您可以自行編寫并構建包含業務邏輯的Python腳本,上傳該腳本后,即可便捷地進行PySpark開發。本文通過一個示例,為您演示如何進行PySpark開發。
前提條件
已準備阿里云賬號,詳情請參見賬號注冊。
操作步驟
步驟一:準備測試文件
在EMR Serverless Spark中,支持使用本地或獨立的開發平臺完成Python文件的開發,并將任務提交至EMR Serverless Spark中運行。本快速入門為了帶您快速熟悉PySpark任務,為您提供了測試文件,您可以直接下載以供后續步驟使用。
單擊DataFrame.py和employee.csv,直接下載測試文件。
DataFrame.py文件是一段使用Apache Spark框架進行OSS上數據處理的代碼。
employee.csv文件中定義了一個包含員工姓名、部門和薪水的數據列表。
步驟二:上傳測試文件
上傳Python文件到EMR Serverless Spark。
進入資源上傳頁面。
在左側導航欄,選擇。
在Spark頁面,單擊目標工作空間名稱。
在EMR Serverless Spark頁面,單擊左側導航欄中的文件管理。
在文件管理頁面,單擊上傳文件。
在上傳文件對話框中,單擊待上傳文件區域選擇Python文件,或直接拖拽Python文件到待上傳文件區域。
本文示例是上傳DataFrame.py。
上傳數據文件(employee.csv)到阿里云對象存儲OSS控制臺,詳情請參見文件上傳。
步驟三:開發并運行任務
在EMR Serverless Spark頁面,單擊左側的數據開發。
單擊新建。
在彈出的對話框中,輸入名稱,類型使用,單擊確定。
在右上角選擇隊列。
添加隊列的具體操作,請參見管理資源隊列。
在新建的開發頁簽中,配置以下信息,其余參數無需配置,然后單擊運行。
參數
說明
主Python資源
選擇前一個步驟中在文件管理頁面上傳的Python文件。本文示例是DataFrame.py。
運行參數
填寫數據文件(employee.csv)上傳到OSS的路徑。例如,oss://<yourBucketName>/employee.csv。
運行任務后,在下方的運行記錄區域,單擊任務操作列的詳情。
在任務歷史中的開發任務頁面,您可以查看相關的日志信息。
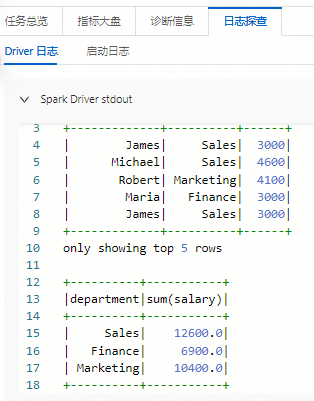
步驟四:發布任務
已發布的任務可以作為工作流節點的任務。
任務運行完成后,單擊右側的發布。
在任務發布對話框中,您可以輸入發布信息,然后單擊確定。
步驟五:查看Spark UI
任務正常運行后,您可以在Spark UI上查看任務的運行情況。
在左側導航欄,單擊任務歷史。
單擊開發任務。
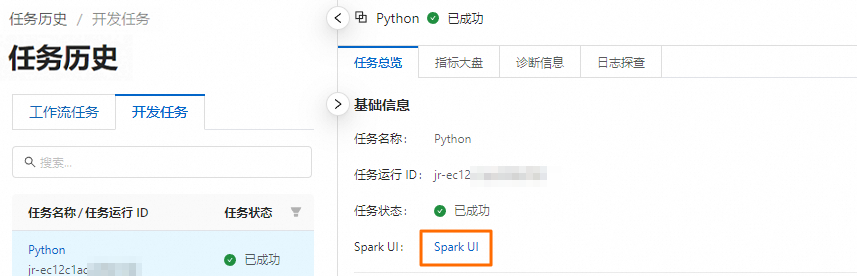
在開發任務頁面,單擊目標任務操作列的詳情。
在任務總覽頁簽,單擊Spark UI。
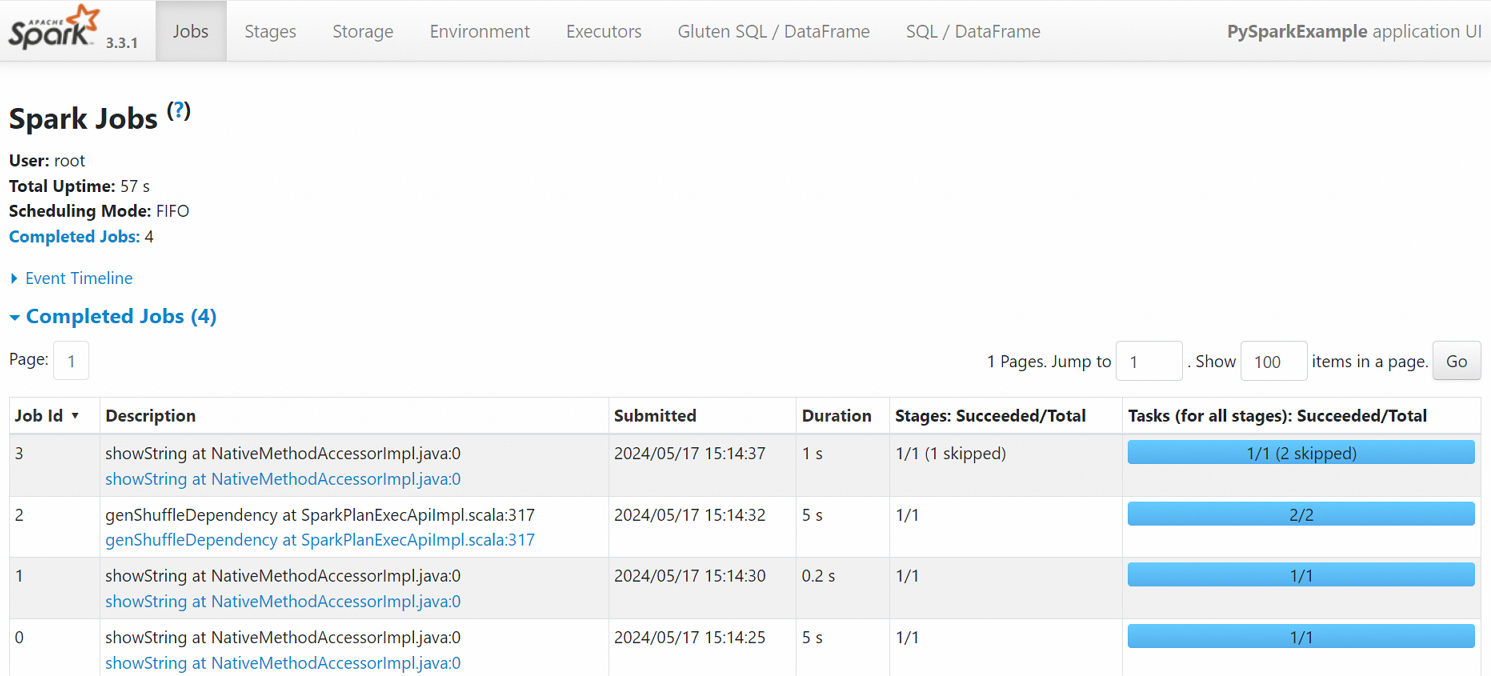
在Spark Jobs頁面,您可以查看任務詳情。
相關文檔
PySpark流任務的開發流程示例,請參見通過Serverless Spark提交PySpark流任務。