在EMR Serverless Spark中使用DLF Catalog
本文主要介紹了在EMR Serverless Spark環(huán)境下有效集成與利用DLF 2.0 Catalog的步驟,幫助您實(shí)現(xiàn)高效的元數(shù)據(jù)管理及數(shù)據(jù)讀寫操作。
前提條件
已創(chuàng)建DLF 2.0數(shù)據(jù)目錄。如未創(chuàng)建,詳情請(qǐng)參見(jiàn)創(chuàng)建數(shù)據(jù)目錄。
步驟一:綁定DLF 2.0 Catalog
單擊創(chuàng)建工作空間,填寫配置信息。詳情請(qǐng)參見(jiàn)創(chuàng)建工作空間。
DLF作為元數(shù)據(jù)服務(wù)默認(rèn)開(kāi)啟,在下拉列表中選擇DLF 2.0的Catalog。
勾選服務(wù)協(xié)議,單擊創(chuàng)建工作空間,完成工作空間創(chuàng)建和Catalog綁定。
步驟二:Catalog授權(quán)
在Catalog列表頁(yè)面,單擊Catalog名稱。
單擊權(quán)限頁(yè)簽,單擊授權(quán)。
選擇對(duì)用戶授權(quán),在授權(quán)用戶下拉列表中選擇AliyunEMRSparkJobRunDefaultRole。
預(yù)置權(quán)限類型選擇Data Editor,單擊確定。
步驟三:讀寫數(shù)據(jù)
創(chuàng)建數(shù)據(jù)庫(kù)
在Spark頁(yè)面,單擊目標(biāo)工作空間名稱。
在EMR Serverless Spark頁(yè)面,單擊左側(cè)導(dǎo)航欄中的數(shù)據(jù)開(kāi)發(fā),進(jìn)入開(kāi)發(fā)目錄。
在開(kāi)發(fā)目錄頁(yè)簽下,單擊新建。
在彈出的對(duì)話框中,輸入名稱,類型選擇SQL > SparkSQL,然后單擊確定。
創(chuàng)建開(kāi)發(fā)任務(wù)詳情,請(qǐng)參見(jiàn)SQL開(kāi)發(fā)快速入門。
運(yùn)行以下SQL,創(chuàng)建數(shù)據(jù)庫(kù)。
說(shuō)明SQL會(huì)話的引擎版本需為esr-2.3 (Spark 3.4.2, Scala 2.12)及以上。
CREATE DATABASE IF NOT EXISTS spark_demo;
創(chuàng)建數(shù)據(jù)表
運(yùn)行以下SQL,創(chuàng)建數(shù)據(jù)表。
USE spark_demo;
CREATE TABLE IF NOT EXISTS average_clicks_by_consumption (
pvalue_level INT,
average_clicks FLOAT
)
USING paimon TBLPROPERTIES (
'format' = 'parquet',
'metastore.partitioned-table' = 'true',
'primary-key' = 'date,pvalue_level'
)
PARTITIONED BY (date STRING);插入數(shù)據(jù)
運(yùn)行以下SQL,插入數(shù)據(jù)。
INSERT INTO average_clicks_by_consumption (date, pvalue_level, average_clicks)
VALUES
('2023-04-01', 1, 100.5),
('2023-05-01', 2, 150.2),
('2023-06-01', 3, 200.1);查詢數(shù)據(jù)
運(yùn)行以下SQL,查詢數(shù)據(jù)。
SELECT * FROM average_clicks_by_consumption;步驟四:在DLF中查看元數(shù)據(jù)
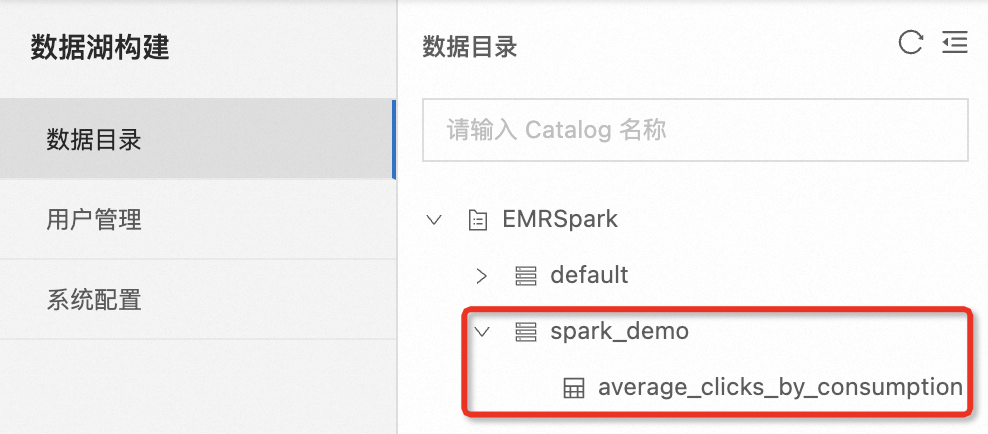
當(dāng)您運(yùn)行成功之后,您可在數(shù)據(jù)湖構(gòu)建控制臺(tái)看到新增的庫(kù)、表元數(shù)據(jù)信息。其中EMRSpark是本例中的示例Catalog名稱。