動態文件剪枝(Dynamic File Pruning, DFP)可以大幅改善許多Delta表查詢的性能。動態文件剪枝對于未分區的表或者未分區列的join來說更加有效。DFP的性能提升通常還和數據的聚集相關聯,可以考慮使用ZOrdering來最大化DFP的性能收益。
詳細內容可參考Databricks官網文章:動態文件修剪
想要了解更多的DFP的背景知識及使用案例,可以參考Databricks的官方博客:使用DFP加速SQL查詢。
在Databricks Runtime 6.1及更高版本中可用。
DFP主要由如下幾個Spark配置項控制:
spark.databricks.optimizer.dynamicFilePruning(默認值為true):表示是否使用DFP,如果為true,則啟動DFP,下沉DFP的過濾器,減少掃描的數據量。如果設置為false,則不啟用DFP。
spark.databricks.optimizer.deltaTableSizeThreshold(默認值為1000000000字節(10 GB)):表示在進行join時,觸發DFP的最小的表的大小。如果表不夠大,可能使用DFP不如直接掃描全表。你可以使用命令:
DESCRIBE DETAIL table_name,然后查看sizeInBytes列獲取到表的大小。spark.databricks.optimizer.deltaTableFilesThreshold(在Databricks 8.3之前是1000,在Databricks 8.4及之后為10):表示在進行join時,觸發DFP的最小的表文件的數量。如果表中的文件數量小于該閾值,則DFP不會被觸發。如果表中的文件數量過少,則掃描全表的開銷可能會更小一些。你可以使用命令:
DESCRIBE DETAIL table_name,然后查看numFiles列獲取到表中的文件數量。
使用案例
測試數據生成:
在本節中我們使用TPCDS數據集作為測試數據,主要使用到store_sales和item表,下載包請聯系Databricks運維,并上傳到您的OSS中,然后再DDI的項目空間中創建Spark作業生成測試數據:
--class com.databricks.spark.sql.perf.tpcds.GenTPCDSData
--deploy-mode cluster
--name generate_dataset
--queue default
--master yarn
--conf spark.yarn.submit.waitAppCompletion=true
--conf spark.driver.cores=6
--conf spark.driver.memory=12G
--conf spark.executor.cores=3
--conf spark.executor.memory=6G
--conf spark.executor.instances=20
--conf spark.yarn.executor.memoryOverhead=1024
--conf spark.default.parallelism=100
--conf spark.shuffle.service.enabled=true
--conf spark.sql.autoBroadcastJoinThreshold=-1
oss://[your_path]/jars/spark-sql-perf-assembly-0.5.1-SNAPSHOT.jar
-m yarn
--dsdgenDir /home/hadoop/tpcds-kit/tools
--scaleFactor 100
--location oss://[your_path]/
--format delta
--overwrite true
--numPartitions 1000
-y 0
-g true在上述的Spark作業中,需要對jar文件的路徑和數據產生的路徑修改為您的OSS中的路徑,其他參數可以保持不變,scaleFactor表示產生的數據量,單位為GB,在這里我們產生100GB的數據。如果出現報錯請聯系DDI的開發人員。
創建一個Notebook,在該Notebook中進行試驗,先創建數據庫,并在數據庫中基于以上生成的數據創建表,對表store_sales的ss_item_sk列做ZOrdering優化:
%sql
-- 創建數據庫
CREATE DATABASE dfp;
-- 使用剛創建的數據庫
USE dfp;
-- 基于上述生成的數據,創建數據表,創建item表:
CREATE TABLE item USING DELTA
LOCATION "oss://[your_path]/data/item";
-- 創建store_sales表:
CREATE TABLE store_sales USING DELTA
LOCATION "oss://[your_path]/data/store_sales";
-- 對store_sales表的ss_item_sk字段進行ZOrdering優化
OPTIMIZE store_sales ZORDER BY (ss_item_sk);案例1:靜態文件剪枝
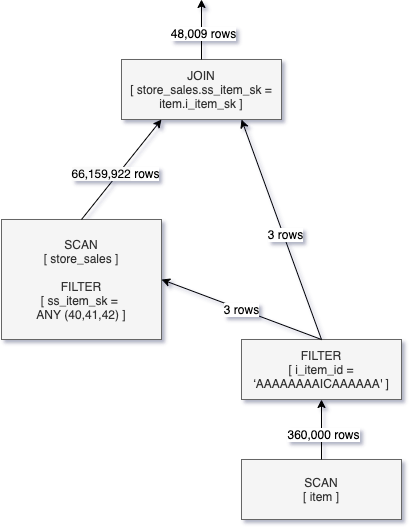
由于我們在store_sales表的ss_item_sk列上執行了ZOrdering優化,且Delta Lake保存了每一列的min-max統計信息,因此,當我們執行查詢如下查詢時:
%sql
SELECT sum(ss_quantity) FROM store_sales WHERE ss_item_sk IN (40, 41, 42);由于我們使用了ss_item_sk IN (40, 41, 42)作為where查詢條件,Delta Engine會利用表文件的統計信息對表文件剪枝,跳過不包含ss_item_sk IN (40, 41, 42)的表文件。上述查詢的邏輯執行計劃如下圖所示,過濾條件被往下推,很大程度減少了掃描的數據量。
 而對于join條件來說,比如常見的星形表連接,join的過濾條件在查詢編譯階段對事實表是未知的,因此,就需要一種和where查詢條件不一樣的方式來進行文件剪枝。
而對于join條件來說,比如常見的星形表連接,join的過濾條件在查詢編譯階段對事實表是未知的,因此,就需要一種和where查詢條件不一樣的方式來進行文件剪枝。
案例2:不使用DFP的星型表連接
在Notebook的第一個paragraph中設置spark.conf,關閉DFP(默認開啟):
%spark.conf
spark.databricks.optimizer.dynamicFilePruning false然后執行一個典型的星型查詢:
%sql
USE dfp;
SELECT sum(ss_quantity) FROM store_sales
JOIN item ON ss_item_sk = i_item_sk
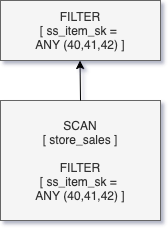
WHERE i_item_id = 'AAAAAAAAICAAAAAA';這個查詢和案例1的查詢的返回值相同,但這里的where查詢條件是針對維表的,而非事實表。這也意味著對表store_sales的過濾會作為Join操作的一部分,因為在掃描和過濾表item之后才能獲取到ss_item_sk的值。
上述查詢的邏輯執行計劃如下圖所示,從圖中可以看出,雖然僅過濾出了4萬條數據,但是卻掃描了表store_sales的80多億條記錄。如果我們能將Join的條件像案例1中的where條件一樣往下推,那么將可以大大減少需要掃描的數據量,提升查詢效率,這正是DFP的動機和實現原理。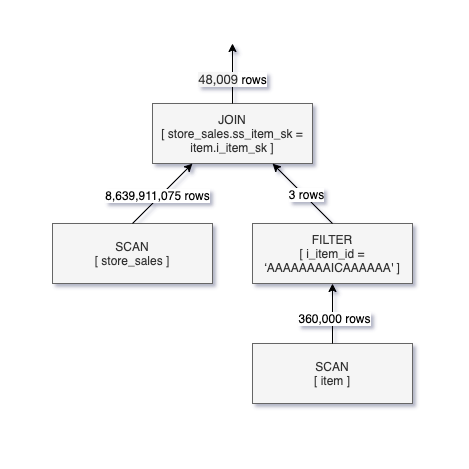
案例3:使用DFP的星型表連接
重啟Zeppelin的Interpreter,啟動DFP(刪除 %spark.conf 的paragraph),然后重新執行查詢:
%sql
USE dfp;
SELECT sum(ss_quantity) FROM store_sales
JOIN item ON ss_item_sk = i_item_sk
WHERE i_item_id = 'AAAAAAAAICAAAAAA';將會生成如下圖所示的邏輯執行計劃,由于將過濾條件下推到SCAN Operator中,掃描的數據量從80億條變為600多萬條,大幅降低了掃描的數據量。由于DFP是以文件為粒度進行剪枝的,因此相對于最終的結果來說,還是掃描了很多無關數據,但和未使用DFP相比,已經有很大的性能提升。