本文介紹如何使用阿里云 Databricks數據洞察 Notebook 進行 PySpark 開發(fā)。
重要
若要使用其他數據源進行數據開發(fā),需開通相應服務。本示例采用OSS數據源。
步驟一:創(chuàng)建 Databricks數據洞察集群
創(chuàng)建Databricks 數據洞察集群,詳情參見創(chuàng)建集群。
步驟二:添加依賴庫并安裝
根據開發(fā)需要,添加相應的依賴庫
添加matplotlib庫,本示例使用PyPI方式添加,詳情參見Python庫管理。
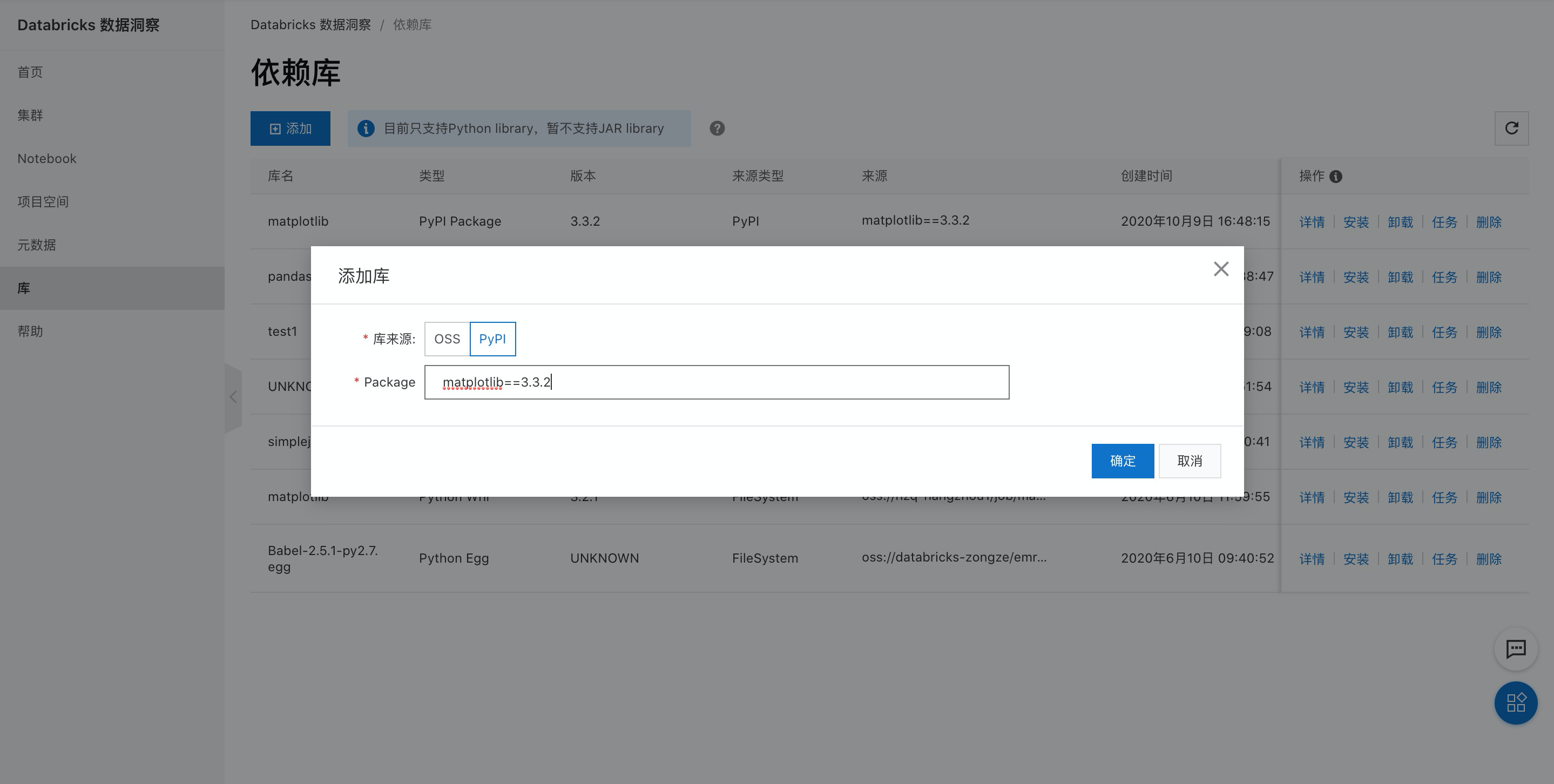
單擊安裝按鈕,安裝依賴到開發(fā)集群。
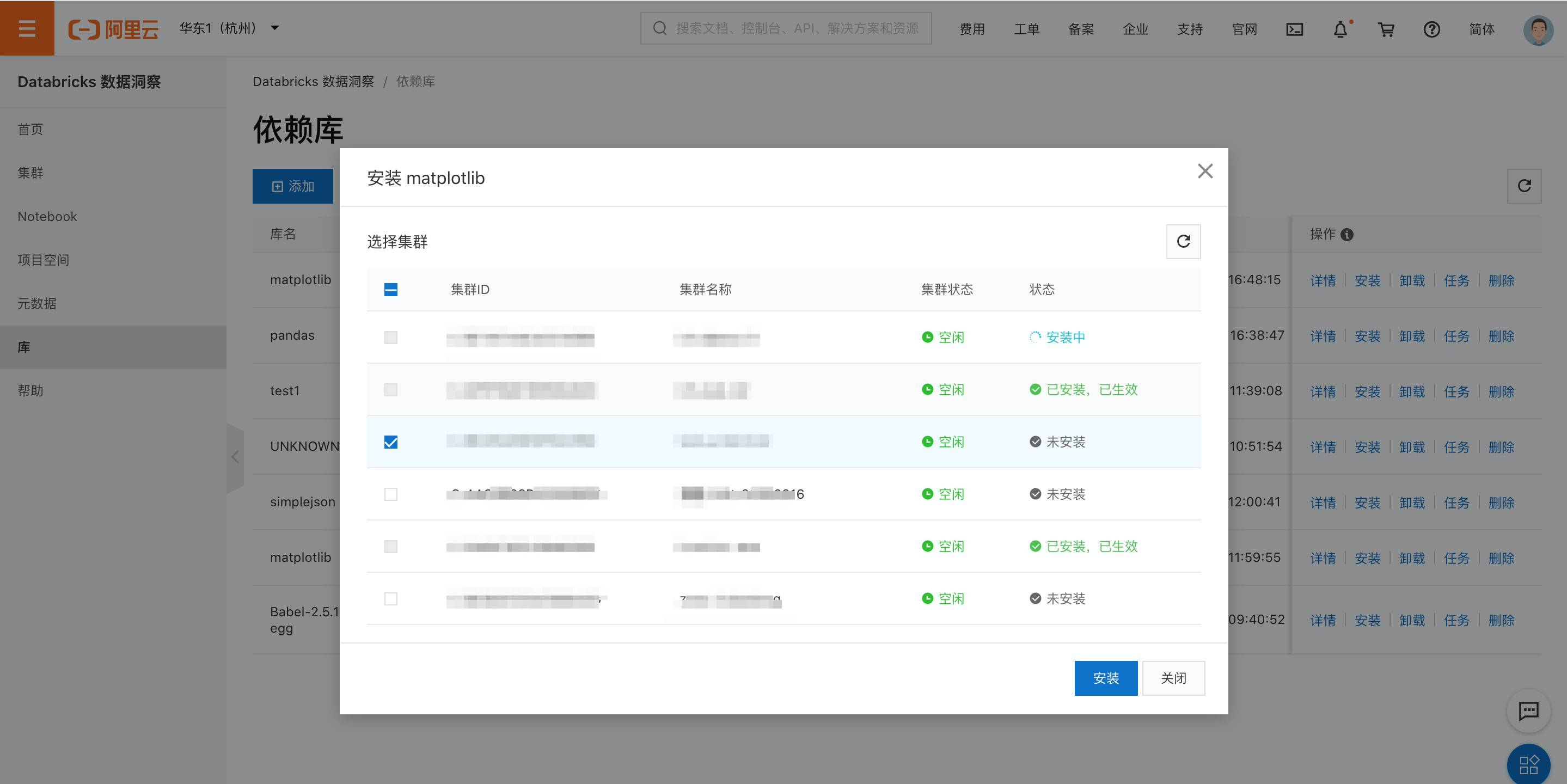
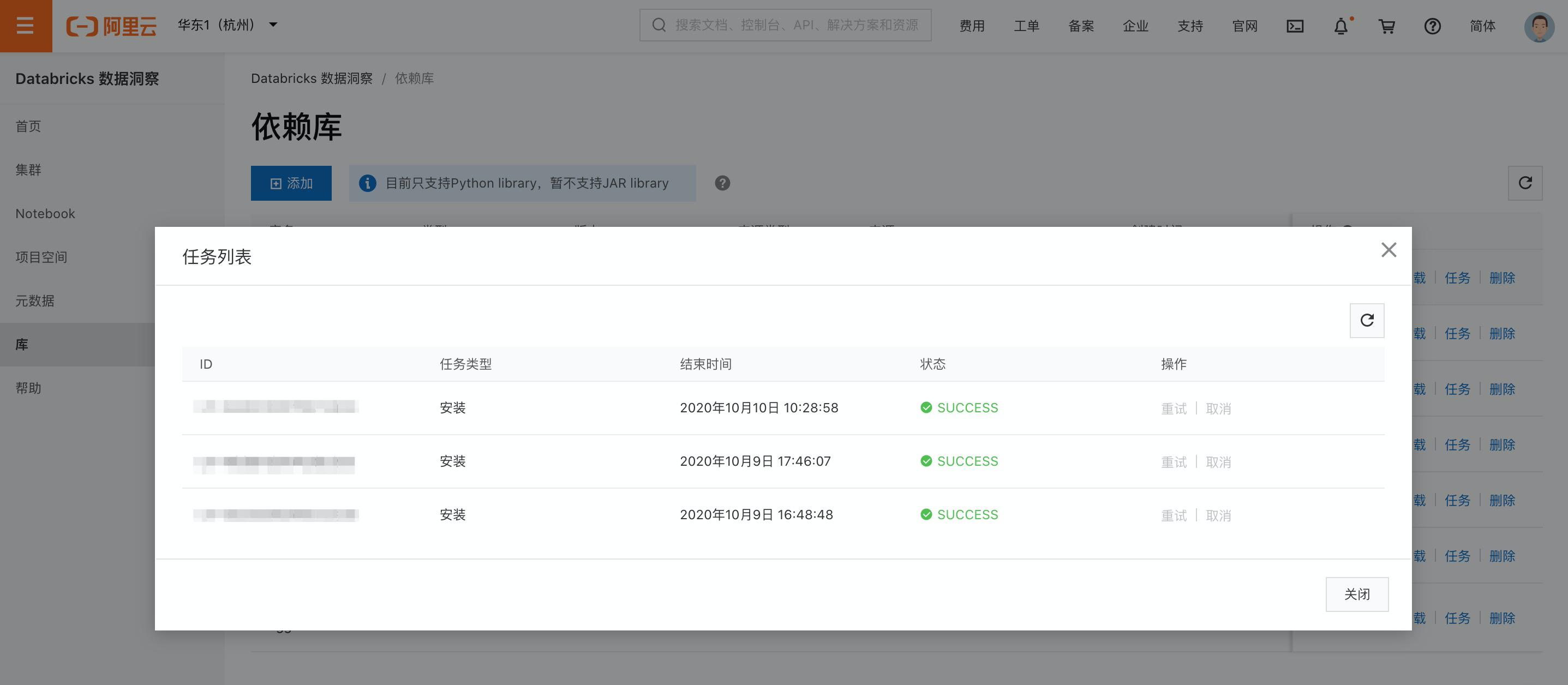
等待安裝完成,可單擊任務按鈕查看。
步驟三:獲取數據并上傳對象存儲 OSS
登錄OSS管理控制臺。
創(chuàng)建Bucket存儲空間,詳情請參見控制臺創(chuàng)建存儲空間。
上傳文件,詳情請參見控制臺上傳文件。
步驟四:數據開發(fā)
Notebook使用,詳情參見使用Notebook。
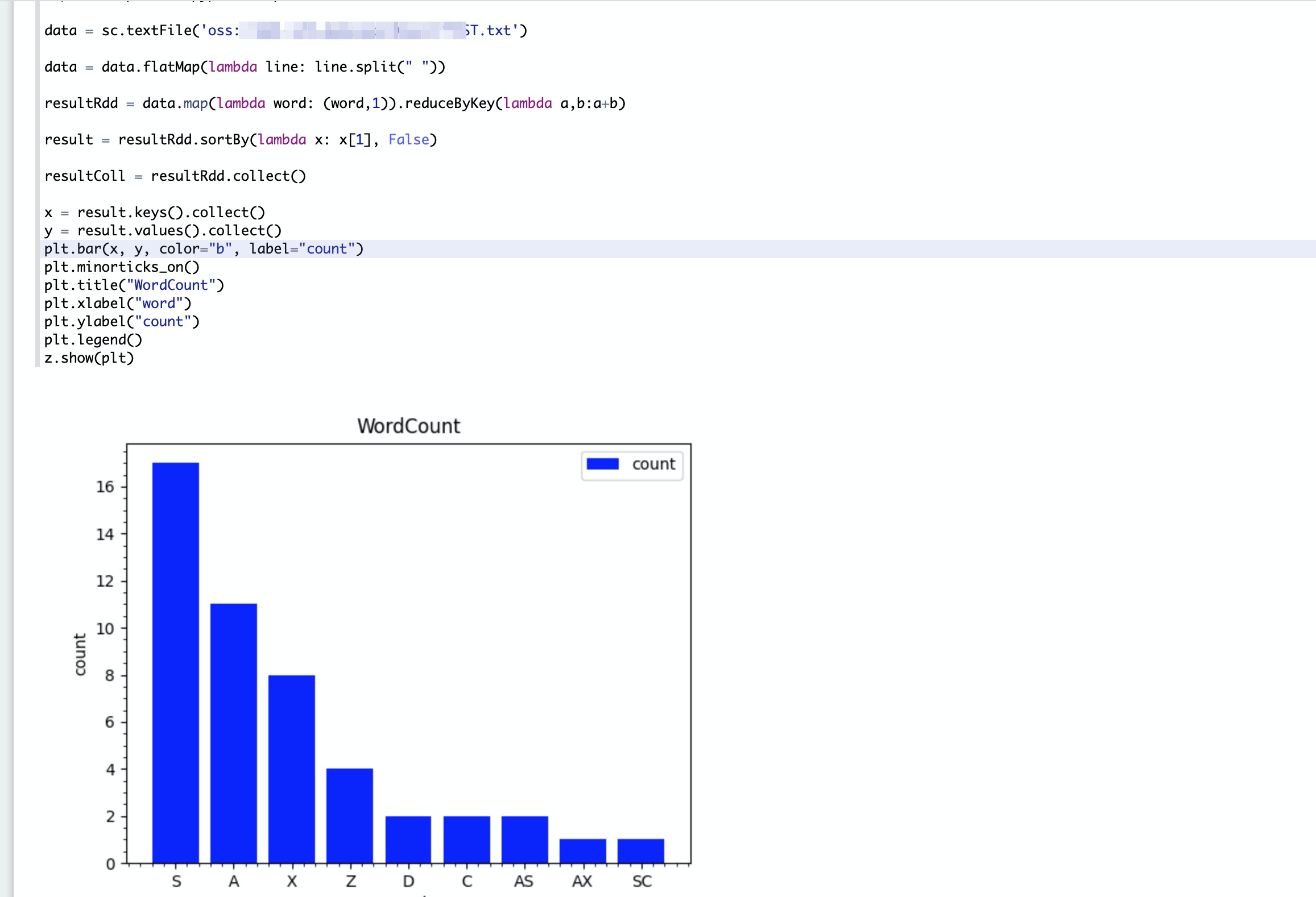
數據開發(fā),將以下代碼寫入note文件,如下圖所示。
%pyspark
import matplotlib.pyplot as plt
data = sc.textFile('oss://xxx/xxx/TEST.txt')
data = data.flatMap(lambda line: line.split(" "))
resultRdd = data.map(lambda word: (word,1)).reduceByKey(lambda a,b:a+b)
result = resultRdd.sortBy(lambda x: x[1], False)
resultColl = resultRdd.collect()
x = result.keys().collect()
y = result.values().collect()
plt.bar(x, y, color="b", label="count")
plt.minorticks_on()
plt.title("WordCount")
plt.xlabel("word")
plt.ylabel("count")
plt.legend()
z.show(plt)單擊右上角運行按鈕,等待任務結束查看結果
文檔內容是否對您有幫助?