如果您的文檔格式比較固定,需要抽取的字段有明確和固定的上下文,我們還提供了一些規則設置方法對模型進行補充支持,進一步提升實體抽取模型的表現。這種方式不需要大量標注,準確率也非常高,如果您的界面上看不到規則配置的入口,請聯系我們為您開通白名單。另外,我們在高級設置中還預設了一些字段(手機號等),用戶無需任何標注就可以自動抽取。在創建模型時可以配置。規則引擎的界面如下:
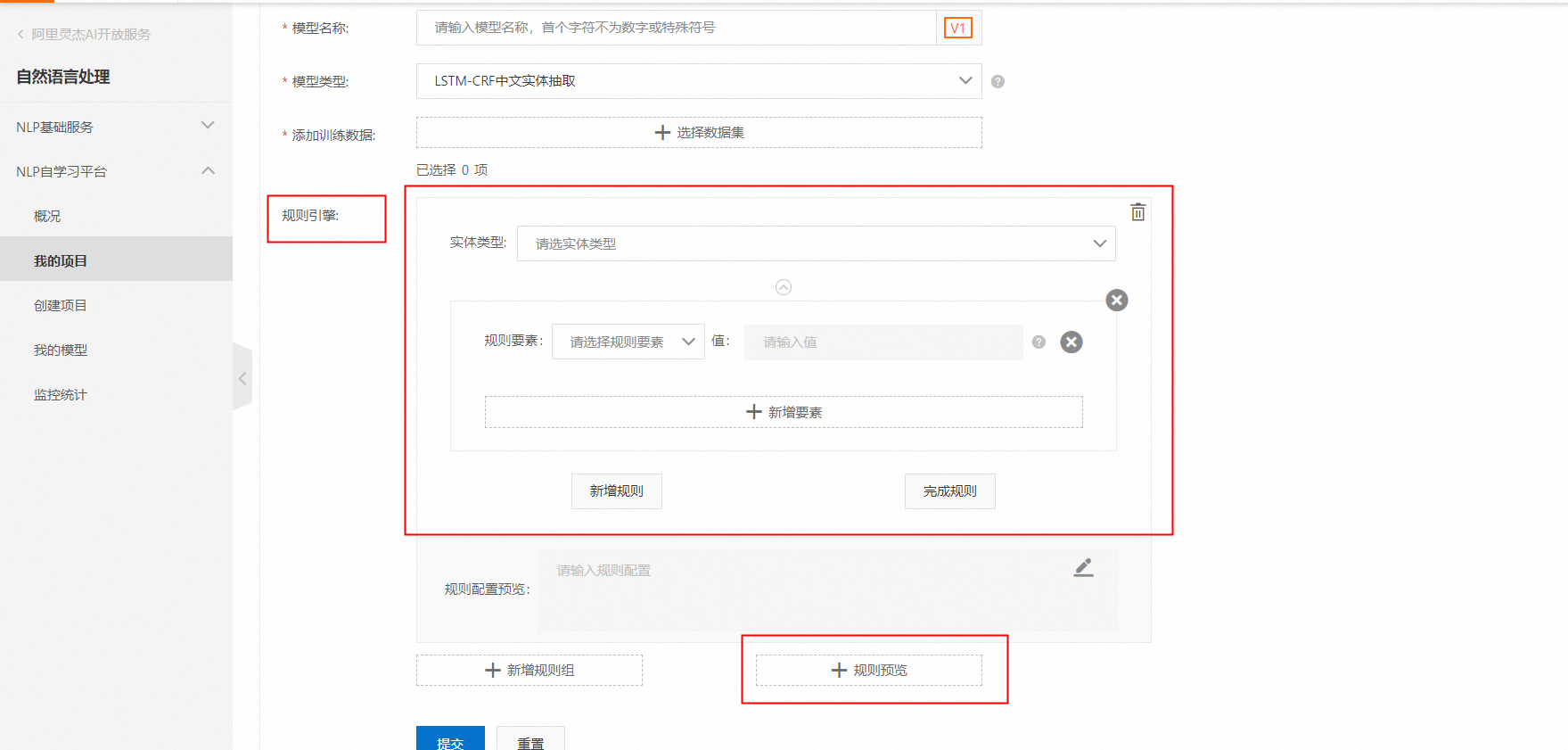
您可以通過規則配置來配置正則、詞典、任意字符和模型抽出的實體的組合等“規則”,并且通過規則預覽可以測試下您的規則是否生效。
規則配置示例
有如下裁判文書,需要抽取原告和被告的姓名,性別,出生年月。
原告:橙小二,女,住所地浙江省杭州市余杭區。\n\n 被告:王某某,男,2019 年10 月1 日出生,漢族。
可以使用規則引擎來配置正則表達式,抽取出這些字段。
先后點擊:新增規則組->實體類型選原告->規則要素選擇正則表達式->值填入:(?<=原告:)([^,]+)(?=,)
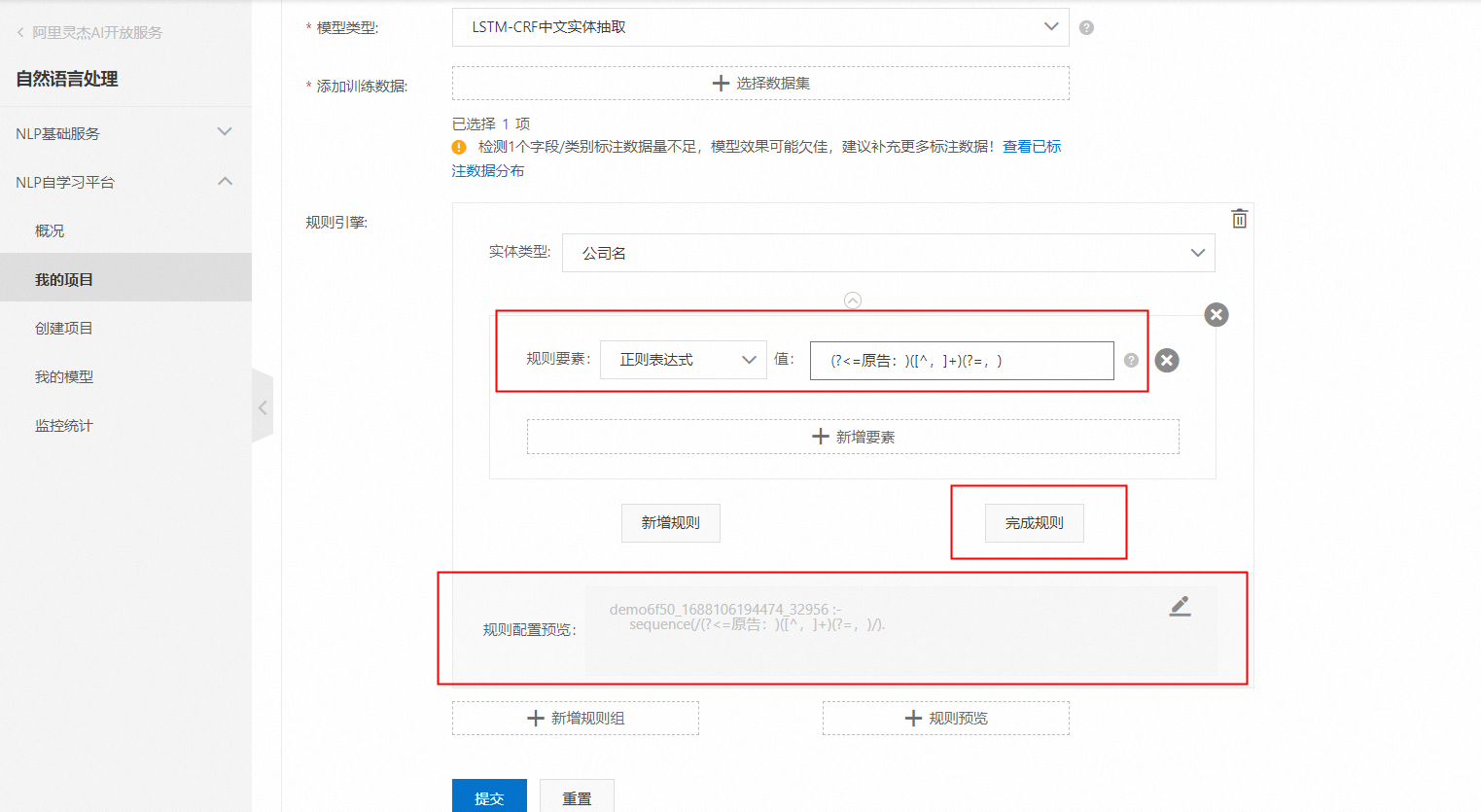
配置好幾個規則后,點擊規則預覽,則可以檢查剛剛配置的規則: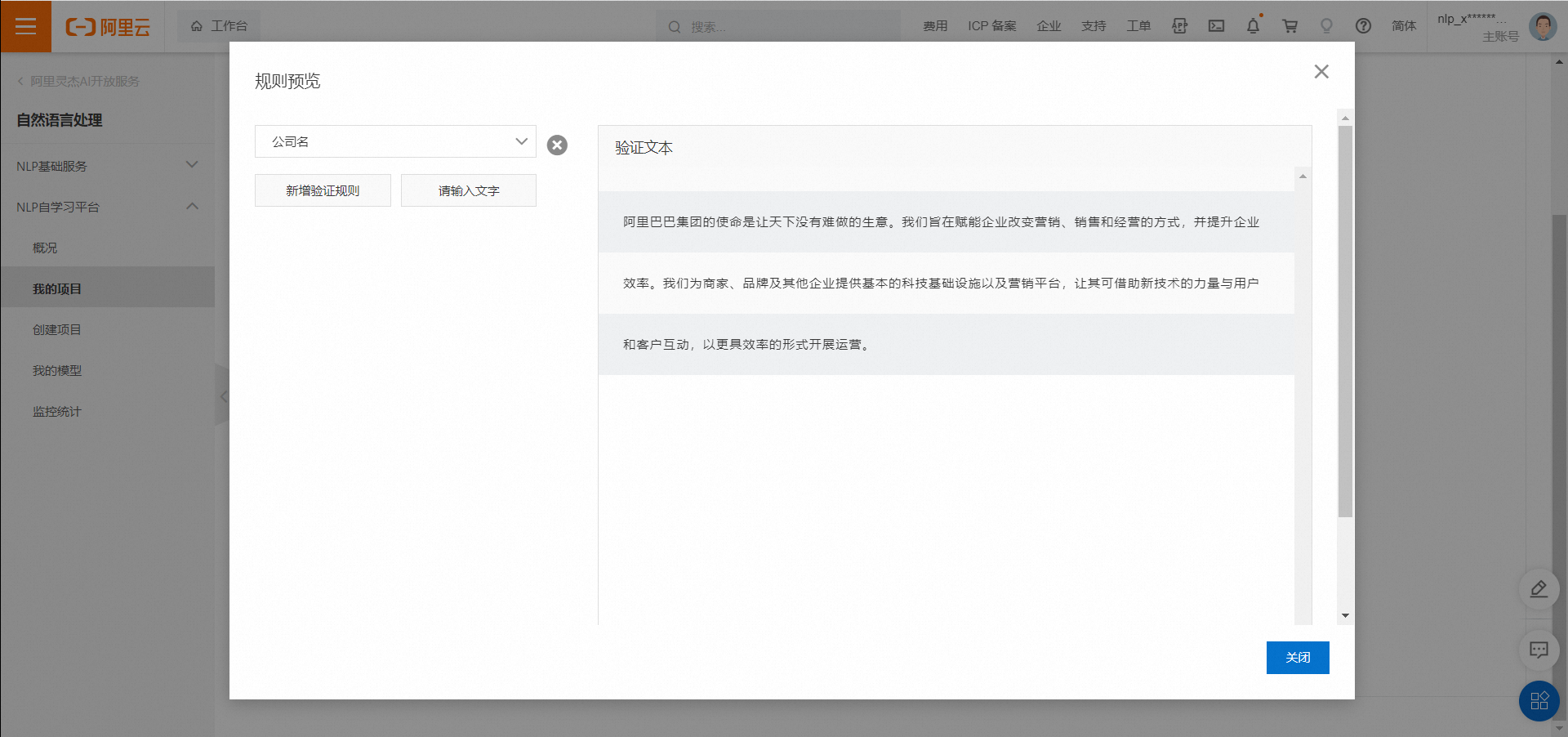
高級設置
我們在高級設置中還預設了通用字段的抽取,方便用戶直接抽取這些類型的字段,而無需提供任何標注。當前支持的通用字段有手機號碼。
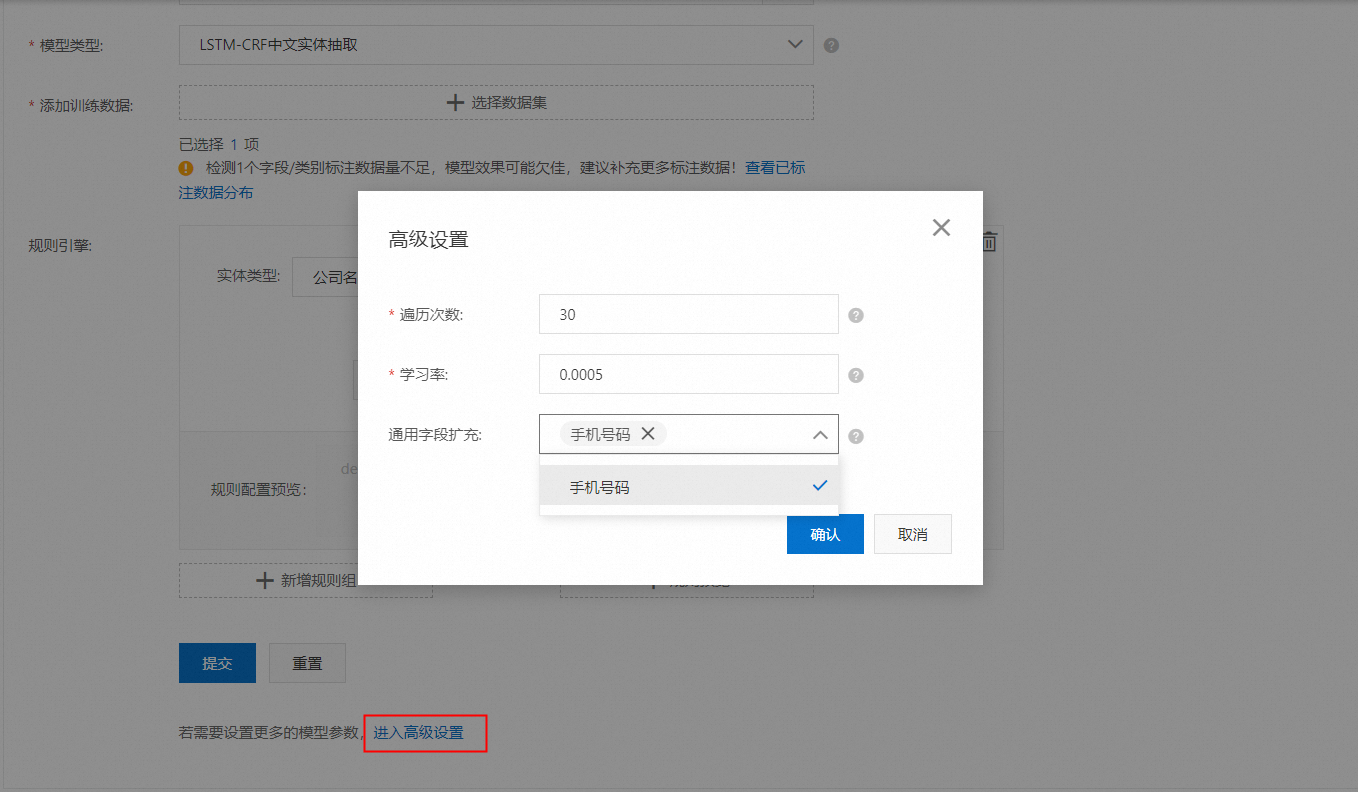
在這個高級設置中,除了通用字段擴充,還有遍歷次數和學習率。通常使用默認值即可,在“結果優化”一章會有更具體的說明
文檔內容是否對您有幫助?