完成了數據集的構建,就可以開始模型的訓練了。回到創建的項目,切換至“模型中心”并點擊“創建模型”。
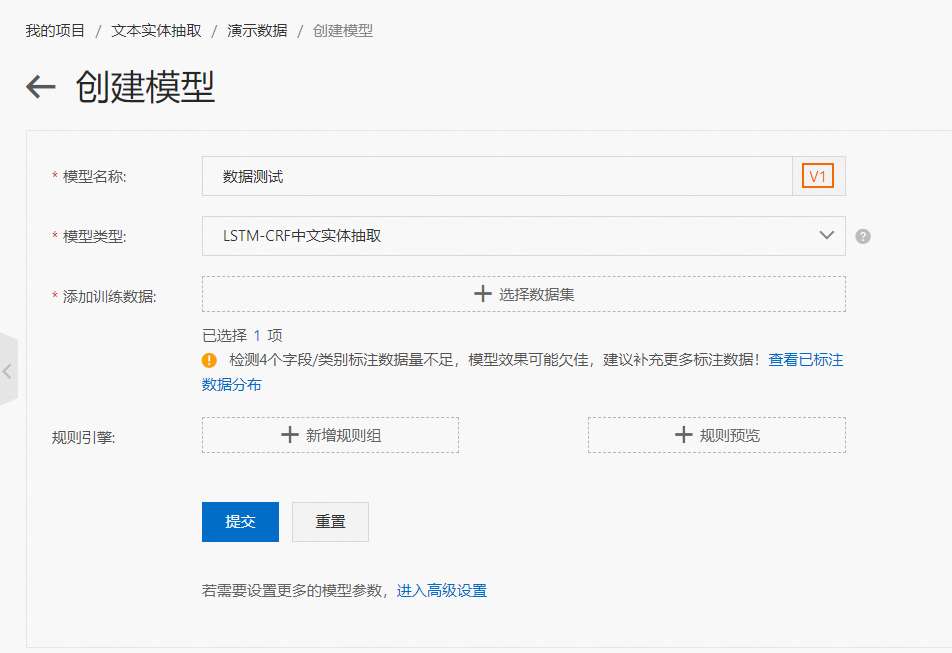
進入創建模型后,通過自學習平臺,您無需關心任何模型的實現細節,只要選擇相應的模型就可以開始訓練。首先請填入模型的名稱。
在模型類型處,我們提供了多個類型的模型供您選擇,支持中文實體抽取或是英文實體抽取服務。您可以在模型說明中查看詳情。
系統默認會選擇中文的LSTM-CRF 模型。點擊添加訓練數據的按鈕,可以找到您已經標注或上傳好的數據集。至此,您就可以點擊提交,模型將會自動開始訓練。在創建模型這里我們還會看到幾個選項,比如專業詞表上傳和正則表達式設置,以及高級設置。這些內容將在“規則引擎和高級設置一章”詳細闡述。
在模型完成初始化后,自動進入模型訓練階段。點擊“查看”,可以進入模型詳情頁面,查看訓練日志和具體的評測指標。
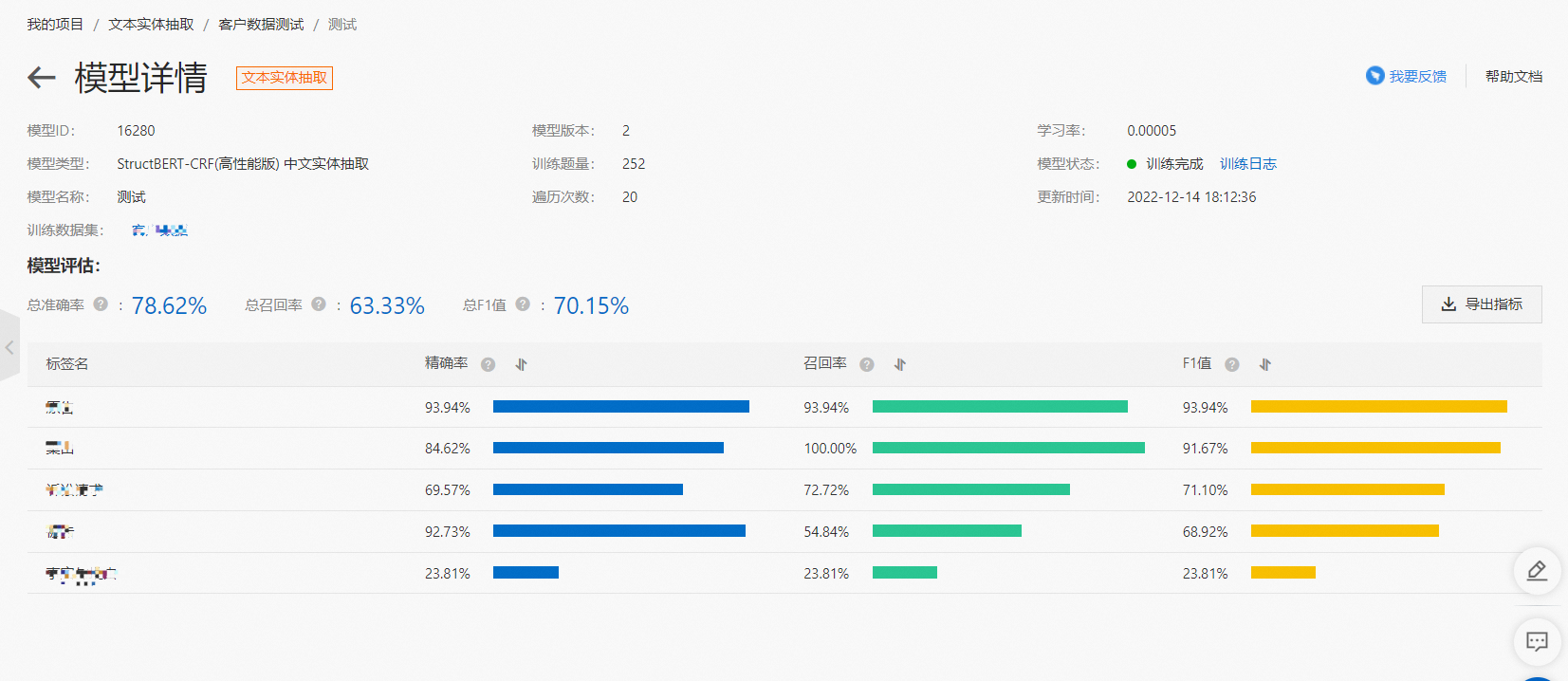
我們提供了精確率(Precision),召回率(Recall),F1值作為實體抽取的評測指標。這三個值得取值范圍都在 0~1 之間。簡單來說,這三個值越大說明模型的性能越好。
精確率(Precision):對某一類別而言為正確預測為該類別的樣本數與預測為該類別的總樣本數之比。對于整體而言為正確預測的樣本數與預測的總樣本數之比。
召回率(Recall):對某一類別而言為正確預測為該類別的樣本數與該類別的總樣本數之比,對于整體而言為正確預測的樣本數與所有類別的總樣本數之比。
F1值:為精確率和召回率的調和平均數。
文檔內容是否對您有幫助?