本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
本文針對Notebook的使用,做一個具體的場景示例——航空公司數據導入及分析。
前提條件
通過主賬號登錄阿里云 Databricks控制臺。
已創建集群,具體請參見創建集群。
已使用OSS管理控制臺創建非系統目錄存儲空間,詳情請參見創建存儲空間。
警告首次使用DDI產品創建的Bucket為系統目錄Bucket,不建議存放數據,您需要再創建一個Bucket來讀寫數據。
說明DDI支持免密訪問OSS路徑,結構為:oss://BucketName/Object
BucketName為您的存儲空間名稱;
Object為上傳到OSS上的文件的訪問路徑。
例:讀取在存儲空間名稱為databricks-demo-hangzhou文件路徑為demo/The_Sorrows_of_Young_Werther.txt的文件
// 從oss地址讀取文本文檔 val text = sc.textFile("oss://databricks-demo-hangzhou/demo/The_Sorrows_of_Young_Werther.txt")
步驟一:創建集群并通過knox賬號訪問Notebook
創建集群參考:創建集群,需注意要設置RAM子賬號及保存好knox密碼,登錄WebUI時候需要用到。
步驟二:創建Notebook、導入數據、進行數據分析
1. 讀取OSS數據、打印schema,創建TempView
Load OSS data
%spark
val sparkDF = spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("oss:/
/databricks-demo-hangzhou
/airline_statistic_usa.csv")Print schema
%spark
sparkDF.printSchema()
sparkDF.show()Create Temp View
%spark
sparkDF.createOrReplaceTempView("usa_flights")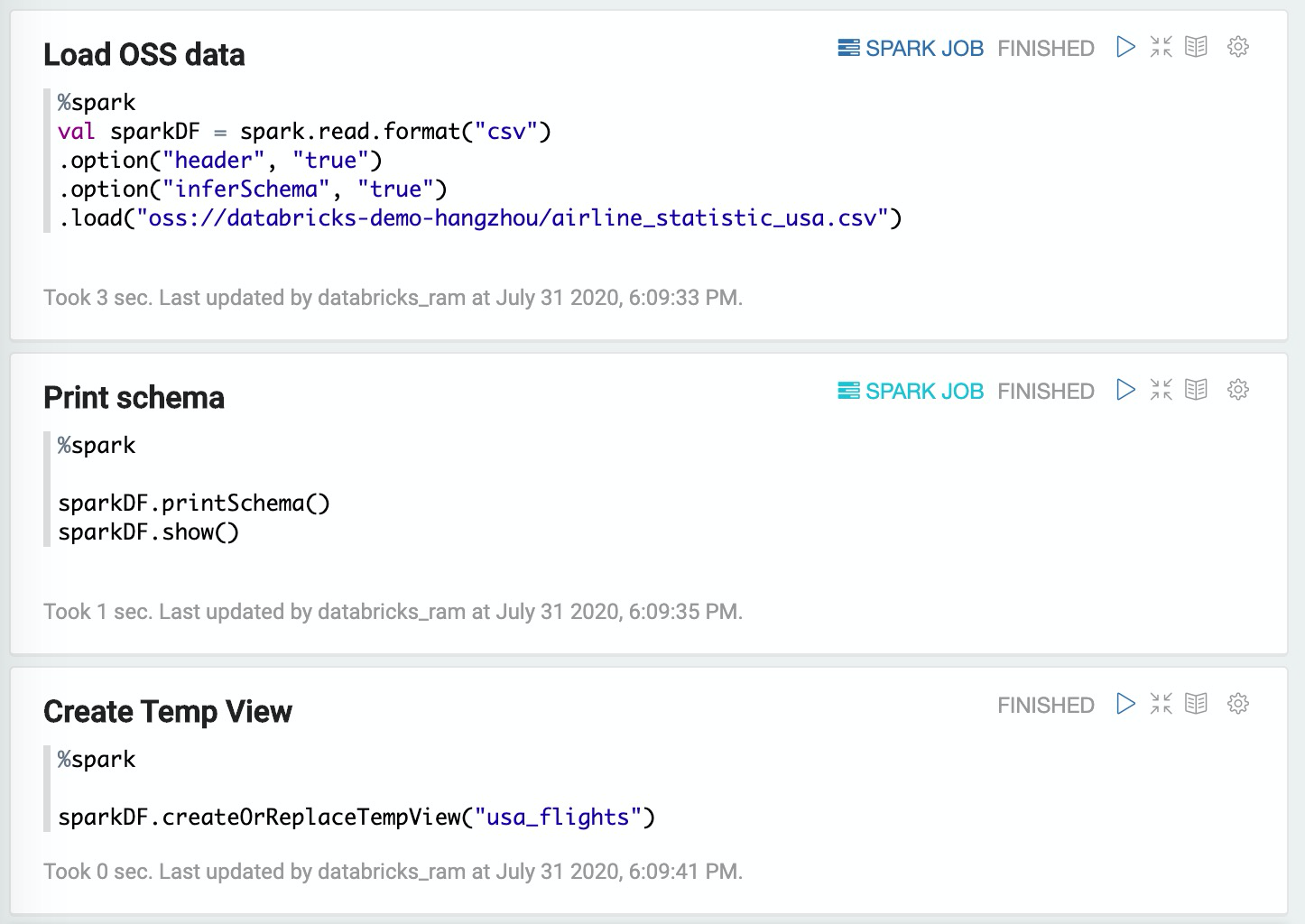
2. 查詢分析:Analysis,Top 10 Average Distance Traveled By Flight Carrier
%sql
SELECT OP_UNIQUE_CARRIER, CAST(AVG(DISTANCE) AS INT) AS AvgDistance
FROM usa_flights
GROUP BY OP_UNIQUE_CARRIER
ORDER BY AvgDistance
DESC
LIMIT 20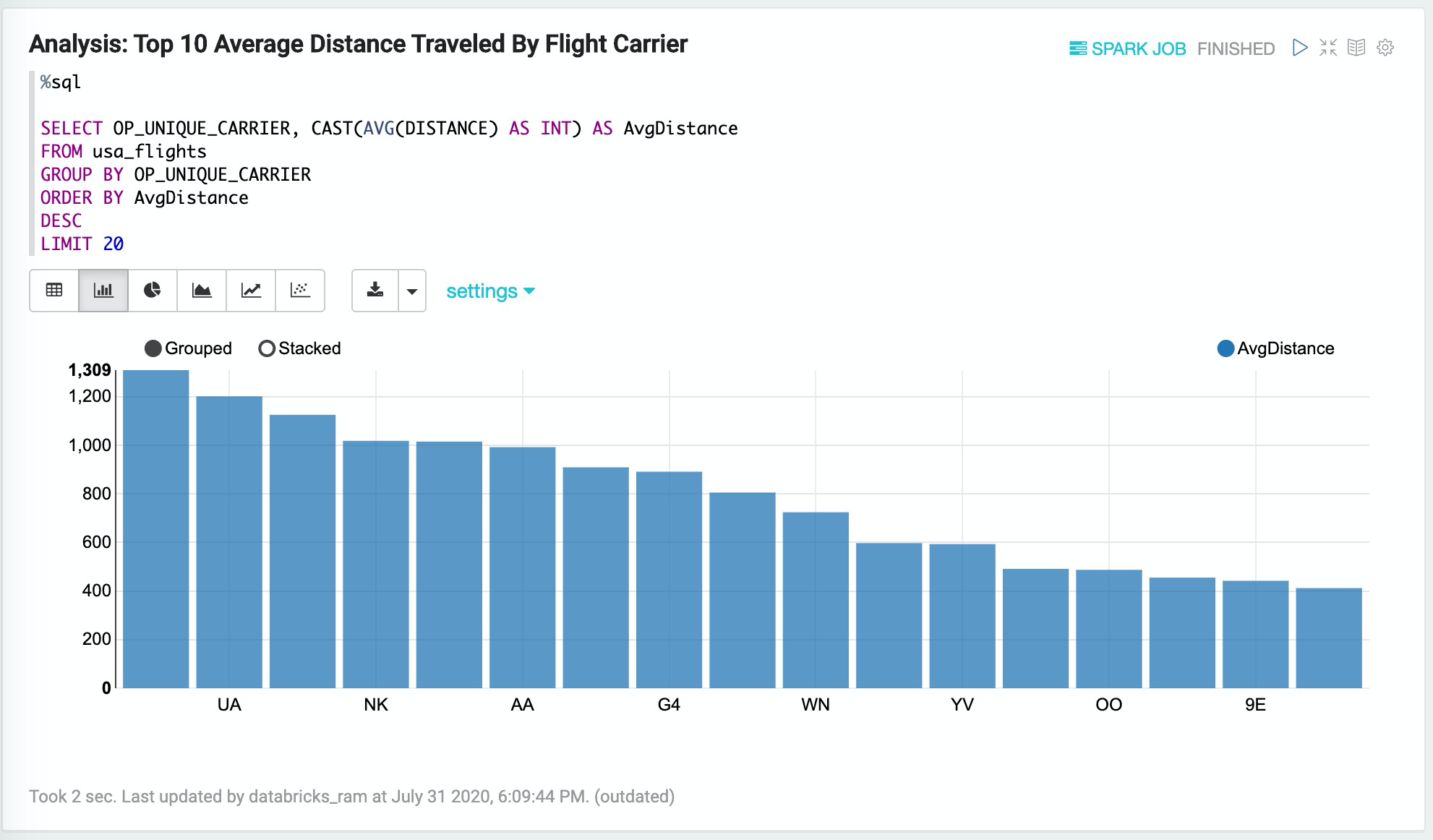
3. 定義UDF:Define UDF
%pyspark
from pyspark.sql.types import IntegerType
def isDelayed(x):
if x == None:
return 0
elif int(x) > 10:
return 1
else:
return 0
spark.udf.register("isDelayed", isDelayed, IntegerType())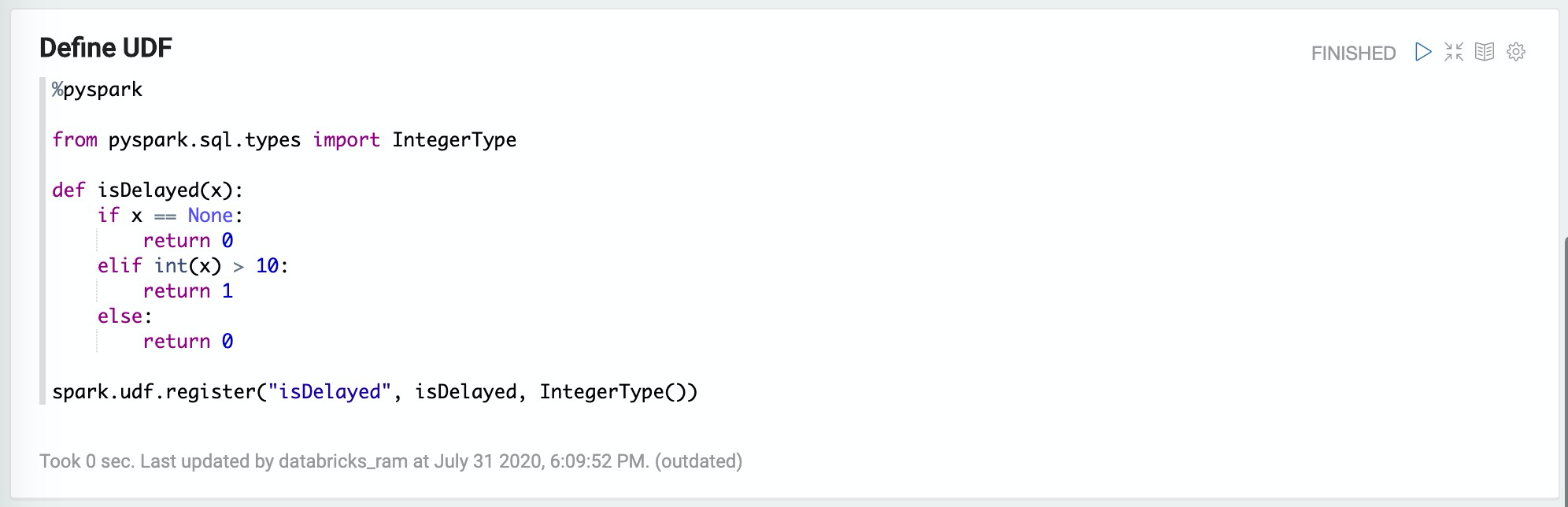
4. 使用UDF進行查詢:Analysis,Top 10 Total Delayed Flights By Carrier
%sql
SELECT OP_UNIQUE_CARRIER, SUM(isDelayed(DEP_DELAY)) AS NumOfDelayed
FROM usa_flights
GROUP BY OP_UNIQUE_CARRIER
ORDER BY NumOfDelayed
DESC
LIMIT 10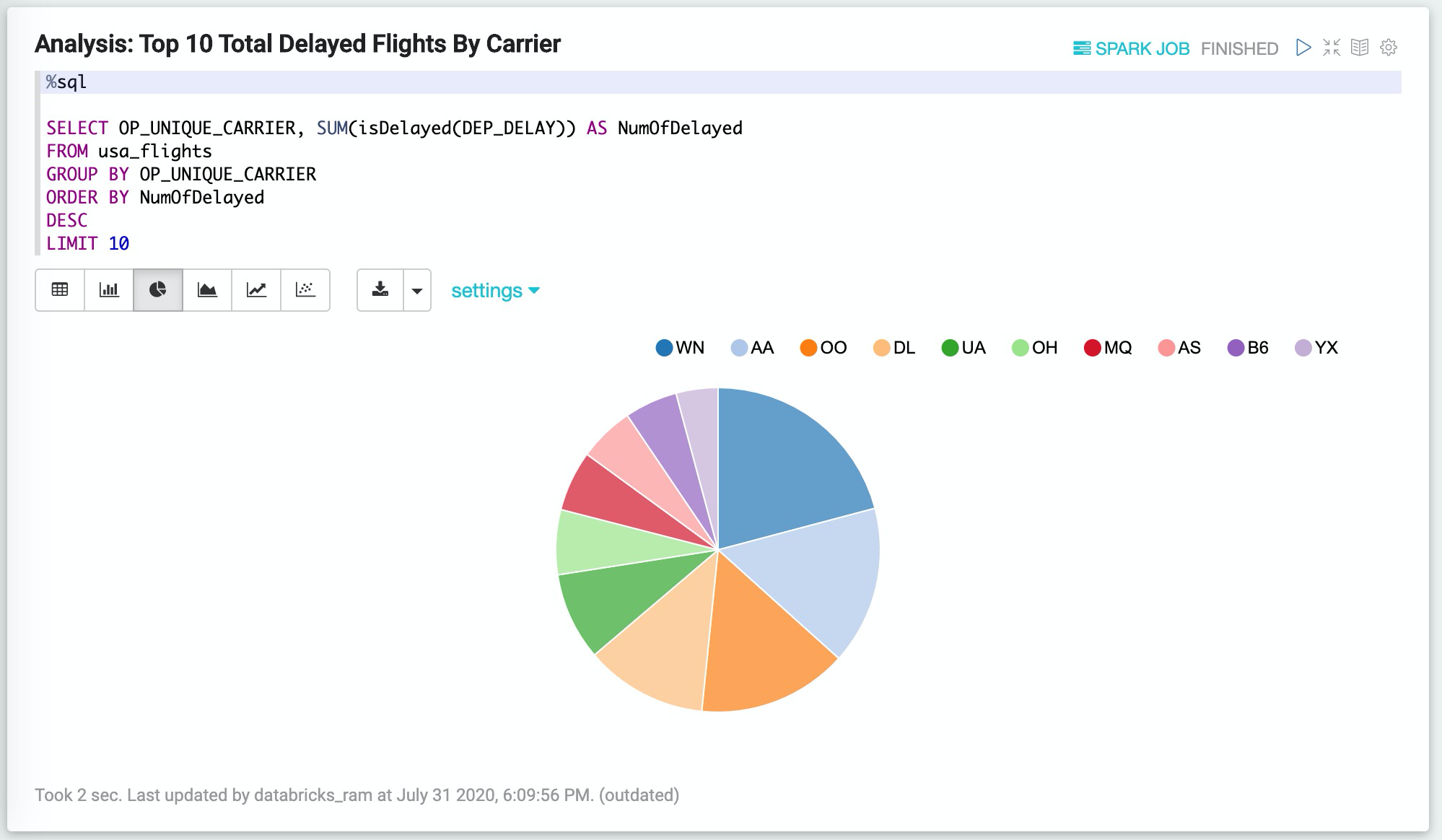
文檔內容是否對您有幫助?