使用基于英特爾CPU的g8i實(shí)例加速Stable Diffusion推理
本文介紹如何使用基于Intel CPU的g8i實(shí)例,以DreamShaper8_LCM(基于Stable Diffusion v1-5微調(diào)后得到的模型)模型為例,結(jié)合系統(tǒng)級(jí)優(yōu)化及IPEX技術(shù)加速文生圖模型的推理速度,在Intel CPU云服務(wù)器上搭建高效的文生圖服務(wù)。
背景信息
Stable Diffusion模型
Stable Diffusion模型是文本到圖像的潛在擴(kuò)散模型,它可以根據(jù)文本提示詞生成對(duì)應(yīng)的圖像,目前已經(jīng)可以應(yīng)用于包括計(jì)算機(jī)視覺(jué)、數(shù)字藝術(shù)、視頻游戲等多種領(lǐng)域和場(chǎng)景。為了更好的用戶體驗(yàn),我們期望能獲得在幾秒鐘內(nèi)生成高質(zhì)量圖像的能力。這種秒級(jí)生成圖像的能力可用于許多場(chǎng)景,如2C的應(yīng)用程序、營(yíng)銷和媒體領(lǐng)域的內(nèi)容生成,或生成合成數(shù)據(jù)以擴(kuò)充數(shù)據(jù)集。
阿里云第八代企業(yè)級(jí)實(shí)例g8i
阿里云第八代企業(yè)級(jí)通用計(jì)算實(shí)例g8i采用CIPU+飛天技術(shù)架構(gòu),搭載Intel最新一代至強(qiáng)可擴(kuò)展處理器(Intel? Xeon? Emerald Rapids或者Intel? Xeon? Sapphire Rapids),性能進(jìn)一步提升。同時(shí),ECS g8i實(shí)例擁有AMX加持的AI能力增強(qiáng),擁有AI增強(qiáng)和全面安全防護(hù)的兩大特色優(yōu)勢(shì)。更多信息,請(qǐng)參見(jiàn)通用型實(shí)例規(guī)格族g8i。
購(gòu)買(mǎi)該實(shí)例時(shí),系統(tǒng)將隨機(jī)分配上述兩種處理器之一,不支持手動(dòng)選擇。
IPEX
Intel? Extension for PyTorch(IPEX)是由Intel開(kāi)源并維護(hù)的一個(gè)PyTorch擴(kuò)展庫(kù),使用IPEX可以充分利用英特爾CPU上的硬件加速功能,包括AVX-512、矢量神經(jīng)網(wǎng)絡(luò)指令(Vector Neural Network Instructions,AVX512 VNNI)以及先進(jìn)矩陣擴(kuò)展 (AMX),大幅度提升了使用PyTorch在Intel處理器上運(yùn)行AI應(yīng)用,尤其是深度學(xué)習(xí)應(yīng)用的性能。Intel正不斷為PyTorch貢獻(xiàn)IPEX的優(yōu)化性能,為PyTorch社區(qū)提供最新的Intel硬件和軟件改進(jìn)。更多信息,請(qǐng)參見(jiàn)IPEX。
阿里云不對(duì)第三方模型“Stable Diffusion”和“DreamShaper8_LCM”的合法性、安全性、準(zhǔn)確性進(jìn)行任何保證,阿里云不對(duì)由此引發(fā)的任何損害承擔(dān)責(zé)任。
您應(yīng)自覺(jué)遵守第三方模型的用戶協(xié)議、使用規(guī)范和相關(guān)法律法規(guī),并就使用第三方模型的合法性、合規(guī)性自行承擔(dān)相關(guān)責(zé)任。
本文的示例服務(wù)僅用于教程實(shí)踐、功能測(cè)試等場(chǎng)景,其結(jié)果數(shù)據(jù)僅為參考值,實(shí)際數(shù)據(jù)可能會(huì)因您的操作環(huán)境而發(fā)生變化。
部署并加速文生圖服務(wù)
準(zhǔn)備環(huán)境與模型
創(chuàng)建ECS實(shí)例
按照界面提示完成參數(shù)配置,創(chuàng)建一臺(tái)ECS實(shí)例。
需要注意的參數(shù)如下,其他參數(shù)的配置,請(qǐng)參見(jiàn)自定義購(gòu)買(mǎi)實(shí)例。
實(shí)例:為了保證模型運(yùn)行的穩(wěn)定,建議實(shí)例規(guī)格至少選擇ecs.g8i.4xlarge(16 vCPU)。
鏡像:Alibaba Cloud Linux 3.2104 LTS 64位。
公網(wǎng)IP:選中分配公網(wǎng)IPv4地址,帶寬計(jì)費(fèi)模式選擇按使用流量,帶寬峰值設(shè)置為100 Mbps。以加快模型下載速度。
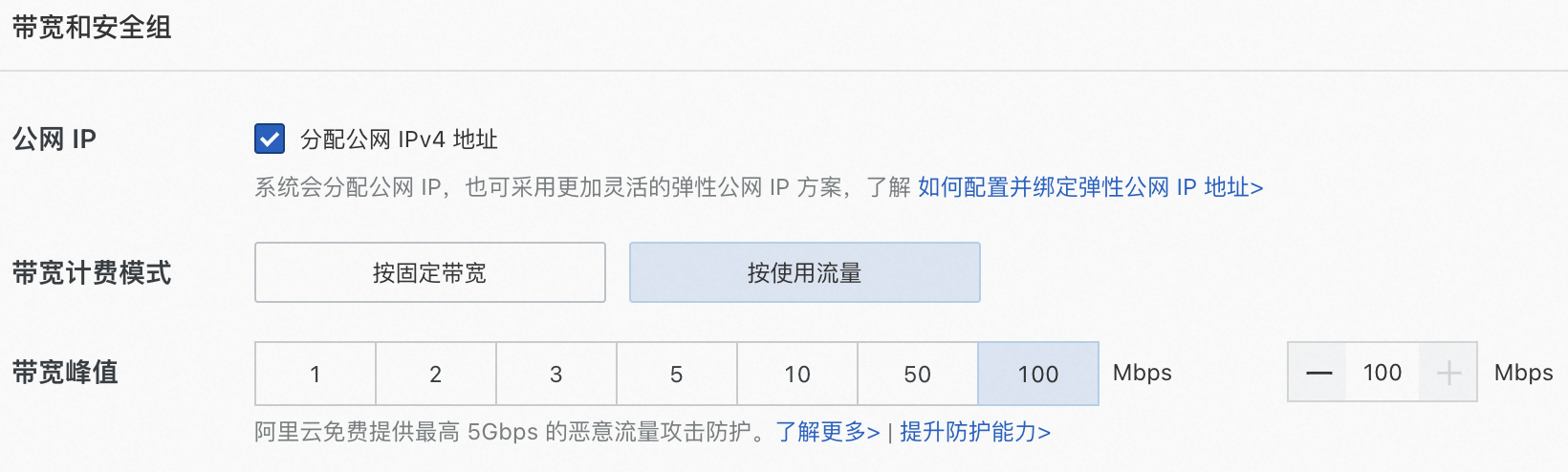
系統(tǒng)盤(pán):模型數(shù)據(jù)下載、轉(zhuǎn)換和運(yùn)行過(guò)程中需要較大存儲(chǔ)空間,為了保證模型順利運(yùn)行,建議系統(tǒng)盤(pán)設(shè)置為100 GiB。
添加安全組規(guī)則。
在ECS實(shí)例安全組的入方向添加安全組規(guī)則并放行22端口(用于訪問(wèn)SSH服務(wù))。具體操作,請(qǐng)參見(jiàn)添加安全組規(guī)則。
下載并安裝Anaconda。
運(yùn)行如下命令,下載Anaconda安裝腳本。
wget https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh運(yùn)行如下命令,安裝Anaconda安裝腳本。
bash Anaconda3-2023.09-0-Linux-x86_64.sh安裝過(guò)程中會(huì)出現(xiàn)確認(rèn)安裝協(xié)議、初始化conda到當(dāng)前Shell中,請(qǐng)按以下操作執(zhí)行。
出現(xiàn)Please,press ENTER to continue時(shí),按一下Enter鍵。
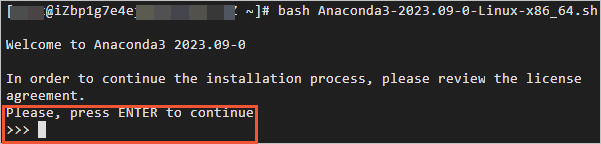
多次按Enter鍵,出現(xiàn)Do you accept the license terms? [yes/no]時(shí),輸入yes。

出現(xiàn)如下圖所示時(shí),按Enter將conda安裝到當(dāng)前目錄,或輸入您想要安裝conda的目錄。
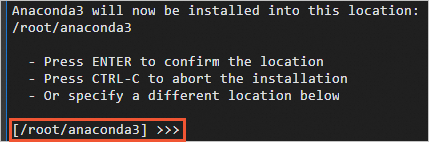
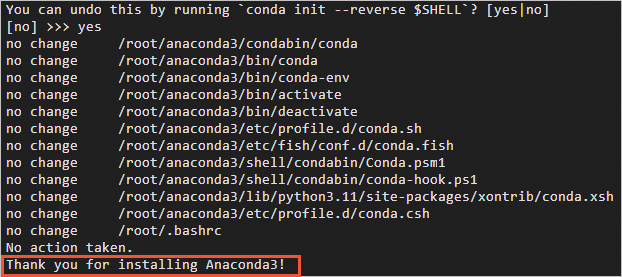
出現(xiàn)You can undo this by running 'conda init --reverse $SHELL'? [yes/no]時(shí),輸入yes。

出現(xiàn)Thank you for installing Anconda時(shí),說(shuō)明Anconda已安裝完成。
執(zhí)行如下命令,使Anaconda相關(guān)的環(huán)境變量生效。
source ~/.bashrc
創(chuàng)建一個(gè)包含Transformers、Diffusers、Accelerate、PyTorch以及IPEX庫(kù)的虛擬環(huán)境。
conda create -n sd_inference python=3.9 -y conda activate sd_inference pip install pip --upgrade pip install transformers diffusers accelerate torch==2.1.1 intel_extension_for_pytorch==2.1.100使用huggingface-cli下載預(yù)訓(xùn)練模型Lykon/dreamshaper-8-lcm。
mkdir /home/hf_models cd /home/hf_models/ pip install -U huggingface_hub pip install -U hf-transfer export HF_ENDPOINT=https://hf-mirror.com export HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download --resume-download --local-dir-use-symlinks False Lykon/dreamshaper-8-lcm --local-dir dreamshaper-8-lcm
運(yùn)行模型
創(chuàng)建ds8_lcm_pipe.py。
執(zhí)行如下命令,創(chuàng)建并打開(kāi)ds8_lcm_pipe.py。
vim ds8_lcm_pipe.py該腳本用于測(cè)試單張圖像生成的平均時(shí)延,在腳本中輸入以下兩部分內(nèi)容:
基準(zhǔn)測(cè)試函數(shù),用于統(tǒng)計(jì)單張圖像生成的平均時(shí)延。
import time def elapsed_time(pipeline, prompt, height=512, width=512, guidance_scale=2, test_loops=3, num_inference_steps=10): # warmup images = pipeline(prompt, num_inference_steps=10, height=height, width=width, guidance_scale=guidance_scale).images start = time.time() for _ in range(test_loops): _ = pipeline(prompt, num_inference_steps=num_inference_steps, height=height, width=width, guidance_scale=guidance_scale) end = time.time() return (end - start) / test_loops用默認(rèn)的float32數(shù)據(jù)類型構(gòu)建一個(gè)StableDiffusionPipeline。
from diffusers import StableDiffusionPipeline, LCMScheduler import torch model_id = "/home/hf_models/dreamshaper-8-lcm" pipe = StableDiffusionPipeline.from_pretrained(model_id) pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config) prompt = "portrait photo of muscular bearded guy in a worn mech suit, light bokeh, intricate, steel metal, elegant, sharp focus, soft lighting, vibrant colors " generator = torch.manual_seed(0) image = pipe(prompt, num_inference_steps=10, height=512, width=512, guidance_scale=2, generator=generator).images[0] image.save("./fp32_image.png") latency = elapsed_time(pipe, prompt, height=512, width=512, guidance_scale=2) print("Using data type FP32, average latency for a test loop (10 steps) is ", latency, " s.")
ds8_lcm_pipe.py腳本的完整內(nèi)容如下:
import time from diffusers import StableDiffusionPipeline, LCMScheduler import torch # 定義基準(zhǔn)測(cè)試函數(shù) def elapsed_time(pipeline, prompt, height=512, width=512, guidance_scale=2, test_loops=3, num_inference_steps=10): # warmup images = pipeline(prompt, num_inference_steps=10, height=height, width=width, guidance_scale=guidance_scale).images start = time.time() for _ in range(test_loops): _ = pipeline(prompt, num_inference_steps=num_inference_steps, height=height, width=width, guidance_scale=guidance_scale) end = time.time() return (end - start) / test_loops # 構(gòu)建StableDiffusionPipeline并測(cè)試 model_id = "/home/hf_models/dreamshaper-8-lcm" pipe = StableDiffusionPipeline.from_pretrained(model_id) pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config) prompt = "portrait photo of muscular bearded guy in a worn mech suit, light bokeh, intricate, steel metal, elegant, sharp focus, soft lighting, vibrant colors" generator = torch.manual_seed(0) image = pipe(prompt, num_inference_steps=10, height=512, width=512, guidance_scale=2, generator=generator).images[0] image.save("./fp32_image.png") latency = elapsed_time(pipe, prompt, height=512, width=512, guidance_scale=2) print("Using data type FP32, average latency for a test loop (10 steps) is ", latency, " s.")按
Esc鍵,輸入:wq,按Enter鍵,退出并保存腳本。
使用jemalloc優(yōu)化圖片生成速度。
圖像生成是一種內(nèi)存密集型操作,通過(guò)安裝高性能內(nèi)存分配庫(kù),能夠加速內(nèi)存操作并使之能在CPU之間并行處理。jemalloc和tcmalloc是兩個(gè)常用的內(nèi)存優(yōu)化庫(kù)。此處使用jemalloc,jemalloc可以用于針對(duì)特定工作負(fù)載進(jìn)行調(diào)優(yōu),如最大化CPU利用率。更多信息,請(qǐng)參見(jiàn) jemalloc調(diào)優(yōu)指南。
安裝jemalloc并設(shè)置環(huán)境變量。
重要export CONDA_LOCATION后的/path_to_your_conda_environment_location請(qǐng)?jiān)O(shè)置為實(shí)際的Anaconda安裝路徑。conda install jemalloc -y export CONDA_LOCATION=/path_to_your_conda_environment_location export LD_PRELOAD=$LD_PRELOAD:$CONDA_LOCATION/lib/libjemalloc.so export MALLOC_CONF="oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms: 60000,muzzy_decay_ms:60000"安裝intel-openmp并設(shè)置環(huán)境變量。
重要OMP_NUM_THREADS后的數(shù)字請(qǐng)修改為當(dāng)前實(shí)例的物理CPU核數(shù)。
pip install intel-openmp export LD_PRELOAD=$LD_PRELOAD:$CONDA_LOCATION/lib/libiomp5.so export OMP_NUM_THREADS=16
安裝numactl并運(yùn)行ds8_lcm_pipe.py腳本。
yum install numactl -y numactl -C 0-15 python ds8_lcm_pipe.py執(zhí)行結(jié)果如下,表示單張圖片生成速度約為21 S。

加速圖片生成速度
為了更好地發(fā)揮EMR CPU性能,可以將IPEX優(yōu)化應(yīng)用到pipeline的每個(gè)模塊,并使用bfloat16數(shù)據(jù)類型。
執(zhí)行如下命令,打開(kāi)ds8_lcm_pipe.py腳本。
vim ds8_lcm_pipe.py對(duì)ds8_lcm_pipe.py進(jìn)行如下修改。
使用IPEX優(yōu)化pipeline的每個(gè)模塊。
對(duì)于StableDiffusionPipeline,需要將IPEX優(yōu)化應(yīng)用到pipeline的每個(gè)模塊,優(yōu)化點(diǎn)包括將數(shù)據(jù)格式轉(zhuǎn)換為channels-last格式、調(diào)用ipex.optimize函數(shù)并使用TorchScript mode等。Intel已將該優(yōu)化pipeline提交pull request到diffusers庫(kù),作為一個(gè)custom_pipeline可以直接被客戶調(diào)用。具體優(yōu)化細(xì)節(jié),請(qǐng)參見(jiàn)Stable Diffusion on IPEX。
在使用層面,需要做的代碼修改非常簡(jiǎn)單:
在load pipe時(shí)配置custom_pipeline="stable_diffusion_ipex"。
對(duì)custom_pipeline調(diào)用prepare_for_ipex函數(shù)。
custom_pipe = StableDiffusionPipeline.from_pretrained(model_id, custom_pipeline="stable_diffusion_ipex") #value of image height/width should be consistent with the pipeline inference custom_pipe.prepare_for_ipex(prompt, dtype=torch.float32, height=512, width=512)
優(yōu)化EMR CPU上的AMX加速器
為了利用EMR CPU上的AMX 加速器,可以借助Automatic Mixed Precision Package使用bfloat16數(shù)據(jù)類型。
custom_pipe = StableDiffusionPipeline.from_pretrained(model_id, custom_pipeline="stable_diffusion_ipex") #value of image height/width should be consistent with the pipeline inference custom_pipe.prepare_for_ipex(prompt, dtype=torch.bfloat16, height=512, width=512) with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16): image = custom_pipe (prompt, num_inference_steps=10, height=512, width=512, guidance_scale=2, generator=generator).images[0] image.save("./bf16_opt_image.png") latency = elapsed_time(custom_pipe, prompt, height=512, width=512, guidance_scale=2) print("Using data type BF16, average latency for a test loop (10 steps) w/ optimized pipeline is ", latency, " s.")
修改后的ds8_lcm_pipe.py腳本內(nèi)容如下:
import time import torch from diffusers import StableDiffusionPipeline def elapsed_time(pipeline, prompt, height=512, width=512, guidance_scale=2, test_loops=3, num_inference_steps=10): # warmup images = pipeline(prompt, num_inference_steps=10, height=height, width=width, guidance_scale=guidance_scale).images start = time.time() for _ in range(test_loops): _ = pipeline(prompt, num_inference_steps=num_inference_steps, height=height, width=width, guidance_scale=guidance_scale) end = time.time() return (end - start) / test_loops model_id = "/home/hf_models/dreamshaper-8-lcm" prompt = "portrait photo of muscular bearded guy in a worn mech suit, light bokeh, intricate, steel metal, elegant, sharp focus, soft lighting, vibrant colors" custom_pipe = StableDiffusionPipeline.from_pretrained(model_id, custom_pipeline="stable_diffusion_ipex") custom_pipe.prepare_for_ipex(prompt, dtype=torch.bfloat16, height=512, width=512) generator = torch.manual_seed(0) custom_pipe.to(torch.bfloat16) with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16): image = custom_pipe(prompt, num_inference_steps=10, height=512, width=512, guidance_scale=2, generator=generator).images[0] image.save("./bf16_opt_image.png") latency = elapsed_time(custom_pipe, prompt, height=512, width=512, guidance_scale=2) print("Using data type BF16, average latency for a test loop (10 steps) w/ optimized pipeline is ", latency, " s.")按
Esc鍵,輸入:wq,按Enter鍵,退出并保存腳本。運(yùn)行ds8_lcm_pipe.py腳本。
numactl -C 0-15 python ds8_lcm_pipe.py執(zhí)行結(jié)果如下,表示單張圖片生成速度約為7 S。
