EMR Serverless Spark支持通過SQL代碼編輯和運行任務。本文帶您快速體驗SQL的創建、啟動和運維等操作。
前提條件
已準備阿里云賬號,詳情請參見賬號注冊。
步驟一:創建并發布開發任務
任務必須先發布,然后才能在任務編排過程中使用。
進入數據開發頁面。
在左側導航欄,選擇。
在Spark頁面,單擊目標工作空間名稱。
在EMR Serverless Spark頁面,單擊左側導航欄中的數據開發。
新建users_task任務。
在開發目錄頁簽下,單擊新建。
在新建對話框中,輸入名稱(例如users_task),類型使用默認的SparkSQL,然后單擊確定。
拷貝如下代碼到新增的Spark SQL頁簽(users_task)中。
CREATE TABLE IF NOT EXISTS students ( name VARCHAR(64), address VARCHAR(64) ) USING PARQUET PARTITIONED BY (data_date STRING); INSERT OVERWRITE TABLE students PARTITION (data_date = '${ds}') VALUES ('Ashua Hill', '456 Erica Ct, Cupertino'), ('Brian Reed', '723 Kern Ave, Palo Alto');目前支持以下基礎日期變量,默認為昨天。
變量
數據類型
說明
{data_date}
str
表示日期信息的變量,格式為
YYYY-MM-DD。例如,2023-09-18。
{ds}
str
{dt}
str
{data_date_nodash}
str
表示日期信息的變量,格式為
YYYYMMDD。例如,20230918。
{ds_nodash}
str
{dt_nodash}
str
{ts}
str
表示時間戳,格式為
YYYY-MM-DDTHH:MM:SS。例如,2023-09-18T16:07:43。
{ts_nodash}
str
表示時間戳,格式為
YYYYMMDDHHMMSS。例如,20230918160743。
在數據庫下拉列表中選擇一個數據庫,在會話下拉列表中選擇一個已啟動的會話實例。
您也可以在下拉列表中選擇創建SQL會話,直接創建一個新的會話實例。會話管理更多介紹,請參見管理SQL會話。
單擊運行,執行創建的任務。
返回結果信息可以在下方的運行結果中查看。如果有異常,則可以在運行問題中查看。
發布users_task任務。
說明任務指定的參數會伴隨任務一起發布,并成為產線運行任務時使用的參數;而在SQL編輯器中執行的任務則使用會話中的參數。
在新增的Spark SQL頁簽中,單擊發布。
在彈出的對話框中,可以輸入發布信息,然后單擊確定。
新建users_count任務。
在開發目錄頁簽下,單擊新建 。
在新建對話框中,輸入名稱(例如users_count),類型使用默認的SparkSQL,單擊確定。
拷貝如下代碼到新增的Spark SQL任務頁簽(users_count)中。
SELECT COUNT(1) FROM students;在數據庫下拉列表中選擇一個數據庫,在會話下拉列表中選擇一個已啟動的會話實例。
您也可以在下拉列表中選擇創建SQL會話,直接創建一個新的會話實例。會話管理更多介紹,請參見管理SQL會話。
單擊運行,執行創建的任務。
返回結果信息可以在下方的運行結果中查看。如果有異常,則可以在運行問題中查看。
發布users_count任務。
說明任務指定的參數會伴隨任務一起發布,并成為產線運行任務時使用的參數;而在SQL編輯器中執行的任務則使用會話中的參數。
在新增的Spark SQL任務頁簽中,單擊發布。
在彈出的對話框中,可以輸入發布信息,然后單擊確定。
步驟二:創建工作流及其節點
在左側導航欄中,單擊任務編排。
在任務編排頁面,單擊創建工作流。
在創建工作流面板中,輸入工作流名稱(例如,spark_workflow_task),然后單擊下一步。
其他設置區域的參數,請根據您的實際情況配置,更多參數信息請參見管理工作流。
添加users_task節點。
在新建的節點畫布中,單擊添加節點。
彈出添加節點面板,在來源文件路徑下拉列表中選擇已發布的任務users_task,然后單擊保存。
添加users_count節點。
單擊添加節點。
彈出添加節點面板,在來源文件路徑下拉列表中選擇已發布的任務users_count,在上游節點下拉列表中選擇users_task,單擊保存。
在新建的節點畫布中,單擊發布工作流。
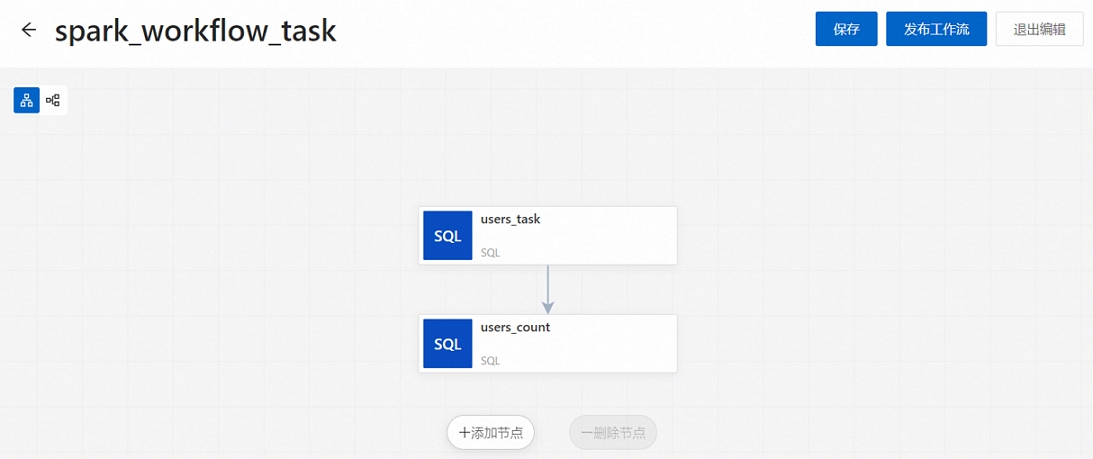
在發布對話框中,可以輸入發布信息,然后單擊確定。
步驟三:運行工作流
在任務編排頁面,單擊新建工作流(例如,spark_workflow_task)的工作流名稱。
在工作流實例列表頁面,單擊手動運行。
說明在配置了調度周期后,您也可以在任務編排頁面通過左側的開關按鈕啟動調度。
在觸發運行對話框中,單擊確定。
步驟四:查看實例狀態
在任務編排頁面,單擊目標工作流名稱(例如,spark_workflow_task)。
在工作流實例列表頁面,您可以查看對應的所有工作流實例,以及各工作流實例的運行時間、運行狀態等。
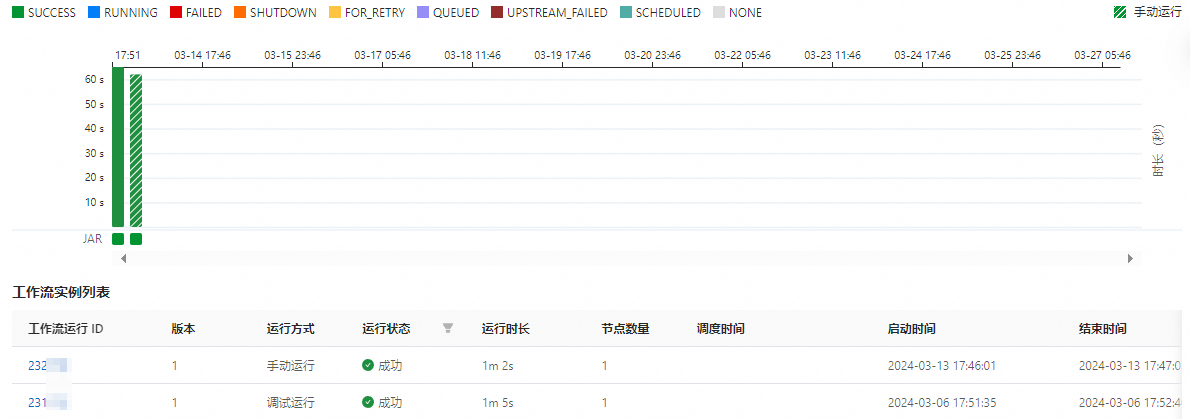
單擊工作流實例列表區域的工作流運行ID,或單擊上方的工作流實例圖頁簽,可以查看對應的工作流實例圖。
單擊目標節點實例,在彈出的節點信息框中,您可以根據需要操作或查看信息。
關于此部分內容的相關操作及詳細介紹,請參見查看節點實例。
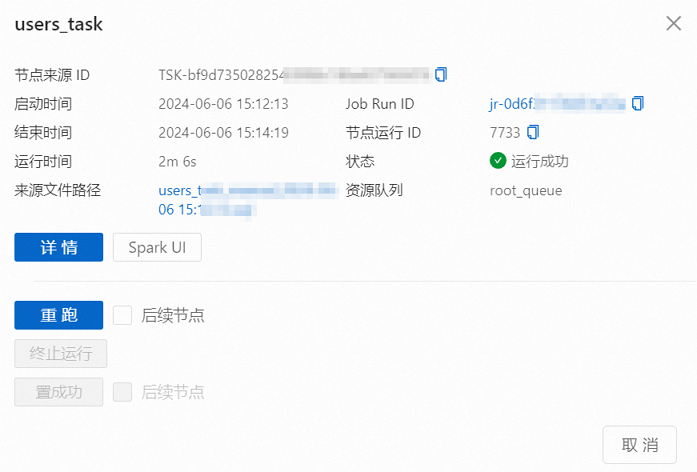
例如,單擊Spark UI跳轉至Spark Jobs頁面,可以查看Spark任務的實時信息。
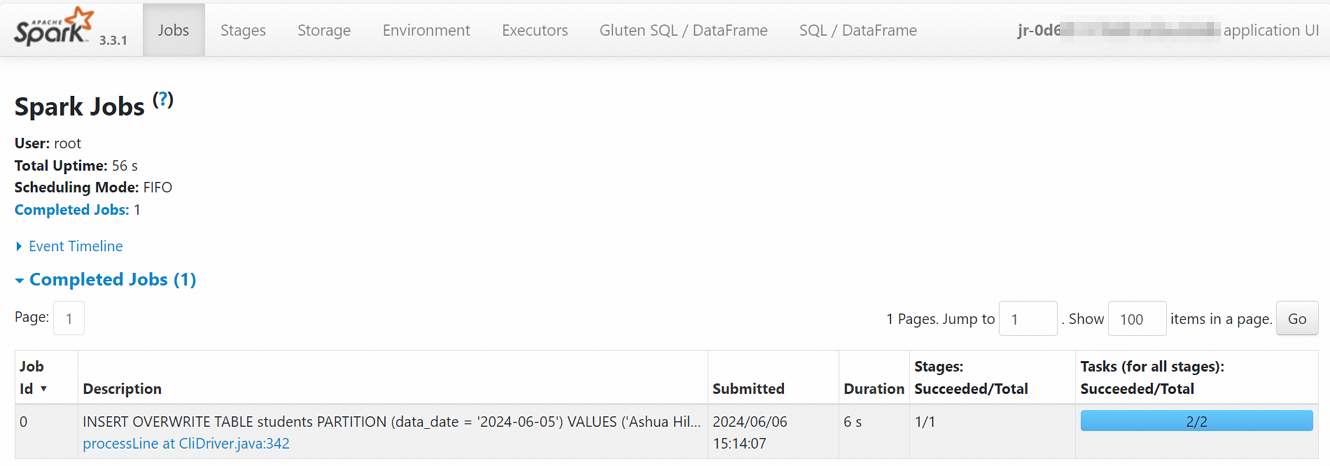
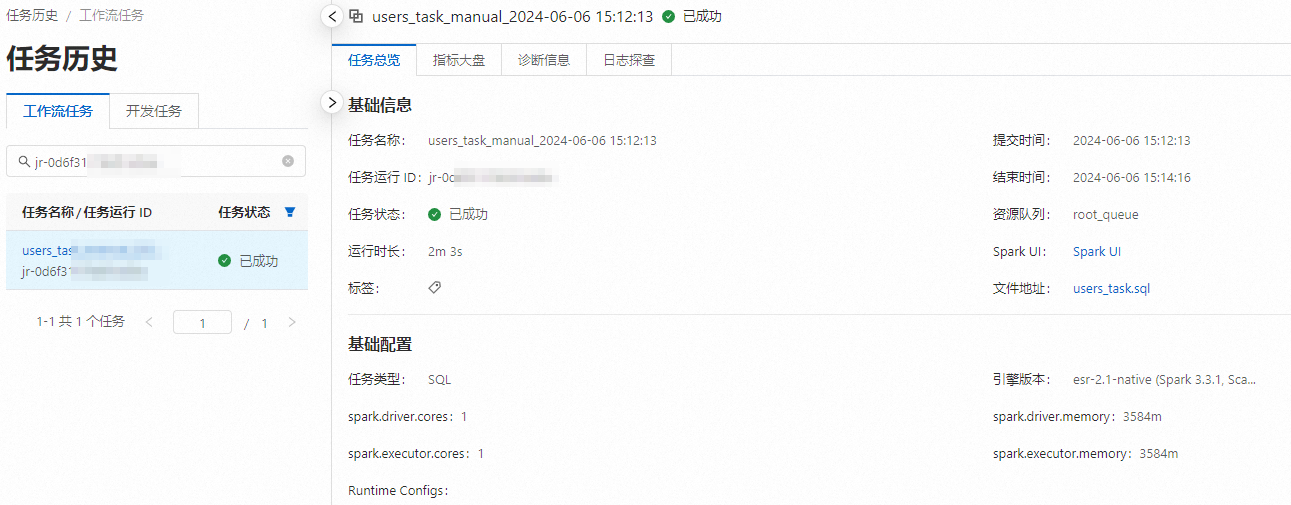
單擊任務運行ID,進入任務歷史頁面,可以查看指標、診斷和日志信息。
步驟五:工作流運維
在任務編排頁面,單擊目標工作流名稱,進入工作流實例列表頁面。您可以:
在工作流信息區域,可以編輯部分參數。
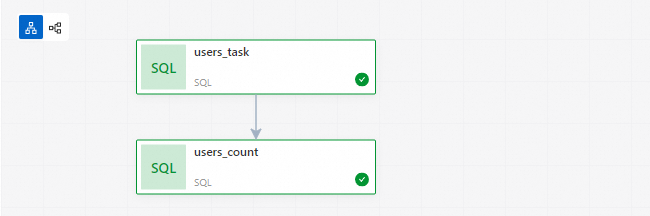
在工作流實例列表區域,可以查看所有工作流。單擊工作流運行ID,可以進入工作流實例圖頁面。
步驟六:查看數據
在左側導航欄中,單擊數據開發。
新建SparkSQL開發,然后輸入并運行以下命令查看表的詳細信息。
SELECT * FROM students;返回信息如下所示。
