多輪對(duì)話搜索
多輪對(duì)話搜索的服務(wù)創(chuàng)建操作指南和調(diào)優(yōu)建議。
服務(wù)創(chuàng)建
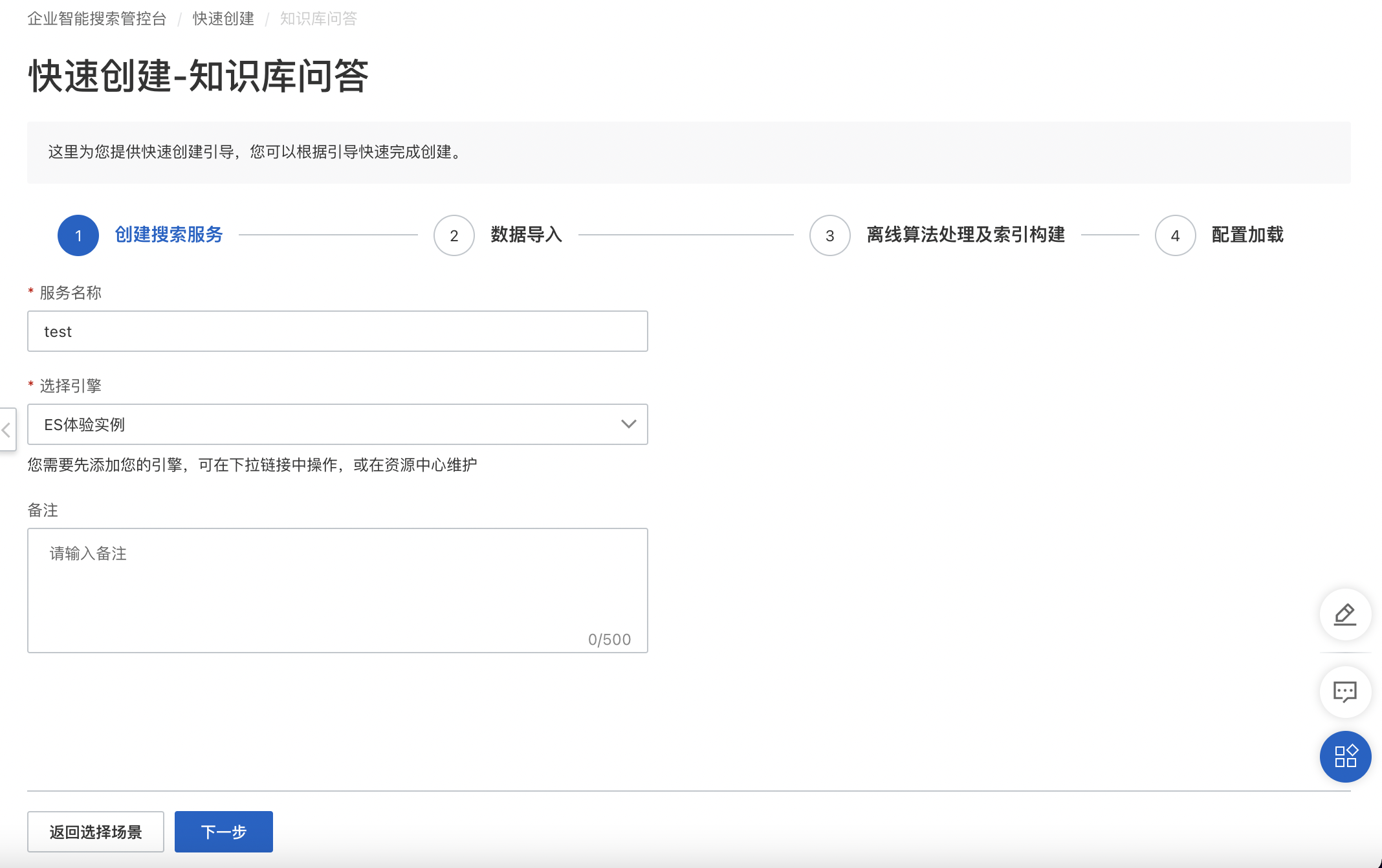
單擊快速創(chuàng)建,選擇多輪對(duì)話搜索,進(jìn)入服務(wù)創(chuàng)建界面,編輯服務(wù)名稱并選擇服務(wù)所使用的引擎,完成創(chuàng)建中進(jìn)入索引配置
引擎
提供檢索服務(wù)的基礎(chǔ)組建,可在資源中心進(jìn)行引擎管理也可在快速創(chuàng)建頁面直接選擇或添加。更多信息可查看引擎管理操作指南。
已適配引擎列表 | 版本 | 配置 | 插件 | 鏈接 |
阿里云Elasticsearch | V8.9 V7.10 V7.7 V6.8 V6.7 | 基礎(chǔ)建議2核8G,存在向量檢索需求8核32G | 無要求 |
數(shù)據(jù)導(dǎo)入
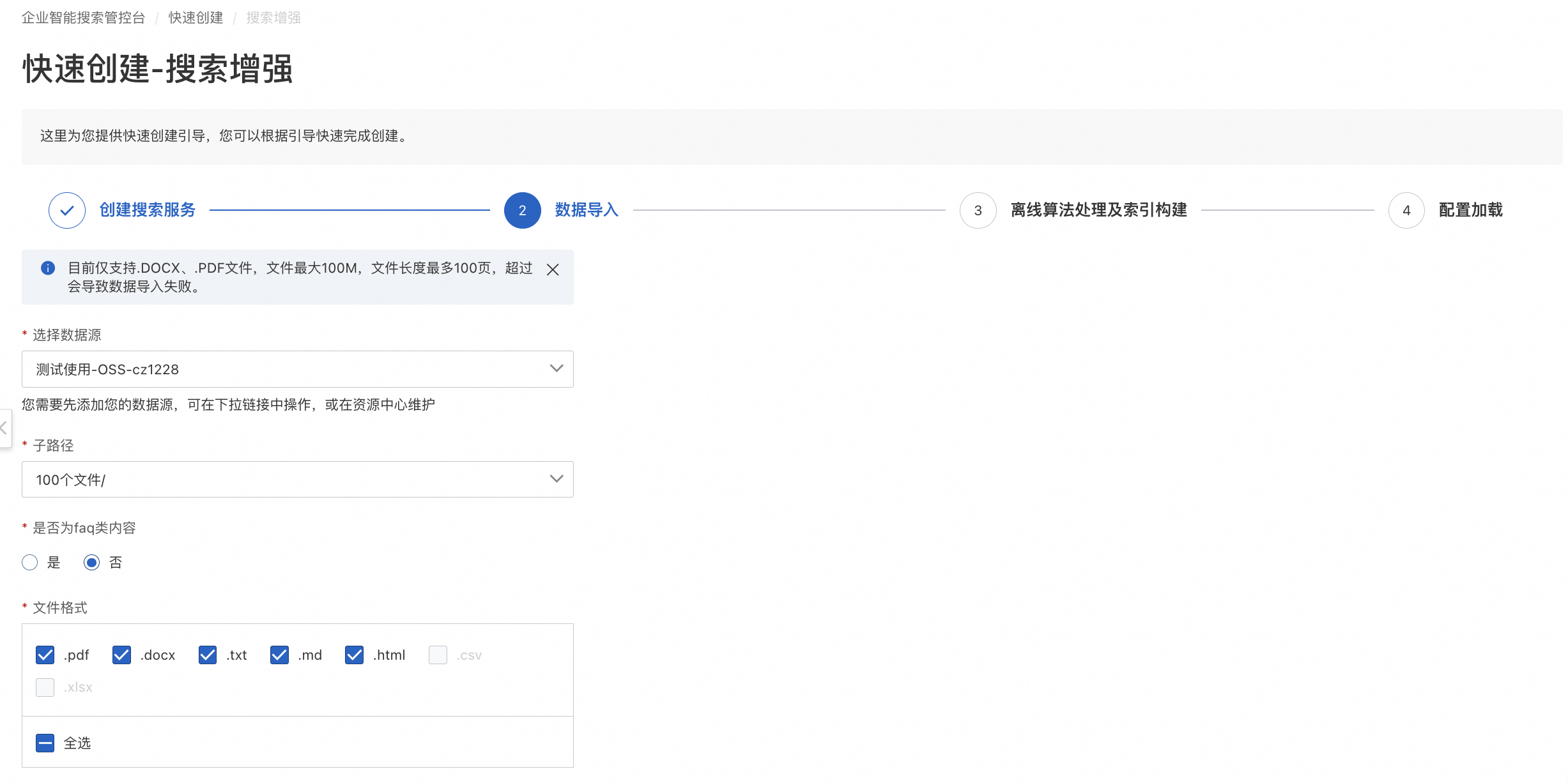
數(shù)據(jù)源
企業(yè)知識(shí)庫存儲(chǔ),可在資源中心進(jìn)行數(shù)據(jù)源管理也可在快速創(chuàng)建頁面直接選擇或添加。更多信息可查看數(shù)據(jù)源管理操作指南。
已適配數(shù)據(jù)源列表 | 鏈接 |
阿里云 RDS MySQL | |
阿里云 MaxCompute | |
阿里云 OSS |
子路徑/庫表
企業(yè)知識(shí)庫當(dāng)前所選數(shù)據(jù)源存儲(chǔ)地址,系統(tǒng)讀取所選數(shù)據(jù)源下的目錄文件/庫表,支持按子路徑選擇目錄文件及其子目錄/庫表。
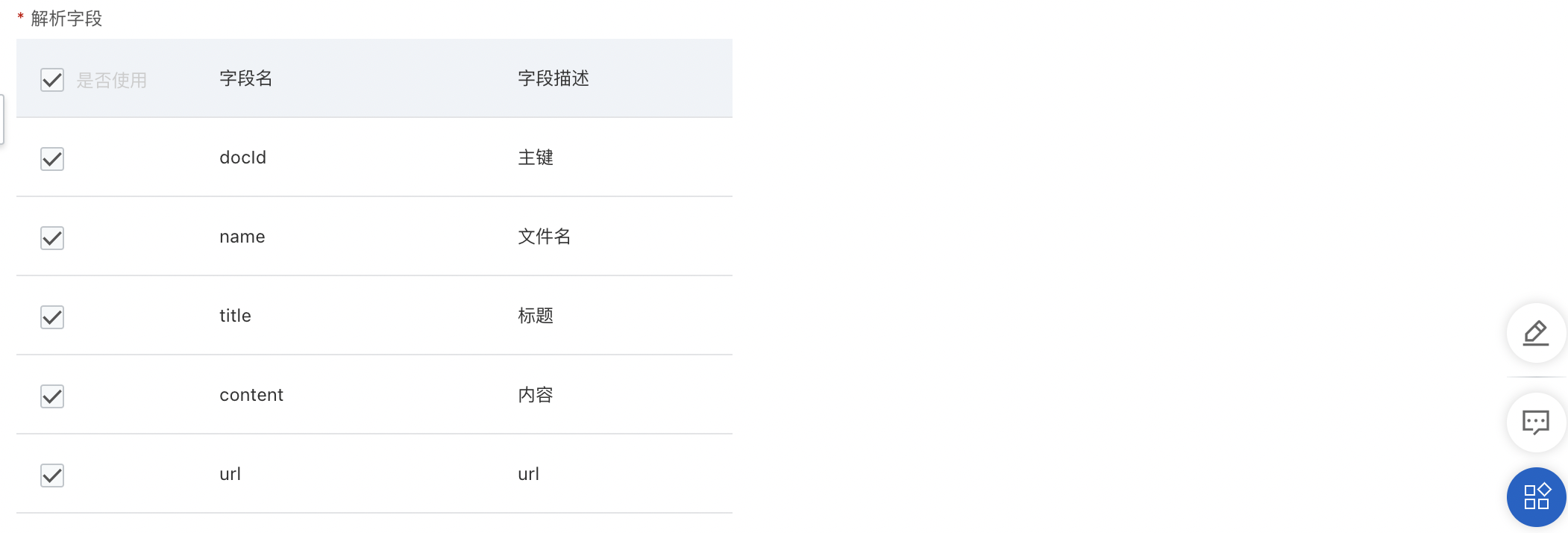
解析字段
系統(tǒng)離線解析數(shù)據(jù)源字段,用于構(gòu)建索引。
勾選使用該字段,對(duì)勾選的字段將入庫構(gòu)建索引,不同的字段類型在搜索過程中參與到召回、排序的鏈路中,在查詢結(jié)果中可以展示。未勾選字段將不會(huì)構(gòu)建索引。
數(shù)據(jù)源類型 | 是否為faq | 解析字段 |
RDS MySQL /MaxCompute | 是 | 要求數(shù)據(jù)庫庫表字段類型為:id、question、answer、sim_question、url、gmt_modified; |
否 | 解析字段同所選數(shù)據(jù)庫庫表字段,非固定可選; | |
OSS | 是 | 支持解析的文件格式為.csv/.xlsx; 要求數(shù)據(jù)源字段類型為id、question、answer、sim_question、url; |
否 | 支持解析的文件格式.pdf/.docx/.txt/.md/.html; 解析字段為默認(rèn)字段,固定全選; |
配置索引
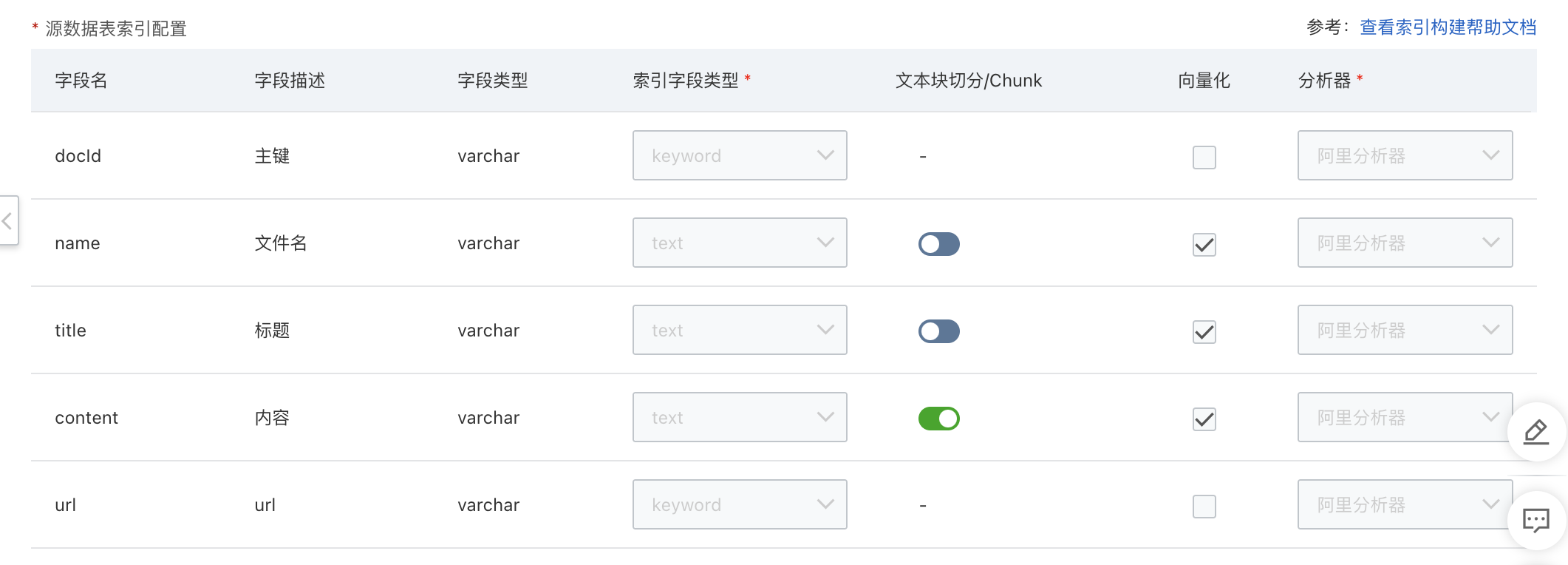
源數(shù)據(jù)表索引配置
完成數(shù)據(jù)源配置后, 需配置索引結(jié)構(gòu)來完成索引構(gòu)建。基于不同的數(shù)據(jù)來源和使用場(chǎng)景, 數(shù)據(jù)字段內(nèi)容會(huì)有差異,但索引構(gòu)建的流程相似,下面以阿里云 OSS數(shù)據(jù)源為例介紹索引構(gòu)建流程。
字段名
字段名稱, 對(duì)采用OSS文件格式作為數(shù)據(jù)源的實(shí)例,字段名稱跟離線數(shù)據(jù)解析結(jié)果字段對(duì)應(yīng),離線解析結(jié)果默認(rèn)的字段名稱包括:
字段名稱 | 字段描述 | 字段類型 |
docId | 主鍵、唯一標(biāo)識(shí)id | varchar |
name | 文件名稱 | varchar |
title | 解析片段標(biāo)題內(nèi)容 | varchar |
content | 解析片段正文內(nèi)容 | varchar |
url | url | varchar |
對(duì)采用數(shù)據(jù)表作為數(shù)據(jù)源的實(shí)例,字段名和表格字段名一一對(duì)應(yīng), 假設(shè)數(shù)據(jù)源表格中只包含"id", "content"字段, 數(shù)據(jù)表索引配置對(duì)應(yīng)顯示"id", "content"字段名, 字段類型跟源數(shù)據(jù)表中定義的字段類型保持一致。
索引字段類型
索引字段類型定義了字段的數(shù)據(jù)類型,以便搜索引擎(例如ElasticSearch)能夠正確地處理和索引這些字段的值。以ElasticSearch為例,常見的索引字段類型:
索引字段類型 | 字段類型說明 |
text | 用于索引長(zhǎng)文本,例如文章內(nèi)容、描述等。文本類型會(huì)進(jìn)行分詞處理,以便能夠根據(jù)單詞進(jìn)行搜索和匹配。 |
keyword | 用于索引短文本,例如標(biāo)簽、關(guān)鍵字等。關(guān)鍵字類型不會(huì)進(jìn)行分詞處理,整個(gè)字段作為一個(gè)整體進(jìn)行索引和匹配。 |
integer | 用于索引INT類型數(shù)字,數(shù)字類型可以用于排序、范圍查詢等操作 |
long | 用于索引LONG類型數(shù)字,數(shù)字類型可以用于排序、范圍查詢等操作 |
double | 用于索引DOUBLE類型數(shù)字,數(shù)字類型可以用于排序、范圍查詢等操作 |
float | 用于索引FLOAT類型數(shù)字,數(shù)字類型可以用于排序、范圍查詢等操作 |
date | 用于索引日期和時(shí)間。日期類型可以進(jìn)行日期范圍查詢、排序等操作。 |
boolean | 用于索引布爾值,即true或false |
binary | 用于索引二進(jìn)制數(shù)據(jù),例如圖片、文件等 |
文本塊切分/Chunk
當(dāng)該字段文本長(zhǎng)度比較長(zhǎng)且需要作為大模型回答的參考內(nèi)容時(shí),建議勾選該字段。勾選后該字段的長(zhǎng)文本會(huì)被切分為短的文本塊;若不勾選,部分較長(zhǎng)的文本后半段會(huì)被直接截?cái)唷SS數(shù)據(jù)源的content字段默認(rèn)勾選。
向量化
文本向量化是將文本數(shù)據(jù)轉(zhuǎn)換為數(shù)值向量的過程。它將文本中的詞語、句子表示為向量形式,以便能夠信息檢索等任務(wù)中進(jìn)行相關(guān)性計(jì)算。勾選向量化后,搜索的準(zhǔn)確性能夠得到提升,對(duì)于用戶輸入的問題與相關(guān)知識(shí)庫內(nèi)容字面不一致的情況也能搜到正確的知識(shí)。
文本向量化實(shí)例
輸入文本:"一條黃色的裙子"
向量化后結(jié)果:[0.2694664001464844,-0.3998311161994934,-0.14598636329174042,-0.4976918697357178,-0.13986249268054962,0.6272065043449402,-0.1434994637966156,-0.33319777250289917]向量化后為一個(gè)浮點(diǎn)數(shù)列表,列表長(zhǎng)度取決于向量化模型的輸出維度
在索引構(gòu)建階段, 向量化只對(duì)TEXT類型字段生效
如果選擇多個(gè)TEXT字段向量化,算法模型將自動(dòng)將多個(gè)字段拼接計(jì)算向量結(jié)果
分析器
在索引構(gòu)建過程中,分析器(OR 分詞器)是用于將文本數(shù)據(jù)分割成詞的工具。它是文本分析過程中的一個(gè)重要組件,用于構(gòu)建倒排索引,以便能夠?qū)ξ谋具M(jìn)行搜索和匹配。
分析器將輸入的文本按照一定的規(guī)則進(jìn)行分割,分析器可以將一個(gè)長(zhǎng)文本分割成多個(gè)詞,以便能夠?qū)@些詞進(jìn)行索引和搜索。
企業(yè)搜索提供多種內(nèi)置的分析器,包括:
阿里分析器
介紹:阿里巴巴開發(fā)的中英文分詞工具,適配多種業(yè)務(wù)場(chǎng)景,多輪對(duì)話搜索默認(rèn)選項(xiàng)。
分詞樣例
輸入文本:"阿里巴巴是一家全球的互聯(lián)網(wǎng)科技公司。"
分詞結(jié)果:"阿里巴巴 / 是 / 一家 / 全球 / 的 / 互聯(lián)網(wǎng) / 科技 / 公司 / 。"Ik分析器
介紹:開源Ik分詞器, 分詞效果跟阿里分析器類似
單字分析器
介紹:按照單個(gè)字符(UTF8編碼)進(jìn)行分割,適用于語義檢索要求不高、要求高召回的檢索場(chǎng)景
分詞樣例
輸入文本:"單字分詞器是一種最基礎(chǔ)的分詞方式。"
分詞結(jié)果:"單 / 字 / 分 / 詞 / 器 / 是 / 一 / 種 / 最 / 基 / 礎(chǔ) / 的 / 分 / 詞 / 方 / 式 / 。"拼音分析器
介紹:針對(duì)中文字段進(jìn)行拼音解析、使用于拼音檢索場(chǎng)景
分詞樣例:
輸入文本:"我愛中文分詞器"
分詞結(jié)果: "wo ai zhong wen fen ci qi"Ngram分析器:
介紹: 按照N-gram字符(UTF8編碼)進(jìn)行分割, N默認(rèn)值為3
分詞樣例:
輸入文本:"中文分詞器"
ngram分詞結(jié)果(N=3):"中 / 文 / 分 / 詞 / 器/ 中文 / 文分 / 分詞 / 詞器/ 中文分 / 文分詞 / 分詞器"通過選擇合適的分析器,可以使得搜索引擎在索引和搜索文本數(shù)據(jù)時(shí)更準(zhǔn)確和靈活。
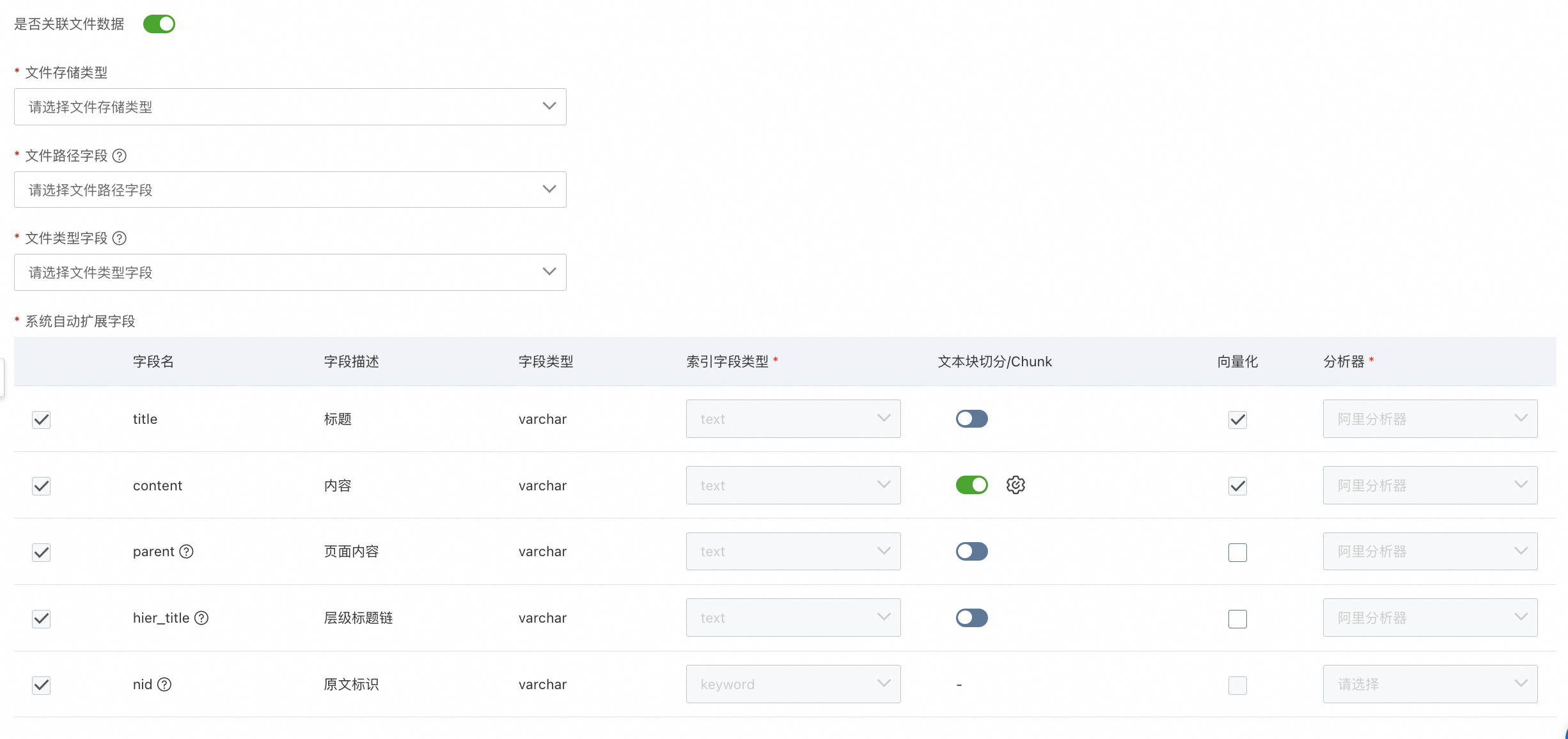
是否關(guān)聯(lián)文件數(shù)據(jù)
當(dāng)接入數(shù)據(jù)源同時(shí)存在文件類型及數(shù)據(jù)庫類型數(shù)據(jù)時(shí),且“文件路徑字段”和“文件類型字段”都是數(shù)據(jù)庫中的字段,需要開啟“關(guān)聯(lián)文件數(shù)據(jù)”功能,可以參考最佳實(shí)踐說明。開啟后,系統(tǒng)會(huì)自動(dòng)校驗(yàn),若源數(shù)據(jù)表中字段和系統(tǒng)自動(dòng)擴(kuò)展字段中的“title、content、parent、hier_title、nid”有重復(fù),則需退出流程,更改字段名稱。
文件存儲(chǔ)類型
現(xiàn)支持OSS和HTTP兩類數(shù)據(jù)。
文件路徑字段
此字段用于獲取存在oss中文件路徑數(shù)據(jù),字段需為keyword/text字段。
文件類型字段
此字段用于獲取存在oss中文件類型數(shù)據(jù),字段需為keyword/text字段,文件類型當(dāng)前支持 .pdf/.docx/.txt/.md/.html。
系統(tǒng)自動(dòng)擴(kuò)展字段
系統(tǒng)自動(dòng)擴(kuò)展字段固定為“title、content、parent、hier_title、nid”。
支持配置chunk參數(shù),“chunk size指定”范圍值在50以上,“chunk overlap指定”范圍值需小于chunk size指定數(shù)值,可以等于0。
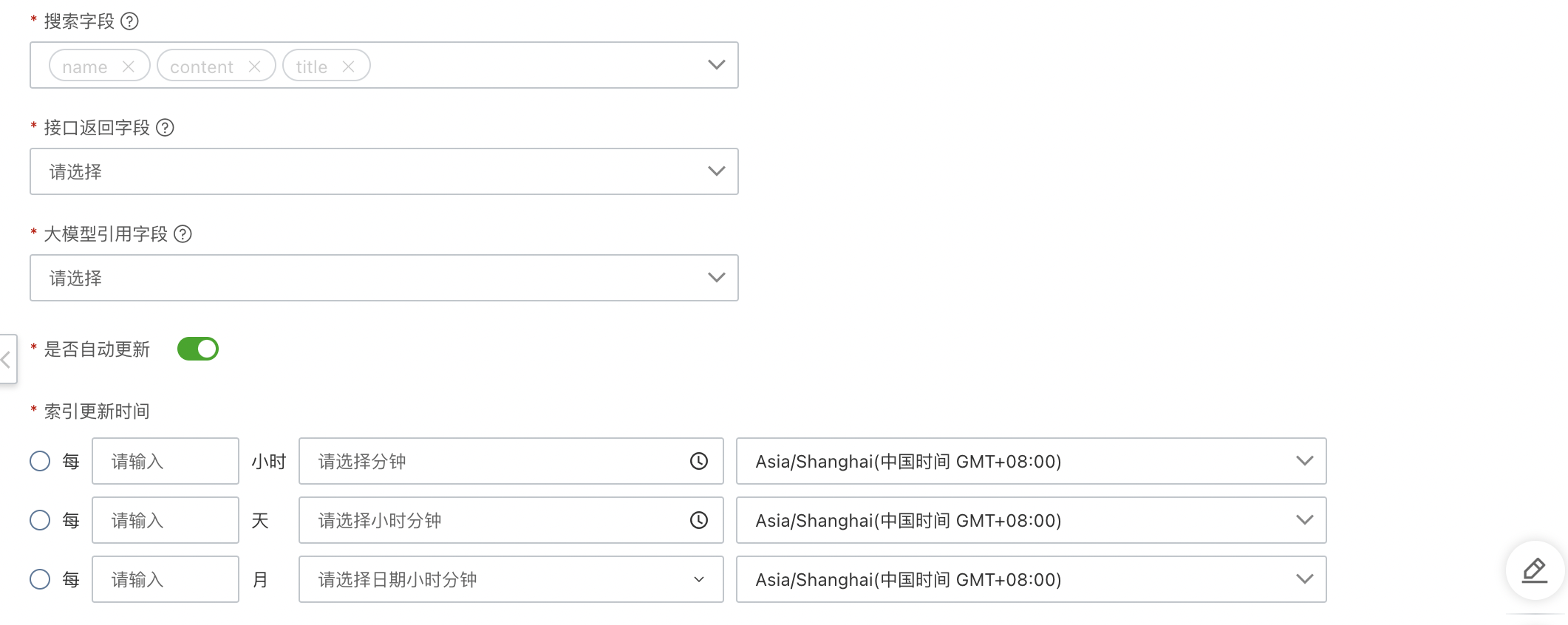
搜索字段
全文檢索字段,需要為keywords或text類型,用來執(zhí)行搜索操作,匹配查詢條件,限制搜索范圍。
接口返回字段
接口返回字段是指搜索請(qǐng)求后的返回結(jié)果字段,可在索引配置字段中選擇業(yè)務(wù)所需字段,此字段會(huì)在開放接口openapi中的fields字段返回。后續(xù)可應(yīng)用于大模型多輪對(duì)話中的參考內(nèi)容。
大模型引用字段
大模型引用字段是指搜索請(qǐng)求后接口返回字段需要被大模型作為參考內(nèi)容引用的字段。此字段需要是接口返回字段中的子集。
為大模型可以更精準(zhǔn)的獲取有效信息,以給出更準(zhǔn)確的答復(fù)。例如接口返回字段為"id", "content",由于"id"字段并未攜帶有效信息輔助大模型理解,因此只選擇"content"作為大模型引用字段。
是否自動(dòng)更新
若數(shù)據(jù)源索引配置需要定期更新,則需要打開此開關(guān)。支持每小時(shí)/每天/每月三種周期自動(dòng)更新,支持配置對(duì)應(yīng)更新的時(shí)間點(diǎn)以及時(shí)區(qū)。
服務(wù)測(cè)試
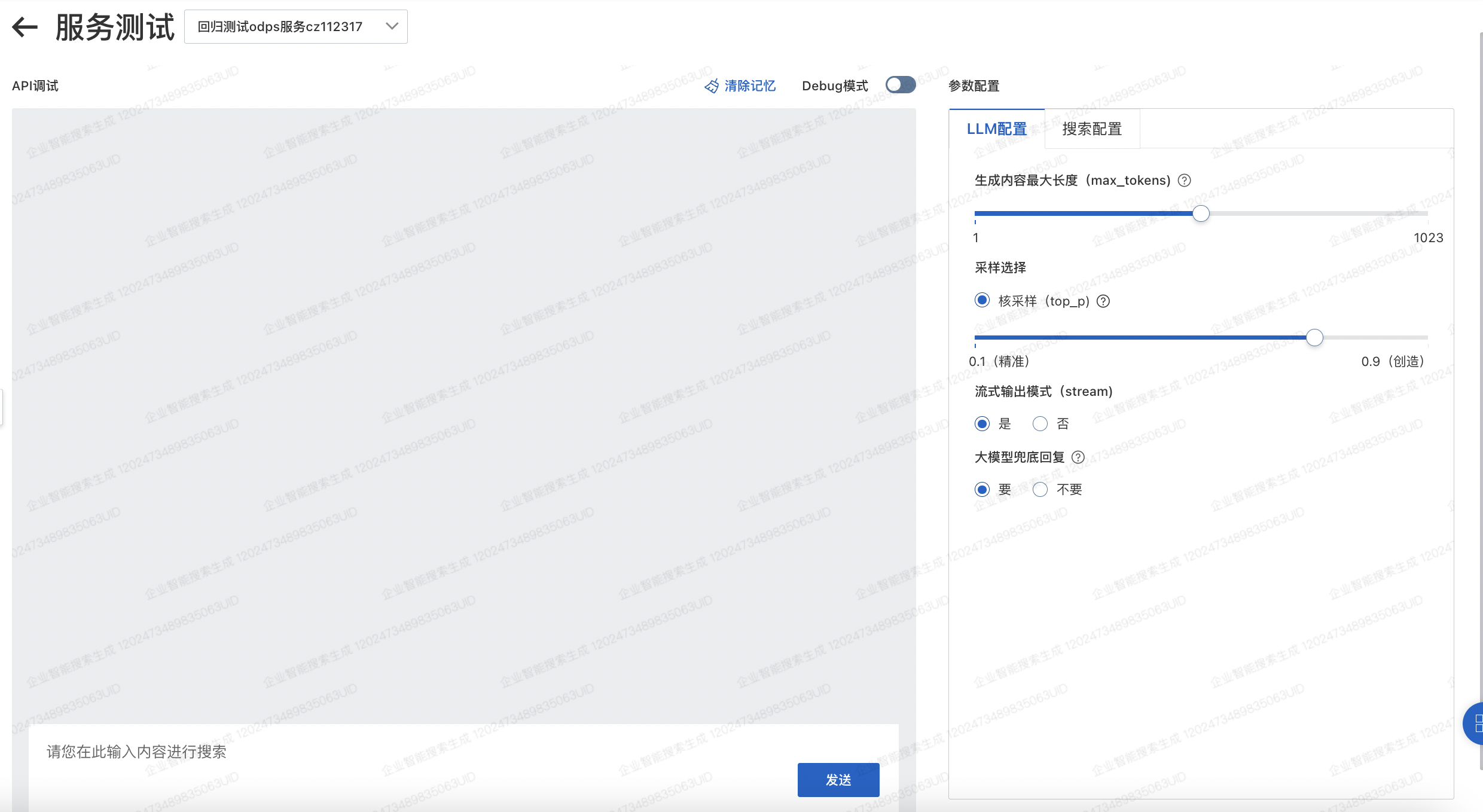
LLM參數(shù)配置
配置修改完成后均需要單擊保存配置才能生效!
生成內(nèi)容最大長(zhǎng)度(max_tokens)
控制每次生成的對(duì)話內(nèi)容長(zhǎng)度。注意輸入生成內(nèi)容的最大長(zhǎng)度不應(yīng)超過2048,超過會(huì)對(duì)輸入內(nèi)容進(jìn)行截?cái)唷?/p>
采樣選擇
較低的top_p代表更加謹(jǐn)慎的輸出;較高的top_p對(duì)應(yīng)更加具有創(chuàng)造力的輸出。一般推薦設(shè)置為0.7-0.8,可根據(jù)實(shí)際情況進(jìn)行調(diào)整。
流式輸出模式(stream)
是:最終輸出結(jié)果將在生成結(jié)果的過程中逐字輸出。
否:最終輸出結(jié)果將在全部生成完畢后整段輸出。
大模型兜底回復(fù)
要:如果搜索請(qǐng)求后并未返回有效信息,則采用大模型做兜底回復(fù)
不要:如果搜索請(qǐng)求后并未返回有效信息,不采用大模型做兜底回復(fù),支持配置相應(yīng)回復(fù)話術(shù)。
Tips
調(diào)試方法:初次配置完后,請(qǐng)選擇索引文檔中的一篇作為目標(biāo),并針對(duì)這篇文章撰寫一個(gè)問題。將問題輸入測(cè)試頁面查看模型返回,如符合預(yù)期可以多測(cè)幾個(gè);如不符合預(yù)期,可以開啟Debug開關(guān)
然后可以看到多輪對(duì)話鏈路具體日志,如果覺得展示框太小可以復(fù)制出來到其他文本編輯器或者JSON編輯器查看。我們主要關(guān)注”child_execs“里面的內(nèi)容
{
"start_time":1692850565627,
"trace_id":"f-s-5NRRqmDDUgkNGFLXw88888",
"exec_params":{
"streaming":true,
"debug":true,
"async_run":false,
"session_id":"f-s-5NRRqmDDUgkNGFLXw88888",
"flow_params":{
"top_p":"0.7",
"search_size":3,
"api_key":"**************",
"content_fields":"title,content",
"max_new_tokens":512,
"temperature":1,
"rank_model_info":"{"rankModelInfo": {"default": {"features": [{"name": "vector_index", "weights": 0.5, "threshold": 0, "norm": true}, {"name": "static_value", "field": "_rc_t_score", "weights": 0.5, "threshold": 0, "norm": true}], "aggregate_algo": "weight_avg"}}}",
"human_input":"牧云",
"custom_config_info":"{"rerankSize": 200, "uqVectorRecallRatio": 0.5}",
"type":"title,content",
"fields":"title,content",
"scene":"dolphin_search_ms_index_es_113_prod"
},
"flow_json":null,
"flow_json_url":"https://******/corp_search.json"
},
"exec_result":{
"result":[
"對(duì)",
"不",
"起",
",",
"現(xiàn)",
"有",
"搜",
"索",
"結(jié)",
"果",
"中",
"不",
"包",
"含",
"該",
"問",
"題",
"相",
"關(guān)",
"內(nèi)",
"容",
",",
"暫",
"時(shí)",
"無",
"法",
"提",
"供",
"答",
"案",
"。"
],
"ext":{
},
"output_tokens":null,
"request_id":null,
"input_tokens":null,
"prompt":"{"query": "牧云", "model_id": "daily-top_qad-392", "api_key": "**************", "stream": true, "search_results": [{"id": 1, "content": "\\n產(chǎn)品團(tuán)隊(duì)核心成員曾負(fù)責(zé)阿里云整體內(nèi)部保障,總結(jié)了過去10多年時(shí)間阿里巴巴在企業(yè)安全運(yùn)營(yíng)上的最佳做法,安全運(yùn)營(yíng)團(tuán)隊(duì)?wèi)?yīng)先清晰的知道企業(yè)當(dāng)前面臨的關(guān)鍵挑戰(zhàn)是什么?以及企業(yè)對(duì)風(fēng)險(xiǎn)的容忍度區(qū)間是怎樣的?我們能夠接受什么風(fēng)險(xiǎn)?不能夠接受什么風(fēng)險(xiǎn)?一旦發(fā)生的安全事件超過這個(gè)風(fēng)險(xiǎn)容忍度,將直接導(dǎo)致企業(yè)陷入無法經(jīng)營(yíng)的狀態(tài),業(yè)務(wù)連續(xù)性受到影響。因此只要能夠證明可真正影響到業(yè)務(wù)的風(fēng)險(xiǎn)才是真實(shí)的安全風(fēng)險(xiǎn),應(yīng)被列為最高優(yōu)先級(jí)修復(fù),而所有安全控制措施的唯一目的就是減緩業(yè)務(wù)風(fēng)險(xiǎn)。", "raw_search_result": {"_rc_score": 18.187634, "_q_score": 1.0, "_id": "7606980412276885772_129", "title": "", "_score": 18.187634, "content": "產(chǎn)品團(tuán)隊(duì)核心成員曾負(fù)責(zé)阿里云整體內(nèi)部保障,總結(jié)了過去10多年時(shí)間阿里巴巴在企業(yè)安全運(yùn)營(yíng)上的最佳做法,安全運(yùn)營(yíng)團(tuán)隊(duì)?wèi)?yīng)先清晰的知道企業(yè)當(dāng)前面臨的關(guān)鍵挑戰(zhàn)是什么?以及企業(yè)對(duì)風(fēng)險(xiǎn)的容忍度區(qū)間是怎樣的?我們能夠接受什么風(fēng)險(xiǎn)?不能夠接受什么風(fēng)險(xiǎn)?一旦發(fā)生的安全事件超過這個(gè)風(fēng)險(xiǎn)容忍度,將直接導(dǎo)致企業(yè)陷入無法經(jīng)營(yíng)的狀態(tài),業(yè)務(wù)連續(xù)性受到影響。因此只要能夠證明可真正影響到業(yè)務(wù)的風(fēng)險(xiǎn)才是真實(shí)的安全風(fēng)險(xiǎn),應(yīng)被列為最高優(yōu)先級(jí)修復(fù),而所有安全控制措施的唯一目的就是減緩業(yè)務(wù)風(fēng)險(xiǎn)。"}}, {"id": 2, "content": "\\nWebShell是什么", "raw_search_result": {"_rc_score": 9.906794, "_q_score": 0.5446994369910897, "_id": "5751733942449846217_6", "title": "", "_score": 9.906794, "content": "WebShell是什么"}}, {"id": 3, "content": "\\n1.牧云管理平臺(tái)", "raw_search_result": {"_rc_score": 9.759266, "_q_score": 0.5365879915991272, "_id": "18103204782719913721_10", "title": "", "_score": 9.759266, "content": "1.牧云管理平臺(tái)"}}], "history_messages": [], "temperature": 1.0, "top_p": 0.7, "top_k": 50, "length_penalty": 1.0, "num_doc": 3, "answer_doc": false, "max_new_tokens": 512, "tp_answer": "", "allow_direct_answer": true}"
},
"child_execs":[
{
"start_time":1692850565683,
"trace_id":"f-s-5NRRqmDDUgkNGFLXw88888",
"exec_params":{
"top_p":0.7,
"api_key":"**************",
"stream":false,
"max_new_tokens":512,
"query":"牧云",
"history_messages":[
],
"model_id":"daily-top_qad-392",
"tp_search":""
},
"exec_result":{
"do_search":true
},
"child_execs":null,
"end_time":1692850566121,
"exec_name":"search_toggle",
"exec_status":true,
"exec_kind":"AI_FLOW_STEP",
"exec_message":null
},
{
"start_time":1692850566122,
"trace_id":"f-s-5NRRqmDDUgkNGFLXw88888",
"exec_params":{
"top_p":0.7,
"api_key":"**************",
"stream":false,
"max_new_tokens":512,
"tp_query_rewrite":"",
"query":"牧云",
"history_messages":[
],
"model_id":"daily-top_qad-392"
},
"exec_result":{
"queries_r":[
"牧云是什么"
]
},
"child_execs":null,
"end_time":1692850566617,
"exec_name":"search_rewrite",
"exec_status":true,
"exec_kind":"AI_FLOW_STEP",
"exec_message":null
},
{
"start_time":1692850566618,
"trace_id":"f-s-5NRRqmDDUgkNGFLXw88888",
"exec_params":{
"customConfigInfo":{
"rerankSize":200,
"uqVectorRecallRatio":0.5
},
"page":1,
"uq":"牧云是什么",
"fields":[
"content",
"title"
],
"rows":3,
"type":"title,content",
"scene":"dolphin_search_ms_index_es_113_prod",
"rankModelInfo":{
"rankModelInfo":{
"default":{
"features":[
{
"name":"vector_index",
"threshold":0,
"weights":0.5,
"norm":true
},
{
"field":"_rc_t_score",
"name":"static_value",
"threshold":0,
"weights":0.5,
"norm":true
}
],
"aggregate_algo":"weight_avg"
}
}
}
},
"exec_result":{
"msg":null,
"code":200,
"data":{
"headers":{
"__d_head_rtm":"1692850566901",
"__d_head_sip":"192.168.43.28",
"__d_head_es_rt":"t:32",
"__d_head_engine_rt":"q:104-s:92-r:7-i:65",
"__d_head_ver":"0.0.1-SNAPSHOT"
},
"debug":null,
"data":{
"qpInfos":[
{
"tokenized":[
"牧",
"云",
"是",
"什么"
],
"stopWords":[
],
"spellcheck":false,
"cleanQuery":"牧云是什么",
"query":"牧云是什么",
"sensitive":false,
"synonymWords":[
],
"recognitions":[
{
"name":"O",
"text":"牧"
},
{
"name":"O",
"text":"云"
},
{
"name":"O",
"text":"是"
},
{
"name":"O",
"text":"什么"
}
],
"spellchecked":"牧云是什么",
"rewrite":"牧云是什么",
"operator":"AND"
}
],
"total":89,
"docs":[
{
"_rc_score":18.187634,
"_q_score":1,
"_id":"7606980412276885772_129",
"title":"",
"_score":18.187634,
"content":"產(chǎn)品團(tuán)隊(duì)核心成員曾負(fù)責(zé)阿里云整體內(nèi)部保障,總結(jié)了過去10多年時(shí)間阿里巴巴在企業(yè)安全運(yùn)營(yíng)上的最佳做法,安全運(yùn)營(yíng)團(tuán)隊(duì)?wèi)?yīng)先清晰的知道企業(yè)當(dāng)前面臨的關(guān)鍵挑戰(zhàn)是什么?以及企業(yè)對(duì)風(fēng)險(xiǎn)的容忍度區(qū)間是怎樣的?我們能夠接受什么風(fēng)險(xiǎn)?不能夠接受什么風(fēng)險(xiǎn)?一旦發(fā)生的安全事件超過這個(gè)風(fēng)險(xiǎn)容忍度,將直接導(dǎo)致企業(yè)陷入無法經(jīng)營(yíng)的狀態(tài),業(yè)務(wù)連續(xù)性受到影響。因此只要能夠證明可真正影響到業(yè)務(wù)的風(fēng)險(xiǎn)才是真實(shí)的安全風(fēng)險(xiǎn),應(yīng)被列為最高優(yōu)先級(jí)修復(fù),而所有安全控制措施的唯一目的就是減緩業(yè)務(wù)風(fēng)險(xiǎn)。"
},
{
"_rc_score":9.906794,
"_q_score":0.5446994369910897,
"_id":"5751733942449846217_6",
"title":"",
"_score":9.906794,
"content":"WebShell是什么"
},
{
"_rc_score":9.759266,
"_q_score":0.5365879915991272,
"_id":"18103204782719913721_10",
"title":"",
"_score":9.759266,
"content":"1.牧云管理平臺(tái)"
}
],
"keywords":[
{
"schema":"title,content",
"name":"全文",
"value":"牧云是什么",
"fuzzy":true
}
],
"totalDistinct":89,
"extras":null,
"aggs":null
},
"success":true,
"rid":null,
"message":null,
"status":0
},
"success":true,
"requestId":"3C90873D-CAAB-437D-925A-5E8D90E2E746",
"httpStatusCode":200
},
"child_execs":null,
"end_time":1692850566905,
"exec_name":"search",
"exec_status":true,
"exec_kind":"AI_FLOW_STEP",
"exec_message":null
},
{
"start_time":1692850570204,
"trace_id":"f-s-5NRRqmDDUgkNGFLXw88888",
"exec_params":{
"top_p":0.7,
"api_key":"**************",
"stream":false,
"max_new_tokens":512,
"query":null,
"history_messages":[
{
"role":"user",
"content":"牧云"
},
{
"role":"assistant",
"content":"對(duì)不起,現(xiàn)有搜索結(jié)果中不包含該問題相關(guān)內(nèi)容,暫時(shí)無法提供答案。"
}
],
"model_id":"daily-top_qad-392"
},
"exec_result":{
"queries_s":[
"牧云是什么?",
"牧云有哪些特點(diǎn)?",
"牧云的優(yōu)勢(shì)是什么?"
]
},
"child_execs":null,
"end_time":1692850571168,
"exec_name":"search_recommend",
"exec_status":true,
"exec_kind":"AI_FLOW_STEP",
"exec_message":null
}
],
"end_time":null,
"exec_name":"corp_search.json",
"exec_status":true,
"exec_kind":"AI_FLOW",
"exec_message":null
}按照以下步驟進(jìn)行排查:
首先看第一個(gè){}框起來的dict里面,do_search是否為false。假如do_search為false,需要檢查您撰寫的query不是一個(gè)需要搜索就能得到答案的,例如”你好“之類。如您默認(rèn)所有query都需要搜索,可以聯(lián)系我們幫您開啟強(qiáng)制搜索開關(guān)。
看第二個(gè){}框起來的dict里面,queries_r是否滿足預(yù)期。queries_r是模型對(duì)于您輸入query的一個(gè)重寫(重新表達(dá)),通常用于多輪對(duì)話時(shí)發(fā)生上下文指代的情況。如您默認(rèn)所有query都不需要此類重寫,可以聯(lián)系我們幫您關(guān)閉重寫。
看第三個(gè){}框起來的dict里面,exec_result->data->docs中前num_docs個(gè)文檔中是否包含了目標(biāo)文檔,如果不包含說明沒搜到。這時(shí)需要您在搜索增強(qiáng)模塊調(diào)試出合適的排序公式,確保對(duì)應(yīng)query能夠搜到目標(biāo)文檔。將調(diào)試好的排序公式填寫進(jìn)來,并單擊保存配置。
在確保目標(biāo)文檔出現(xiàn)在前num_docs個(gè)文檔中之后,如仍然返回不符合預(yù)期的結(jié)果,請(qǐng)調(diào)整LLM參數(shù)配置中相關(guān)生成參數(shù)大小以達(dá)到預(yù)期。
搜索增強(qiáng)參數(shù)配置
條數(shù)配置
名詞解釋:知識(shí)條為搜索召回的相關(guān)索引條目,以搜索接口返回字段為結(jié)構(gòu)構(gòu)成,通過排序計(jì)算,相關(guān)度高的知識(shí)條優(yōu)先排序。若“候選知識(shí)條數(shù)”選擇3條,則選擇排序分?jǐn)?shù)最高的三條知識(shí)條作為參考內(nèi)容傳給下游大模型。
數(shù)值限制:當(dāng)前模型上限閾值為6000,閾值=候選知識(shí)條數(shù)*單條知識(shí)長(zhǎng)度。
推薦值:候選知識(shí)條數(shù)為3,單條知識(shí)長(zhǎng)度上限為1000。
功能描述:控制輸入給大模型的知識(shí)條范圍。
Tips:
若候選知識(shí)條數(shù)越多,則大模型的回復(fù)泛化性越高,但由于存在模型上限閾值,其單條知識(shí)長(zhǎng)度有限,若知識(shí)長(zhǎng)度過短,則可能導(dǎo)致信息不完整,影響大模型回復(fù)的精準(zhǔn)度。
多路召回-向量召回比例
名詞解釋:召回模型主要包括文本相關(guān)性召回和語義向量召回。其中文本相關(guān)性召回是從文本分詞后的詞粒度的一致性上做文檔召回,語義向量召回是指將文本轉(zhuǎn)為語義向量后在向量空間里的尋找空間距離最靠近的文檔作為召回。
推薦值:目前建議50%,表示文本召回和語義向量召回的文檔數(shù)各占總召回?cái)?shù)量的一半。
功能描述:控制query召回時(shí)向量召回部分占所有召回?cái)?shù)量的比例。
Tips:
若希望不使用向量召回(僅用文本相關(guān)性召回)設(shè)置為0%,當(dāng)前版本不支持僅向量召回(不建議設(shè)置成100%)。
精排DOC數(shù)量
名詞解釋:進(jìn)入精排計(jì)算的最大文檔數(shù)量。
推薦值:200-500。
功能描述:query在召回所有相關(guān)文本后,會(huì)基于召回的結(jié)果做一個(gè)基礎(chǔ)的相關(guān)性打分并排序,當(dāng)召回的文檔數(shù)目總數(shù)大于當(dāng)前設(shè)置的精排DOC數(shù)量N時(shí),會(huì)取基礎(chǔ)相關(guān)性打分最高的TOP N進(jìn)入精排計(jì)算。
Tips:
該數(shù)字越大表示用于精排的文檔數(shù)越多,對(duì)于最終效果會(huì)更好,但精排計(jì)算所消耗時(shí)間會(huì)更長(zhǎng)。
自定義排序公式
名詞解釋:產(chǎn)品提供了豐富的排序特征供用戶根據(jù)實(shí)際情況實(shí)現(xiàn)自定義排序。排序公式為JSON格式,配置在rankModelInfo中。內(nèi)置的排序模型將會(huì)根據(jù)rankModelInfo指定的排序公式對(duì)召回結(jié)果根據(jù)排序特征進(jìn)行打分,并計(jì)算最終的排序分?jǐn)?shù)以及排序結(jié)果。內(nèi)置的排序模塊提供了多種排序特征,并且支持對(duì)每個(gè)特征配置對(duì)應(yīng)索引字段,權(quán)重,閾值,以及是否歸一化等。
rankModelInfo
自定義排序公式配置字段,包含對(duì)原始query以及extra query的排序公式,每類排序公式為dict類型,dict名稱為對(duì)應(yīng)的查詢字段名稱。(默認(rèn)query(uq)的排序公式類型名為“default",額外的查詢排序公式類型名為其對(duì)應(yīng)的在"extras"字段對(duì)應(yīng)的查詢名稱)。
排序公式
每類排序公式的具體內(nèi)容包含 "features" 以及 "aggregate_algo"兩部分。“features” 為具體排序特征及其參數(shù)的列表。 "aggregate_algo"目前僅支持“weight_avg",即對(duì)所有特征加權(quán)求和。
特征
每一項(xiàng)特征為dict格式,包含特征名稱以及特征參數(shù)。特征通用參數(shù)如下:
特征通用參數(shù)
name: 特征名
field: 計(jì)算相關(guān)性特征的索引字段
weights: 特征權(quán)重,為float類型
threshold: 特征分?jǐn)?shù)閾值,float類型。低于閾值的特征分?jǐn)?shù)將被置為0(注意:threshold 過濾值為normalize前分?jǐn)?shù))
norm: 是否將特征進(jìn)行歸一化bool類型
norm_factor:float類型, 歸一化系數(shù),用于調(diào)節(jié)歸一化后的分?jǐn)?shù)分布。
具體每項(xiàng)特征具體說明如下:
特征說明:
特征名 | 說明 | 特征特殊參數(shù) |
vector_index | 向量匹配分?jǐn)?shù)(需配置向量召回) | score_type: 向量檢索分?jǐn)?shù)計(jì)算類型,可選擇L2(越相關(guān)分?jǐn)?shù)越大)與IP(越相關(guān)分?jǐn)?shù)越小),默認(rèn)為IP。需要根據(jù)向量引擎配置選擇合適的score_type。 |
text_index | 搜索引擎召回得分 Tips:該特征只支持僅文本召回時(shí)使用。使用多路召回(向量+搜索引擎)時(shí),可以使用static_value獲得ES召回得分(field 配置為“_rc_t_score") | |
timeliness | 時(shí)效性得分,正比于給定時(shí)間字段與基礎(chǔ)時(shí)間相差的毫秒數(shù),取值范圍為[0,1] | time_field(str):時(shí)間字段名,格式為:"%Y-%m-%d %H:%M:%S.%f" field(str): 字段名,與時(shí)間字段名保持一致 base_time(str): 基礎(chǔ)時(shí)間字段,格式為: "%Y-%m-%d %H:%M:%S",應(yīng)設(shè)置為最初始文檔的時(shí)間 normalized_number(float): 控制時(shí)效性得分的顆粒度,通常應(yīng)設(shè)置為1e6 |
doc_match_ratio | 字段與查詢匹配詞個(gè)數(shù)與該字段總詞數(shù)的比值 | |
query_match_ratio | 查詢與字段匹配詞個(gè)數(shù)與查詢總詞數(shù)的比值 | |
doc_match_count | 字段與查詢匹配詞個(gè)數(shù) | |
query_match_count | 查詢與字段匹配詞個(gè)數(shù) | |
query_min_slide_window | 衡量查詢與字段詞匹配緊密度,即查詢?cè)谧侄紊掀ヅ涞脑~個(gè)數(shù)與字段上包含對(duì)應(yīng)詞最小窗口的比值(不考慮查詢匹配順序)。 | |
ordered_query_min_slide_window | 衡量查詢與對(duì)應(yīng)字段匹配緊密度,查詢?cè)~在某個(gè)字段上命中的分詞詞組個(gè)數(shù)與該詞組在字段上最小窗口的比值(有順序匹配)。 | |
doc_unique_ratio | 字段非重復(fù)詞個(gè)數(shù)與總詞數(shù)的比值,用于篩選重復(fù)關(guān)鍵詞的文檔。 | |
overlap_coefficient | 查詢與字段匹配詞個(gè)數(shù)與查詢與字段總詞數(shù)比值,衡量文本匹配度。 | |
char_overlap_coefficient | 查詢與字段匹配字符數(shù)與查詢與字段總字符數(shù)比值,衡量字符級(jí)別相似度。 | |
lcs_match_ratio | 查詢與字段詞級(jí)別長(zhǎng)度與查詢?cè)~數(shù)的比值。 | |
char_lcs_match_ratio | 查詢與字段字級(jí)別長(zhǎng)度與查詢字符個(gè)數(shù)的比值,適用于email, mobile 等字符串匹配場(chǎng)景。 | |
edit_similarity | 根據(jù)字段與查詢的編輯距離計(jì)算的文本相似度,取值為0-1,越高代表兩者越相似。用于衡量查詢與對(duì)應(yīng)字段完全匹配的程度。適用于問題與問題進(jìn)行匹配的場(chǎng)景,建議配合較高閾值使用。 | |
char_edit_similarity | 字符級(jí)別的編輯相似度。 | |
char_sequential_match_priority | 適用于人名匹配專用特征(考慮匹配順序)。按順序計(jì)算字符級(jí)別的順序匹配度,第i個(gè)字的匹配相似度為 1/ |i-j|, j代表對(duì)應(yīng)字段中與之最近的相同字符。第i個(gè)字權(quán)重為1.0 / i。最終得分為所有字相似度的加權(quán)平均。 該特征用于計(jì)算與順序相關(guān)的文本相似度。 | |
pinyin_lc_substr | 查詢與字段拼音最長(zhǎng)公共子串長(zhǎng)度與對(duì)應(yīng)字段拼音長(zhǎng)度的比值,衡量拼音相似度 | |
doc_pinyin_lc_substr | 查詢與字段拼音最長(zhǎng)公共子串長(zhǎng)度與查詢拼音長(zhǎng)度的比值,衡量拼音相似度 | |
static_value | 將數(shù)字字段本身作為特征分?jǐn)?shù)。 | |
name_pinyin_match | 人名拼音匹配專用特征,判斷查詢與對(duì)應(yīng)字段的拼音全拼,拼音首字母縮寫,首字母與全拼的混合進(jìn)行匹配。如某人名字段值為“張三”,該特征將檢查查詢的拼音是否為["zhangsan","zs","zhangs","zsan"] 中的任意一種,如果匹配成功,返回1分,否則返回0分。人名拼音匹配專用特征 | |
prefix_match_ratio | 詞級(jí)別前綴匹配特征,匹配得分為查詢與字段最長(zhǎng)公共前綴長(zhǎng)度/查詢長(zhǎng)度。(前綴匹配指查詢和文檔從第一個(gè)位置開始每個(gè)詞按順序匹配,能完全匹配的最長(zhǎng)字符子串)。適用于對(duì)匹配位置有要求的場(chǎng)景(如郵箱匹配,首位匹配相關(guān)性更高),建議與其他特征共同使用(如lcs_match_ratio) | |
char_prefix_match_ratio | 字符級(jí)別前綴匹配特征,匹配得分為查詢與字段最長(zhǎng)公共前綴長(zhǎng)度/查詢長(zhǎng)度。適用于對(duì)匹配位置有要求的場(chǎng)景(如郵箱匹配,首位匹配相關(guān)性更高),建議與其他特征共同使用(如lcs_match_ratio) | |
pinyin_prefix_match_ratio | 拼音前綴匹配特征,匹配得分為查詢與對(duì)應(yīng)字段最長(zhǎng)公共前綴長(zhǎng)度/查詢長(zhǎng)度。適用于對(duì)匹配位置有要求的場(chǎng)景(如郵箱匹配,首位匹配相關(guān)性更高),建議與其他特征共同使用(如lcs_match_ratio) | |
is_contained | 查詢是否包含在給定字段里(list類型)某一項(xiàng)完全匹配,用于匹配標(biāo)簽。對(duì)應(yīng)索引字段必須為list[string]類型。 | |
contained_boost | 完整的查詢?cè)诮o定字段中出現(xiàn)的次數(shù),用于提高完全匹配查詢的匹配度。 | |
part_of_doc | 完整的查詢?cè)诮o定字段中是否出現(xiàn)(出現(xiàn)為1,不出現(xiàn)為0),用于提高完全匹配查詢的匹配度。 |
最佳實(shí)踐
Tips:以下例子均假設(shè)在索引中存在名為“content"的字段。
{
"rankModelInfo":{
"default":{
"features":[
{
"name":"text_index",
"weights":1,
"threshold":10,
"norm":true
},
{
"name":"query_match_ratio",
"weights":1,
"threshold":0,
"field":"content"
}
],
"aggregate_algo":"weight_avg"
}
}
}{
"rankModelInfo":{
"default":{
"features":[
{
"name":"static_value",
"field":"_rc_t_score",
"weights":1,
"threshold":10,
"norm":true
},
{
"name":"vector_index",
"weights":1,
"threshold":0,
"norm":true,
"norm_factor":0.001,
"score_type": "L2"
},
{
"name":"query_match_ratio",
"weights":1,
"threshold":0,
"field":"content"
}
],
"aggregate_algo":"weight_avg"
}
}
}{
"rankModelInfo": {
"default": {
"features": [
{
"name": "static_value",
"field": "_rc_t_score",
"weights": 1,
"threshold": 10,
"norm": true
},
{
"name": "vector_index",
"weights": 1,
"threshold": 0,
"norm": true,
"norm_factor": 0.001,
"score_type": "L2"
},
{
"name": "query_match_ratio",
"weights": 1,
"threshold": 0,
"field": "title"
}
],
"aggregate_algo": "weight_avg"
}
},
"keyword": {
"features": [
{
"name": "query_match_ratio",
"weights": 1,
"threshold": 0,
"field": "content"
}
],
"aggregate_algo": "weight_avg"
}
}本例子展示了一個(gè)帶額外查詢“keyword”的排序公式,用戶需要在"extras"字段內(nèi)配置與特征字段名相同的查詢字段(本例中為“keyword")
對(duì)話測(cè)試
完成所有參數(shù)配置并保存后,即可進(jìn)行對(duì)話測(cè)試。您可在界面上通過輸入框或多輪對(duì)話搜索API,輸入您的問題,即可得到所對(duì)應(yīng)的回答。LLM大模型將把搜索得到的知識(shí)片段與上下文信息進(jìn)行總結(jié)和生成,從而進(jìn)行問題的回答。