除了通過JSON文件來創建數據集的方式,如果您暫時沒有標注數據,也可以通過我們的標注平臺來標注數據。
接下來,通過一個例子來演示標注平臺的使用。在第一步創建剛剛創建好的項目中,選擇創建標注任務
注意:目前僅支持UTF-8編碼方式的數據文件
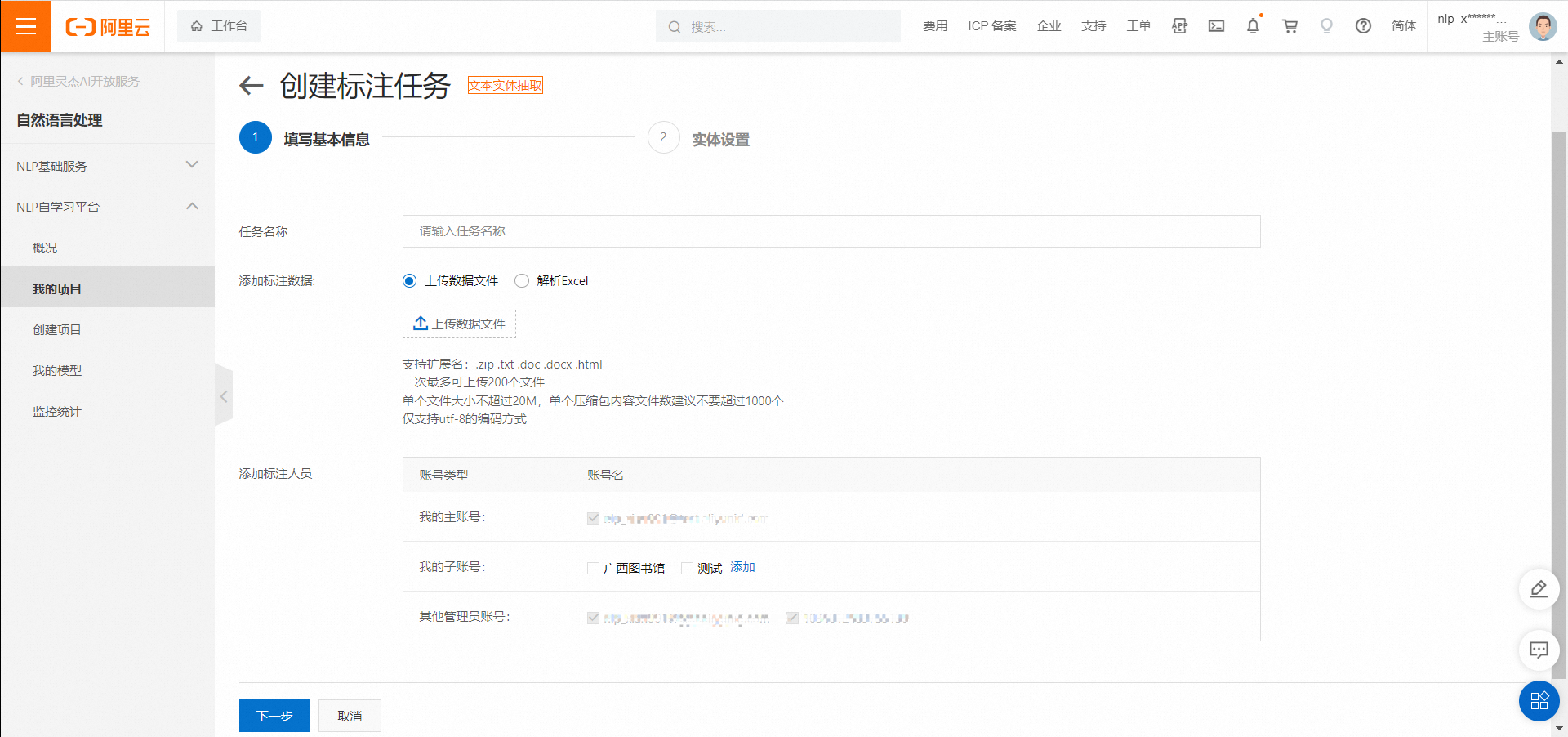
填寫數據集的名稱后,您需要上傳待標注的原始數據文件。上傳完成后點擊下一步,進入實體名稱的設置頁面,點擊添加實體,輸入您需要抽取的實體的名稱,如下:
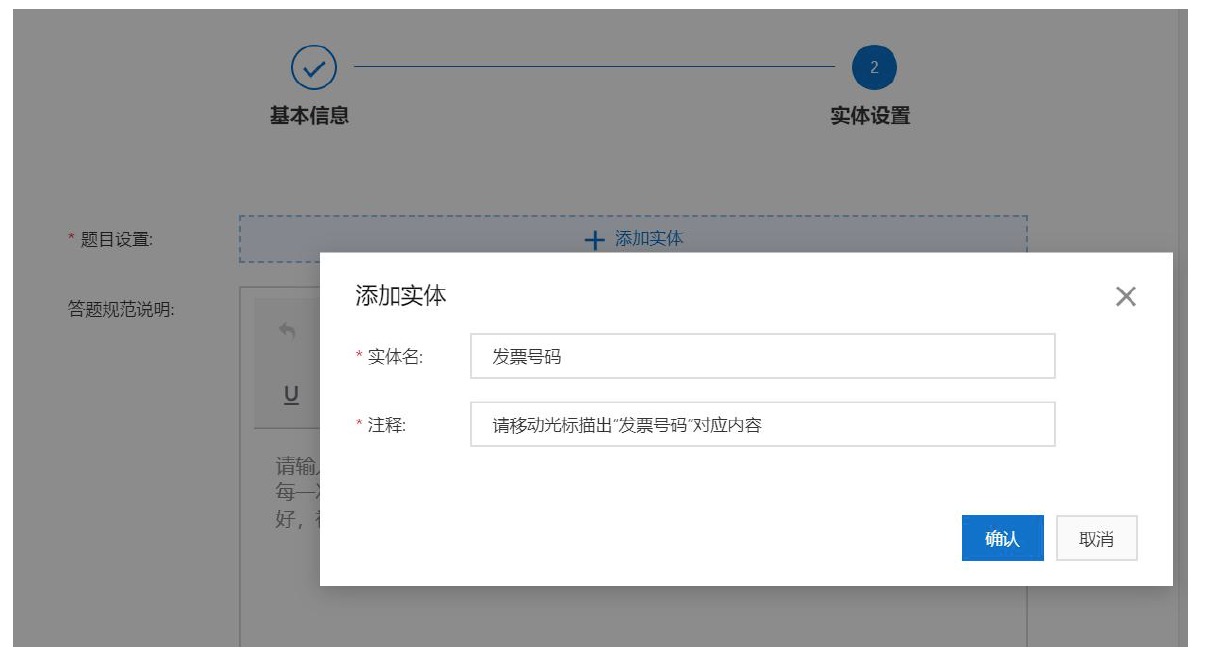
多次點擊“添加實體”按鈕,直至所有需要抽取的實體都顯示在右邊欄,點擊提交即可。待上傳的數據集解析完畢后即可標注,之后按照頁面提示進行數據的標注即可。
標注規范
需要對待標注文檔中所有出現的實體予以標注。(建議打開左上角的“同值標注” 功能)
某文檔中對某個實體已經有過標注了,在另一篇文檔中還需要對相同實體進行標注嗎?答:需要。
被標注的實體中不能出現換行符“\n”或句號“。”,否則將不能識別,但不會影響訓練。
常見問題
當構建好數據集后,模型就可以開始學習。需要知道的是模型所有的知識都來源于您輸入的這個數據集,它不具備任何的先驗知識。模型做出的所有判斷都是依據從這個訓練數據集中學到的知識,因此它不可能做出它認知外的判斷。
常見的用戶遇到的問題如:
我需要從一句話中抽出一個金額,于是我標注了500句包含這個金額的句子。但是我測試模型效果時可以使用一整篇文章嗎?文章中有一句話包含待抽取的實體。
答:不可以。測試文本和訓練文本需要保持一致,因此,測試時也要用一句話去測試。或者構造訓練數據時也選用完整的文章。
我有一整段裁判文書,需要從某一句話推理得到審判結果,可以通過標出這些話抽取推理得到答案嗎?
答:實體抽取目前支持的是內容較短的完整文本,并且不做推理。如果標注的內容是成多句或是成段的,建議您選擇其它的項目/解決方案看看能否解決您的問題。
標注太累了,我需要抽取的文本有好幾種格式,能不能只標一種,能不能先標幾條測測效果?
答:標注的數據越多且越多樣,模型的泛化性能就會越好,如果您希望模型具備好的性能,標注數據這一關是必不可少的。我們不建議標幾條數據試試效果,因為極少的樣本模型是學不到規律的,因此不會有好的效果。另外,如果您有多個類型的樣本,建議您每個類型都標一些,而不是只標一個類型。這樣也能提升模型的穩定性和準確率。