本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
Delta 表支持許多實用程序命令。
詳細文章請參考Databricks官網文章:表實用程序命令。
有關演示這些功能的Databricks筆記本,請參閱入門筆記本二。
刪除Delta表不再引用的文件
您可以通過在表上運行vacuum命令來刪除Delta表不再引用且早于保留閾值的文件。vacuum 不會自動觸發。文件的默認保留閾值為7天。
vacuum僅刪除數據文件,而不刪除日志文件。檢查點操作后,日志文件將自動異步刪除。日志文件的默認保留期為30天,可通過使用ALTER TABLE SET TBLPROPERTIES SQL方法設置的delta.logRetentionPeriod屬性進行配置。請參閱表屬性。
運行vacuum后,無法再按時間順序查看在保留期之前創建的版本。
SQL
%sql
VACUUM eventsTable -- vacuum files not required by versions older than the default retention period
VACUUM '/data/events' -- vacuum files in path-based table
VACUUM delta.`/data/events/`
VACUUM delta.`/data/events/` RETAIN 100 HOURS -- vacuum files not required by versions more than 100 hours old
VACUUM eventsTable DRY RUN -- do dry run to get the list of files to be deletedPython
%pyspark
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, pathToTable) # path-based tables, or
deltaTable = DeltaTable.forName(spark, tableName) # Hive metastore-based tables
deltaTable.vacuum() # vacuum files not required by versions older than the default retention period
deltaTable.vacuum(100) # vacuum files not required by versions more than 100 hours oldScala
%spark
import io.delta.tables._
val deltaTable = DeltaTable.forPath(spark, pathToTable)
deltaTable.vacuum() // vacuum files not required by versions older than the default retention period
deltaTable.vacuum(100) // vacuum files not required by versions more than 100 hours old有關語法的詳細信息,請參見
Databricks Runtime 7.0及更高版本:VACUUM
Databricks Runtime 6.x及以下:VACUUM
有關Scala,Java和Python語法的詳細信息,請參見API參考。
我們不建議您將保留間隔設置為短于7天,因為并發的讀取器或寫入器仍然可以將舊快照和未提交的文件用于表。如果 vacuum清除活動文件,則并發閱讀器可能會失敗,或者更糟的是,當vacuum刪除尚未提交的文件時,表可能會損壞。
Delta Lake具有一項安全檢查,以防止您執行危險的vacuum命令。如果您確定在此表上執行的操作沒有超過計劃指定的保留時間間隔,你可以通過設置ApacheSpark屬性spark.databricks.delta.retentionDurationCheck.enabled設置為false來關閉此安全檢查。選擇的時間間隔,必須比最長的并發事務長,也必須比任何流可以滯后于表的最新更新的最長時間長。
檢索Delta表歷史記錄
您可以通過運行history命令來檢索每次寫入Delta表的操作、用戶、時間戳等信息。以相反的時間順序返回操作。默認情況下,表歷史記錄會保留30天。
SQL
%sql
DESCRIBE HISTORY '/data/events/' -- get the full history of the table
DESCRIBE HISTORY delta.`/data/events/`
DESCRIBE HISTORY '/data/events/' LIMIT 1 -- get the last operation only
DESCRIBE HISTORY eventsTable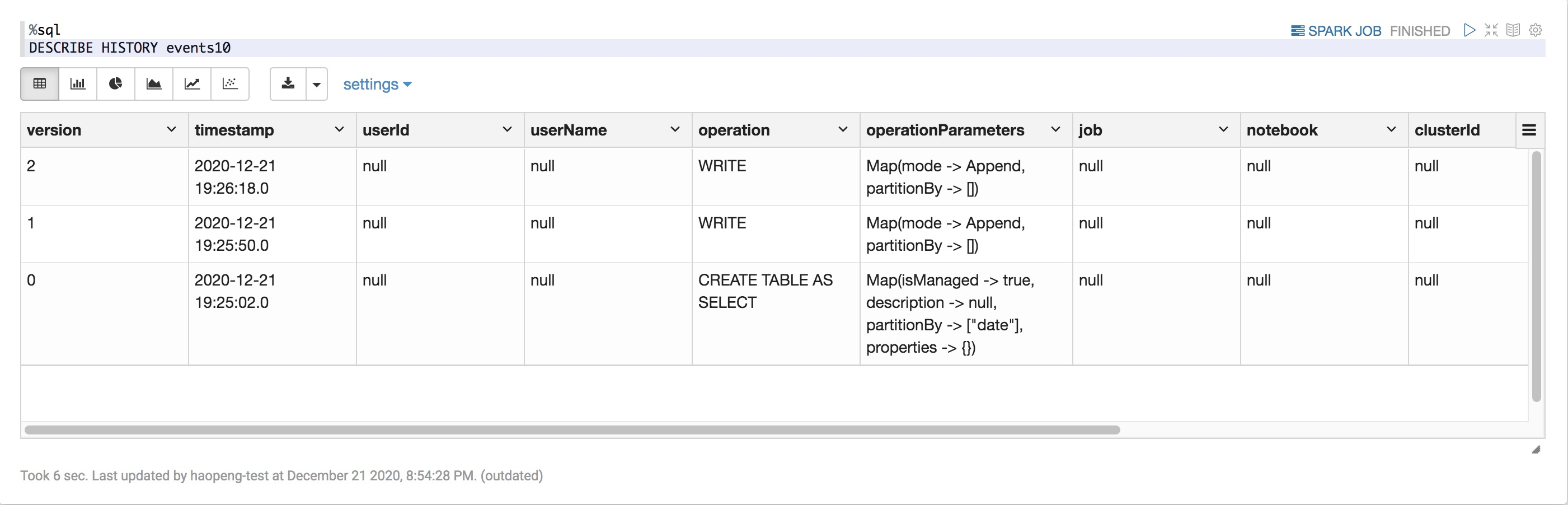
Python
%pyspark
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, pathToTable)
fullHistoryDF = deltaTable.history() # get the full history of the table
lastOperationDF = deltaTable.history(1) # get the last operationScala
%spark
import io.delta.tables._
val deltaTable = DeltaTable.forPath(spark, pathToTable)
val fullHistoryDF = deltaTable.history() // get the full history of the table
val lastOperationDF = deltaTable.history(1) // get the last operation有關Spark SQL語法的詳細信息,請參見
Databricks Runtime 7.0及更高版本:DESCRIBE HISTORY (Delta Lake on Databricks)
Databricks Runtime 6.x及更低版本:Describe History (Delta Lake on Databricks)
有關Scala,Java和Python語法的詳細信息,請參見API參考。
歷史架構
列 | 類型 | 說明 |
版本 | long | 通過操作生成的表版本 |
timestamp | timestamp | 提交此版本的時間 |
userId | 字符串 | 運行操作的用戶的ID |
userName | 字符串 | 運行操作的用戶的姓名。 |
operation | 字符串 | 操作的名稱。 |
operationParameters | map | 操作的參數(例如謂詞。) |
作業(job) | struct | 運行操作的作業的詳細信息。 |
筆記本 | struct | 運行操作的筆記本的詳細信息。 |
clusterId | 字符串 | 運行操作的集群的 ID。 |
readVersion | long | 讀取以執行寫入操作的表的版本。 |
isolationLevel | 字符串 | 用于此操作的隔離級別。 |
isBlindAppend | boolean | 此操作是否追加數據。 |
operationMetrics | map | 操作的指標(例如已修改的行數和文件數。) |
userMetadata | 字符串 | 用戶定義的提交元數據(如果已指定) |
該history操作的輸出包含以下列。
+-------+-------------------+------+--------+---------+--------------------+----+--------+---------+-----------+-----------------+-------------+--------------------+
|version| timestamp|userId|userName|operation| operationParameters| job|notebook|clusterId|readVersion| isolationLevel|isBlindAppend| operationMetrics|
+-------+-------------------+------+--------+---------+--------------------+----+--------+---------+-----------+-----------------+-------------+--------------------+
| 5|2019-07-29 14:07:47| ###| ###| DELETE|[predicate -> ["(...|null| ###| ###| 4|WriteSerializable| false|[numTotalRows -> ...|
| 4|2019-07-29 14:07:41| ###| ###| UPDATE|[predicate -> (id...|null| ###| ###| 3|WriteSerializable| false|[numTotalRows -> ...|
| 3|2019-07-29 14:07:29| ###| ###| DELETE|[predicate -> ["(...|null| ###| ###| 2|WriteSerializable| false|[numTotalRows -> ...|
| 2|2019-07-29 14:06:56| ###| ###| UPDATE|[predicate -> (id...|null| ###| ###| 1|WriteSerializable| false|[numTotalRows -> ...|
| 1|2019-07-29 14:04:31| ###| ###| DELETE|[predicate -> ["(...|null| ###| ###| 0|WriteSerializable| false|[numTotalRows -> ...|
| 0|2019-07-29 14:01:40| ###| ###| WRITE|[mode -> ErrorIfE...|null| ###| ###| null|WriteSerializable| true|[numFiles -> 2, n...|
+-------+-------------------+------+--------+---------+--------------------+----+--------+---------+-----------+-----------------+-------------+--------------------+僅當使用 Databricks Runtime 6.5 或更高版本運行歷史記錄中的 history 命令和操作時,操作指標才可用。
如果使用以下方法寫入Delta表,則其他一些列將不可用:
JDBC或ODBC
JAR工作
Spark提交工具
使用REST API運行命令
將來添加的列將始終添加在最后一列之后。
操作指標鍵
該history操作在operationMetrics列映射中返回操作指標的集合。
下表按操作列出了映射鍵定義。
操作方式 | 指標名稱 | 描述 |
WRITE, CREATE TABLE AS SELECT, REPLACE TABLE AS SELECT, COPY INTO | ||
numFiles | 寫入的文件數。 | |
numOutputBytes | 已寫入的內容的大小(以字節為單位)。 | |
numOutputRows | 寫入的行數。 | |
STREAMING UPDATE | ||
numAddedFiles | 添加的文件數。 | |
numRemovedFiles | 刪除的文件數。 | |
numOutputRows | 寫入的行數。 | |
numOutputBytes | 寫入大小(以字節為單位)。 | |
DELETE | ||
numAddedFiles | 添加的文件數。 刪除表的分區時未提供。 | |
numRemovedFiles | 刪除的文件數。 | |
numDeletedRows | 刪除的行數。 刪除表的分區時未提供。 | |
numCopiedRows | 在刪除文件期間復制的行數。 | |
TRUNCATE | numRemovedFiles | 刪除的文件數。 |
MERGE | ||
numSourceRows | 源數據幀中的行數。 | |
numTargetRowsInserted | 插入到目標表的行數。 | |
numTargetRowsUpdated | 目標表中更新的行數。 | |
numTargetRowsDeleted | 目標表中刪除的行數。 | |
numTargetRowsCopied | 復制的目標行數。 | |
numOutputRows | 寫出的總行數。 | |
numTargetFilesAdded | 添加到接收器(目標)的文件數。 | |
numTargetFilesRemoved | 從接收器(目標)刪除的文件數。 | |
UPDATE | ||
numAddedFiles | 添加的文件數 | |
numRemovedFiles | 刪除的文件數。 | |
numUpdatedRows | 更新的行數。 | |
numCopiedRows | 剛才在更新文件期間復制的行數。 | |
FSCK | numRemovedFiles | 刪除的文件數。 |
CONVERT | numConvertedFiles | 已轉換的 Parquet 文件數。 |
操作方式 | 指標名稱 | 描述 |
CLONE | ||
sourceTableSize | 所克隆版本的源表的大小(以字節為單位)。 | |
sourceNumOfFiles | 源表中已克隆版本的文件數。 | |
numRemovedFiles | 目標表中刪除的文件數(如果替換了先前的 Delta 表)。 | |
removedFilesSize | 如果替換了先前的 Delta 表,則為目標表中刪除文件的總大小(以字節為單位)。 | |
numCopiedFiles | 復制到新位置的文件數。 如果是淺表克隆,則為 0。 | |
copiedFilesSize | 復制到新位置的文件總大小(以字節為單位)。 如果是淺表克隆,則為 0。 | |
RESTORE | ||
tableSizeAfterRestore | 還原后的表大小(以字節為單位)。 | |
numOfFilesAfterRestore | 還原后表中的文件數。 | |
numRemovedFiles | 還原操作刪除的文件數。 | |
numRestoredFiles | 由于還原而添加的文件數。 | |
removedFilesSize | 還原刪除的文件的大小(以字節為單位)。 | |
restoredFilesSize | 還原添加的文件的大小(以字節為單位)。 | |
OPTIMIZE | ||
numAddedFiles | 添加的文件數。 | |
numRemovedFiles | 優化的文件數。 | |
numAddedBytes | 優化表后添加的字節數。 | |
numRemovedBytes | 刪除的字節數。刪除的字節數。 | |
minFileSize | 優化表后最小文件的大小。 | |
p25FileSize | 優化表后第 25 個百分位文件的大小。 | |
p50FileSize | 優化表后的文件大小中值。 | |
p75FileSize | 優化表后第 75 個百分位文件的大小。 | |
maxFileSize | 優化表后最大文件的大小。 |
需要Databricks Runtime 7.3或更高版本。
需要Databricks Runtime 7.4或更高版本。
檢索Delta表詳細信息
可以使用“描述詳細信息”檢索有關增量表的詳細信息(例如,文件數、數據大小)。
SQL
%sql
DESCRIBE DETAIL '/data/events/'
DESCRIBE DETAIL eventsTable詳細架構
此操作的輸出只有一行具有以下架構。
列 | 類型 | 說明 |
format | 字符串 | 表的格式,即“delta”。 |
id | 字符串 | 表的唯一 ID。 |
name | 字符串 | 在元存儲中定義的表名稱。 |
description | 字符串 | 表的說明。 |
location | 字符串 | 表的位置。 |
createdAt | timestamp | 表創建時間。 |
lastModified | timestamp | 表的上次修改時間。 |
partitionColumns | 字符串數組 | 如果表已分區,則為分區列的名稱。 |
numFiles | long | 表最新版本中的文件數。 |
properties | string-string map | 此表的所有屬性集。 |
minReaderVersion | int | 可讀取表的讀取器最低版本(由日志協議而定)。 |
minWriterVersion | int | 可寫入表的寫入器最低版本(由日志協議而定)。 |
+------+--------------------+------------------+-----------+--------------------+--------------------+-------------------+----------------+--------+-----------+----------+----------------+----------------+
|format| id| name|description| location| createdAt| lastModified|partitionColumns|numFiles|sizeInBytes|properties|minReaderVersion|minWriterVersion|
+------+--------------------+------------------+-----------+--------------------+--------------------+-------------------+----------------+--------+-----------+----------+----------------+----------------+
| delta|d31f82d2-a69f-42e...|default.deltatable| null|file:/Users/tdas/...|2020-06-05 12:20:...|2020-06-05 12:20:20| []| 10| 12345| []| 1| 2|
+------+--------------------+------------------+-----------+--------------------+--------------------+-------------------+----------------+--------+-----------+----------+----------------+----------------+生成清單文件
您可以為Delta表生成清單文件,供其他處理引擎(即Apache Spark以外的其他引擎)用來讀取Delta表。例如,要生成清單文件,Presto和Athena可以使用它們來讀取Delta表,請運行以下命令:
SQL
%sql
GENERATE symlink_format_manifest FOR TABLE delta.`/mnt/events`
GENERATE symlink_format_manifest FOR TABLE eventsTablePython
%pyspark
deltaTable = DeltaTable.forPath(<path-to-delta-table>)
deltaTable.generate("symlink_format_manifest")Scala
%spark
val deltaTable = DeltaTable.forPath(<path-to-delta-table>)
deltaTable.generate("symlink_format_manifest")將Parquet表轉換為Delta表
就地將Parquet表轉換為Delta表。此命令會列出目錄中的所有文件,創建一個Delta Lake事務日志來跟蹤這些文件,并通過讀取所有Parquet文件的頁腳自動推斷數據架構。如果您的數據已分區,則必須將分區列的架構指定為DDL格式的字符串(即)。<column-name1> <type>, <column-name2> <type>, ...
SQL
%SQL
-- Convert unpartitioned parquet table at path '<path-to-table>'
CONVERT TO DELTA parquet.`<path-to-table>`
-- Convert partitioned Parquet table at path '<path-to-table>' and partitioned by integer columns named 'part' and 'part2'
CONVERT TO DELTA parquet.`<path-to-table>` PARTITIONED BY (part int, part2 int)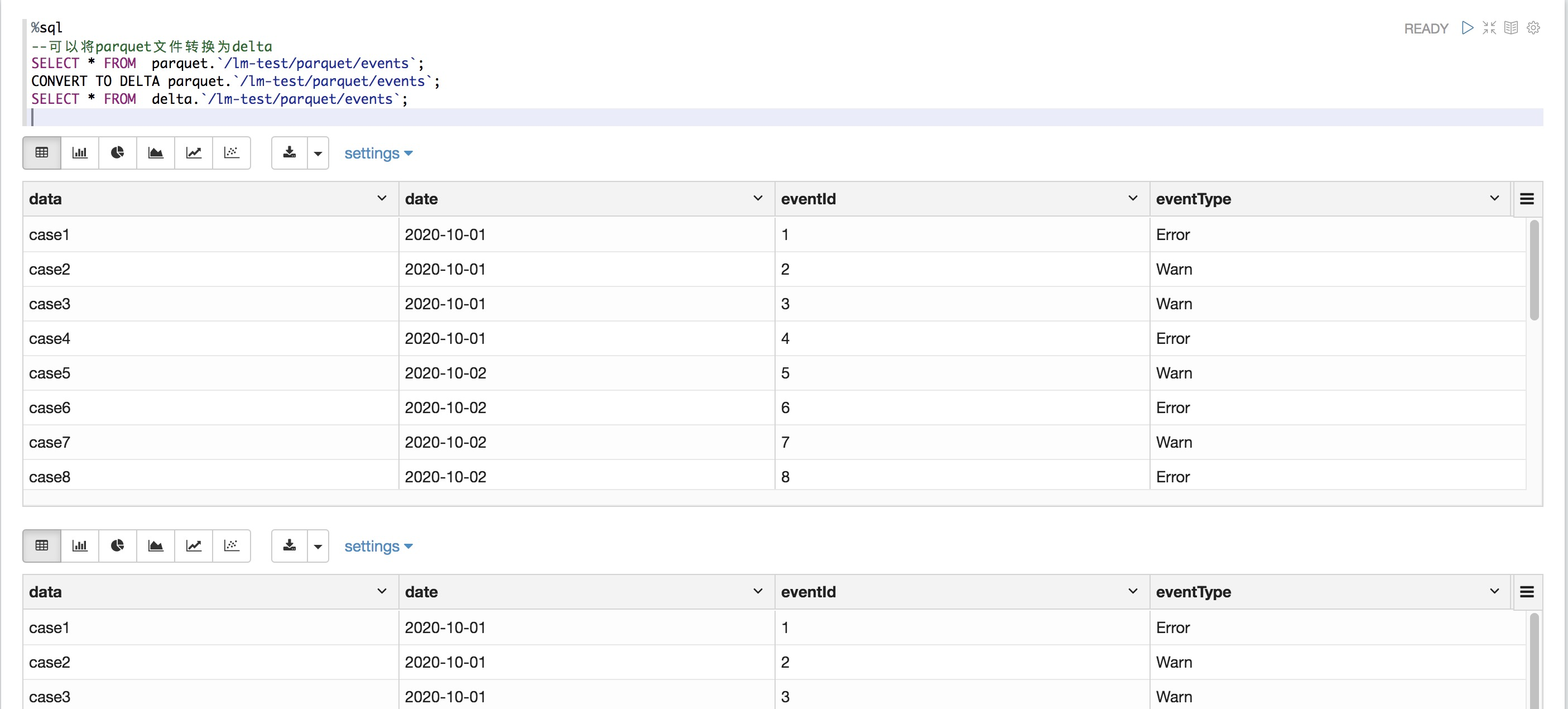
Python
%pyspark
from delta.tables import *
# Convert unpartitioned parquet table at path '<path-to-table>'
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`<path-to-table>`")
# Convert partitioned parquet table at path '<path-to-table>' and partitioned by integer column named 'part'
partitionedDeltaTable = DeltaTable.convertToDelta(spark, "parquet.`<path-to-table>`", "part int")可在 Databricks Runtime 6.1 及更高版本中使用 Python API。
Scala
%spark
import io.delta.tables._
// Convert unpartitioned Parquet table at path '<path-to-table>'
val deltaTable = DeltaTable.convertToDelta(spark, "parquet.`<path-to-table>`")
// Convert partitioned Parquet table at path '<path-to-table>' and partitioned by integer columns named 'part' and 'part2'
val partitionedDeltaTable = DeltaTable.convertToDelta(spark, "parquet.`<path-to-table>`", "part int, part2 int")可在 Databricks Runtime 6.0 及更高版本中使用 Scala API。
有關語法的詳細信息,請參見
Databricks運行時7.0及更高版本:轉換為DELTA(Databricks上的Delta Lake)
Databricks Runtime 6.x及更低版本:轉換為Delta(Databricks上的Delta Lake)
Delta Lake跟蹤的文件都是不可見的,運行vacuum時可以刪除。您勿在轉換過程中更新或附加數據文件。轉換表后,請確保通過Delta Lake寫入所有文件。
將Delta表轉換為Parquet表
您可以使用以下步驟輕松地將Delta表轉換回Parquet表:
如果執行了可以更改數據文件的Delta Lake操作(例如delete或merge),請運行vacuum并將保留期限設為0小時,從而刪除表的最新版本中未包含的所有數據文件。
刪除目錄中的_delta_log目錄。
將Delta表還原到較早的狀態
此功能目前以 公共預覽版提供。
在Databricks Runtime 7.4及更高版本中可用。
您可以使用以下RESTORE命令將Delta表還原到其早期狀態。Delta表在內部維護該表的歷史版本,以使其能夠還原到較早的狀態。RESTORE命令支持與早期狀態相對應的版本或創建早期狀態的時間戳。
您可以還原已經還原的表和克隆的表。
將表還原到手動或刪除數據文件的舊版本vacuum將失敗。如果spark.sql.files.ignoreMissingFiles設置為true,仍然可以部分還原到該版本。
恢復到較早狀態的時間戳格式為yyyy-MM-dd HH:mm:ssyyyy-MM-dd。還支持僅提供date()字符串。
SQL
%sql
RESTORE TABLE db.target_table TO VERSION AS OF <version>
RESTORE TABLE delta.`/data/target/` TO TIMESTAMP AS OF <timestamp>Python
%pyspark
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, <path-to-table>) # path-based tables, or
deltaTable = DeltaTable.forName(spark, <table-name>) # Hive metastore-based tables
deltaTable.restoreToVersion(0) # restore table to oldest version
deltaTable.restoreToTimestamp('2019-02-14') # restore to a specific timestampScala
%spark
import io.delta.tables._
val deltaTable = DeltaTable.forPath(spark, <path-to-table>)
val deltaTable = DeltaTable.forName(spark, <table-name>)
deltaTable.restoreToVersion(0) // restore table to oldest version
deltaTable.restoreToTimestamp("2019-02-14") // restore to a specific timestamp有關語法的詳細信息,請參見RESTORE(Databricks上的Delta Lake)。
表訪問控制
您必須MODIFY對要還原的表具有權限
克隆 Delta 表
此功能目前以 公共預覽版提供。
在Databricks Runtime 7.2及更高版本中可用。
您可以使用以下clone命令以特定版本創建現有Delta表的副本。克隆可以是深層或淺層。
深層克隆是指除了現有表的元數據外,還會將源表數據復制到克隆目標的克隆。 此外,它還會克隆流元數據,使寫入 Delta 表的流可在源表上停止,并在克隆的目標位置(即停止位置)繼續進行克隆。
淺表克隆不會將數據文件復制到克隆目標。 表元數據等效于源。 創建這些克隆的成本較低。
對深層克隆或淺層克隆所做的任何更改都只會影響克隆本身,而不會影響源表。
克隆的元數據包括:架構,分區信息,不變量,可為Null性。對于深層克隆,還將克隆流和COPY INTO(Databricks上的Delta Lake)元數據。未克隆的元數據是表描述和用戶定義的提交元數據。
淺克隆引用源目錄中的數據文件。如果在源表上運行vacuum,客戶端將無法再讀取引用的數據文件,并將引發FileNotFoundException。在這種情況下,在淺層克隆上運行clone with replace將修復克隆。如果經常發生這種情況,請考慮使用不依賴于源表的深層克隆。
深度克隆不依賴于其克隆來源,因為深度克隆會復制數據以及元數據,所以創建深度克隆的成本很高。
使用 replace 克隆到已在該路徑具有表的目標時,如果該路徑不存在,會創建一個 Delta 日志。您可以通過vacuum運行清理任何現有數據。如果現有表是Delta表,則會在現有Delta表上創建新的提交,其中包括源表中的新元數據和新數據。
克隆表與 Create Table As Select 或 CTAS 不同,除了數據之外,克隆還復制源表的元數據。克隆的語法更為簡單:不需要指定分區、格式、不變量、可Null性等,因為它們取自源表。
克隆表與其具有源表無關的歷史記錄。在克隆表上的按時間查詢時,這些查詢使用的輸入與它們在其源表上查詢時使用的不同。
SQL
%sql
CREATE TABLE delta.`/data/target/` CLONE delta.`/data/source/` -- Create a deep clone of /data/source at /data/target
CREATE OR REPLACE TABLE db.target_table CLONE db.source_table -- Replace the target
CREATE TABLE IF NOT EXISTS TABLE delta.`/data/target/` CLONE db.source_table -- No-op if the target table exists
CREATE TABLE db.target_table SHALLOW CLONE delta.`/data/source`
CREATE TABLE db.target_table SHALLOW CLONE delta.`/data/source` VERSION AS OF version
CREATE TABLE db.target_table SHALLOW CLONE delta.`/data/source` TIMESTAMP AS OF timestamp_expression -- timestamp can be like “2019-01-01” or like date_sub(current_date(), 1)Python
%pyspark
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, pathToTable) # path-based tables, or
deltaTable = DeltaTable.forName(spark, tableName) # Hive metastore-based tables
deltaTable.clone(target, isShallow, replace) # clone the source at latest version
deltaTable.cloneAtVersion(version, target, isShallow, replace) # clone the source at a specific version
# clone the source at a specific timestamp such as timestamp=“2019-01-01”
deltaTable.cloneAtTimestamp(timestamp, target, isShallow, replace)Scala
%spark
import io.delta.tables._
val deltaTable = DeltaTable.forPath(spark, pathToTable)
val deltaTable = DeltaTable.forName(spark, tableName)
deltaTable.clone(target, isShallow, replace) // clone the source at latest version
deltaTable.cloneAtVersion(version, target, isShallow, replace) // clone the source at a specific version
deltaTable.cloneAtTimestamp(timestamp, target, isShallow, replace) // clone the source at a specific timestamp有關語法的詳細信息,請參見CLONE(Databricks上的Delta Lake)
權限
您必須CLONEDatabricks表訪問控制和您的云提供的所需的權限。
表訪問控制
深層和淺層克隆都需要具有以下權限:
源表上的SELECT權限
如果要CLONE用于創建新表,請對創建表的數據庫具有CREATE權限。
如果要CLONE用來替換表,則必須具有該表的MODIFY權限。
云權限
如果創建了深度克隆,則任何讀取該深度克隆的用戶都必須具有對該克隆目錄的讀取權限。要更改克隆,用戶必須具有對克隆目錄的寫入權限。
如果創建了淺表克隆,則讀取淺表克隆的任何用戶都需要權限才能讀取原始表中的文件,因為數據文件保留在源表中,并且包含淺表克隆以及該表的目錄。若要更改克隆,用戶需要對克隆目錄具有寫入權限。
克隆用例
數據存檔:數據保存的時間可能會比按時間查看或災難恢復的時間更長。在這些情況下,您可以創建一個深層克隆,保留表的某個時間點的狀態以供存檔。還可以通過增量存檔保留源表的持續更新狀態,以進行災難恢復。
SQL
%sql -- Every month run CREATE OR REPLACE TABLE delta.`/some/archive/path` CLONE my_prod_table機器學習流重現:在進行機器學習時,你可能希望將已訓練 ML 模型的表的特定版本進行存檔。可以使用此存檔數據集測試將來的模型。
SQL
%sql -- Trained model on version 15 of Delta table CREATE TABLE delta.`/model/dataset` CLONE entire_dataset VERSION AS OF 15在生產表上進行短期實驗:為了在不損壞表的情況下測試生產表中的工作流,可以輕松創建淺表克隆。這樣,就可在包含所有生產數據的克隆表上運行任意工作流,而不會影響任何生產工作負載。
SQL
%sql -- Perform shallow clone CREATE OR REPLACE TABLE my_test SHALLOW CLONE my_prod_table; UPDATE my_test WHERE user_id is null SET invalid=true; -- Run a bunch of validations. Once happy: -- This should leverage the update information in the clone to prune to only -- changed files in the clone if possible MERGE INTO my_prod_table USING my_test ON my_test.user_id <=> my_prod_table.user_id WHEN MATCHED AND my_test.user_id is null THEN UPDATE *; DROP TABLE my_test;數據共享:單個組織內的其他業務部門可能希望訪問上述的數據,但可能不需要最新更新。可以為不同的業務部門提供具有不同權限的克隆,而不是直接授予對源表的訪問權限。克隆的性能比簡單視圖的性能更高。
SQL
%sql -- Perform deep clone CREATE OR REPLACE TABLE shared_table CLONE my_prod_table; -- Grant other users access to the shared table GRANT SELECT ON shared_table TO `<user-name>@<user-domain>.com`;