DLF產品(數據湖構建)提供元數據抽取和數據探索的功能,本文介紹如何通過DLF完成對淘寶用戶行為樣例的分析。
前提條件
已創建OSS Bucket。如未創建,請參見創建存儲空間。
操作流程
服務開通:開通阿里云賬號及DLF和OSS相關服務。
樣例數據集下載和導入:下載樣例數據(CSV文件),并上傳至OSS。
DLF數據抽取:使用DLF數據抽取,自動識別文件Schema并創建元數據表。
DLF數據探索:使用DLF數據探索,對用戶行為進行分析,包括用戶活躍度、漏斗模型等。
數據說明
本次測試的數據集來自阿里云天池比賽中使用的淘寶用戶行為數據集,為了提高性能,我們做了一定的裁剪。數據集中以CSV的格式存儲了用戶行為及商品樣例數據。
淘寶用戶行為數據集介紹:https://tianchi.aliyun.com/dataset/dataDetail?dataId=46
數據范圍:2014年12月1日 - 2014年12月7日
數據格式:
user表
字段 | 字段說明 | 提取說明 |
user_id | 用戶標識 | 抽樣&字段脫敏(非真實ID) |
item_id | 商品標識 | 字段脫敏(非真實ID) |
behavior_type | 用戶對商品的行為類型 | 包括瀏覽、收藏、加購物車、購買,對應取值分別是1、2、3、4。 |
user_geohash | 用戶位置的空間標識,可以為空 | 由經緯度通過保密的算法生成 |
item_category | 商品分類標識 | 字段脫敏 (非真實ID) |
time | 行為時間 | 精確到小時級別 |
item表
字段 | 字段說明 | 提取說明 |
item_id | 商品標識 | 抽樣&字段脫敏(非真實ID) |
item_ geohash | 商品位置的空間標識,可以為空 | 由經緯度通過保密的算法生成 |
item_category | 商品分類標識 | 字段脫敏 (非真實ID) |
詳細流程
第一步:開通DLF和OSS服務
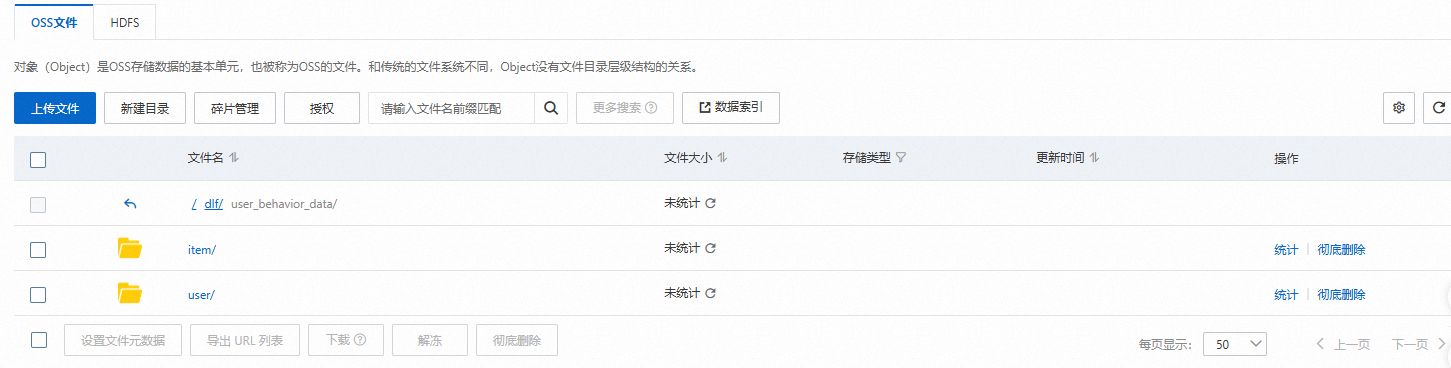
第二步:將需要分析的數據文件上傳至OSS
第三步:在DLF上抽取元數據
登錄數據湖構建控制臺。
創建數據庫。
在左側菜單欄,選擇。
單擊數據庫頁簽,選擇目標數據目錄,單擊新建數據庫。
配置以下數據庫信息,單擊確定。
所屬數據目錄:選擇所屬數據目錄。
數據庫名稱:輸入數據庫名稱。
數據庫描述:可選,輸入數據庫描述。
選擇路徑:選擇上一步中存有用戶行為分析數據user_behavior_data的OSS路徑。
如下圖所示,數據庫創建成功。

進行DLF數據抽取。
在左側導航欄,單擊。
在元數據抽取頁面,單擊新建抽取任務。參數配置詳情請參見元數據抽取。
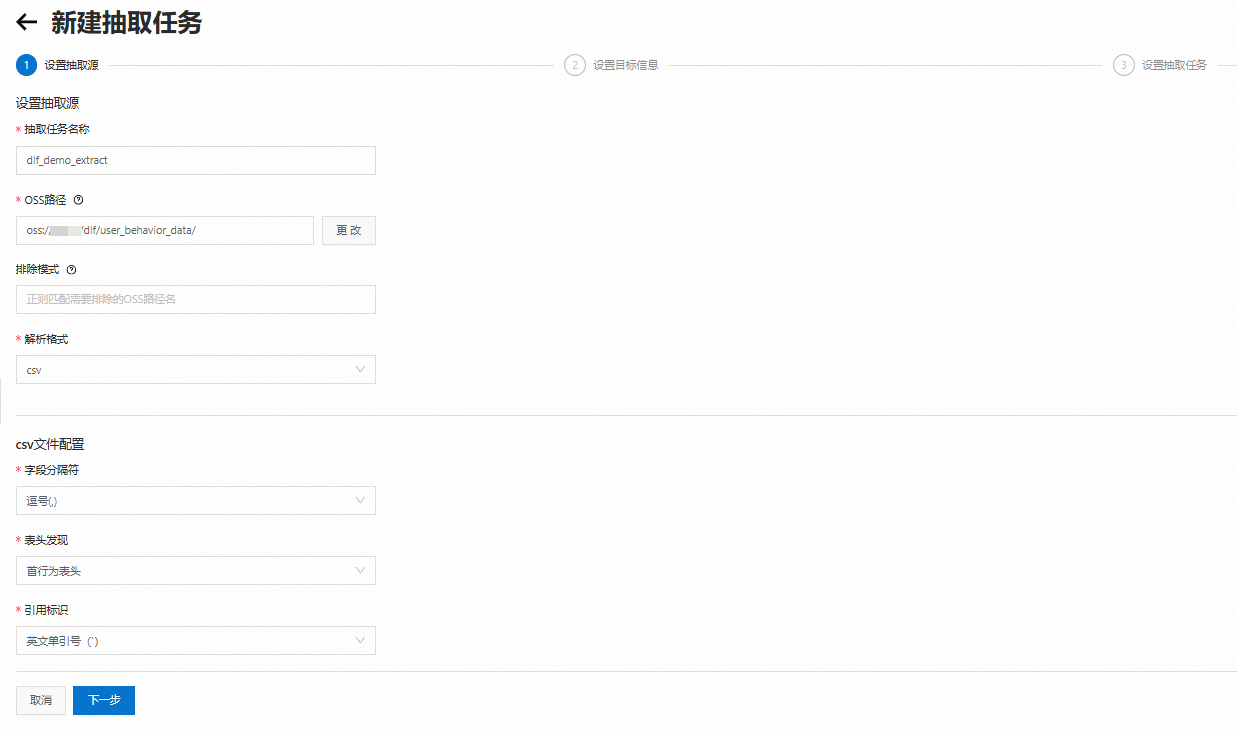
填寫抽取源相關配置,單擊下一步。
選擇要使用的目標數據庫,單擊下一步。
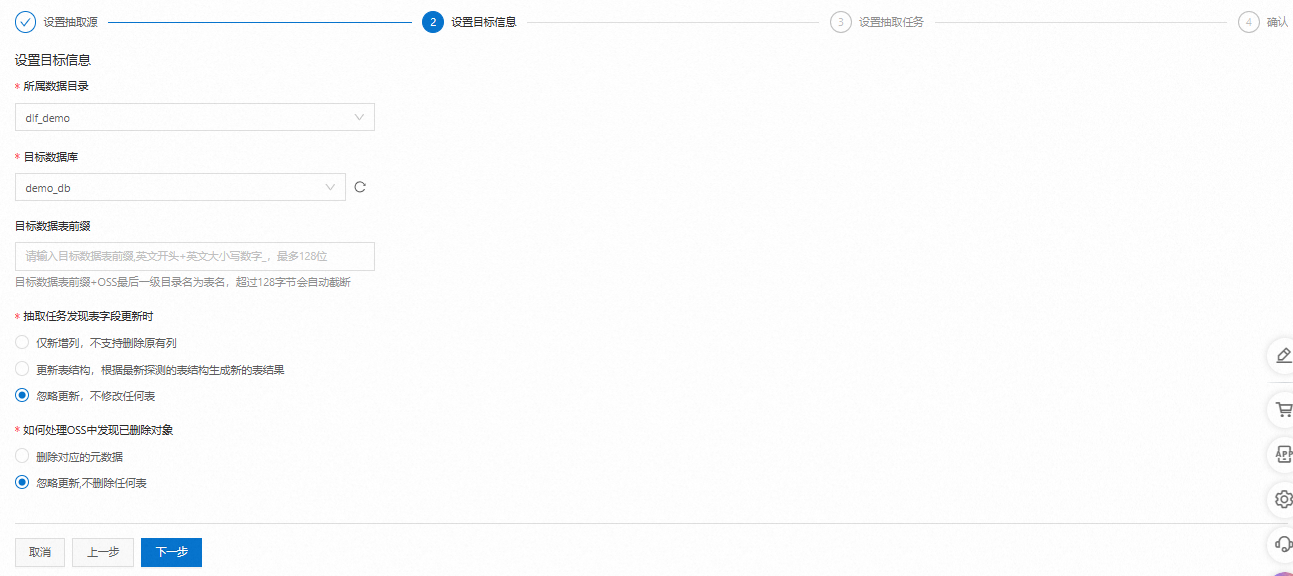
設置抽取任務信息。
RAM角色:默認為開通階段已經授權的“AliyunDLFWorkFlowDefaultRole”。
執行策略:選擇手動執行。
抽取策略:選擇全量抽取。掃描全量數據文件,在數據規模比較大時,作業消耗時間長,抽取結果更準確。
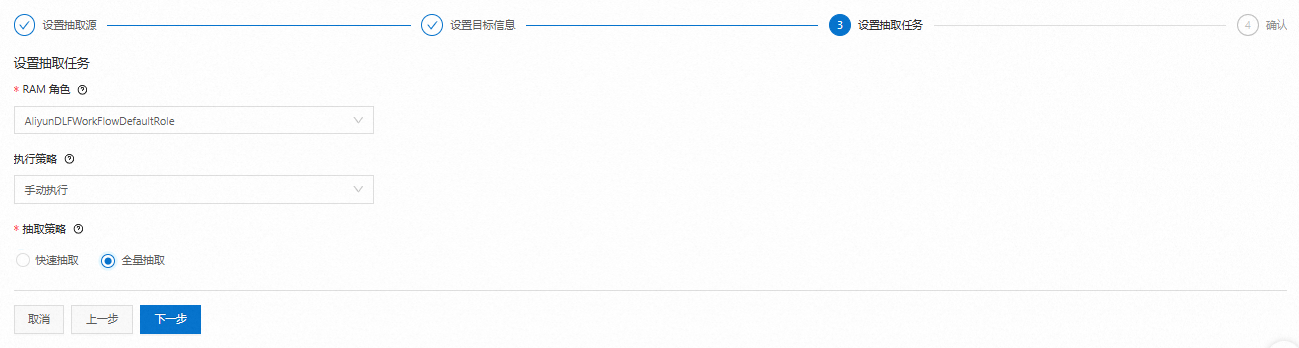
核對信息后,單擊保存并立即執行。
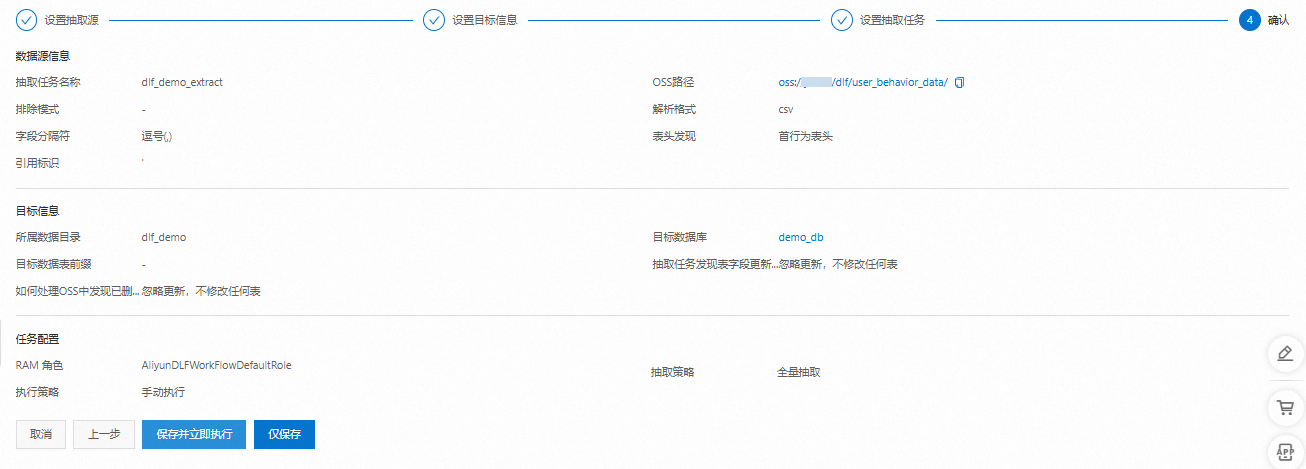
系統會跳轉到元數據抽取列表頁面,新建的任務開始創建并自動運行。在數據規模比較大時,作業消耗時間長。
待任務運行成功后,鼠標移到狀態欄的問號圖標,可看到已經成功創建了兩張元數據表。

查詢數據表信息。
單擊浮層中的數據庫,單擊表列表頁簽,可查看該庫中相關的表信息。

單擊表名,查看并確認抽取出來的表結構是否符合預期。
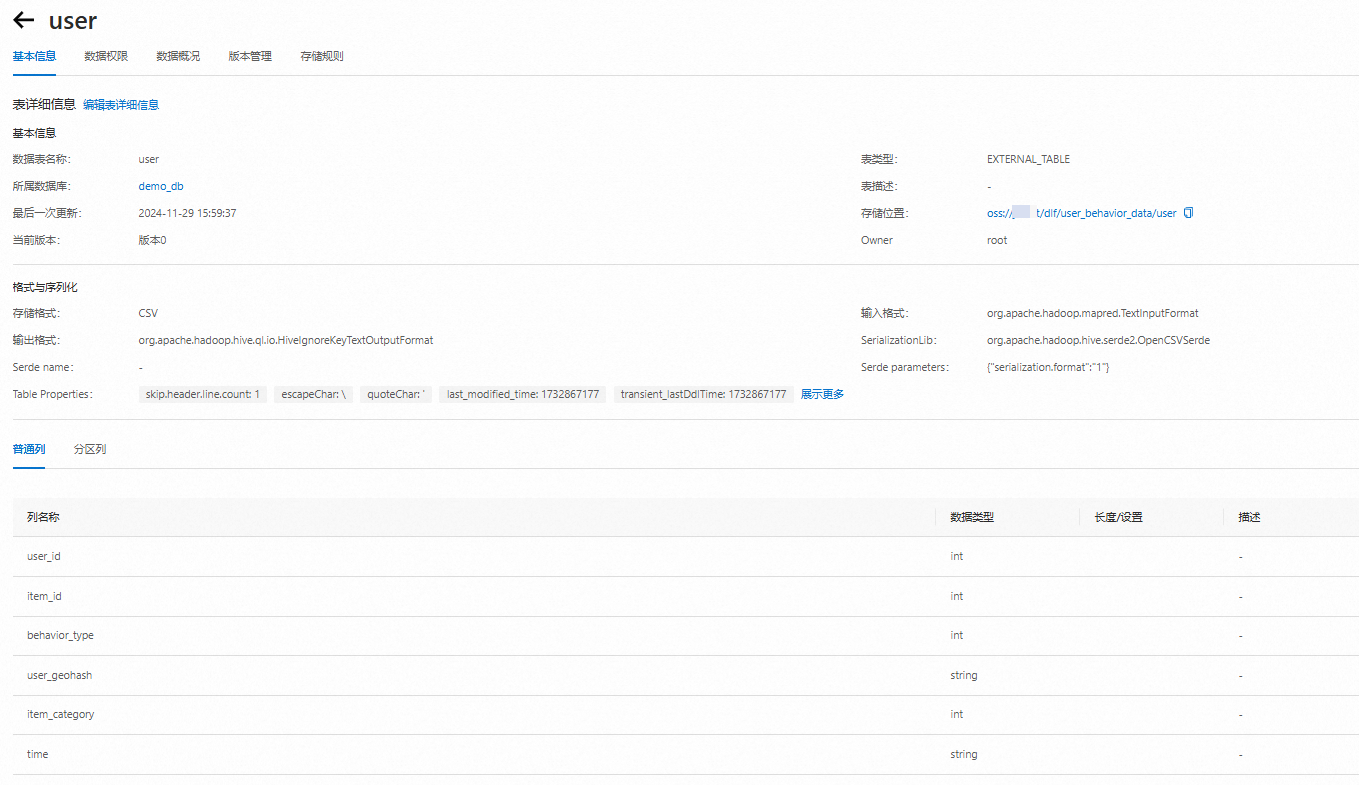
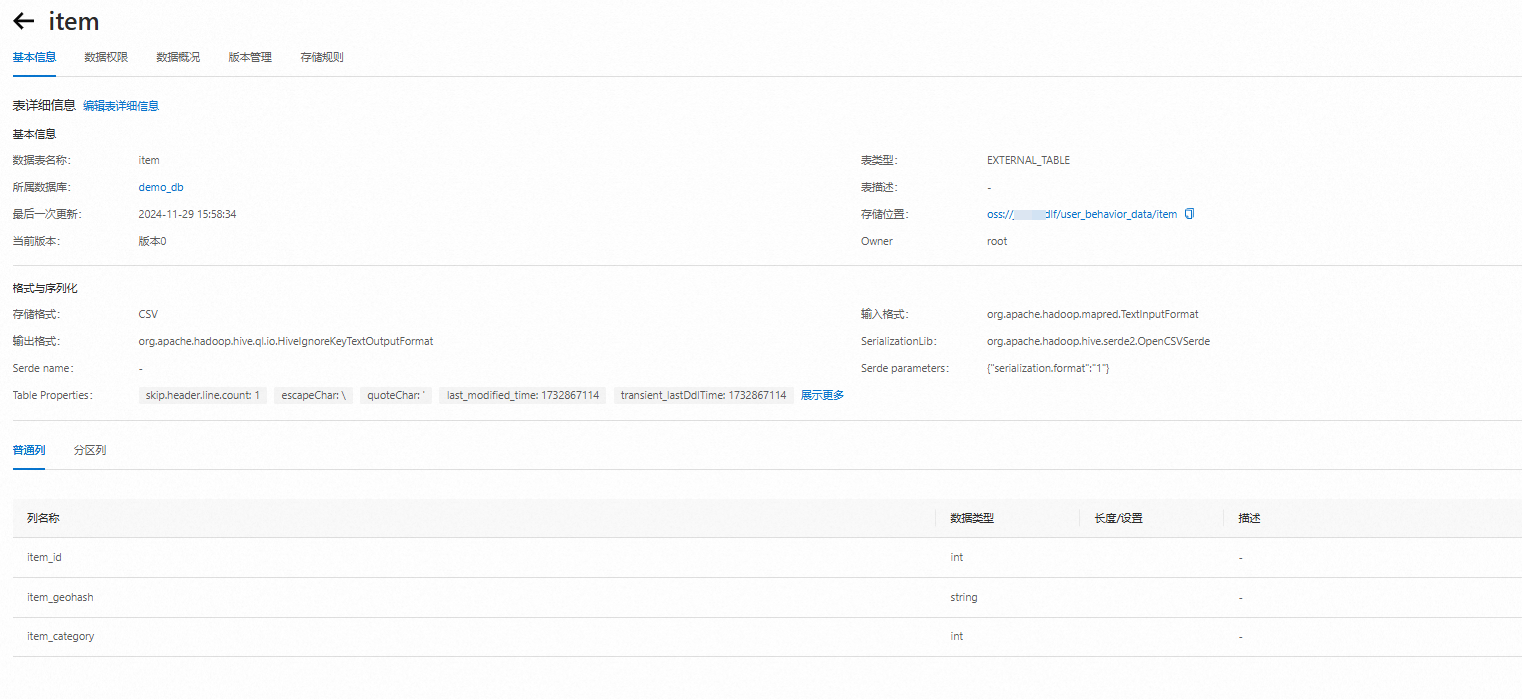
第四步:用戶行為數據分析
數據分析的過程主要分為三步:
預覽并檢查數據信息。
簡單的數據清洗。
進行用戶活躍度、漏斗模型和商品熱度分析。
預覽并檢查數據
在左側菜單欄,單擊數據探索,在SQL查詢框中輸入以下語句,查看文件中的數據信息。
SET spark.sql.legacy.timeParserPolicy=LEGACY;
-- 預覽數據
SELECT * FROM `demo_db`.`user` limit 10;
SELECT * FROM `demo_db`.`item` limit 10;
-- 用戶數
SELECT COUNT(DISTINCT user_id) FROM `demo_db`.`user`;
-- 商品數
SELECT COUNT(DISTINCT item_id) FROM `demo_db`.`item`;
-- 行為記錄數
SELECT COUNT(*) FROM `demo_db`.`user`;結果如下:
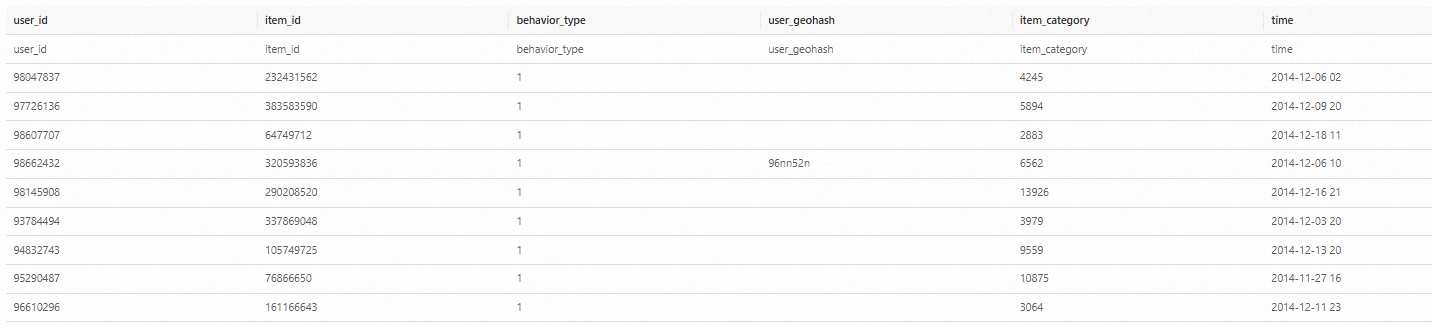
數據預處理
我們對原始數據進行一定的處理,以提高數據的可讀性,并提升分析的性能。
創建新表user_log,表格式為Parquet,按日期分區。
將behavior_type轉換成更易理解的字符串信息:1-click; 2-collect; 3-cart; 4-pay。
將日志+時間的格式拆分為日期和小時兩列,再加上周信息,便于分別做日期和小時級別的分析。
過濾掉不必要的字段,并將數據存入新表user_log。
后續我們會基于新表做用戶行為分析。
CREATE TABLE `demo_db`.`user_log`
USING PARQUET
PARTITIONED BY (date)
AS SELECT
user_id,
item_id,
CASE
WHEN behavior_type = 1 THEN 'click'
WHEN behavior_type = 2 THEN 'collect'
WHEN behavior_type = 3 THEN 'cart'
WHEN behavior_type = 4 THEN 'pay'
END AS behavior,
item_category,
time,
date_format(time, 'yyyy-MM-dd') AS date,
date_format(time, 'H') AS hour,
date_format(time, 'u') AS day_of_week
FROM `dlf_demo`.`user`;
-- 查看運行后的數據
SELECT * FROM `demo_db`.`user_log` limit 10; 結果如下:
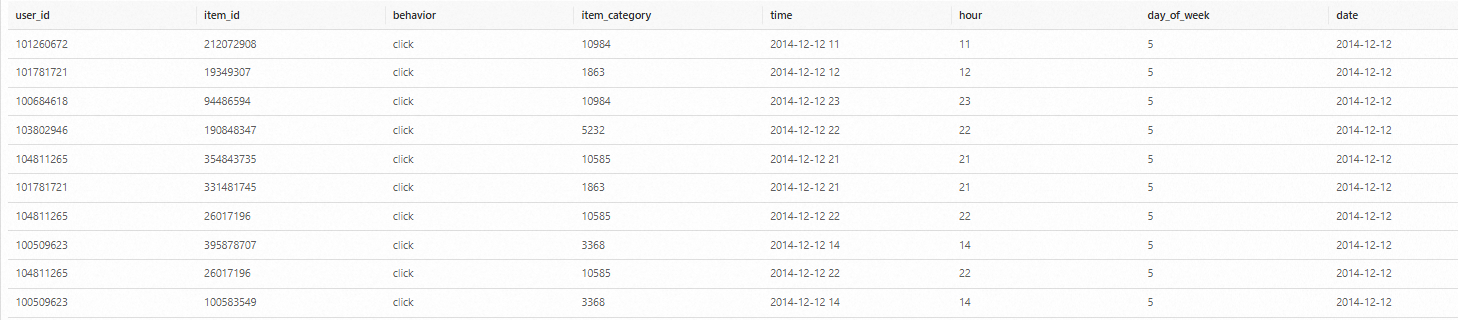
用戶行為分析
首先,我們基于漏斗模型,對所有用戶從點擊到加購、收藏、購買的轉化情況進行分析。
-- 漏斗分析耗時13秒 SELECT behavior, COUNT(*) AS total FROM `demo_db`.`user_log` GROUP BY behavior ORDER BY total DESC結果如下:

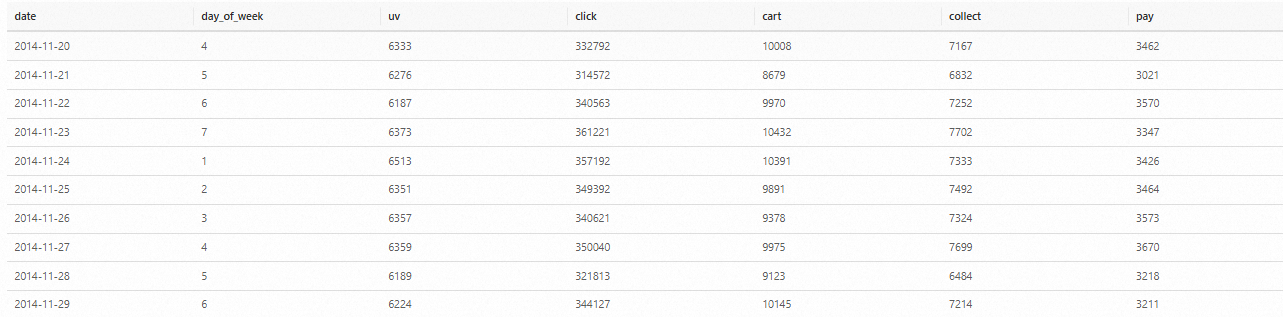
然后對一周內每天的用戶行為做統計分析。
-- 用戶行為分析耗時14秒 SELECT date, day_of_week, COUNT(DISTINCT(user_id)) as uv, SUM(CASE WHEN behavior = 'click' THEN 1 ELSE 0 END) AS click, SUM(CASE WHEN behavior = 'cart' THEN 1 ELSE 0 END) AS cart, SUM(CASE WHEN behavior = 'collect' THEN 1 ELSE 0 END) AS collect, SUM(CASE WHEN behavior = 'pay' THEN 1 ELSE 0 END) AS pay FROM `demo_db`.`user_log` GROUP BY date, day_of_week ORDER BY date結果如下(由于數據集經過裁剪,對于工作日和非工作日的結果有失真)。
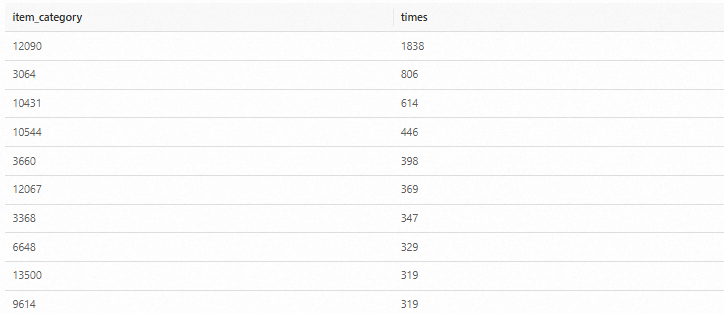
最后,我們結合商品表,分析出數據集中最受歡迎的是個商品品類
-- 銷售最多的品類耗時1分10秒 SELECT item.item_category, COUNT(*) AS times FROM `demo_db`.`item` item JOIN `demo_db`.`user_log` log ON item.item_id = log.item_id WHERE log.behavior='pay' GROUP BY item.item_category ORDER BY times DESC LIMIT 10;結果如下:
(可選)下載分析結果。
DLF提供將分析結果以CSV文件的形式下載的功能,啟用該功能需要提前設置分析結果的保存路徑(OSS路徑)。設置后,查詢結果會被保存到該路徑下。
單擊數據探索頁面右上方的路徑設置,設置結果存儲路徑,可以選擇已有文件夾或者新建文件夾。
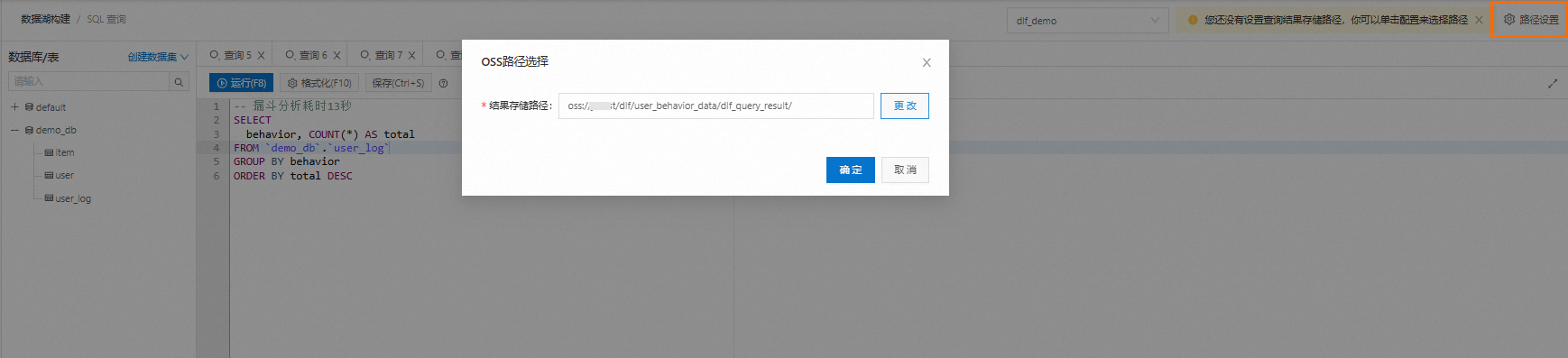
設置完成后,運行SQL查詢,在運行歷史頁簽的下載結果直接下載,也可以直接通過OSS路徑訪問和下載該文件。

(可選)保存SQL。
通過單擊保存,可以將本次分析用到的SQL進行保存,后續可直接在已存查詢中打開,做進一步的調用及修改。
問題解答
如果您有任何問題或希望深入探討數據湖技術,歡迎在微信中搜索并關注“數據湖技術圈”公眾號。