產(chǎn)品簡介
產(chǎn)品簡介
阿里巴巴通義實驗室千尋搜索算法,基于達摩院長期積累的自然語言處理技術(shù),專注企業(yè)統(tǒng)一搜索場景,提供精準的多源異構(gòu)搜索,以PaaS服務形式提供離線數(shù)據(jù)處理和搜索服務API。同時支持公有云、專有云、 基于云原生的基礎(chǔ)架構(gòu)下混合云 、私有化方式輸出。
產(chǎn)品基于自然語言處理、機器學習技術(shù)和企業(yè)內(nèi)部知識庫,從相關(guān)性到認知智能,將語義、知識融入搜索過程和結(jié)果,提供高效、高準確率的搜索服務產(chǎn)品,幫助用戶搜得到、搜得全、搜得準。面向企業(yè)客戶,提供交互式多輪對話搜索、通訊錄搜索、地址搜索、文檔搜索等能力。面向企業(yè)和大模型的交互場景,提供檢索增強能力。
產(chǎn)品優(yōu)勢
場景化、簡單易用
開發(fā)者/ISV從0開始搭建搜索全鏈路門檻較高、有困難,千尋搜索算法針對企業(yè)內(nèi)統(tǒng)一搜索的幾大核心場景提供全鏈路搜索配置引導和默認算法能力支持。
行業(yè)領(lǐng)先的算法效果
全自研多語言Query分析能力(分詞、NER、糾錯、改寫、分類等)。全鏈路算法結(jié)合LLM,算法效果驅(qū)動,中文多領(lǐng)域Embedding在檢索數(shù)據(jù)集MRR@10表現(xiàn)優(yōu)異。多路召回加精排相比純向量檢索, MRR@10及Recall顯著提升。
靈活的搜索工程框架
支持多數(shù)據(jù)源;支持離線智能數(shù)據(jù)處理(文本、文檔等)、支持ES等多引擎,系統(tǒng)組件支持模塊化(比如搜索引擎兼容等)。
安全、穩(wěn)定、高魯棒性
服務穩(wěn)定運行,并以在線工單等方式提供技術(shù)支持,具備完善的故障監(jiān)控、自動告警、快速定位等一系列故障應急響應機制。基于阿里云的AccessKeyId和AccessKeySecret安全加密對,從訪問接口上進行權(quán)限控制和隔離,保證用戶級別的數(shù)據(jù)隔離,用戶數(shù)據(jù)安全有保障。
應用場景
搜人
大型企業(yè)員工眾多,需要多部門協(xié)同,可以通過員工姓名或部門等進行人員或部門的精確搜索,以卡片形式展示搜索信息,并可以鏈接到員工/部門組織架構(gòu),幫忙快速查詢對應業(yè)務人員,提升部門間協(xié)同效率。
搜內(nèi)容
對散落在各業(yè)務系統(tǒng)的內(nèi)容資源和業(yè)務資源的全方位、多層面整合,建立全面的知識服務應用體系,結(jié)合各部門的需求,滿足不同用戶差異化的智能檢索。
搜應用
大型企業(yè)有很多的業(yè)務應用和導航鏈接,通過統(tǒng)一搜索,不同角色可以搜索權(quán)限范圍內(nèi)的應用/導航,可以快速鏈接到對應的應用/導航,幫助提升員工自助效率。
搜地址
提供21級結(jié)構(gòu)化標準地址數(shù)據(jù),結(jié)合企業(yè)自身的地址數(shù)據(jù),為企業(yè)提供統(tǒng)一標準的地址搜索服務。零售、能源、司法公安等多個行業(yè)場景均有強烈訴求。
泛場景基礎(chǔ)搜索效果提升
基于達摩院NLP算法能力構(gòu)建的搜索增強服務,幫助用戶針對自有數(shù)據(jù)快速構(gòu)建智能搜索服務,支持包括且不限于文本搜索、文檔搜索、通訊錄搜索、地址搜索等多種不同的搜索場景 。
智能客服助手
結(jié)合企業(yè)專屬知識庫,以對話機器人交互方式進行多輪對話問答,完成通識類或企業(yè)專屬類問題快速解答,避免企業(yè)用戶多源頭人工搜索并總結(jié)繁瑣流程,有效提升效能。
功能模塊
搜索增強
功能簡介
搜索增強是基于大規(guī)模分布式搜索引擎搭建的,面向企業(yè)提供的一站式智能搜索PaaS服務,為企業(yè)開發(fā)人員提供基礎(chǔ)結(jié)構(gòu)、API 和搜索工具。服務集成全自研多語言query分析能力(分詞、NER、糾錯、改寫、分類等),多模型結(jié)構(gòu)的預訓練向量表示能力(encoder-only、decoder-only),混合召回和多因子排序能力(文本匹配、深度語義匹配)等,相對比純向量檢索,提升為行業(yè)領(lǐng)先搜索效果。
功能優(yōu)勢
優(yōu)勢1:行業(yè)領(lǐng)先的Chunk分析及文件解析能力
基于阿里巴巴達摩院自研IDP服務,對于不同格式數(shù)據(jù)源,進行切片,生成chunk數(shù)據(jù),并加入一定量文本理解。
優(yōu)勢2:行業(yè)領(lǐng)先的搜索增強算法
全自研多語言Query分析能力,多模型結(jié)構(gòu)的預訓練向量表示能力,混合召回和多因子排序能力,多路召回加精排, 相比純向量檢索, MRR@10提升28%,Recall提升21.6%。
應用場景
針對企業(yè)泛搜索場景,對大模型進行搜索能力與效果增強。
多輪對話搜索
功能簡介
多輪對話搜索是搜索與大模型的結(jié)合能力,支持用戶基于自己的專有知識庫搭建新一代的生成式搜索應用。區(qū)別于傳統(tǒng)關(guān)鍵詞匹配的搜索引擎,生成式搜索支持用戶通過對話式交互來清晰地表達意圖,并對查詢到的知識根據(jù)用戶意圖進行個性化表達,生產(chǎn)更加清晰明確的回復。
功能優(yōu)勢
優(yōu)勢1:創(chuàng)新的對話式交互體驗
支持用戶以對話的形式來清晰地表達意圖。通過多輪次、深度的對話來滿足用戶的查詢需求。
優(yōu)勢2:靈活的智能搜索引擎
支持用戶靈活配置索引以及多種召回排序算法,將語義、知識融入搜索過程中,提供高效、高準確率的搜索能力。
優(yōu)勢3:可信的答案回復
內(nèi)置搜索版通義千問大模型,事實性、可靠性大幅提升。結(jié)合用戶本地知識庫降低答案幻覺。
應用場景
場景1:智能客服助手
集成企業(yè)產(chǎn)品信息,幫助處理用戶咨詢和問題,提高客服效率和用戶滿意度。
場景2:自然語言企業(yè)內(nèi)部知識庫
集成企業(yè)內(nèi)部知識庫,幫助員工快速查找所需信息,打造員工專屬主力,提高工作效率。
千尋搜索算法原子能力
功能簡介
能力1:多輪query改寫
對用戶輸入的原始語句進行算法改寫,使得模型更好理解及達到更好搜索召回效果,并支持多輪操作。
能力2:搜索判定
對于用戶原始查詢語句進行判斷,是否需要進行搜索任務來完成查詢及回答。
能力3:通用排序模型
對數(shù)據(jù)元素進行算法排序。
功能優(yōu)勢
行業(yè)領(lǐng)先的搜索算法,全自研多語言Query分析能力,多模型結(jié)構(gòu)的預訓練向量表示能力,混合召回和多因子排序能力,多路召回加精排, 相比純向量檢索, MRR@10提升28%,Recall提升21.6%。
應用場景
針對企業(yè)泛搜索場景,對大模型進行搜索能力與效果增強。
產(chǎn)品如何調(diào)用
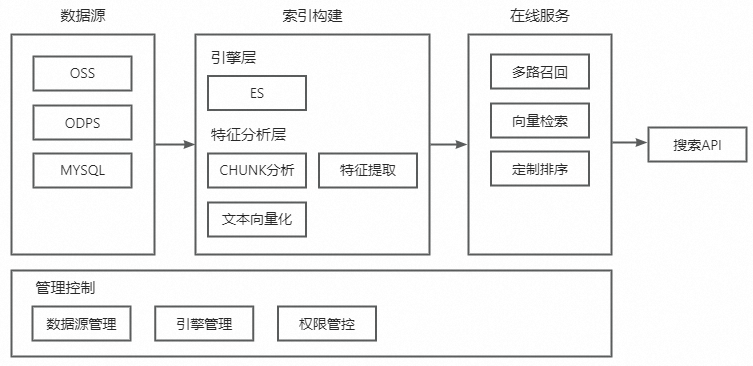
基本概念
名詞 | 描述 |
應用場景 | 搜索應用場景指的是在各種不同環(huán)境和情境下,使用搜索技術(shù)來查找和獲取所需信息的情況。搜索應用場景廣泛應用于互聯(lián)網(wǎng)、移動應用、企業(yè)內(nèi)部系統(tǒng)、智能設(shè)備等各個領(lǐng)域。常見的搜索應用場景包括互聯(lián)網(wǎng)搜索、電子商務搜索、社交媒體搜索等等 |
檢索引擎 | 文本檢索引擎是一種用于從大量文本數(shù)據(jù)中快速檢索相關(guān)信息的軟件工具。它能夠根據(jù)用戶的查詢詞或關(guān)鍵字,從文本數(shù)據(jù)庫中找到相關(guān)的文檔或記錄,并將其按照相關(guān)性排序后返回給用戶。 |
搜索策略 | 針對特定搜索場景制定的搜索方案、包括查詢召回策略、排序策略、業(yè)務邏輯篩選等 |
索引 | 檢索引擎索引是指將大量文本數(shù)據(jù)進行結(jié)構(gòu)化存儲和標記的過程。在建立索引時,文本檢索引擎會對每個文檔進行分析和處理,提取出其中的關(guān)鍵詞和其他重要信息,并將其存儲到索引結(jié)構(gòu)中。索引結(jié)構(gòu)可以是多種形式,如倒排索引、哈希表或B樹等。通過索引,檢索引擎能夠快速定位到包含查詢關(guān)鍵詞的文檔,提高檢索效率。索引的建立是文本檢索引擎的重要步驟,它直接影響到后續(xù)查詢處理和結(jié)果展示的速度和準確性。 |
索引字段 | 檢索引擎索引字段是指在建立索引時,將數(shù)據(jù)中的特定字段進行提取和存儲,以便在后續(xù)查詢時能夠快速定位到相關(guān)文檔。例如,在電子郵件檢索中,可以通過索引字段"發(fā)件人"和"收件人"來查找特定的郵件。索引字段的選擇和設(shè)計需要根據(jù)具體應用場景和需求來確定,以提高檢索的準確性和效率。合理使用索引字段可以提高檢索引擎的性能和用戶體驗。 |
召回 | 搜索召回是指搜索產(chǎn)品根據(jù)用戶的查詢詞,在龐大的數(shù)據(jù)集中找出與查詢相關(guān)的文檔,一般通過算法模型或規(guī)則匹配文檔的關(guān)鍵詞、標題、內(nèi)容等信息,以及利用文檔的相關(guān)性、權(quán)重等指標進行排序以提供準確、快速的搜索結(jié)果 |
排序 | 對召回結(jié)果進行進一步的排序。通過算法、模型或規(guī)則,根據(jù)文檔的相關(guān)性、權(quán)重、用戶反饋等指標,將搜索結(jié)果按照一定的順序返回。搜索排序的目標是提高搜索結(jié)果的準。搜索排序算法通常會考慮多個因素,如關(guān)鍵詞匹配度、文檔的質(zhì)量、用戶偏好等,以提供個性化的搜索結(jié)果。 |
數(shù)據(jù)源 | 提供數(shù)據(jù)的源點,會根據(jù)這些數(shù)據(jù)來構(gòu)建私域知識庫,用于后續(xù)的檢索、知識問答 |
大模型 | 大規(guī)模預訓練語言模型是指使用海量文本數(shù)據(jù)進行預訓練的語言模型。它通過學習大量的語言知識和語境信息,能夠生成高質(zhì)量的文本或提供語義理解。大規(guī)模預訓練語言模型在自然語言處理任務中展現(xiàn)出強大的能力,如文本生成、機器翻譯、問答系統(tǒng)等。然而,這樣的模型需要大量的計算資源進行訓練和推理,并對數(shù)據(jù)集的質(zhì)量和多樣性要求較高。大規(guī)模預訓練語言模型是當前自然語言處理領(lǐng)域的重要研究方向。 |