EMR+DLF數(shù)據(jù)湖解決方案
通過EMR+DLF數(shù)據(jù)湖方案,可以為企業(yè)提供數(shù)據(jù)湖內(nèi)的統(tǒng)一的元數(shù)據(jù)管理,統(tǒng)一的權(quán)限管理,支持數(shù)據(jù)湖的多種管理如數(shù)據(jù)生命周期、湖格式自動優(yōu)化、存儲分析等。同時支持多源數(shù)據(jù)入湖以及一站式數(shù)據(jù)探索的能力。本文為您介紹EMR+DLF數(shù)據(jù)湖方案具體實踐步驟。
背景信息
采用EMR+DLF數(shù)據(jù)湖解決方案,相對傳統(tǒng)EMR數(shù)據(jù)湖方案有下列優(yōu)點:
DLF提供數(shù)據(jù)湖跨引擎的統(tǒng)一的,全托管免運維的元數(shù)據(jù)服務(wù)。
支持可視化的元數(shù)據(jù)管理,以及多版本管理和回退。
支持可視化一鍵元數(shù)據(jù)遷移。
支持元數(shù)據(jù)全文檢索。
支持元數(shù)據(jù)DataProfile,如文件大小、行數(shù)、訪問頻次、小文件數(shù)量、文件冷熱度、有效文件數(shù)等。
支持除EMR開源引擎外的更多計算引擎,如MaxCompute、Flink、Hologres等多種引擎。
DLF提供豐富的細粒度數(shù)據(jù)權(quán)限控制。
支持按照數(shù)據(jù)目錄、數(shù)據(jù)庫、數(shù)據(jù)列、函數(shù)等資源的各種細粒度權(quán)限點的可視化配置。
支持與EMR中多種計算引擎集成,包括Spark、Hive、Presto、Impala多種計算引擎。
提供豐富的數(shù)據(jù)湖管理能力。
支持多種維度的數(shù)據(jù)生命周期管理,可以對數(shù)據(jù)按照冷熱、更新時間等自動化歸檔,節(jié)省存儲成本。
支持針對Delta數(shù)據(jù)湖格式的自動化存儲優(yōu)化策略,節(jié)省存儲成本。
EMR+DLF數(shù)據(jù)湖解決方案整體架構(gòu)
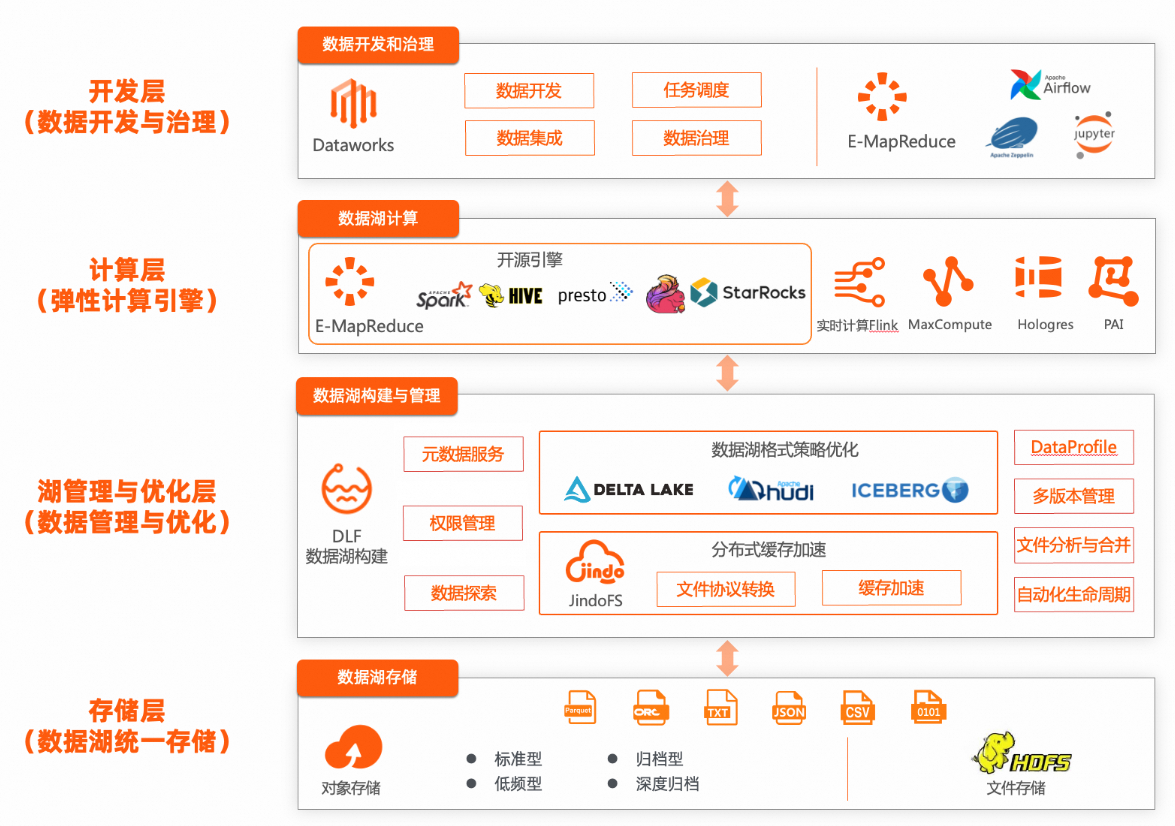
其他說明
目前DLF服務(wù)已開通的地域,請參見已開通的地域和訪問域名。
關(guān)于DLF收費,請參見計費模式。
操作流程
步驟一:創(chuàng)建DLF統(tǒng)一元數(shù)據(jù)的EMR DataLake集群
創(chuàng)建EMR集群,并使用DLF作為元數(shù)據(jù)。
創(chuàng)建E-MapReduce集群,輸入選項如下:
業(yè)務(wù)場景:選擇數(shù)據(jù)湖。
可選服務(wù):需要至少選中Hive組件,其他組件根據(jù)業(yè)務(wù)需要選擇。
元數(shù)據(jù):選擇DLF 統(tǒng)一元數(shù)據(jù)。
DLF數(shù)據(jù)目錄:選擇默認的DLF Catalog,或者新建一個數(shù)據(jù)目錄(Catalog)。如果您沒有開通DLF,會提醒您先開通DLF產(chǎn)品。
繼續(xù)其他配置完成EMR集群創(chuàng)建。詳情請參見創(chuàng)建集群。
步驟二:初始化元數(shù)據(jù)
初始化元數(shù)據(jù)分為以下三種情況:
原有EMR集群(內(nèi)置MySQL或自建RDS做元數(shù)據(jù)),需要將原集群的元數(shù)據(jù)遷移到DLF中。相關(guān)內(nèi)容請參見EMR元數(shù)據(jù)遷移DLF最佳實踐。
新建EMR集群,沒有歷史元數(shù)據(jù)。您可以通過DLF來可視化創(chuàng)建元數(shù)據(jù),或者使用Hive、Spark SQL來創(chuàng)建數(shù)據(jù)庫和數(shù)據(jù)表等。
登錄數(shù)據(jù)湖構(gòu)建控制臺,選擇與OSS相同的地域,例如華東1(杭州)。
在左側(cè)導(dǎo)航欄,選擇。
單擊數(shù)據(jù)庫頁簽,單擊新建數(shù)據(jù)庫。
在新建數(shù)據(jù)庫頁面,配置元數(shù)據(jù)庫參數(shù),單擊確定。
新建EMR集群,已有數(shù)據(jù)存在OSS中,但沒有元數(shù)據(jù)信息。可以使用元數(shù)據(jù)抽取來識別OSS上數(shù)據(jù)的元數(shù)據(jù)信息,并存儲在DLF中。最佳實踐,請參見DLF數(shù)據(jù)探索快速入門-淘寶用戶行為分析。
步驟三:初始化數(shù)據(jù)
初始化數(shù)據(jù)一般常見的幾種情況如下:
原有EMR集群,需要進行數(shù)據(jù)遷移。此時可以考慮通過JindoDistCp工具將原集群的數(shù)據(jù)遷移到OSS中。
從RDS、MySQL、Kafka等業(yè)務(wù)系統(tǒng)接入數(shù)據(jù)。此時可以考慮通過實時計算Flink實現(xiàn)數(shù)據(jù)入湖到DLF中。可參考如何在Flink中管理DLF Catalog。
步驟四:通過Spark/Presto引擎查詢DLF表
通過SSH方式登錄到EMR集群的Master-1-1節(jié)點,詳情請參見登錄集群。
通過spark-sql查詢表。
執(zhí)行以下命令,啟動spark-sql。
spark-sql輸入SQL,查詢表數(shù)據(jù)。
SELECT * FROM <database>.<table>;
通過presto查詢表。
執(zhí)行以下命令,進入Presto命令行。
presto --server master-1-1:8889輸入SQL,查詢表數(shù)據(jù)。
SELECT * FROM <catalog>.<database>.<table>;命令中的參數(shù)說明如下:
參數(shù)名稱
說明
<catalog>待連接的數(shù)據(jù)源的名稱。
您可以通過
show catalogs;命令查看所有的Catalog;或者在EMR控制臺Presto服務(wù)的配置頁簽,查看所有的Catalog。<database>待查詢的數(shù)據(jù)庫的名稱。
<table>待查詢的數(shù)據(jù)表。
例如,如果要查看Hive數(shù)據(jù)源中默認數(shù)據(jù)庫中的
test表的數(shù)據(jù),您可以使用SELECT * FROM hive.default.test;命令。
步驟五(可選):開啟數(shù)據(jù)權(quán)限控制
有些業(yè)務(wù)場景對數(shù)據(jù)安全要求較高,需要對數(shù)據(jù)湖內(nèi)的數(shù)據(jù)權(quán)限進行合理控制。此時您需要以下兩步來完成數(shù)據(jù)權(quán)限的開啟:
EMR集群開啟DLF權(quán)限控制,操作步驟可參考DLF-Auth開啟EMR集群權(quán)限控制。
在DLF中按照權(quán)限設(shè)置為您的相應(yīng)Catalog開啟權(quán)限控制。
以上兩個步驟完成后,您的整個EMR集群的數(shù)據(jù)訪問將會受到數(shù)據(jù)權(quán)限控制,如果沒有權(quán)限的用戶訪問集群數(shù)據(jù),將會被拒絕。
此時可以參考DLF的數(shù)據(jù)授權(quán),為相應(yīng)用戶配置合理的數(shù)據(jù)權(quán)限。相關(guān)內(nèi)容請參見DLF+EMR之統(tǒng)一權(quán)限最佳實踐。
步驟六(可選):生命周期管理
您可以通過生命周期管理對數(shù)據(jù)湖中的數(shù)據(jù)庫、數(shù)據(jù)表配置數(shù)據(jù)管理規(guī)則,可以基于分區(qū)/表創(chuàng)建時間、分區(qū)/表最近修改時間、分區(qū)值三種規(guī)則類型,對數(shù)據(jù)定期進行OSS存儲類型轉(zhuǎn)換,從而節(jié)省數(shù)據(jù)存儲成本。具體操作和說明請參考生命周期管理。