT4
NF4
BF16_FP16
BF16_INT8
BF16_W8A8
BF16_INT4
BF16_NF4
W8A8_INT8
W8A8_int4
W8A8_NF4
Qwen-7B-Chat的代碼依照LICENSE開(kāi)源,免費(fèi)商用需填寫(xiě)商業(yè)授權(quán)申請(qǐng)。您應(yīng)自覺(jué)遵守第三方模型的用戶(hù)協(xié)議、使用規(guī)范和相關(guān)法律法規(guī),并就使用第三方模型的合法性、合規(guī)性自行承擔(dān)相關(guān)責(zé)任。
步驟一:創(chuàng)建ECS實(shí)例
按照界面提示完成參數(shù)配置,創(chuàng)建一臺(tái)ECS實(shí)例。
需要注意的參數(shù)如下,其他參數(shù)的配置,請(qǐng)參見(jiàn)自定義購(gòu)買(mǎi)實(shí)例。
實(shí)例:Qwen-7B-Chat運(yùn)行大概需要16 GiB內(nèi)存以上,為了保證模型運(yùn)行的穩(wěn)定,實(shí)例規(guī)格至少需要選擇ecs.c8i.4xlarge(32 GiB內(nèi)存)。
鏡像:Alibaba Cloud Linux 3.2104 LTS 64位。
公網(wǎng)IP:選中分配公網(wǎng)IPv4地址,帶寬計(jì)費(fèi)模式選擇按使用流量,帶寬峰值設(shè)置為100 Mbps。以加快模型下載速度。
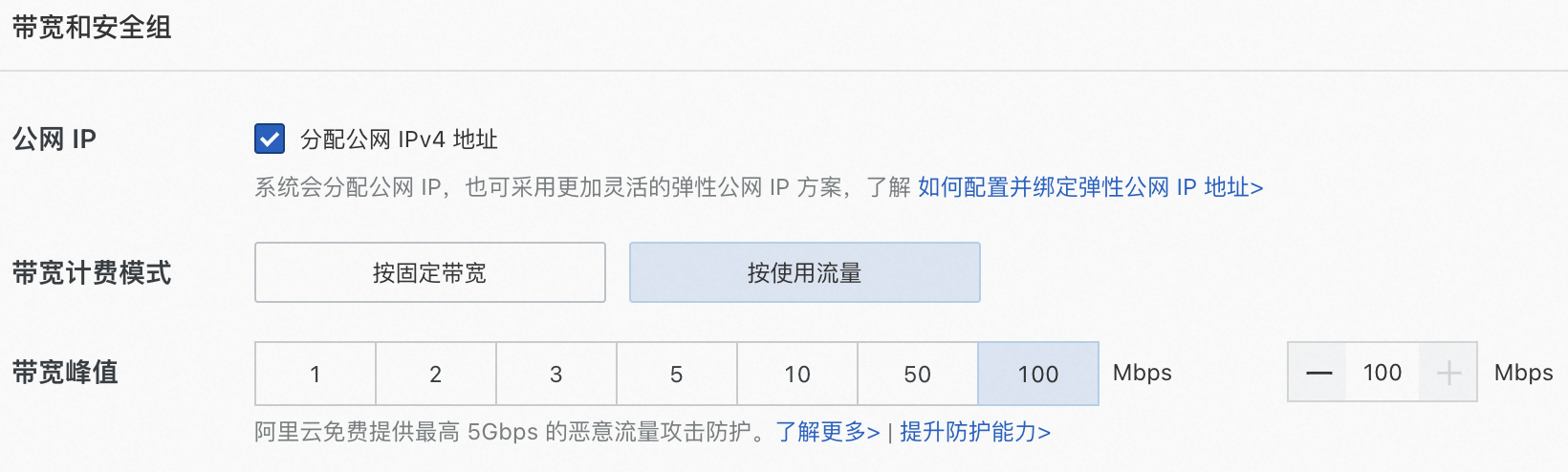
系統(tǒng)盤(pán):Qwen-7B-Chat模型數(shù)據(jù)下載、轉(zhuǎn)換和運(yùn)行過(guò)程中需要占用60 GiB的存儲(chǔ)空間,為了保證模型順利運(yùn)行,建議系統(tǒng)盤(pán)設(shè)置為100 GiB。
添加安全組規(guī)則。
在ECS實(shí)例安全組的入方向添加安全組規(guī)則并放行22端口和7860端口(22端口用于訪(fǎng)問(wèn)SSH服務(wù),7860端口用于訪(fǎng)問(wèn)WebUI頁(yè)面)。具體操作,請(qǐng)參見(jiàn)添加安全組規(guī)則。
步驟二:安裝模型所需容器環(huán)境
遠(yuǎn)程連接該ECS實(shí)例。
具體操作,請(qǐng)參見(jiàn)使用Workbench工具以SSH協(xié)議登錄Linux實(shí)例。
安裝并啟動(dòng)Docker。
具體操作,請(qǐng)參見(jiàn)安裝Docker。
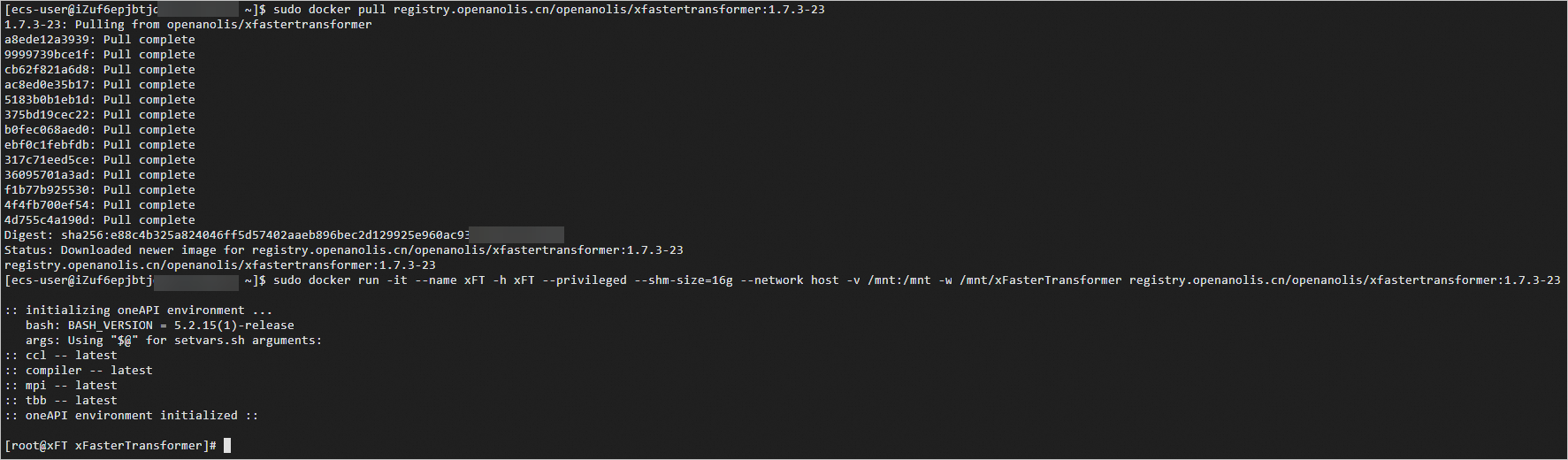
獲取并運(yùn)行Intel xFasterTransformer容器。
sudo docker pull registry.openanolis.cn/openanolis/xfastertransformer:1.7.3-23 sudo docker run -it --name xFT -h xFT --privileged --shm-size=16g --network host -v /mnt:/mnt -w /mnt/xFasterTransformer registry.openanolis.cn/openanolis/xfastertransformer:1.7.3-23當(dāng)出現(xiàn)類(lèi)似如下信息時(shí),表示已獲取并成功運(yùn)行xFasterTransformer容器。
 重要
重要后續(xù)操作都需要在容器中運(yùn)行,如果退出了容器,可以通過(guò)以下命令啟動(dòng)并再次進(jìn)入容器的Shell環(huán)境。
sudo docker start xFT sudo docker exec -it xFT bash(可選)更新xFasterTransformer腳本代碼。
xFasterTransformer鏡像中已包含對(duì)應(yīng)版本的腳本代碼,可以更新升級(jí)到最新的測(cè)試腳本。
yum update -y yum install -y git cd /root/xFasterTransformer git pull
步驟三:準(zhǔn)備模型數(shù)據(jù)
在容器中安裝依賴(lài)軟件。
yum update -y yum install -y wget git git-lfs vim tmux啟用Git LFS。
下載預(yù)訓(xùn)練模型需要Git LFS的支持。
git lfs install創(chuàng)建并進(jìn)入模型數(shù)據(jù)目錄。
mkdir /mnt/data cd /mnt/data創(chuàng)建一個(gè)tmux session。
tmux重要下載預(yù)訓(xùn)練模型耗時(shí)較長(zhǎng),且成功率受網(wǎng)絡(luò)情況影響較大,建議在tmux session中下載,以避免ECS斷開(kāi)連接導(dǎo)致下載模型中斷。
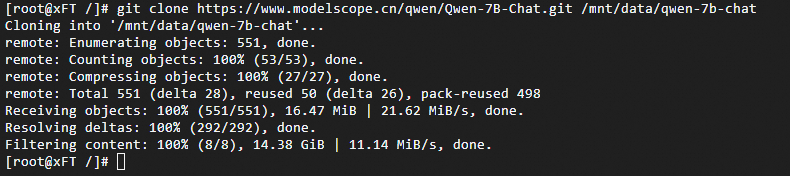
下載Qwen-7B-Chat預(yù)訓(xùn)練模型。
git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat.git /mnt/data/qwen-7b-chat重要在執(zhí)行
git clone命令后,Git將通過(guò)Git LFS開(kāi)始下載倉(cāng)庫(kù)及其所有大文件。這個(gè)過(guò)程可能需要幾分鐘到幾小時(shí)不等,具體取決于模型大小和網(wǎng)絡(luò)條件,請(qǐng)您耐心等待。當(dāng)出現(xiàn)如下信息時(shí),表示預(yù)訓(xùn)練模型已下載成功。
轉(zhuǎn)換模型數(shù)據(jù)。
由于下載的模型數(shù)據(jù)是HuggingFace格式,需要轉(zhuǎn)換成xFasterTransformer格式。生成的模型文件夾為
/mnt/data/qwen-7b-chat-xft。python -c 'import xfastertransformer as xft; xft.QwenConvert().convert("/mnt/data/qwen-7b-chat")'當(dāng)出現(xiàn)如下信息時(shí),表示模型轉(zhuǎn)換成功。
 說(shuō)明
說(shuō)明不同的模型數(shù)據(jù)使用的Convert類(lèi)不同,xFasterTransformer支持以下模型轉(zhuǎn)換類(lèi):
LlamaConvert
ChatGLMConvert
ChatGLM2Convert
ChatGLM3Convert
OPTConvert
BaichuanConvert
QwenConvert
步驟四:運(yùn)行模型進(jìn)行AI對(duì)話(huà)
在Web頁(yè)面中進(jìn)行對(duì)話(huà)
在容器中,依次執(zhí)行以下命令,安裝WebUI相關(guān)依賴(lài)軟件。
cd /root/xFasterTransformer/examples/web_demo pip install -r requirements.txt執(zhí)行以下命令,升級(jí)gradio以避免與fastapi的沖突。
pip install --upgrade gradio執(zhí)行以下命令,啟動(dòng)WebUI。
OMP_NUM_THREADS=$(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') / 2)) GRADIO_SERVER_NAME="0.0.0.0" numactl -C $(seq -s, 0 2 $(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') - 2))) -m 0 python Qwen.py -t /mnt/data/qwen-7b-chat -m /mnt/data/qwen-7b-chat-xft -d bf16當(dāng)出現(xiàn)如下信息時(shí),表示W(wǎng)ebUI服務(wù)啟動(dòng)成功。

在瀏覽器地址欄輸入
http://<ECS公網(wǎng)IP地址>:7860,進(jìn)入Web頁(yè)面。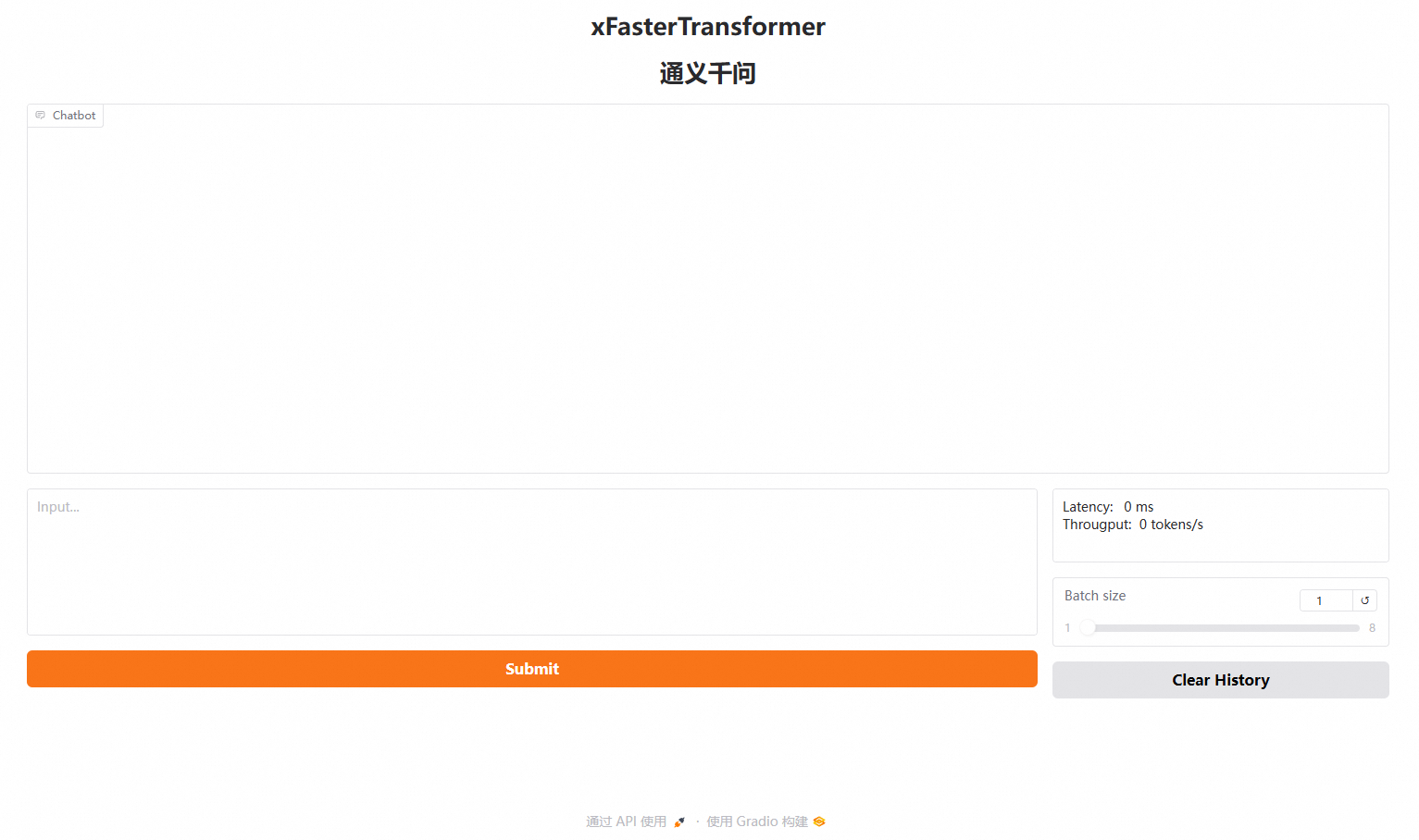
在頁(yè)面對(duì)話(huà)框中,輸入對(duì)話(huà)內(nèi)容,然后單擊Submit,即可進(jìn)行AI對(duì)話(huà)。
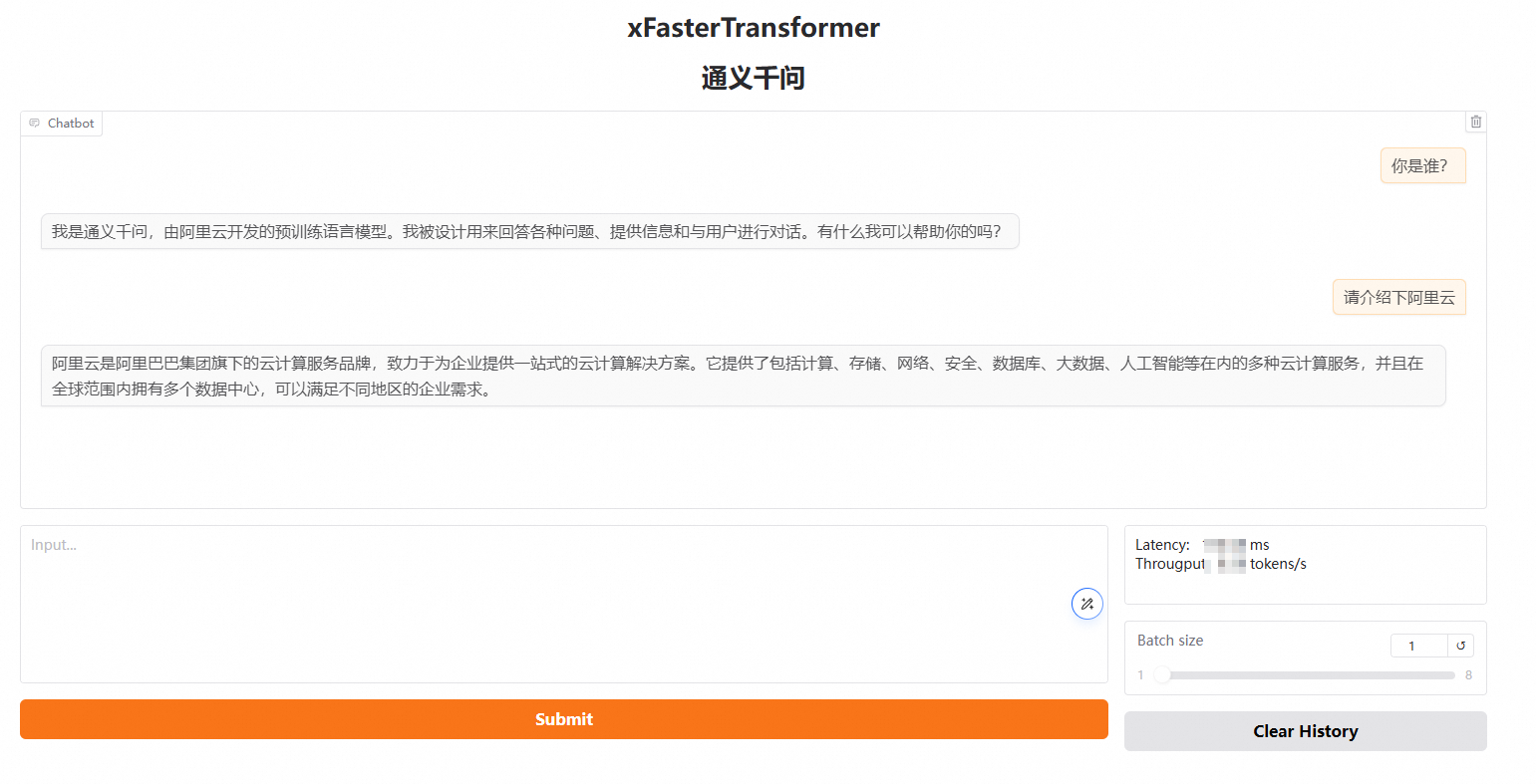
在實(shí)例終端進(jìn)行對(duì)話(huà)
執(zhí)行以下命令,啟動(dòng)AI對(duì)話(huà)程序。
cd /root/xFasterTransformer/examples/pytorch
OMP_NUM_THREADS=$(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') / 2)) LD_PRELOAD=libiomp5.so numactl -C $(seq -s, 0 2 $(($(lscpu | grep "^CPU(s):" | awk '{print $NF}') - 2))) -m 0 python demo.py -t /mnt/data/qwen-7b-chat -m /mnt/data/qwen-7b-chat-xft -d bf16 --chat true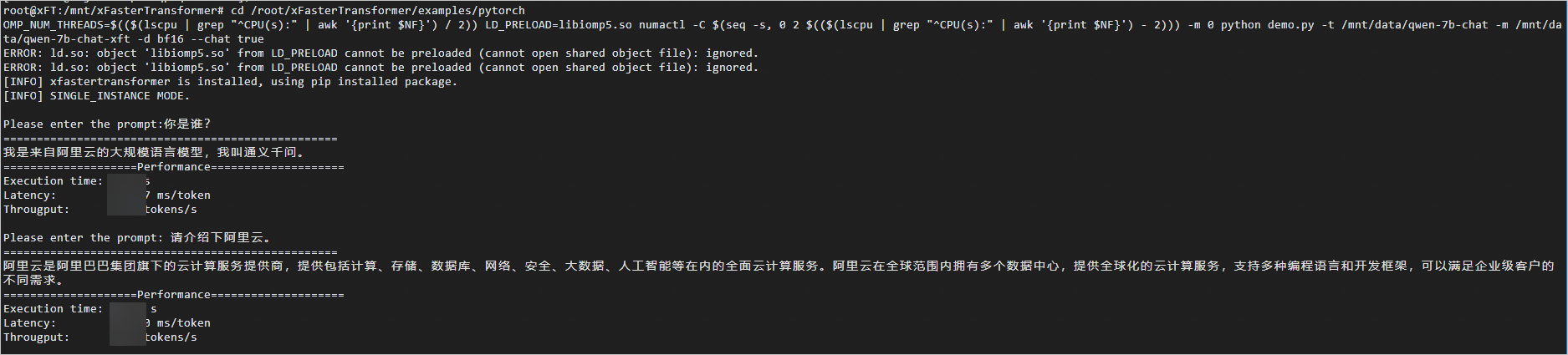
Benchmark模型性能
運(yùn)行benchmark腳本時(shí)默認(rèn)使用的是假模型數(shù)據(jù),因此不需要準(zhǔn)備模型數(shù)據(jù)。您執(zhí)行以下指令來(lái)測(cè)試模型性能。
cd /root/xFasterTransformer/benchmark
XFT_CLOUD_ENV=1 bash run_benchmark.sh -m qwen-7b -d bf16 -bs 1 -in 32 -out 32 -i 10通過(guò)調(diào)整運(yùn)行參數(shù),來(lái)測(cè)試指定場(chǎng)景下的性能數(shù)據(jù):
-d 或 --dtype選擇模型量化類(lèi)型:
bf16 (default)
bf16_fp16
int8
bf16_int8
fp16
bf16_int4
int4
bf16_nf4
nf4
bf16_w8a8
w8a8
w8a8_int8
w8a8_int4
w8a8_nf4
-bs或--batch_size選擇batch size大小,默認(rèn)為1。
-in或--input_tokens選擇輸入長(zhǎng)度,自定義長(zhǎng)度請(qǐng)?jiān)趐rompt.json中配置對(duì)應(yīng)的prompt,默認(rèn)為32。
-out或--output_tokens選擇生成長(zhǎng)度,默認(rèn)為32。
-i或--iter選擇迭代次數(shù),迭代次數(shù)越大,等待測(cè)試結(jié)果的時(shí)間越長(zhǎng),默認(rèn)為10次。
運(yùn)行結(jié)果展示如下:
