本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
本文針對Databricks數據洞察Notebook基本使用的一個示例。
前提條件
通過主賬號登錄阿里云 Databricks控制臺。
已創建集群,具體請參見創建集群。
已使用OSS管理控制臺創建非系統目錄存儲空間,詳情請參見創建存儲空間。
警告首次使用DDI產品創建的Bucket為系統目錄Bucket,不建議存放數據,您需要再創建一個Bucket來讀寫數據。
說明DDI支持免密訪問OSS路徑,結構為:oss://BucketName/Object
BucketName為您的存儲空間名稱;
Object為上傳到OSS上的文件的訪問路徑。
例:讀取在存儲空間名稱為databricks-demo-hangzhou文件路徑為demo/The_Sorrows_of_Young_Werther.txt的文件
// 從oss地址讀取文本文檔 val text = sc.textFile("oss://databricks-demo-hangzhou/demo/The_Sorrows_of_Young_Werther.txt")
步驟一:創建集群并通過knox賬號訪問Notebook
創建集群參考:http://bestwisewords.com/document_detail/167621.html,需注意要設置RAM子賬號及保存好knox密碼,登錄WebUI時候需要用到。
步驟二:創建Notebook并做可視化調試
示例Note下載:CASE1-DataInsight-Notebook-Demo.zpln
示例文本下載:The_Sorrows_of_Young_Werther.txt
示例python lib下載:matplotlib-3.2.1-cp37-cp37m-manylinux1_x86_64.whl
1. 創建DataFrame并使用z.show展示
%spark
val df1 = spark.createDataFrame(
Seq(
(1, "andy", 20, "USA"),
(2, "jeff", 23, "China"),
(3, "james", 18, "USA"),
(4, "zongze", 28, "France")
)
).toDF("id", "name", "age", "country")
val df2 = df1.groupBy("country").count()
df2.show()
z.show(df2)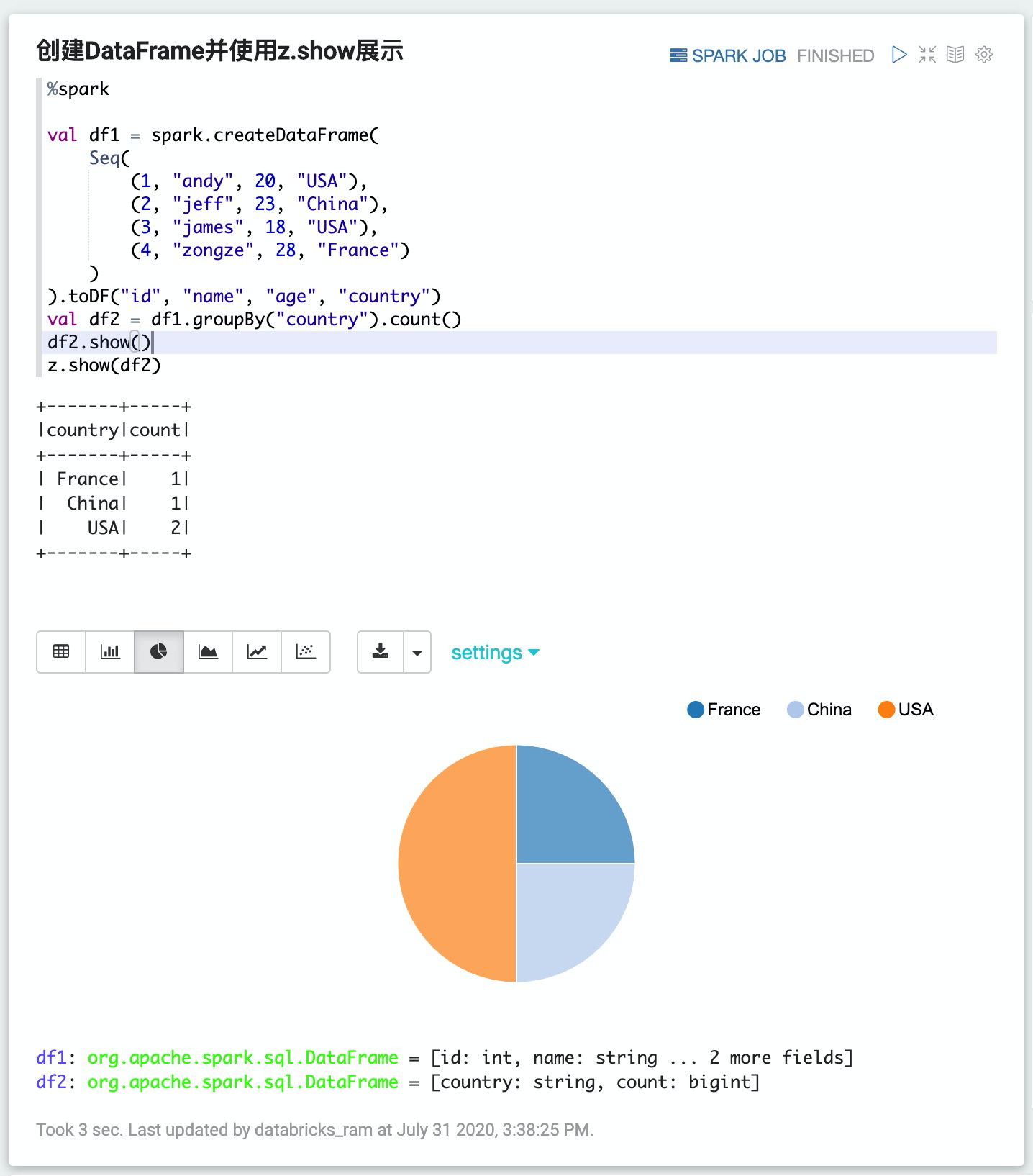
2. 創建DataFrame并通過%spark.sql做可視化查詢
%spark
val df1 = spark.createDataFrame(Seq((1, "andy", 20, "USA"), (2, "jeff", 23, "China"), (3, "james", 18, "USA"), (4, "zongze", 28, "France"))).toDF("id", "name", "age", "country")
// register this DataFrame first before querying it via %spark.sql
df1.createOrReplaceTempView("people")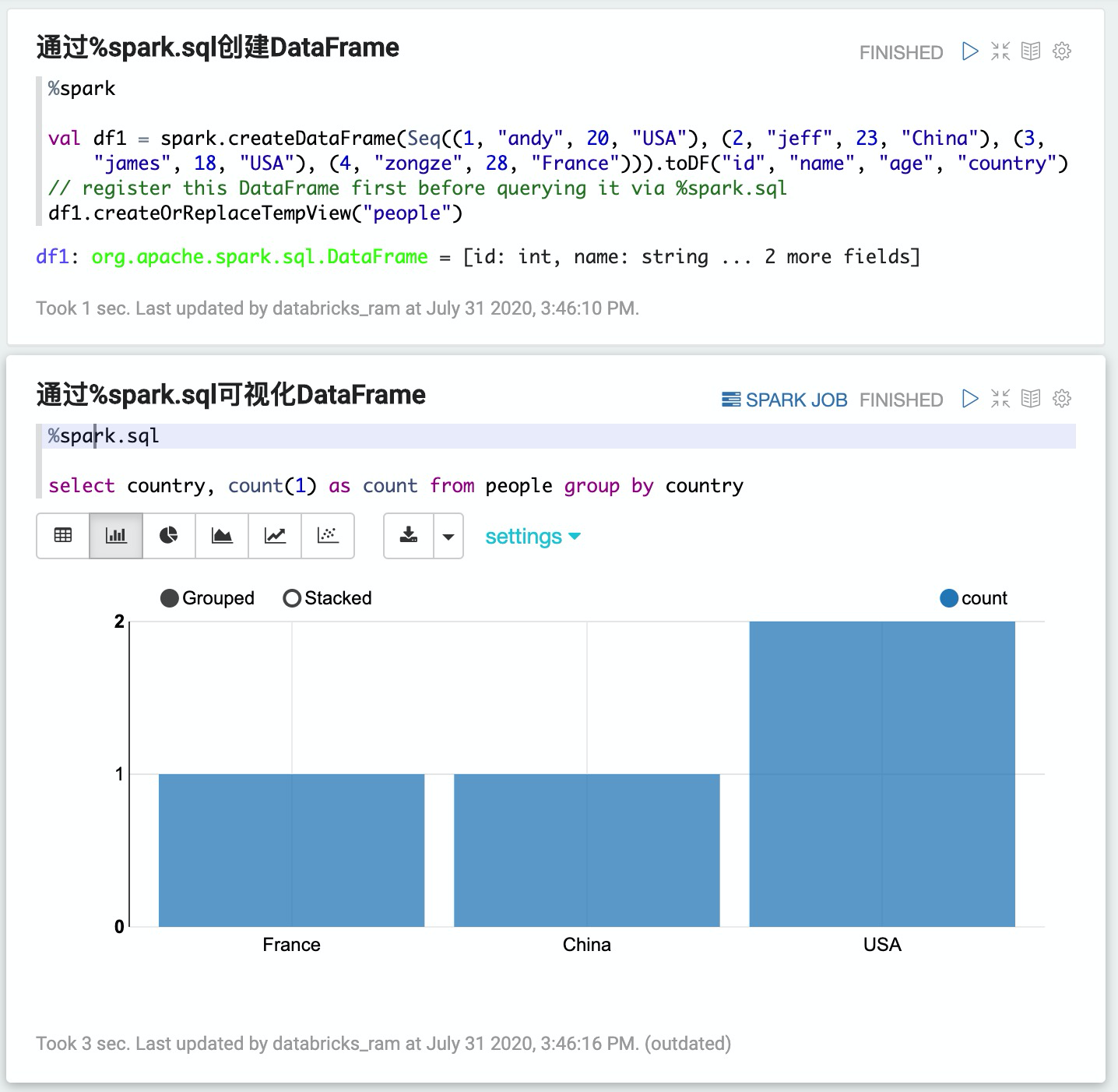
3. 測試OSS聯通性,基本的WordCount示例
// 從oss地址讀取文本文檔(注意oss文件在賬號下上傳到對應目錄)
val text = sc.textFile("oss://databricks-demo-hangzhou/The_Sorrows_of_Young_Werther.txt")
// 使用Scala做WordCount處理
val counts = text.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_)
// 將計算結果寫入并存檔到oss
counts.saveAsTextFile("oss://databricks-demo-hangzhou/WordCount示例-Result-Zeppelin-001.txt")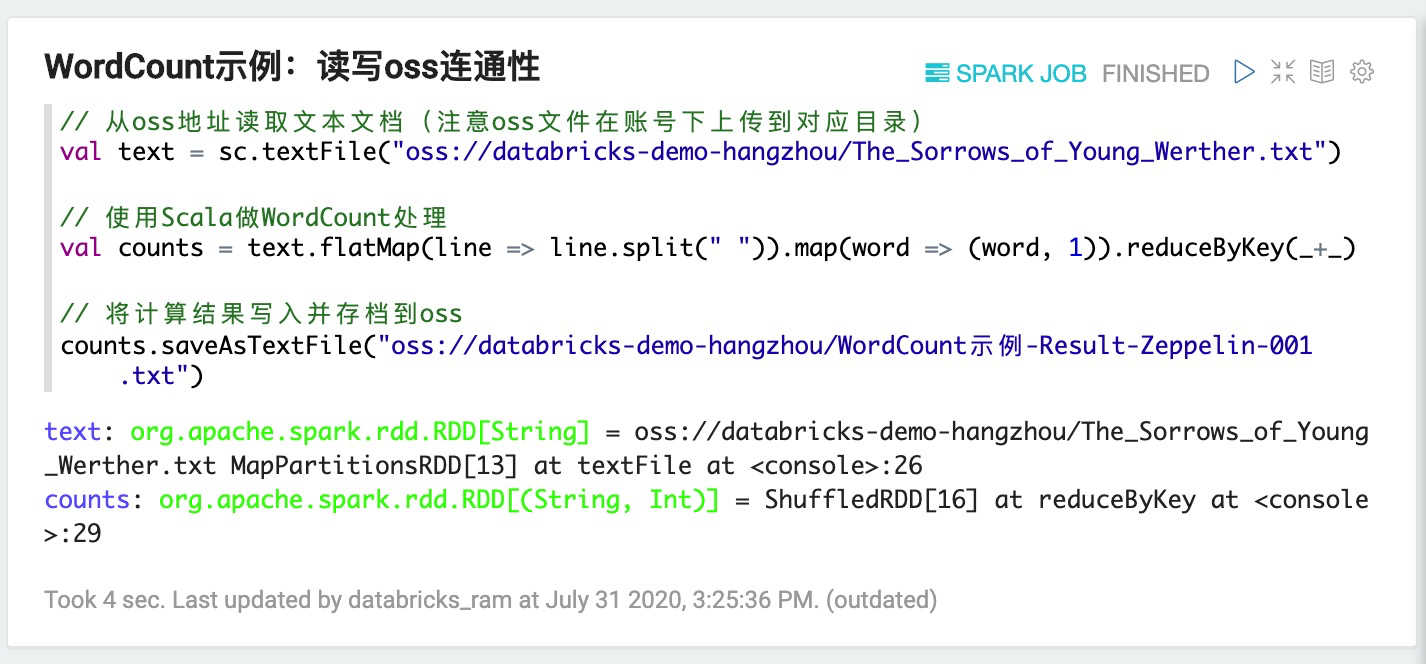
4. 庫的功能示例
%pyspark
import matplotlib.pyplot as plt
# 1. 當使用pyspark進行開發時候,依賴的庫可以通過ddi庫能力導入,具體見:http://bestwisewords.com/document_detail/168087.html
# 2. 這里示例導入matplotlib庫,并做展示——先download下官方庫安裝包,在庫功能下進行.whl文件的上傳,在需要使用庫的集群里進行安裝
plt.clf()
#define some data
x = [1,2,3,4]
y = [20, 21, 20.5, 20.8]
#plot data
plt.plot(x, y, marker="o", color="red")
z.show(plt)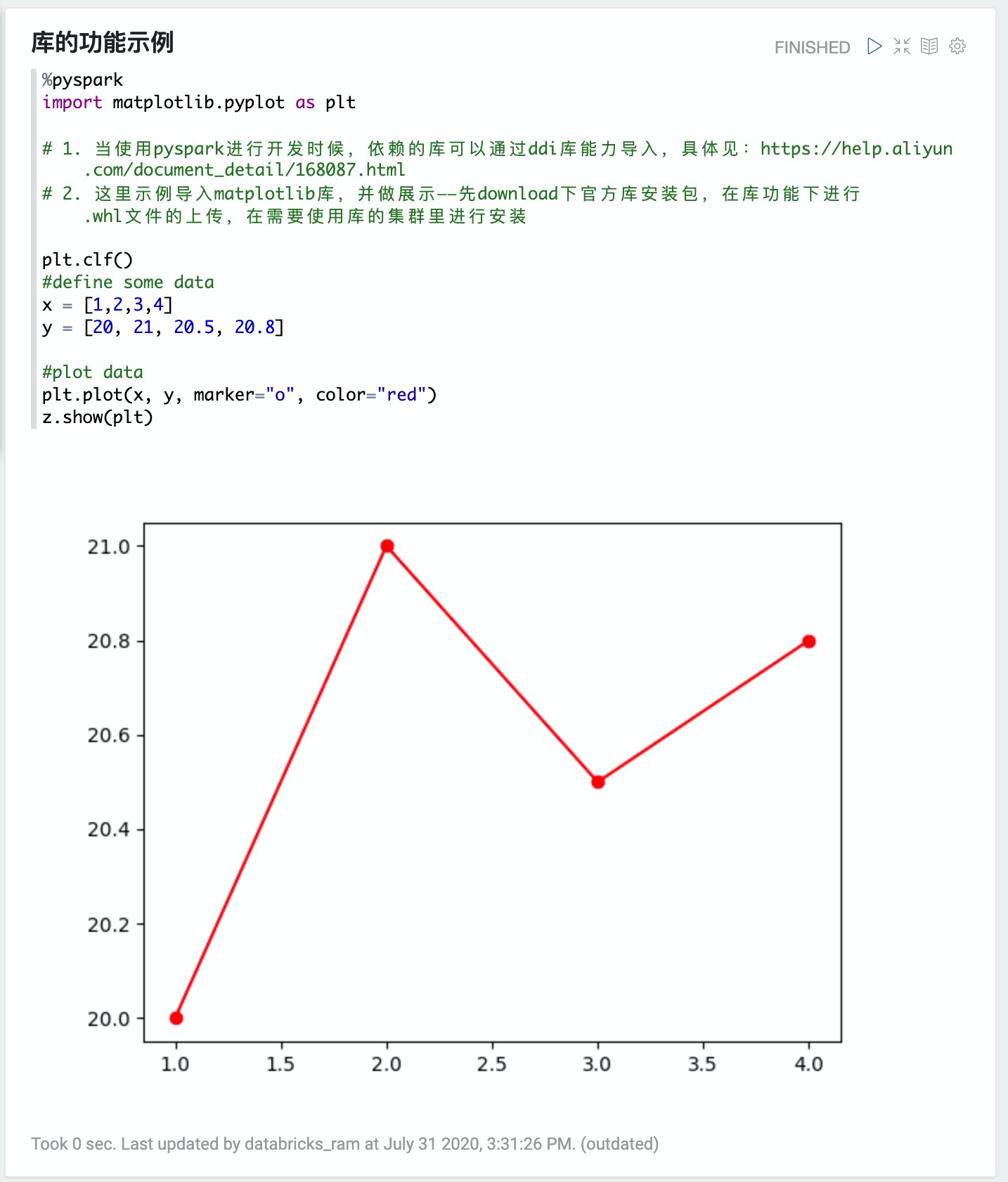
文檔內容是否對您有幫助?