機(jī)器學(xué)習(xí)開(kāi)發(fā)示例
本文中含有需要您注意的重要提示信息,忽略該信息可能對(duì)您的業(yè)務(wù)造成影響,請(qǐng)務(wù)必仔細(xì)閱讀。
本文介紹如何使用阿里云 Databricks 數(shù)據(jù)洞察的Notebook進(jìn)行機(jī)器學(xué)習(xí)開(kāi)發(fā)。
首次使用DDI產(chǎn)品創(chuàng)建的Bucket為系統(tǒng)目錄Bucket,不建議存放數(shù)據(jù),您需要再創(chuàng)建一個(gè)Bucket來(lái)讀寫(xiě)數(shù)據(jù)。
DDI訪問(wèn)OSS路徑結(jié)構(gòu):oss://BucketName/Object
BucketName為您的存儲(chǔ)空間名稱。
Object為上傳到OSS上的文件的訪問(wèn)路徑。
例:讀取在存儲(chǔ)空間名稱為databricks-demo-hangzhou文件路徑為demo/The_Sorrows_of_Young_Werther.txt的文件
// 從oss地址讀取文本文檔
val dataRDD = sc.textFile("oss://databricks-demo-hangzhou/demo/The_Sorrows_of_Young_Werther.txt")開(kāi)發(fā)流程
在本教程中,您將執(zhí)行以下步驟:
創(chuàng)建集群并通過(guò)knox賬號(hào)訪問(wèn)Notebook
創(chuàng)建Notebook、加載樣本數(shù)據(jù)
準(zhǔn)備ML算法數(shù)據(jù)
建立模型、運(yùn)行線性回歸模型
評(píng)估線性回歸模型
可視化線性回歸模型
步驟一:創(chuàng)建集群并通過(guò)knox賬號(hào)訪問(wèn)Notebook
創(chuàng)建集群參考: 創(chuàng)建集群,需注意要設(shè)置ram子賬號(hào)及保存好knox密碼,登錄WebUI時(shí)候需要用到。
步驟二:創(chuàng)建Notebook、加載樣本數(shù)據(jù)
開(kāi)始進(jìn)行機(jī)器學(xué)習(xí)的最簡(jiǎn)單方法是使用對(duì)象存儲(chǔ)工作區(qū)中可訪問(wèn)的文件夾中的示例Databricks數(shù)據(jù)集 。例如,要訪問(wèn)將城市人口數(shù)量與房屋平均價(jià)格進(jìn)行比較的文件,您可以通過(guò)oss路徑訪問(wèn)文件。例如:oss://databricks-datasets/samples/data_geo.csv。
1.加載oss數(shù)據(jù),并緩存
%pyspark
path="oss://databricks-datasets/samples/data_geo.csv" # 根據(jù)oss路徑;
# 加載樣本數(shù)據(jù)并打印;
data = spark.read \
.option("header", "true") \
.option("inferSchema", "true") \
.csv(path) \
data.cache() # 緩存數(shù)據(jù)以加快重用2.數(shù)據(jù)展示,打印schema
%pyspark
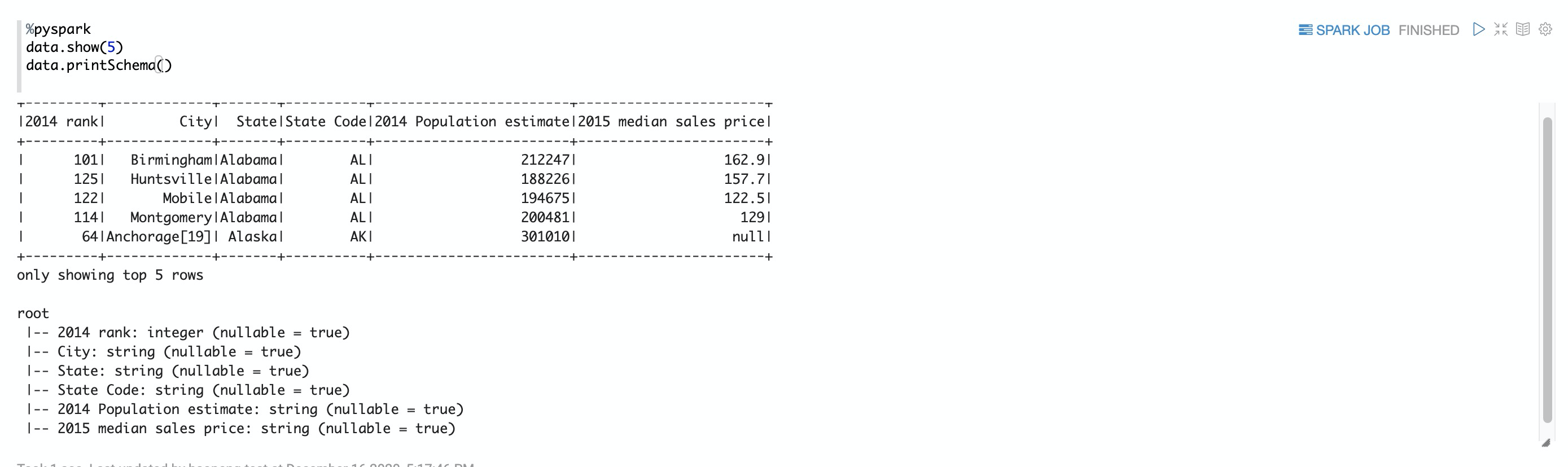
data.show(5)
data.printSchema()數(shù)據(jù)打印
步驟三:準(zhǔn)備ML算法數(shù)據(jù)
在監(jiān)督學(xué)習(xí)(例如回歸算法)中,通常需要定義標(biāo)簽(lable)和一組要素(features)。在此線性回歸示例中,標(biāo)簽為2015年中位數(shù)銷(xiāo)售價(jià)格(lable),特征為2014年人口估計(jì)(features)。您使用特征來(lái)預(yù)測(cè)標(biāo)簽(售價(jià))。
1.數(shù)據(jù)類型轉(zhuǎn)換,刪除缺少值的行,然后重命名特征和標(biāo)簽列,并用"_"替換空格
%pyspark
from pyspark.sql.functions import col
from pyspark.sql.types import DoubleType
#數(shù)據(jù)類型轉(zhuǎn)換
datat=data.select(col("2014 rank"),col("city"),col("state"),col("State Code"),col("2014 Population estimate"),col("2015 median sales price").cast(DoubleType()))
#刪除缺少值的行
datat = datat.dropna()
#重命名特征和標(biāo)簽列,并用"_"替換空格
exprs = [col(column).alias(column.replace(' ', '_')) for column in datat.columns]2.為了簡(jiǎn)化特征的創(chuàng)建,請(qǐng)注冊(cè)UDF以將特征(2014_Population_estimate)列向量轉(zhuǎn)換為VectorUDT類型并將其應(yīng)用于該列
%pyspark
from pyspark.ml.linalg import Vectors, VectorUDT
# 定義UDF函數(shù),數(shù)據(jù)向量化處理;
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
ml_data = datat.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
3.數(shù)據(jù)展示
%pyspark
# 數(shù)據(jù)展示
ml_data.show()ML算法數(shù)據(jù)打印

步驟四:建立模型、運(yùn)行線性回歸模
在本部分中,您將使用不同的正則化參數(shù)運(yùn)行兩個(gè)不同的線性回歸模型,以基于人口(features)確定這兩個(gè)模型中的任何一個(gè)對(duì)銷(xiāo)售價(jià)格(label)的預(yù)測(cè)程度。
1.建立模型
%pyspark
from pyspark.ml.regression import LinearRegression
# 定義LinearRegression算法
lr = LinearRegression()
# 建立模型
modelA = lr.fit(ml_data, {lr.regParam:0.0})
modelB = lr.fit(ml_data, {lr.regParam:100.0})
2.使用該模型并作出預(yù)測(cè),您可以使用transform()函數(shù)進(jìn)行預(yù)測(cè),該函數(shù)會(huì)添加新的預(yù)測(cè)列。例如下面的代碼采用第一個(gè)模型(modelA),并根據(jù)特征(features)向您顯示標(biāo)簽(原始銷(xiāo)售價(jià)格)和預(yù)測(cè)(預(yù)測(cè)銷(xiāo)售價(jià)格)
%pyspark
# 運(yùn)行線性回歸模型,并展示數(shù)據(jù)
predictionsA = modelA.transform(ml_data)
predictionsA.show(10)數(shù)據(jù)打印
步驟五:評(píng)估線性回歸模型
要評(píng)估回歸分析,請(qǐng)使用RegressionEvaluator來(lái)計(jì)算均方根誤差 。
在機(jī)器學(xué)習(xí)中我們用計(jì)算測(cè)試值和預(yù)測(cè)值之間出現(xiàn)的誤差的均方根的平均值來(lái)查看模型的準(zhǔn)確性。
%pyspark
from pyspark.ml.evaluation import RegressionEvaluator
# 使RegressionEvaluator用來(lái)計(jì)算均方根誤差 。
evaluator = RegressionEvaluator(metricName="rmse")
RMSE = evaluator.evaluate(predictionsA)
print("ModelA: Root Mean Squared Error = " + str(RMSE))
# ModelA: Root Mean Squared Error = 128.602026843
predictionsB = modelB.transform(ml_data)
RMSE = evaluator.evaluate(predictionsB)
print("ModelB: Root Mean Squared Error = " + str(RMSE))
# ModelB: Root Mean Squared Error = 129.496300193RMSE評(píng)估結(jié)果打印
我們的RMSE值約為128~130。 好的模型的RMSE值應(yīng)小于180。如果您具有較高的RMSE值,則意味著您可能需要更改功能或調(diào)整超參數(shù)。
步驟六:可視化線性回歸模型
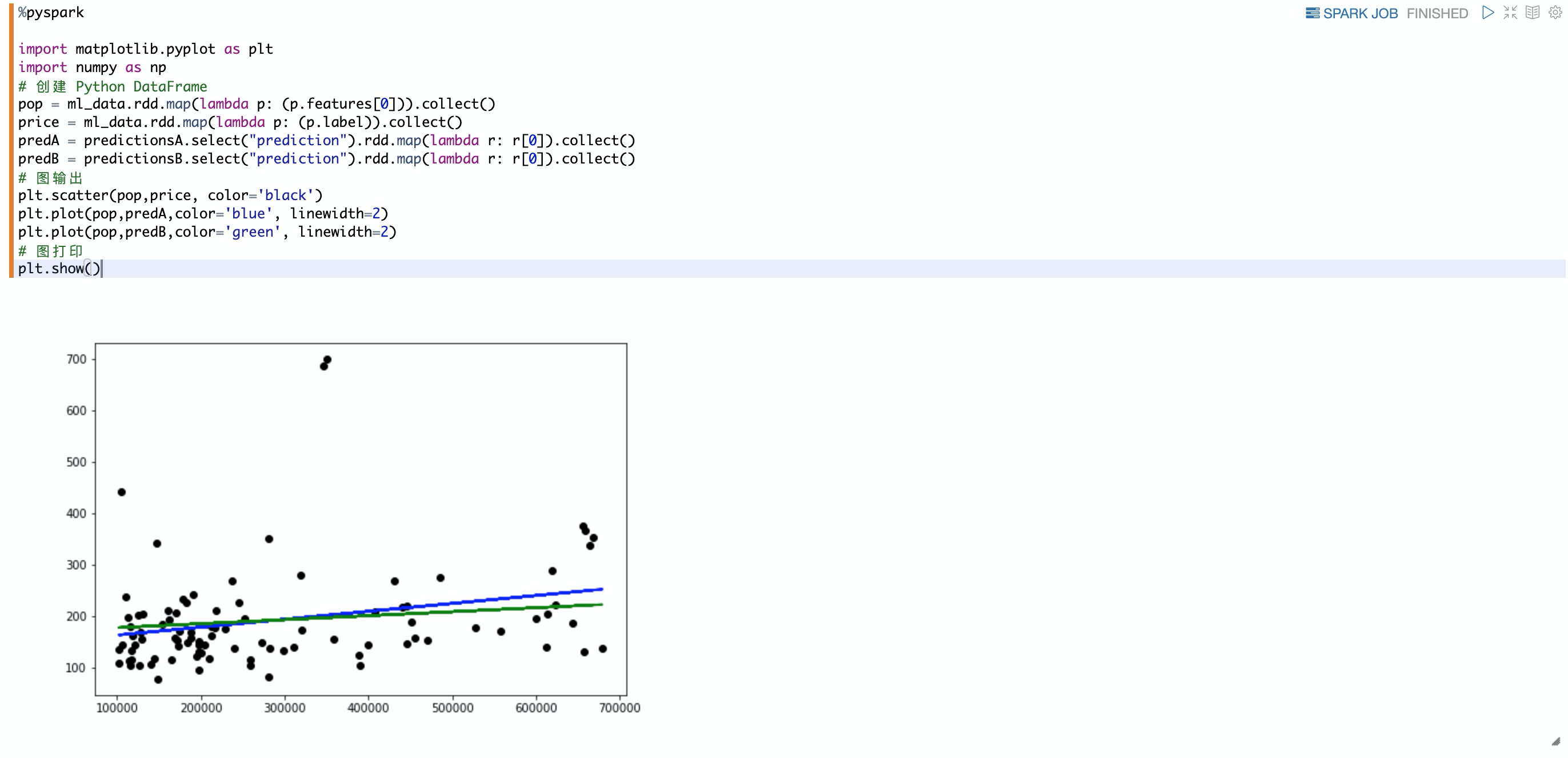
可視化散點(diǎn)圖,與許多機(jī)器學(xué)習(xí)算法一樣使用matplotlib創(chuàng)建線性回歸圖以顯示散點(diǎn)圖和兩個(gè)回歸模型。
依賴庫(kù)導(dǎo)入
當(dāng)使用pyspark進(jìn)行開(kāi)發(fā)時(shí)候,依賴的庫(kù)可以通過(guò)ddi庫(kù)能力導(dǎo)入,具體見(jiàn):Python庫(kù)管理
這里示例導(dǎo)入matplotlib庫(kù),并做展示——先download下官方庫(kù)安裝包,在庫(kù)功能下進(jìn)行.whl文件的上傳,在需要使用庫(kù)的集群里進(jìn)行安裝
2.創(chuàng)建Python DataFrame 、使用matplotlib做圖渲染 、圖打印
%pyspark
#為展示效果,本實(shí)例對(duì)樣本數(shù)據(jù)做了部分篩選;
import matplotlib.pyplot as plt
import numpy as np
# 創(chuàng)建 Python DataFrame
pop = ml_data.rdd.map(lambda p: (p.features[0])).collect()
price = ml_data.rdd.map(lambda p: (p.label)).collect()
predA = predictionsA.select("prediction").rdd.map(lambda r: r[0]).collect()
predB = predictionsB.select("prediction").rdd.map(lambda r: r[0]).collect()
# 圖渲染
plt.scatter(pop,price, color='black')
plt.plot(pop,predA,color='blue', linewidth=2)
plt.plot(pop,predB,color='green', linewidth=2)
# 圖打印
z.show(plt)