Delta緩存通過使用快速中間數據格式在節點的本地存儲中創建遠程文件的副本來加速數據讀取。每當需要從遠程位置獲取文件時,數據都會自動緩存。然后在本地的連續讀取上述數據,從而顯著提高讀取速度。
詳細內容可參考Databricks官網文章:通過緩存優化性能
Delta緩存支持讀取DBFS、HDFS、azureblob存儲、azuredatalake存儲Gen1和azuredatalake存儲Gen2中的Parquet文件。它不支持其他存儲格式,如CSV、JSON和ORC。
Delta緩存適用于所有Parquet文件,并且不僅限于Delta Lake格式的文件。
Delta和Apache Spark緩存
Databricks提供兩種類型的緩存:增量緩存和Apache Spark緩存。這是每種類型的特征:
存儲的數據類型:Delta緩存包含遠程數據的本地副本。它可以提高各種查詢的性能,但不能用于存儲任意子查詢的結果。Spark緩存可以存儲任何子查詢數據的結果以及以Parquet以外的格式(例如CSV,JSON和ORC)存儲的數據。
性能:Delta緩存中存儲的數據比Spark緩存中的數據讀取和操作速度更快。這是因為Delta緩存使用高效的解壓算法,并以最佳格式輸出數據,以便使用整個階段的代碼生成進行進一步處理。
自動與手動控制:啟用Delta緩存時,必須從遠程源獲取的數據將自動添加到緩存中。這個過程是完全透明的,不需要任何操作。但是,要預先將數據預加載到緩存中,可以使用cache命令(請參見緩存數據的子集)。使用Spark緩存時,必須手動指定要緩存的表和查詢。
磁盤與基于內存:Delta緩存完全存儲在本地磁盤上,這樣就不會從Spark中的其他操作中占用內存。由于現代固態硬盤的高讀取速度,Delta緩存可以完全駐留在磁盤上,而不會對其性能產生負面影響。相反,Spark緩存使用內存。
您可以同時使用Delta緩存和Apache Spark緩存。
概要
下表總結了Delta和Apache Spark緩存之間的主要區別,以便您選擇最合適工作流的工具:
功能 | Delta 緩存 | Apache Spark 緩存 |
|---|---|---|
儲存格式 | 工作節點上的本地文件。 | In-memory blocks,但它取決于存儲級別。 |
適用對象 | WASB和其他文件系統上存儲任何Parquet表。 | 任何RDD或DataFrame。 |
觸發 | 自動執行,第一次讀取時(如果啟用了緩存)。 | 手動執行,需要更改代碼。 |
已評估 | Lazily. | Lazily. |
強制緩存 | CACHE 和 SELECT | .cache + 任何實現緩存的操作和.persist. |
可用性 | 可以通過配置標志啟用或禁用,在某些節??點類型上禁用。 | 始終可用 |
驅逐 | 在任何文件更改時自動執行,重新啟動集群時手動執行。 | 以LRU方式自動執行,使用unpersist手動執行。 |
Delta 緩存一致性
Delta緩存會自動檢測何時創建或刪除數據文件,并相應地更新其內容。您可以寫入,修改和刪除表數據,而無需顯示的使緩存數據無效。
Delta緩存會自動檢測緩存后已被修改或覆蓋的文件。所有陳舊的條目都會自動失效并從緩存中逐出。
使用Delta緩存
要使用Delta緩存,請在配置集群時選擇Delta緩存加速工作器類型。
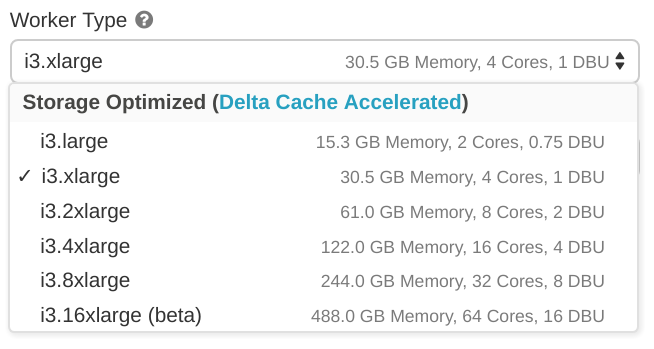 默認啟用Delta緩存,并配置為最多使用工作節點隨附的本地SSD上一半可用空間。
默認啟用Delta緩存,并配置為最多使用工作節點隨附的本地SSD上一半可用空間。
有關配置選項,請參閱“配置Delta緩存”。
緩存數據的子集
要明確選擇需要緩存的數據子集,請使用以下語法:
SQL
CACHE SELECT column_name[, column_name, ...] FROM [db_name.]table_name [ WHERE boolean_expression ]您無需使用此命令即可正常使用Delta緩存(數據在首次訪問時將自動緩存)。但是,當您需要一致的查詢性能時,它可能會有所幫助。
有關示例和更多詳細信息,請參見
Databricks Runtime 7.x:CACHE(Databricks上的Delta Lake)
Databricks運行時5.5 LTS和6.x:CACHE(Databricks上的Delta Lake)
監控Delta緩存
您可以在Spark UI的“存儲”選項卡中的每個執行器上檢查Delta緩存的當前狀態。
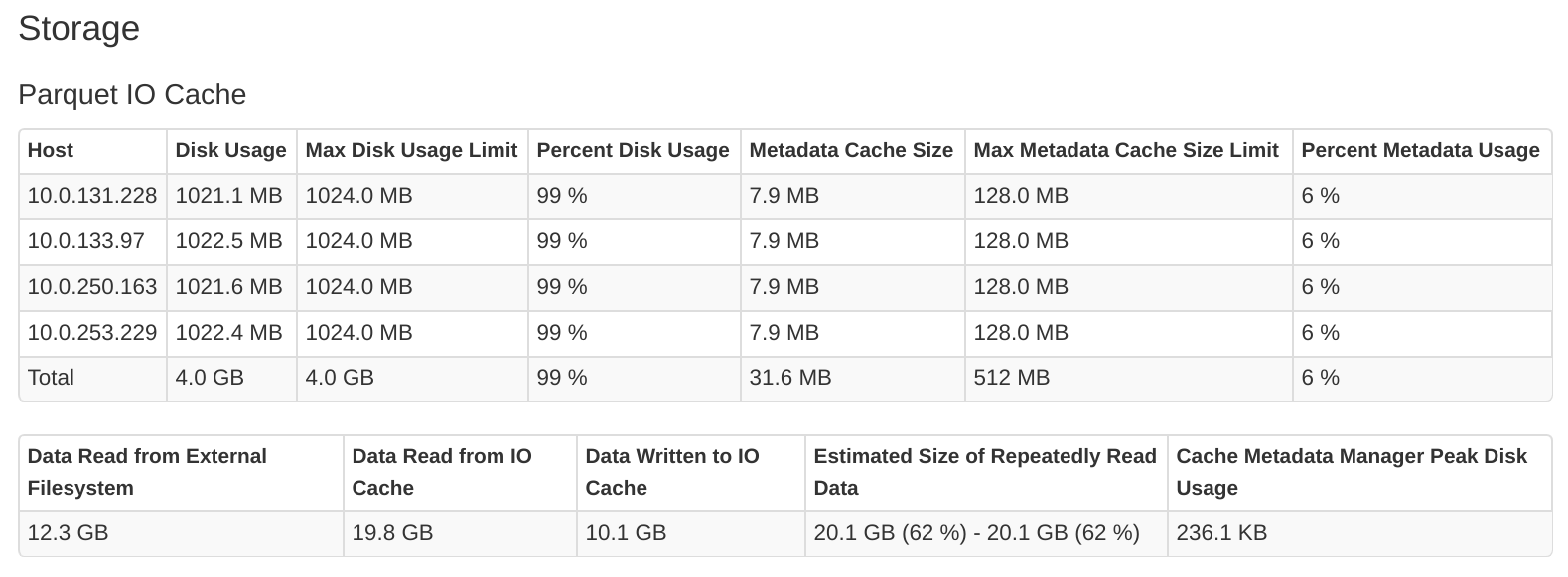 當節點的磁盤使用率達到100%時,緩存管理器將丟棄最近最少使用的緩存條目,以便為新數據騰出空間。
當節點的磁盤使用率達到100%時,緩存管理器將丟棄最近最少使用的緩存條目,以便為新數據騰出空間。
配置Delta緩存
Databricks建議您為集群選擇緩存加速的工作程序實例類型。此類實例已針對Delta緩存自動執行了最佳配置。
配置磁盤使用率
要配置Delta緩存如何使用工作節點的本地存儲,請在集群創建期間指定以下Spark配置設置:
spark.databricks.io.cache.maxDiskUsage -每個節點為緩存的數據保留的磁盤空間(以字節為單位)
spark.databricks.io.cache.maxMetaDataCache -每個節點為緩存的元數據保留的磁盤空間(以字節為單位)
spark.databricks.io.cache.compression.enabled -緩存的數據是否應以壓縮格式存儲
INI
spark.databricks.io.cache.maxDiskUsage 50g
spark.databricks.io.cache.maxMetaDataCache 1g
spark.databricks.io.cache.compression.enabled false啟用Delta緩存
要啟用和禁用Delta緩存,請運行:
Scala
spark.conf.set("spark.databricks.io.cache.enabled", "[true | false]")