本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
前提條件
通過主賬號登錄阿里云 Databricks控制臺。
已創建集群,具體請參見創建集群。
已使用OSS管理控制臺創建非系統目錄存儲空間,詳情請參見創建存儲空間。
警告首次使用DDI產品創建的Bucket為系統目錄Bucket,不建議存放數據,您需要再創建一個Bucket來讀寫數據。
說明DDI支持免密訪問OSS路徑,結構為:oss://BucketName/Object
BucketName為您的存儲空間名稱;
Object為上傳到OSS上的文件的訪問路徑。
例:讀取在存儲空間名稱為databricks-demo-hangzhou文件路徑為demo/The_Sorrows_of_Young_Werther.txt的文件
// 從oss地址讀取文本文檔 val text = sc.textFile("oss://databricks-demo-hangzhou/demo/The_Sorrows_of_Young_Werther.txt")
如何使用Databricks Delta更新和查詢商品庫存信息
當執行UPSERT操作時,一般情況下,您需要執行兩個不同的任務 - UPdate操作和inSERT操作。為了優化性能,Databricks Delta能夠執行“upsert”或MERGE操作,從而簡化業務邏輯。
在這個notebook中,我們將會演示2個Use Case:
DML: MERGE/DELETE/UPDATE。
如何通過`OPTIMIZE`` and `ZORDER`對查詢性能進行優化。
步驟一:創建集群并通過knox賬號訪問Notebook
創建集群參考:創建集群,需注意要設置RAM子賬號及保存好knox密碼,登錄WebUI時候需要用到。
步驟二:創建Notebook、導入數據、進行數據分析
%pyspark
# 將csv文件轉化為parquet格式
# 注意文件讀取和保存的路徑請按照您的oss路徑進行配置
spark.read.option("header", "true") \
.csv("oss://databricks-demo/online_retail.csv") \
.select("StockCode","Description","Quantity","UnitPrice","Country") \
.write.format("parquet").mode("overwrite") \
.save("oss://databricks-demo/parquet_online_retail/inventory")
# 從parquet文件導入DataFrame并查看
df = spark.read.parquet("oss://databricks-demo/parquet_online_retail/inventory")
df.show()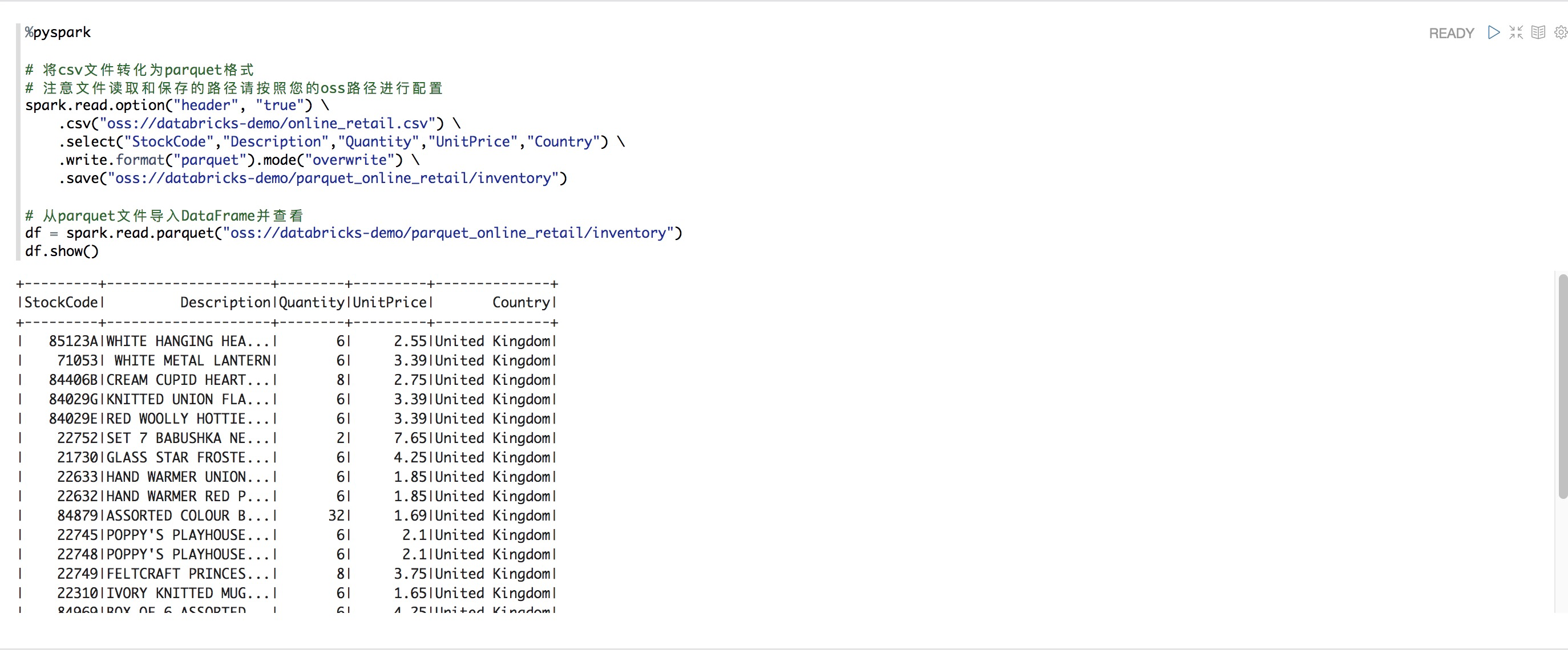
Case 1: DML MERGE/DELETE/UPDATE
%spark.sql
-- 創建庫 DB_Demo_Inventory_OSS
DROP DATABASE if EXISTS DB_Demo_Inventory_OSS CASCADE;
-- 建表
CREATE DATABASE IF NOT EXISTS DB_Demo_Inventory_OSS LOCATION 'oss://databricks-demo/parquet_online_retail/inventory_database';
USE DB_Demo_Inventory_OSS;
-- 從parquet數據建表current_inventory
CREATE TABLE IF NOT EXISTS current_inventory USING PARQUET LOCATION 'oss://databricks-demo/parquet_online_retail/inventory';
-- 查看是否建表成功,簡單SELECT語句驗證
SHOW TABLES;
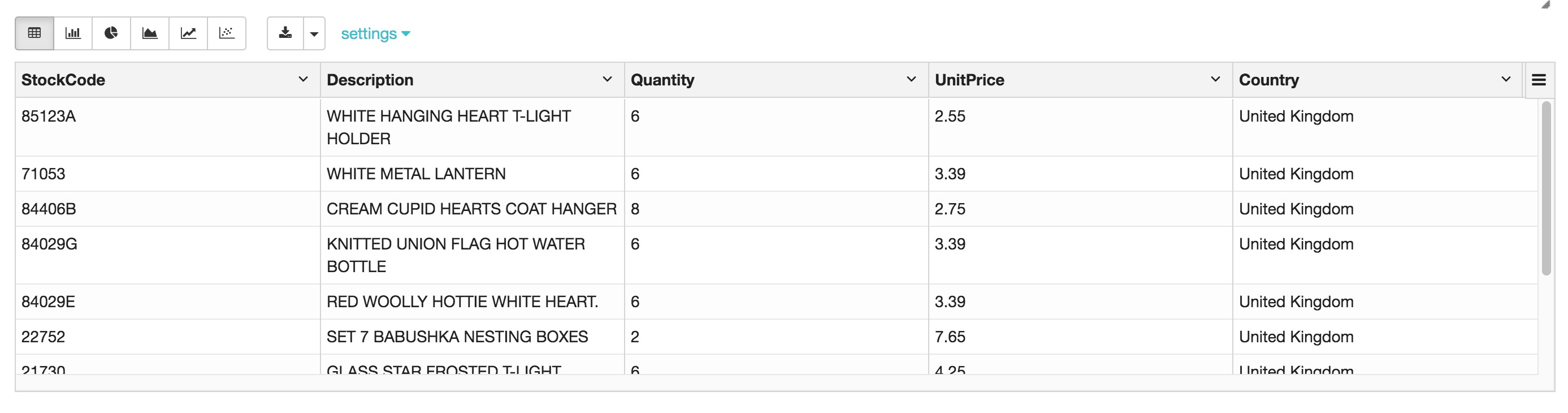
SELECT * FROM current_inventory LIMIT 10;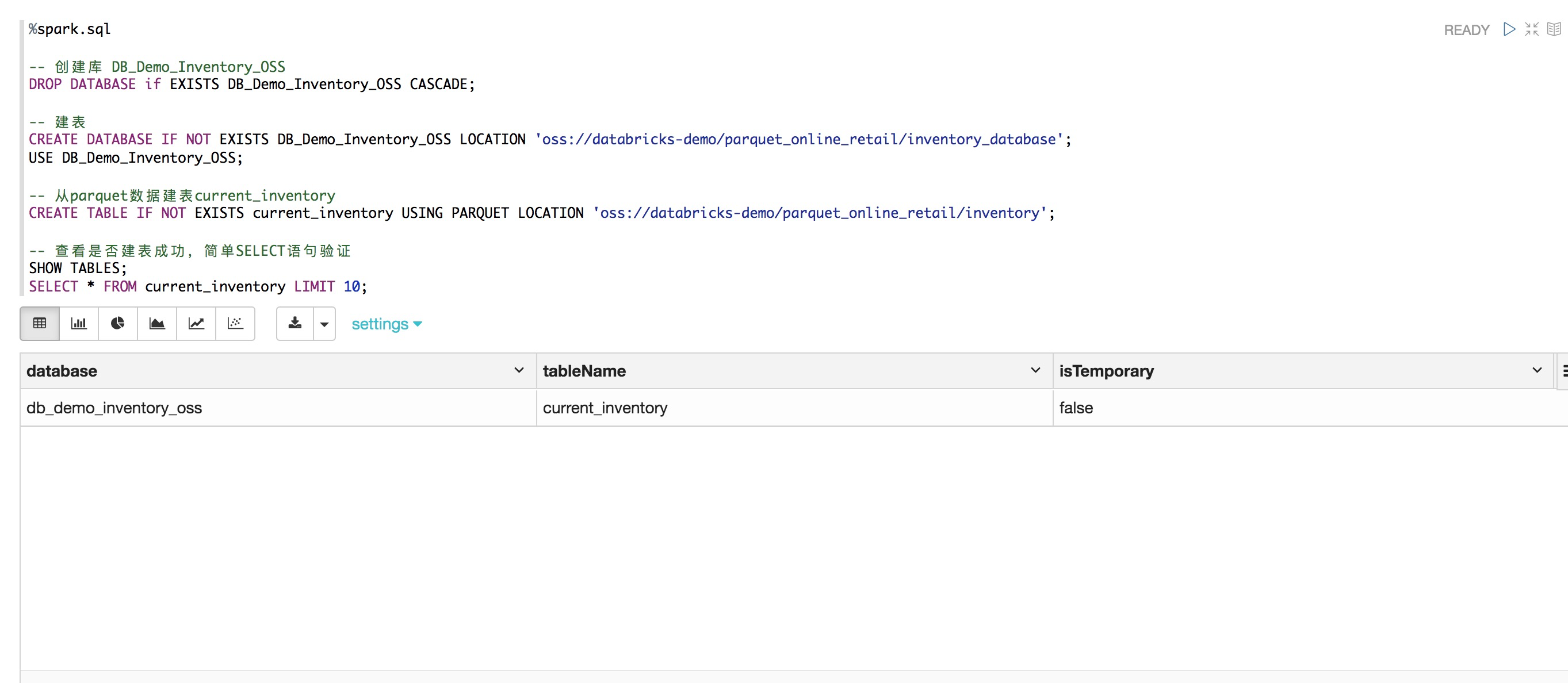
INSERT 或 UPDATE parquet文件的七個步驟
在使用Databricks Delta之前,我們先來看下,在通常情況下如何插入或更新表記錄。
確定需要插入的新記錄。
確定將會被替換的記錄 (例如,更新updated)。
確定不會被INSERT或UPDATE操作影響的記錄。
基于前面3步的結果,創建一張臨時表。
將原表刪除(包括所有相關的數據文件)。
對臨時表重命名。
刪除臨時表。

查看當前Parquet表的數據
%spark.sql
-- 查看某個StockCode下的數據
SELECT * FROM current_inventory WHERE StockCode IN ('21877', '21876')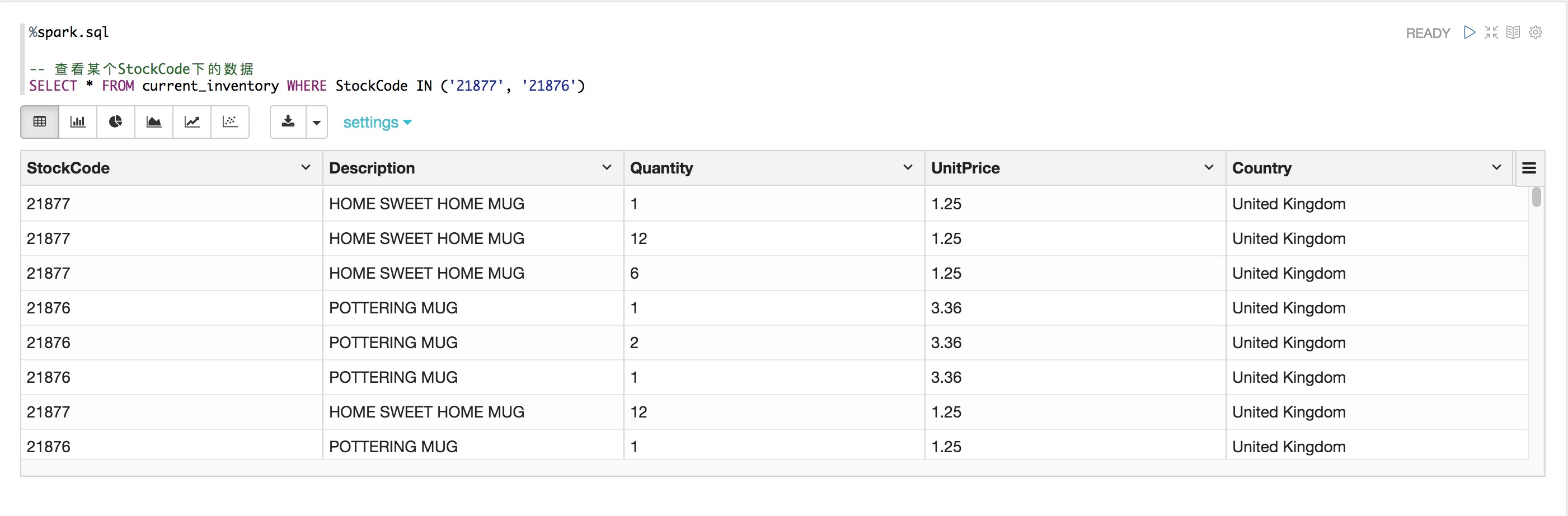
步驟1:向Parquet表中插入記錄
%pyspark
# 創建2條記錄,準備插入到表中并轉換為DataFrame
items = [('2187709', 'RICE COOKER', 30, 50.04, 'United Kingdom'), ('2187631', 'PORCELAIN BOWL - BLACK', 10, 8.33, 'United Kingdom')]
cols = ['StockCode', 'Description', 'Quantity', 'UnitPrice', 'Country']
insert_rows = spark.createDataFrame(items, cols)
insert_rows.show()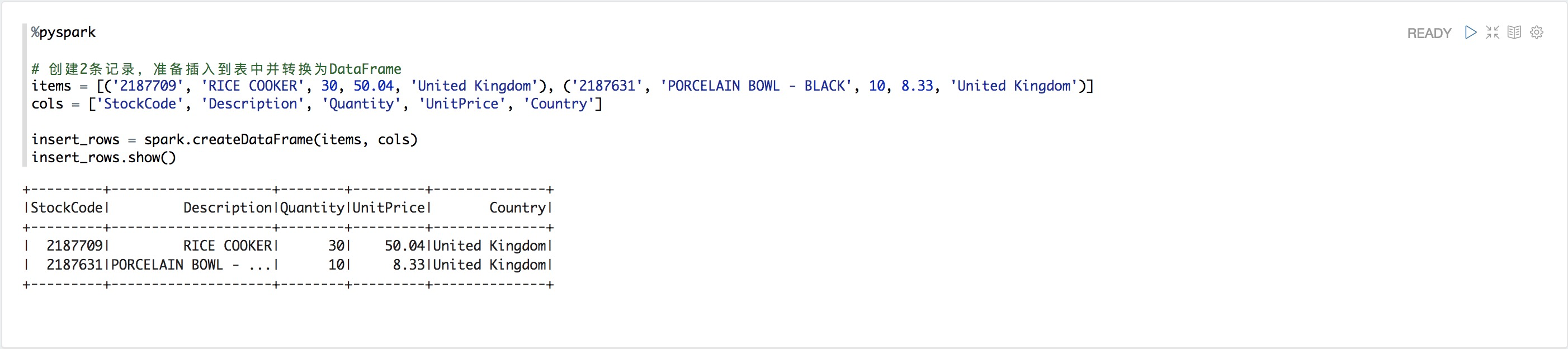
步驟2:更新Parquet表中的記錄
%pyspark
# 創建2條記錄,準備更新到表中并轉換為DataFrame
items = [('21877', 'HOME SWEET HOME MUG', 300, 26.04, 'United Kingdom'), ('21876', 'POTTERING MUG', 1000, 48.33, 'United Kingdom')]
cols = ['StockCode', 'Description', 'Quantity', 'UnitPrice', 'Country']
update_rows = spark.createDataFrame(items, cols)
update_rows.show()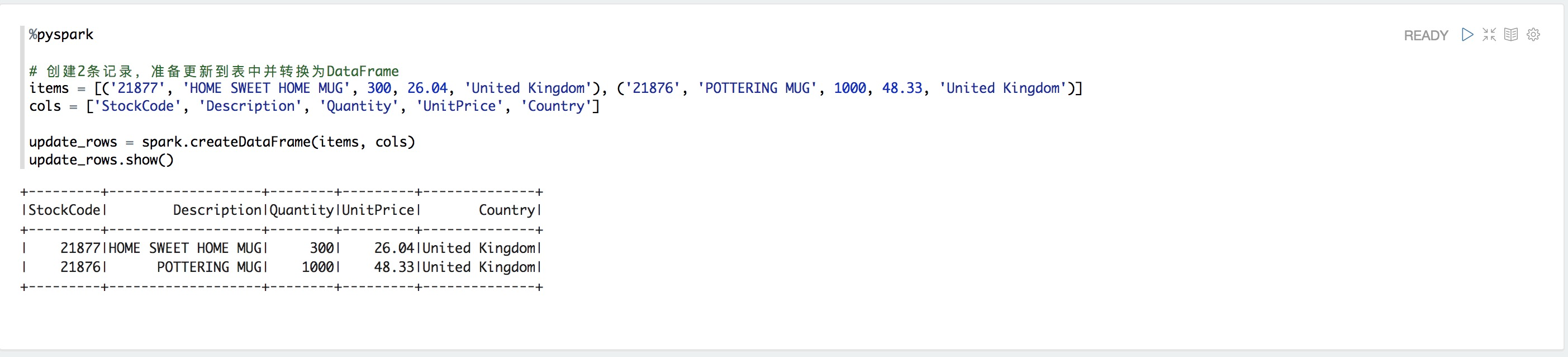
步驟3:找到Parquet表中沒有被變更過的記錄
%pyspark
# 展示不會被以上數據更新的數據
unchanged_rows = spark.sql("select * from current_inventory where StockCode !='21877' and StockCode != '21876'")
unchanged_rows.show()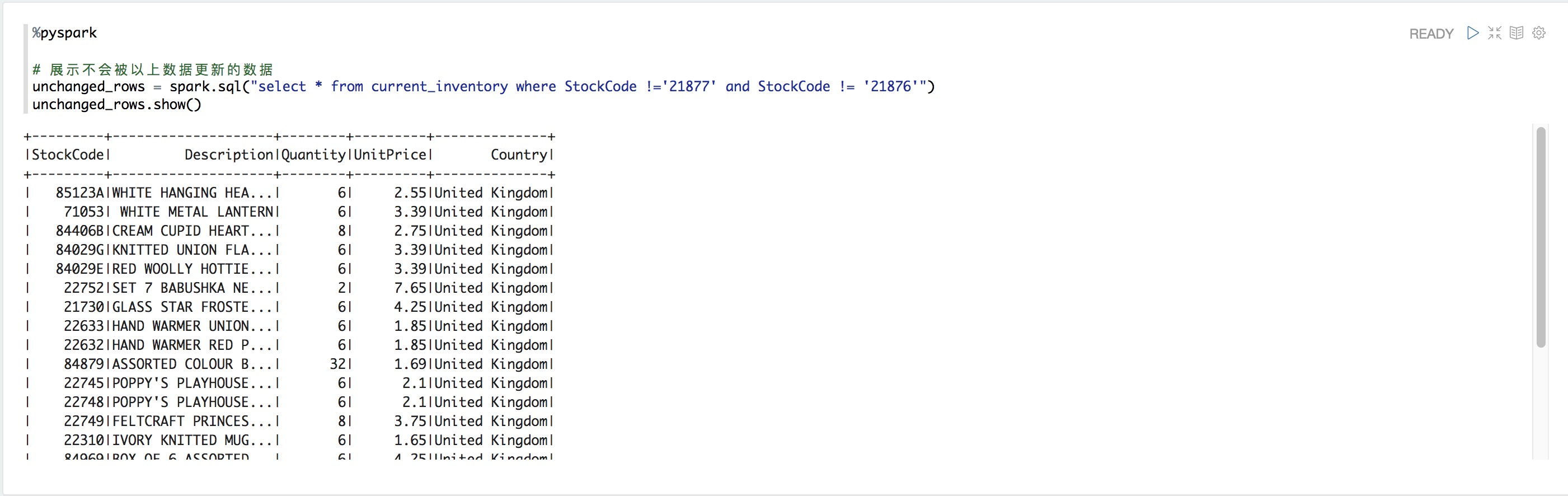
步驟4:創建臨時表
%pyspark
temp_current_inventory = insert_rows.union(update_rows).union(spark.sql("select * from current_inventory").filter("StockCode !='21877' and StockCode != '21876'"))
temp_current_inventory.show()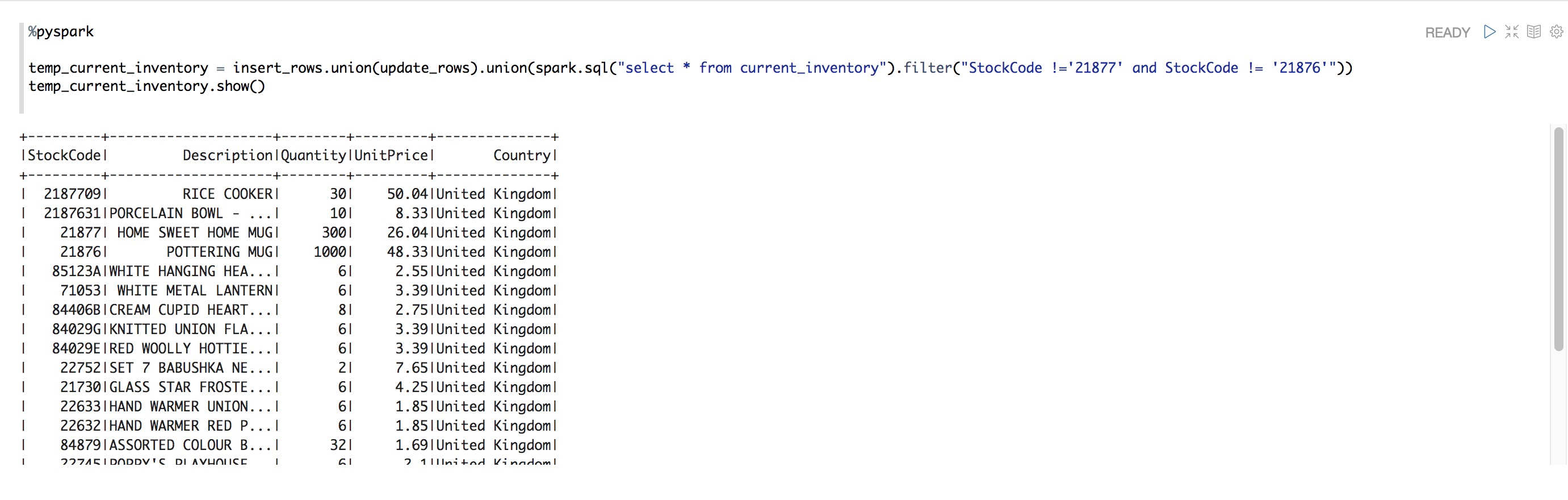
步驟5:刪除原始表
%spark.sql
USE DB_Demo_Inventory_OSS;
DROP TABLE current_inventory;步驟6:使用臨時表的數據,生產新原始表current_inventory
%pyspark
temp_current_inventory.write.format("parquet").mode("overwrite").saveAsTable("current_inventory")
spark.sql("select * from current_inventory").show()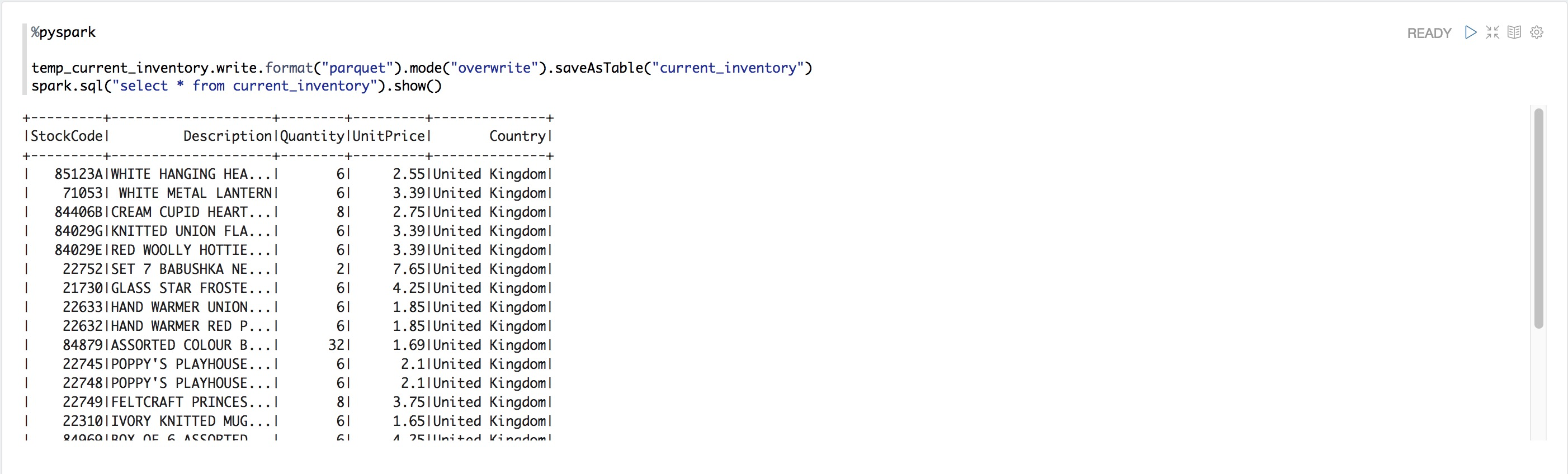
步驟7:刪除臨時表
%sql
drop table if exists temp_current_inventory;使用Databricks Delta更新表數據僅需2步:
確定需要插入或更新的記錄。
使用MERGE。
創建一個delta表
%sql
DROP TABLE IF EXISTS current_inventory_delta;
CREATE TABLE current_inventory_delta
USING delta
AS SELECT * FROM current_inventory;
SHOW TABLES;
SELECT * FROM current_inventory_delta;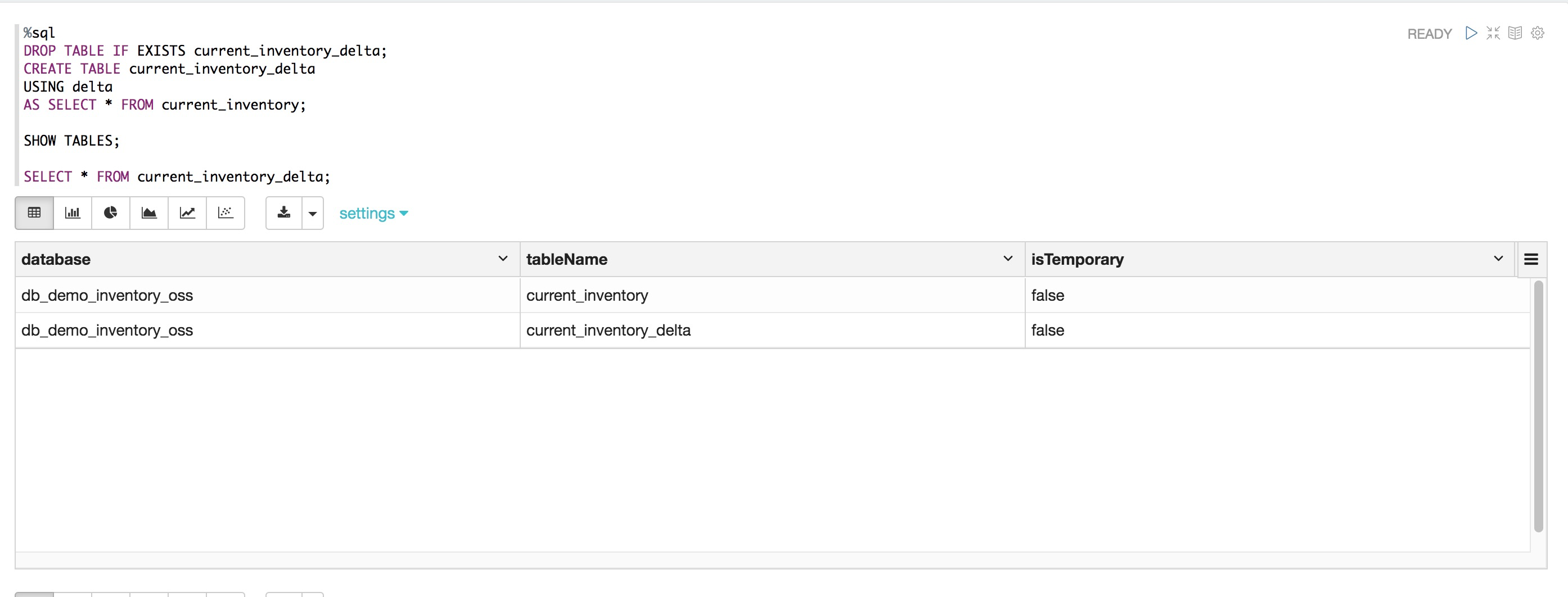
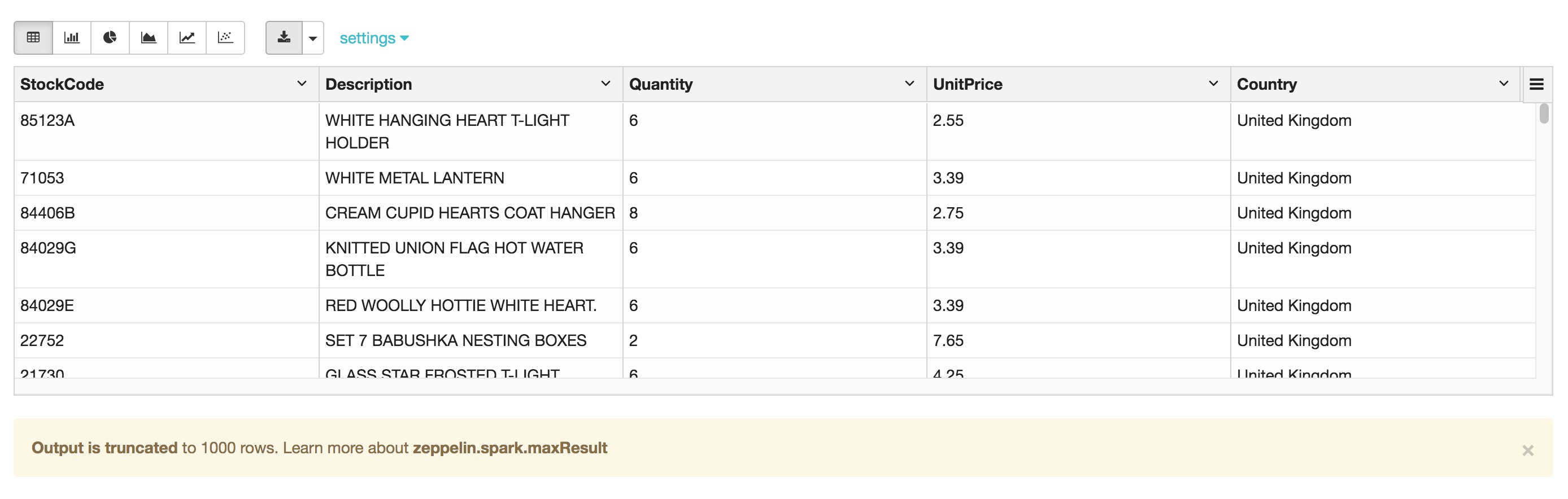
步驟1:將目標數據更新至delta表
%pyspark
spark.read.option("header","True").csv("oss://databricks-demo/online_retail_mergetable.csv").createOrReplaceTempView("merge_table")%sql
SELECT * FROM merge_table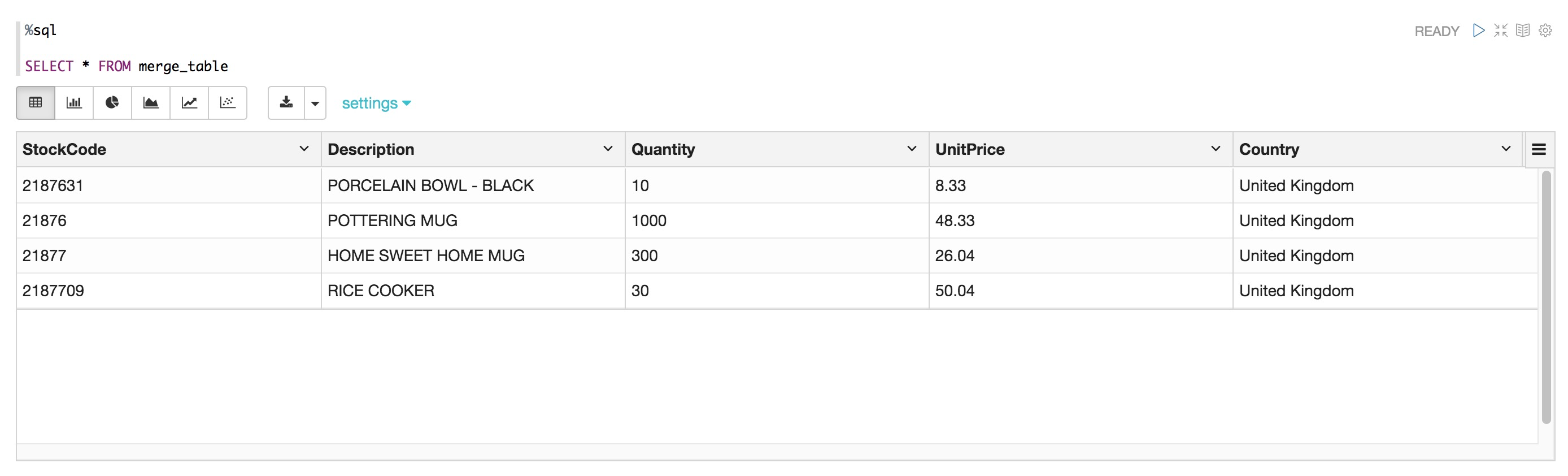
步驟2:使用MERGE插入或更新delta表
%sql
MERGE INTO current_inventory_delta as d
USING merge_table as m
on d.StockCode = m.StockCode and d.Country = m.Country
WHEN MATCHED THEN
UPDATE SET *
WHEN NOT MATCHED
THEN INSERT *MERGE語句執行成功!
我們可以看到所有數據均被更新,新增數據也插入成功。
%sql
select * from current_inventory_delta where StockCode in ('2187709', '2187631', '21877', '21876') and Country = 'United Kingdom'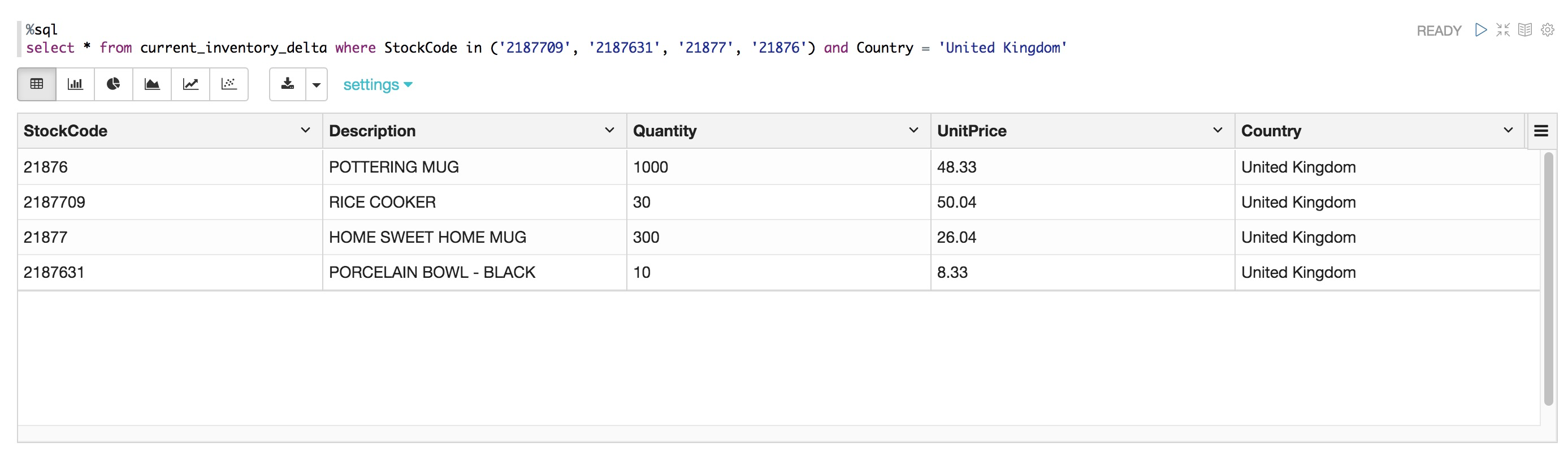
DELETE
同樣,我們可以輕松刪除Delta表中的記錄。
創建redItem
%pyspark
redItem = Row({'StockCode':'33REDff', 'Description':'ADDITIONAL RED ITEM', 'Quantity': '8', 'UnitPrice': '3.53', 'Country':'United Kingdom'})
redItemDF = spark.createDataFrame(redItem)
redItemDF.printSchema()分別創建PARQUET表和DELTA表
%pyspark
redItemDF.write.format("delta").mode("append").saveAsTable("current_inventory_delta")
redItemDF.write.format("parquet").mode("append").saveAsTable("current_inventory_pq")
spark.sql("""select * from current_inventory_delta where StockCode = '33REDff'""").show()
刪除PARQUET表中的記錄將會報錯 – 與DELTA的不同之處
%sql
delete from current_inventory_pq where StockCode = '33REDff';
刪除DELTA表中的記錄 – 成功
%sql
delete from current_inventory_delta where StockCode = '33REDff';
select * from current_inventory_delta where StockCode = '33REDff';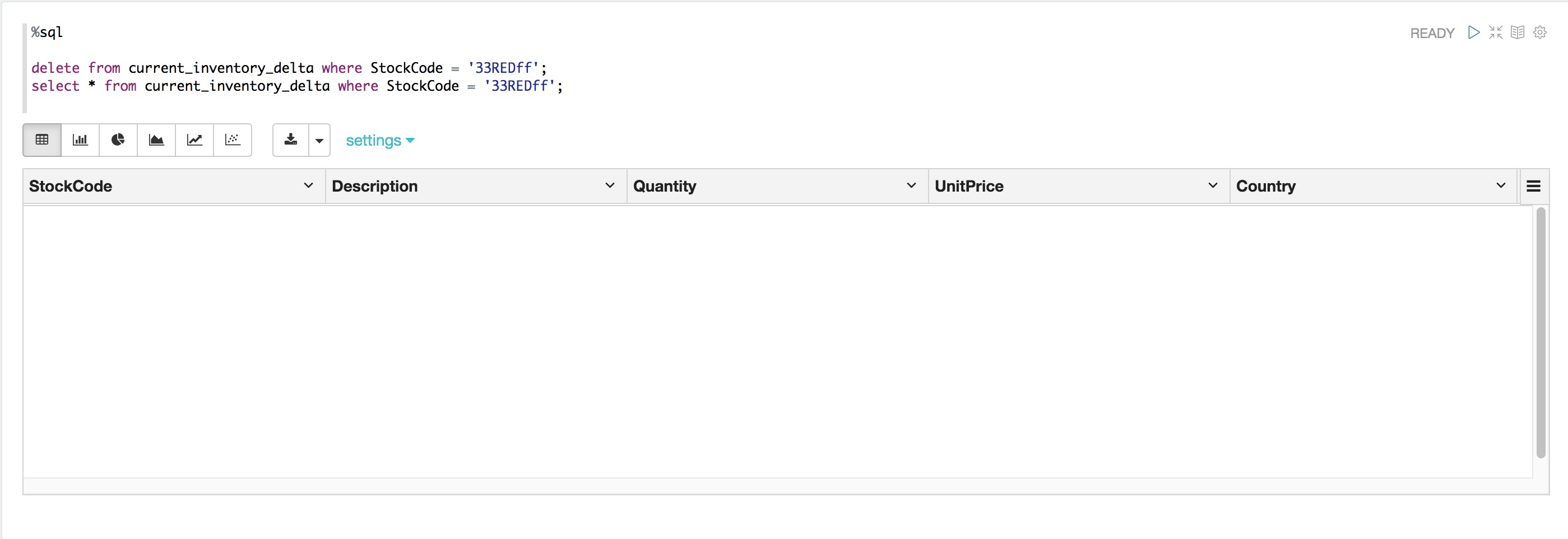
Case 2:OPTIMIZE 和 ZORDER
通過OPTIMIZE和ZORDERZORDER對數據文件進行優化,以提高查詢性能。
查詢DELTA表
%sql
select * from current_inventory_delta where Country = 'United Kingdom' and StockCode like '21%' and UnitPrice > 10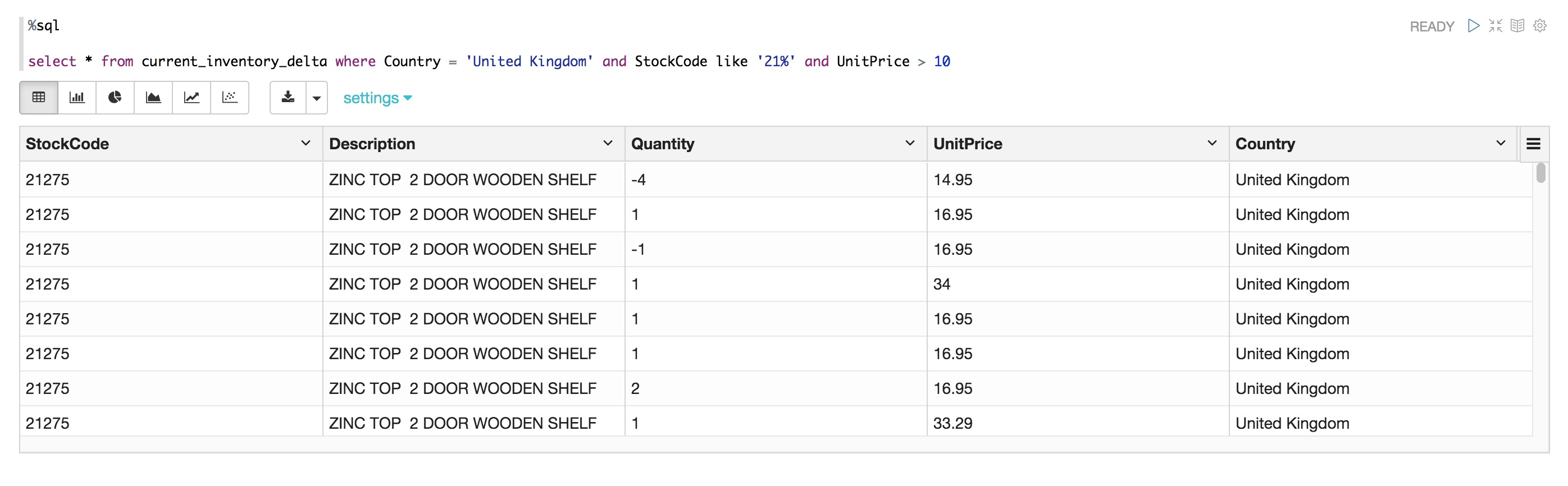
%sql
OPTIMIZE current_inventory_delta
ZORDER by Country, StockCode;
select * from current_inventory_delta
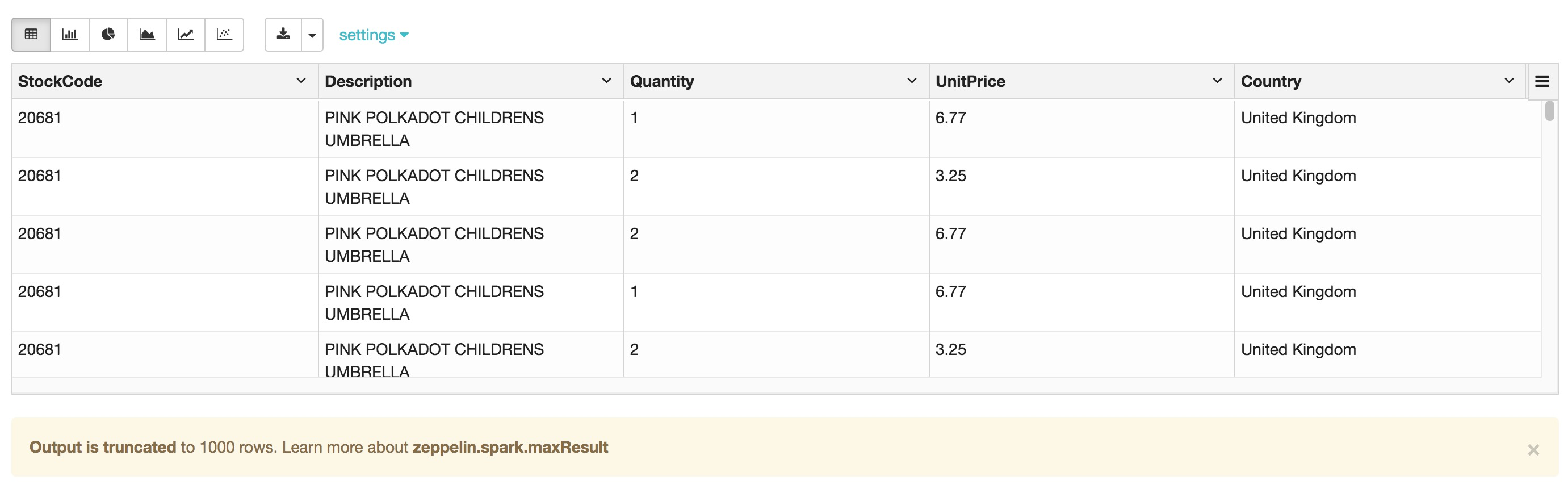
執行相同的查詢 – 查詢時間更短
實際執行時間與集群ECS規格的選擇有關,與標準PARQUET表相比,通常會有5-10X性能提升,最快會有50X性能提升。
%sql
select * from current_inventory_delta where Country = 'United Kingdom' and StockCode like '21%' and UnitPrice > 10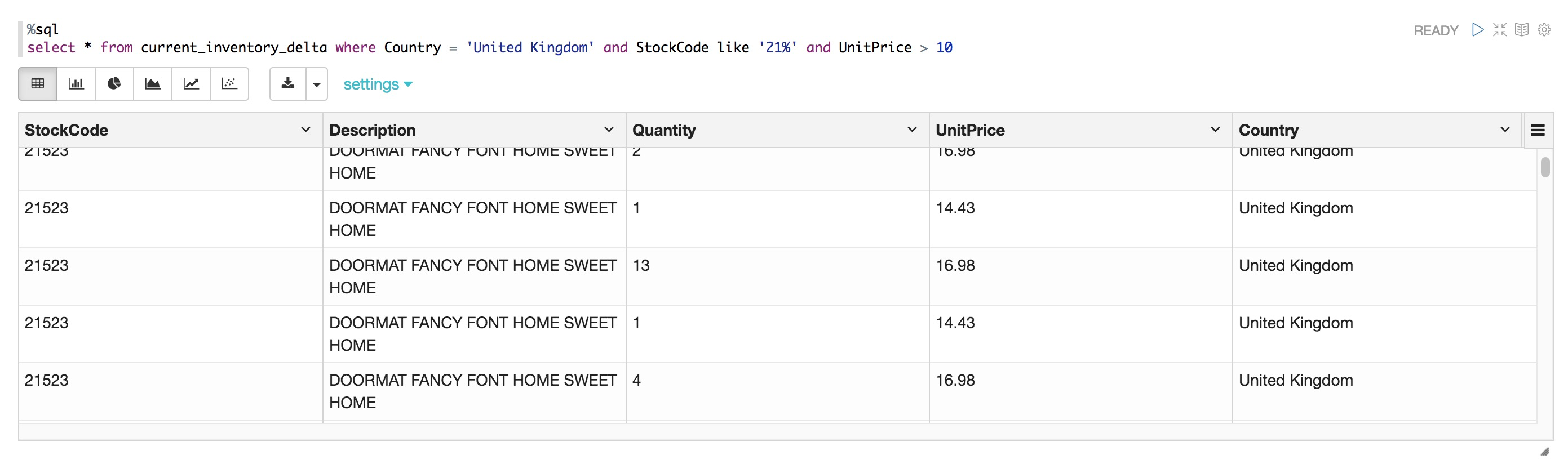
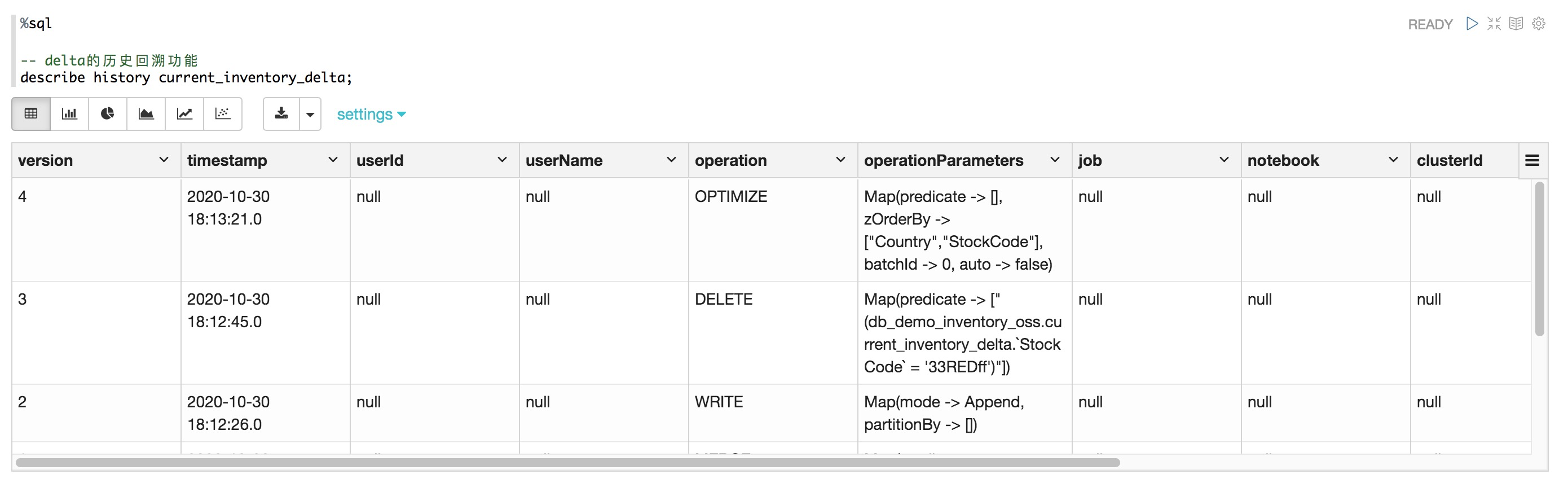
%sql
-- delta的歷史回溯功能
describe history current_inventory_delta;