本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
該Notebook展示了如何將JSON數據轉換為Delta Lake格式,創建Delta表,在Delta表中Append數據,最后使用Delta Lake元數據命令來顯示表的歷史記錄、格式和詳細信息。
前提條件
通過主賬號登錄阿里云 Databricks控制臺。
已創建集群,具體請參見創建集群。
已使用OSS管理控制臺創建非系統目錄存儲空間,詳情請參見創建存儲空間。
警告首次使用DDI產品創建的Bucket為系統目錄Bucket,不建議存放數據,您需要再創建一個Bucket來讀寫數據。
說明DDI支持免密訪問OSS路徑,結構為:oss://BucketName/Object
BucketName為您的存儲空間名稱;
Object為上傳到OSS上的文件的訪問路徑。
例:讀取在存儲空間名稱為databricks-demo-hangzhou文件路徑為demo/The_Sorrows_of_Young_Werther.txt的文件
// 從oss地址讀取文本文檔 val text = sc.textFile("oss://databricks-demo-hangzhou/demo/The_Sorrows_of_Young_Werther.txt")
詳情可參考Databricks官網Blog文章
步驟一:創建集群并通過knox賬號訪問Notebook
創建集群參考:創建集群,需注意要設置RAM子賬號及保存好knox密碼,登錄WebUI時候需要用到。
步驟二:創建Notebook、導入數據、進行數據分析
定義Notebook中使用的路徑path
%pyspark # 注意需要將數據文件events.json上傳至您的OSS對應bucket下,events.json數據來源Databricks站點的open/close數據 inputPath = "oss://databricks-huhehaote/delta-demo/events.json" deltaPath = "/delta/events" database = "Delta_QuickStart_Database"導入數據到Dataframe中 & 打印數據data
%pyspark from pyspark.sql.functions import expr from pyspark.sql.functions import from_unixtime # spark.read讀取json數據,并將表頭time轉換為date格式 events = spark.read \ .option("inferSchema", "true") \ .json(inputPath) \ .withColumn("date", expr("time")) \ .drop("time") \ .withColumn("date", from_unixtime("date", 'yyyy-MM-dd')) events.show()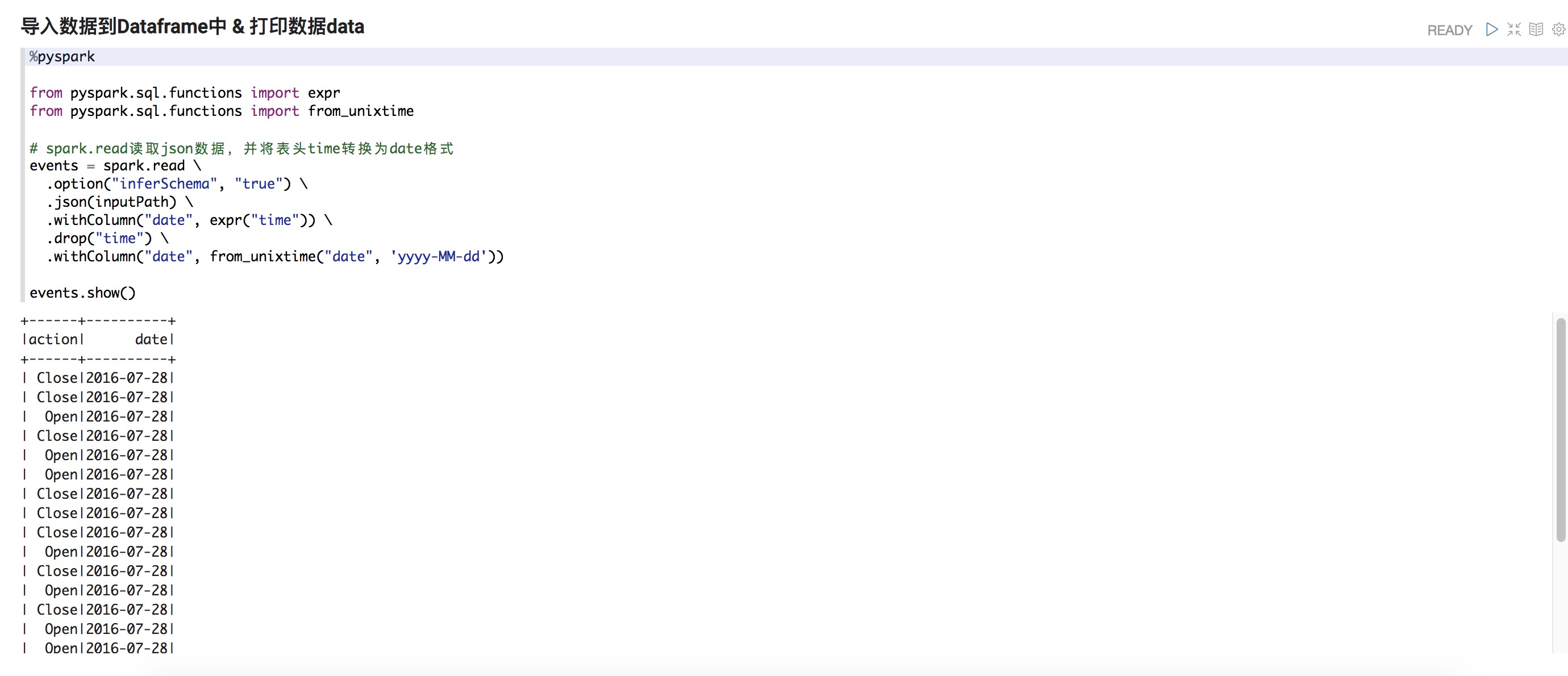
將數據使用Delta格式寫入
%pyspark events.write.format("delta").mode("overwrite").partitionBy("date").save(deltaPath)再次讀取數據查看是否成功保存
%pyspark events_delta = spark.read.format("delta").load(deltaPath) events_delta.printSchema()重置數據庫
%pyspark spark.sql("DROP DATABASE IF EXISTS {} CASCADE".format(database)) # 注意{}是在pyspark里spark.sql()中使用的變量,參數在.format中指定 (參考:https://stackoverflow.com/questions/44582450/how-to-pass-variables-in-spark-sql-using-python) spark.sql("CREATE DATABASE IF NOT EXISTS {}".format(database))使用Delta創建表
%pyspark spark.sql("USE {}".format(database)) spark.sql("CREATE TABLE events USING DELTA LOCATION \"{}\"".format(deltaPath))查看表中的數據
%sql select * from events limit 10;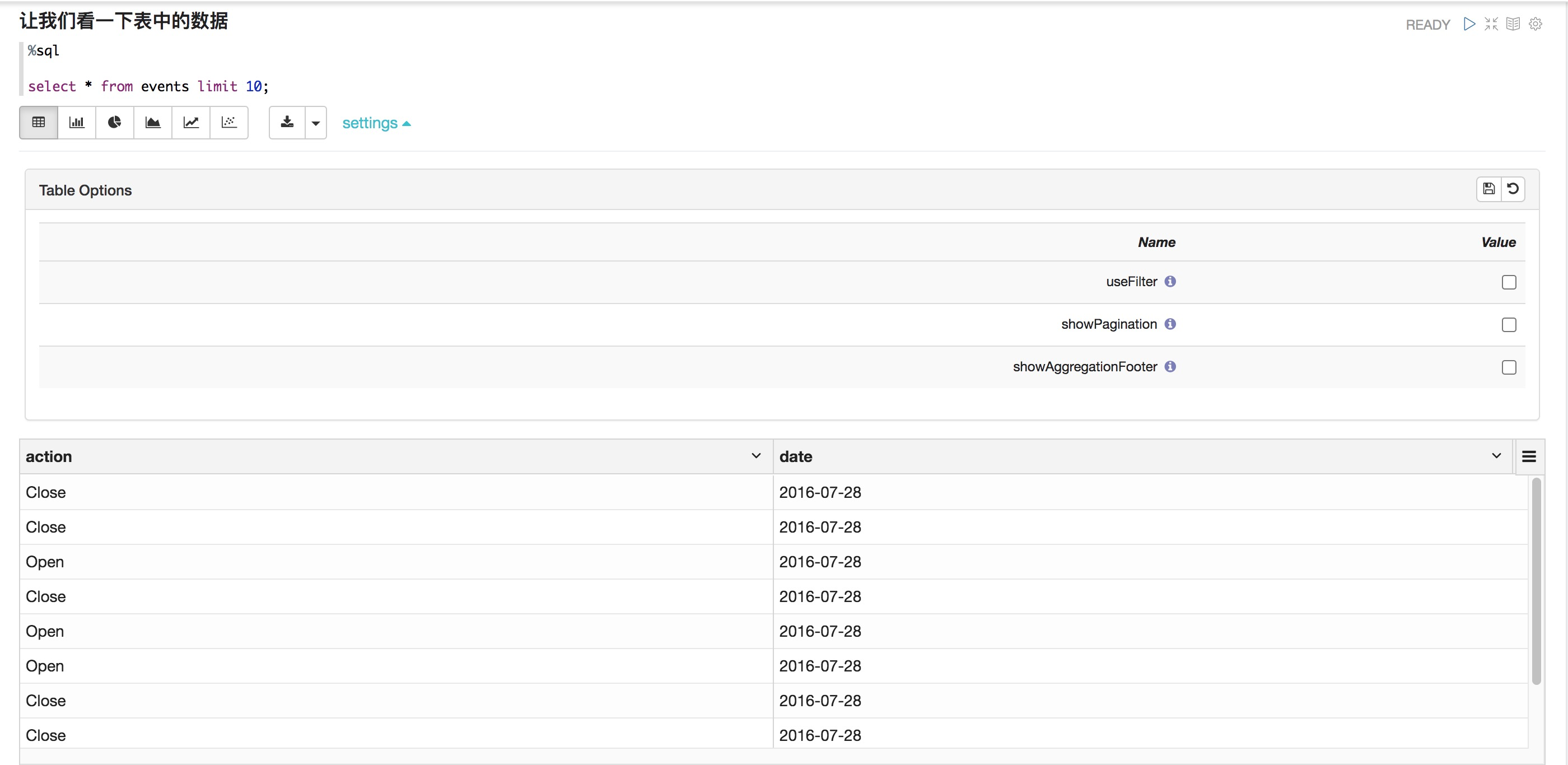
對數據執行一個簡單的count
%pyspark events_delta.count()查看events詳情
%sql DESCRIBE DETAIL events;查看表歷史,這個功能只有Delta表中可用
%sql DESCRIBE HISTORY events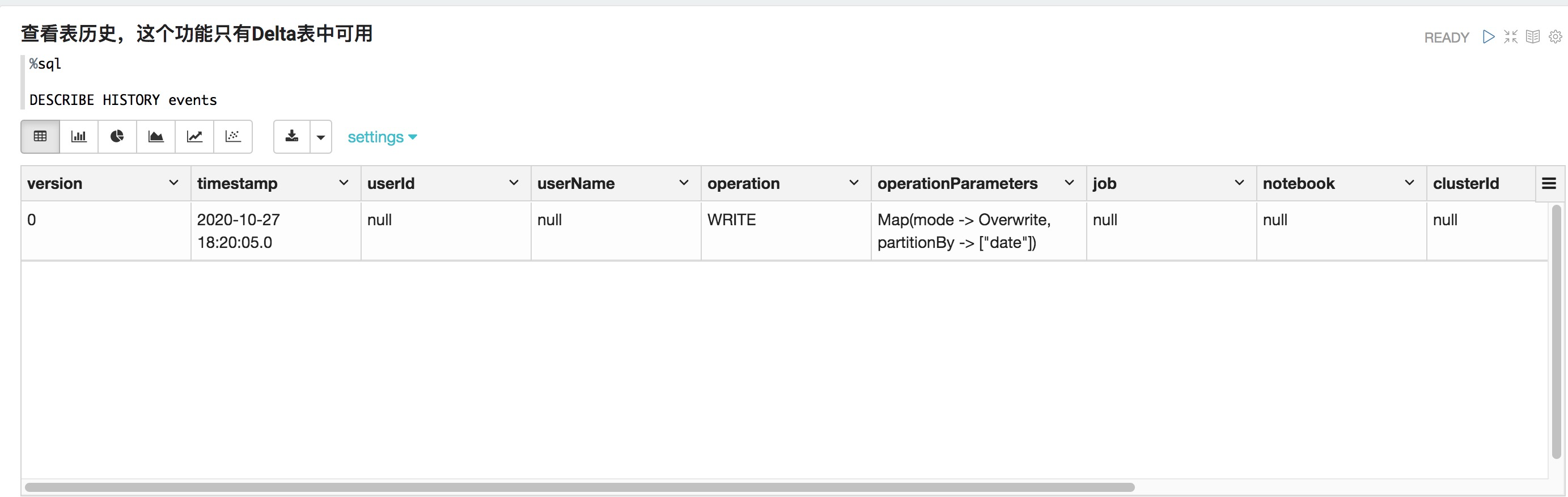
做一個聚合(aggregation)操作并將結果保存在一個臨時表中
%pyspark from pyspark.sql.functions import count events_delta.groupBy("action","date").agg(count("action").alias("action_count")).orderBy("date", "action").createOrReplaceTempView("tempDisplay")可視化該臨時表
%sql select * from tempDisplay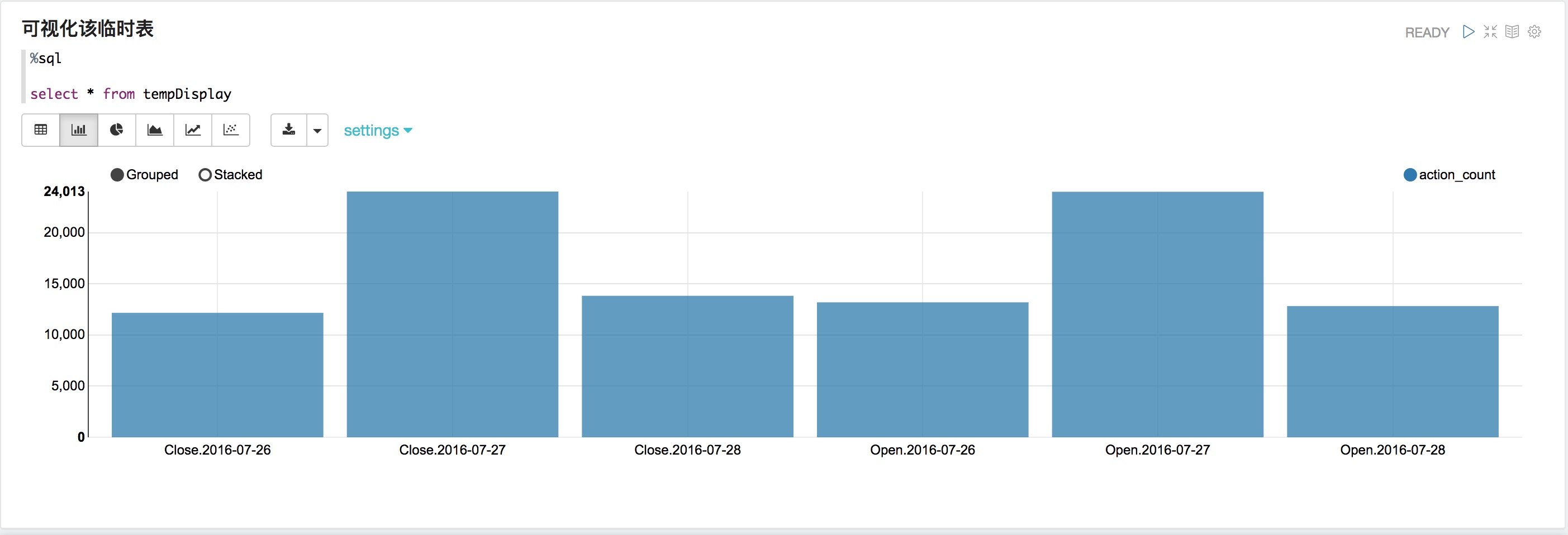
我們可以很方便的使用append模式追加新數據
%pyspark # 該操作主要將數據中時間前移2天(172800秒) historical_events = spark.read \ .option("inferSchema", "true") \ .json(inputPath) \ .withColumn("date", expr("time-172800")) \ .drop("time") \ .withColumn("date", from_unixtime("date", 'yyyy-MM-dd')) historical_events.write.format("delta").mode("append").partitionBy("date").save(deltaPath) historical_events.show()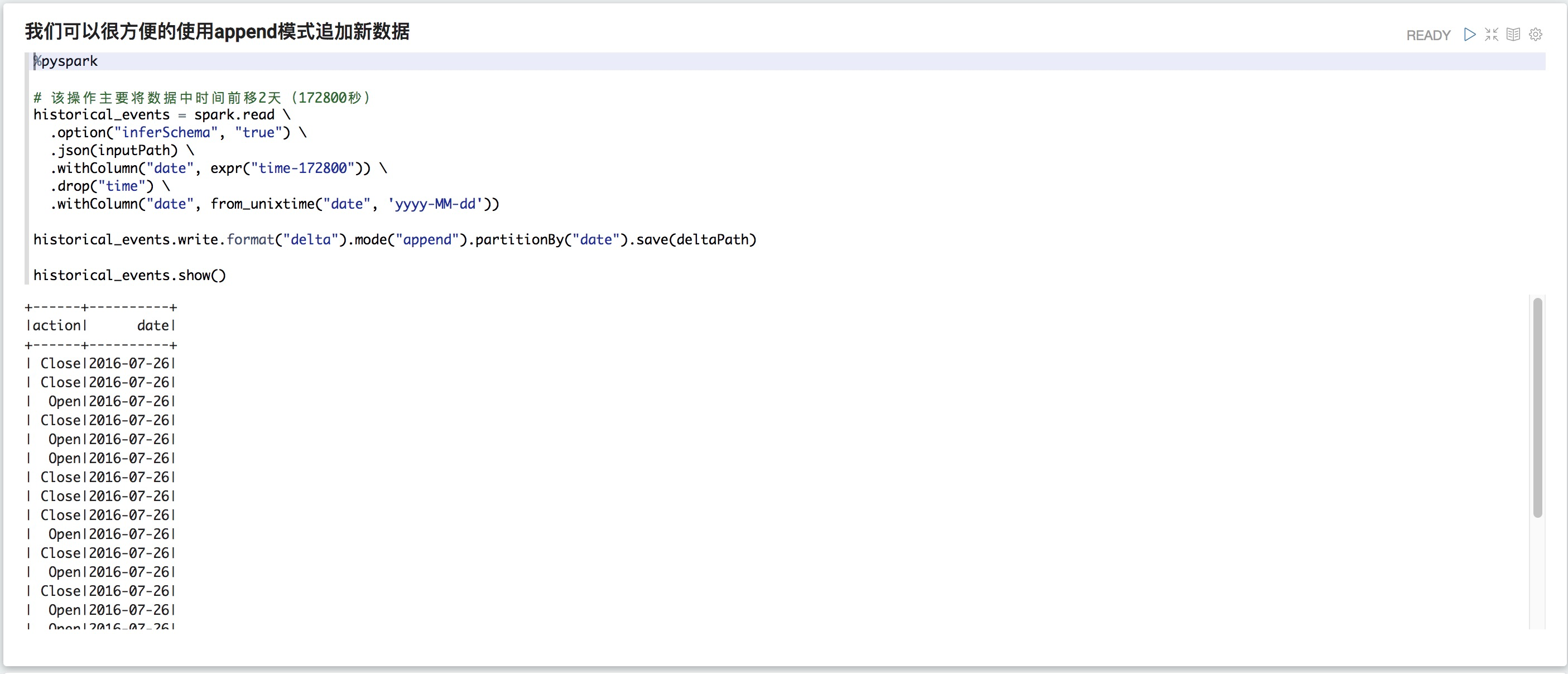
聚合(aggregate)并查看新數據
%pyspark events_delta.groupBy("action","date").agg(count("action").alias("action_count")).orderBy("date", "action").createOrReplaceTempView("tempDisplay2")可視化新表
%sql select * from tempDisplay2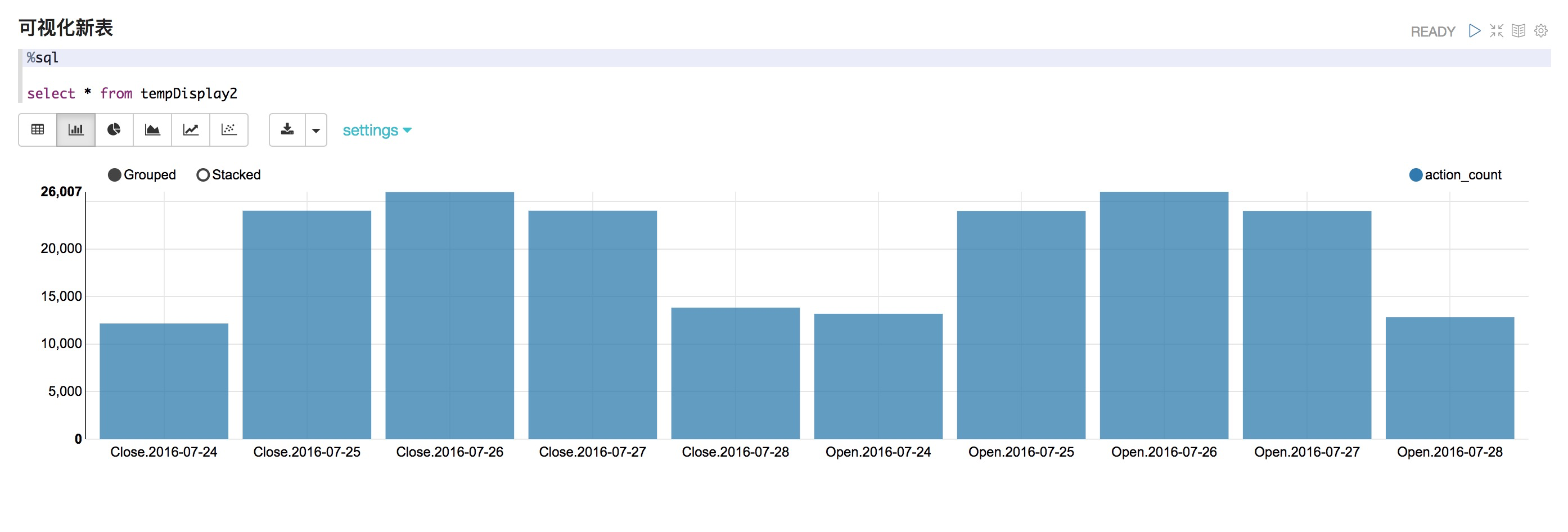
執行count操作查看新append數據行
%pyspark events_delta.count()Describe表來展示表詳情,并能夠看到表中有6個文件
%sql DESCRIBE DETAIL events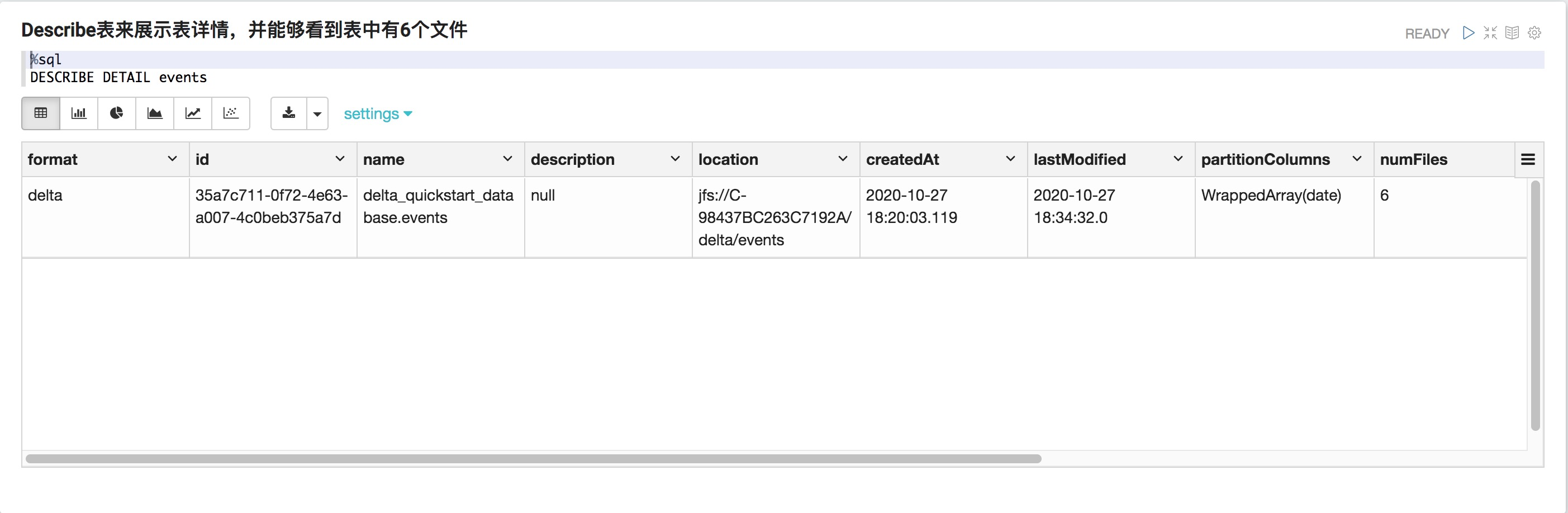
Databricks支持優化(OPTIMIZE)合并文件以提升性能
%pyspark spark.sql("OPTIMIZE events")可以看到優化(OPTIMIZE)命令也在事務日志中增加了日志(z-order)
%sql DESCRIBE HISTORY events
優化后,文件被自動合并做性能優化,表中只有5個文件
%sql DESCRIBE DETAIL events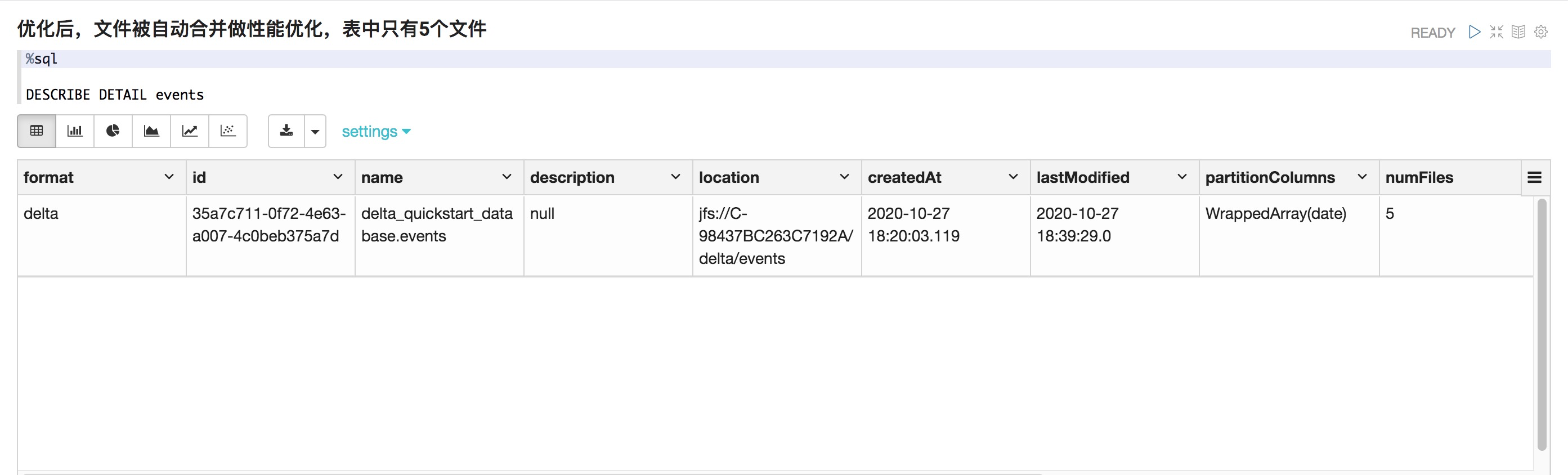
Describe formatted 命令也在DDI中支持
%sql DESCRIBE FORMATTED events
附錄
清理數據庫
%sql
/*
DROP DATABASE IF EXISTS Delta_QuickStart_Database1 CASCADE;
*/