Model Gallery預置了多種LLM預訓練模型。本文為您介紹如何在Model Gallery中,通過模型評測功能全方位評估模型能力查找適合您業務需求的大語言模型。
簡介
模型評測功能支持從兩個維度對大語言模型進行評測:基于自定義數據集和公開數據集評測。
基于自定義數據集的評測包括:
基于規則的評測,用ROUGE和BLEU系列指標計算模型預測結果和真實結果之間的差距;
基于裁判員模型的評測,基于PAI提供的裁判員模型,對問答對【問題-模型輸出】逐條打分,并統計得分情況,用于評價模型性能;
基于公開數據集的評測是通過在多種公開數據集上加載并執行模型預測,根據每個數據集特定的評價框架,為您提供行業標準的評估參考。
當前模型評測支持HuggingFace所有AutoModelForCausalLM類型的模型。
最新特性:
現已支持裁判員模型打分,使用基于Qwen2定制的大模型作為裁判員,對被評估模型的生成結果進行打分,適用于開放性、復雜問答場景。限時免費中,歡迎在模型評測-專家模式中試用。[2024.09.01]
使用場景
模型評測是模型開發中重要的環節,您可以結合實際業務挖掘模型評測應用。例如在以下場景中使用模型評測功能:
模型基準測試,基于公開數據集對模型通用能力進行評估,并與業界模型或基準進行對比;
領域能力評估,將模型應用到特定領域,比較不同領域內預訓練和微調后的模型效果,以評估模型應用領域知識的能力;
模型回歸測試,您可以構建回歸測試集,通過模型評測功能來評估模型在實際業務場景下的表現,是否滿足上線標準。
前提條件
如果您需要對模型進行評測,則需要創建OSS Bucket存儲空間。具體操作請參見控制臺快速入門。
計費說明
使用模型評測時需要收取OSS存儲費用和DLC的評測任務費用,計費詳情參見OSS計費概述和分布式訓練(DLC)計費說明。
數據準備
模型評測功能支持基于自定義數據集和公開數據集(例如C-Eval)完成評測。
公開數據集:已經由PAI上傳并維護,可以直接使用。
目前PAI維護了MMLU、TriviaQA、HellaSwag、GSM8K、C-Eval、TruthfulQA,其他公開數據集陸續接入中。
自定義數據集:如果需要基于自定義評測文件,需要提供JSONL格式的評測文件,可自行上傳至OSS,并創建自定義數據集,詳情參見上傳OSS文件和創建及管理數據集。文件格式如下:
使用
question標識問題列,answer標識答案列,也可以在評測頁面選擇指定列。如果僅需要自定義數據集-裁判員模型評測,則answer列選填。[{"question": "中國發明了造紙術,是否正確?", "answer": "正確"}] [{"question": "中國發明了火藥,是否正確?", "answer": "正確"}]文件示例:eval.jsonl
操作流程
選定模型
查找模型的具體操作步驟如下:
進入Model Gallery頁面。
登錄PAI控制臺。
在左側導航欄單擊工作空間列表,在工作空間列表頁面中單擊待操作的工作空間名稱,進入對應工作空間內。
在左側導航欄選擇快速開始 > Model Gallery,進入Model Gallery頁面。
查找適合業務的模型。
在模型列表中,根據模型描述信息進行查看,對于可評測的模型,會展示評測按鈕。
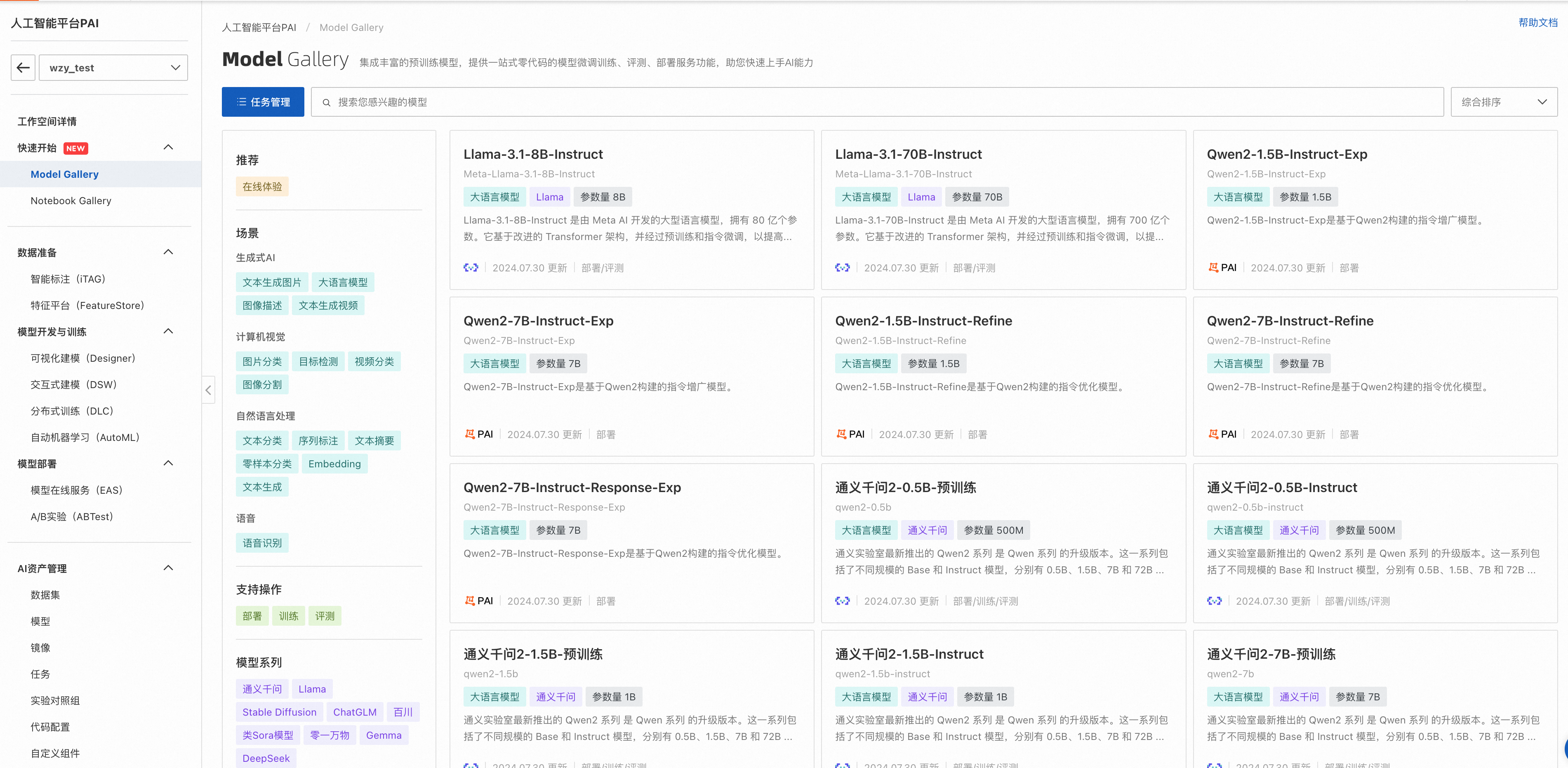
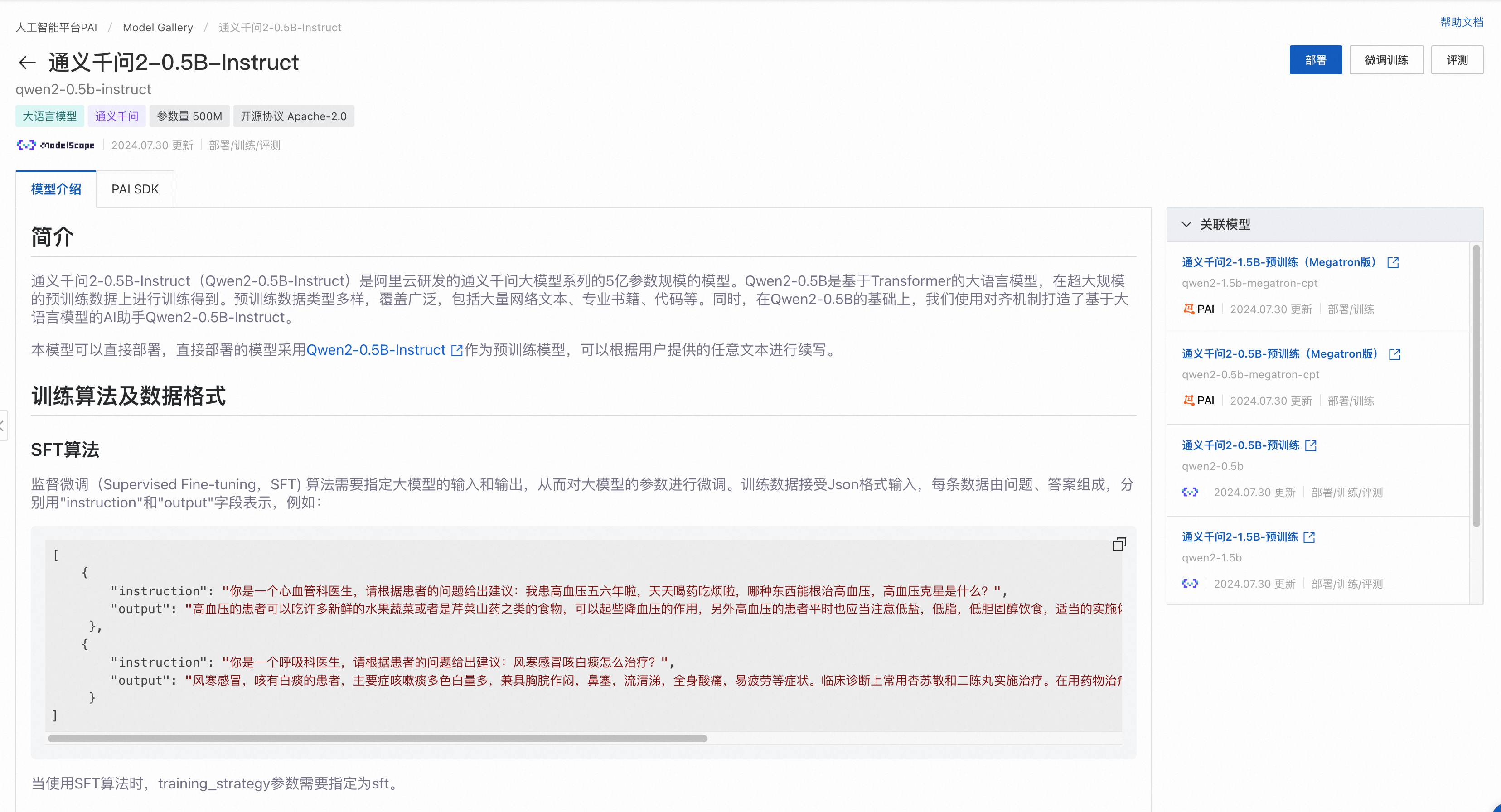
點擊左上角任務管理,打開訓練任務列表頁,點擊進入LLM訓練任務詳情頁,對于支持評測的模型,基于其二次訓練的模型也支持評測:

評測模型
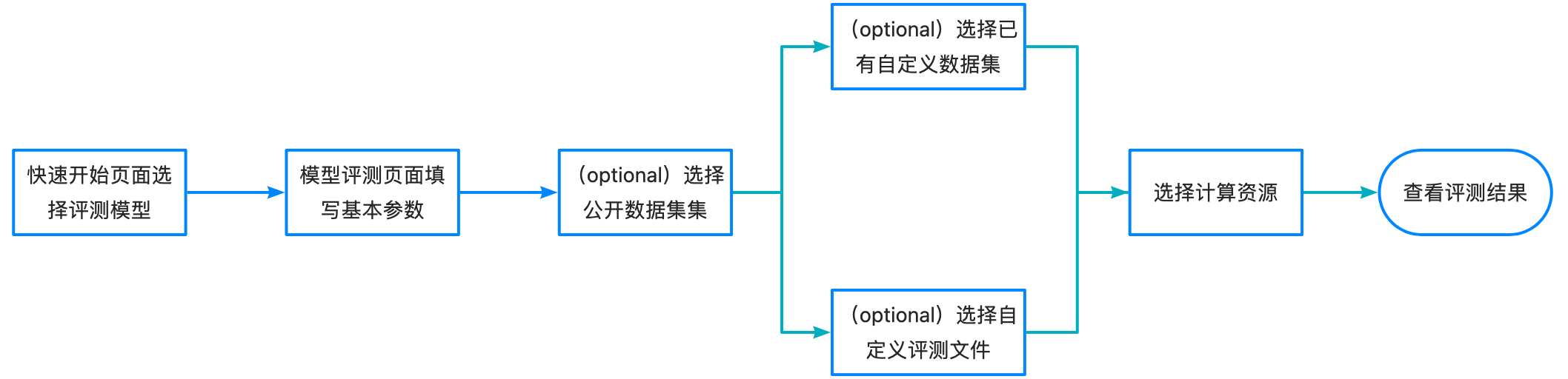
模型評測具有兩種模式,極簡模式和專家模式。
極簡模式
可直接選擇公開評測集或者已創建好的自定義數據集,快速使用模型評測功能(如需裁判員評測,請切換到專家模式)。
![]()
模型評測頁面填寫評測任務名。
填寫評測結果存儲路徑。選擇評測結果輸出路徑時,請保證路徑僅被該評測任務使用,否則會導致不同評測任務間結果的互相覆蓋。

選擇評測數據集。數據集可選擇自定義數據集和PAI提供的公開數據集,其中自定義數據集需要滿足數據準備章節中的格式要求。
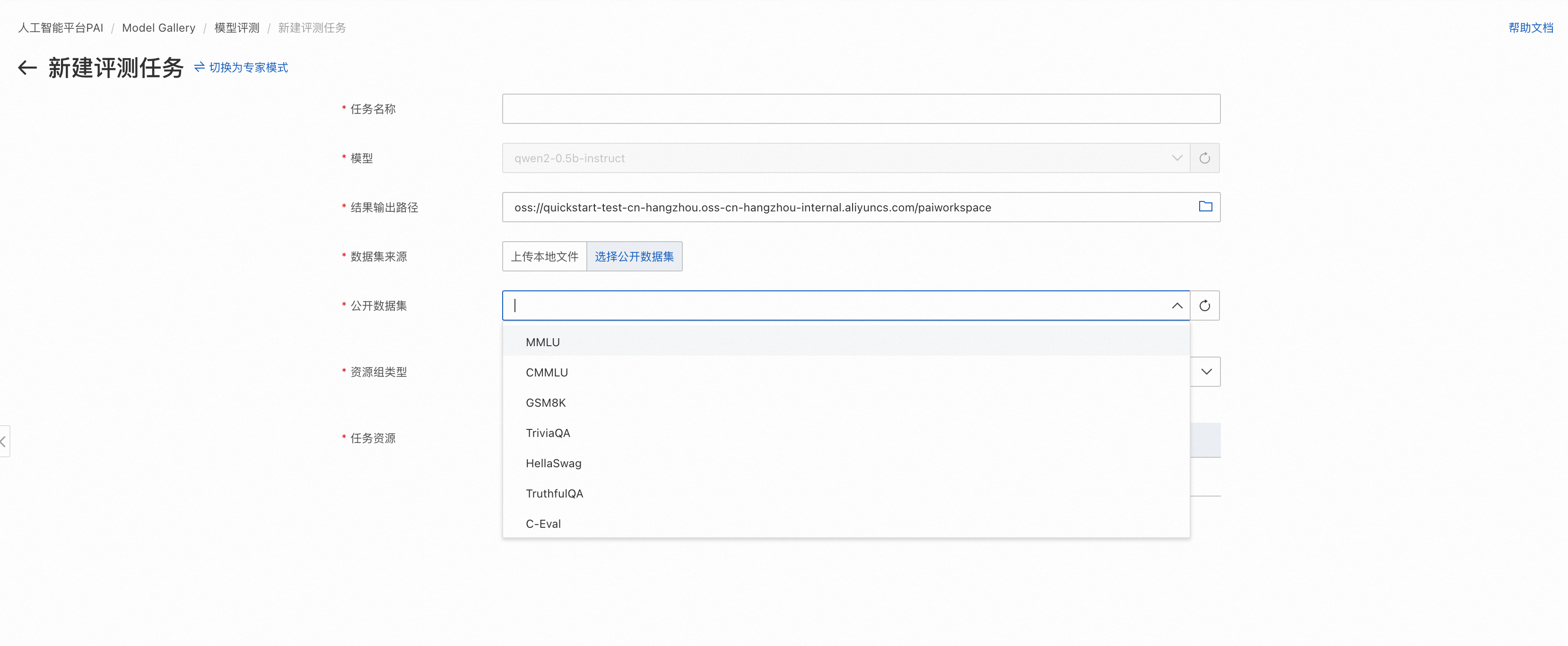
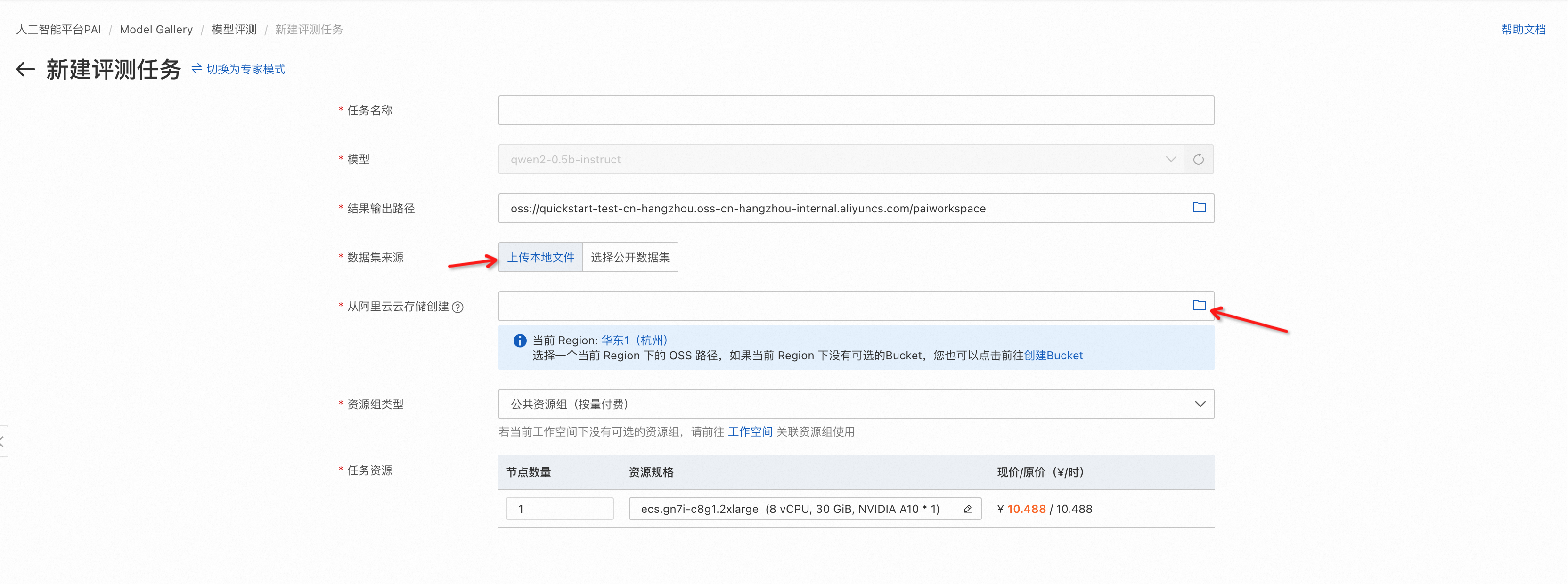
選擇計算資源,需要GPU類型計算資源(推薦選擇A10或者V100),在左下角提交評測任務,提交成功后自動跳轉到評測任務詳情頁,等待任務成功,查看評測報告。
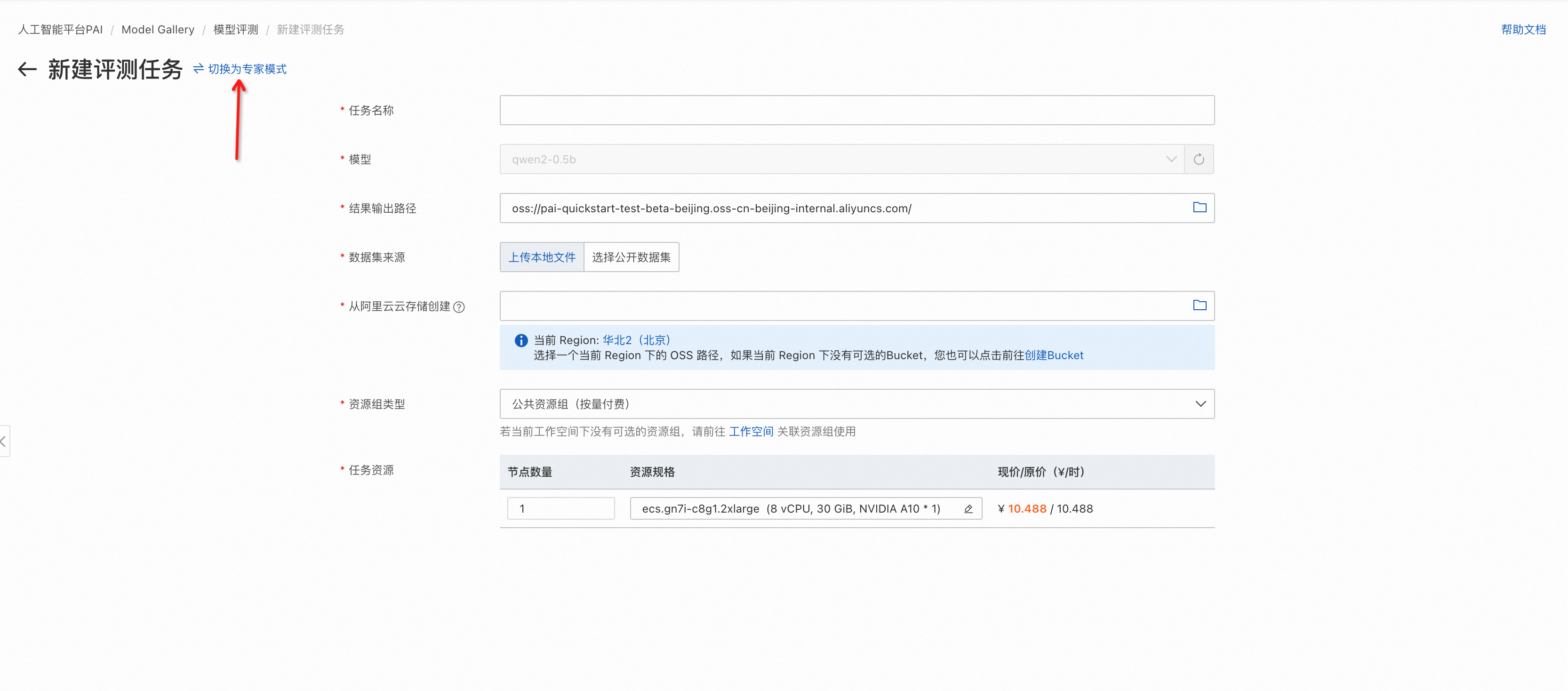
專家模式
支持同時選擇公開數據集和自定義數據集完成評測,支持設置超參數,支持裁判員模型評測,支持選擇多個公開數據集。
左上角選項切換到專家模式
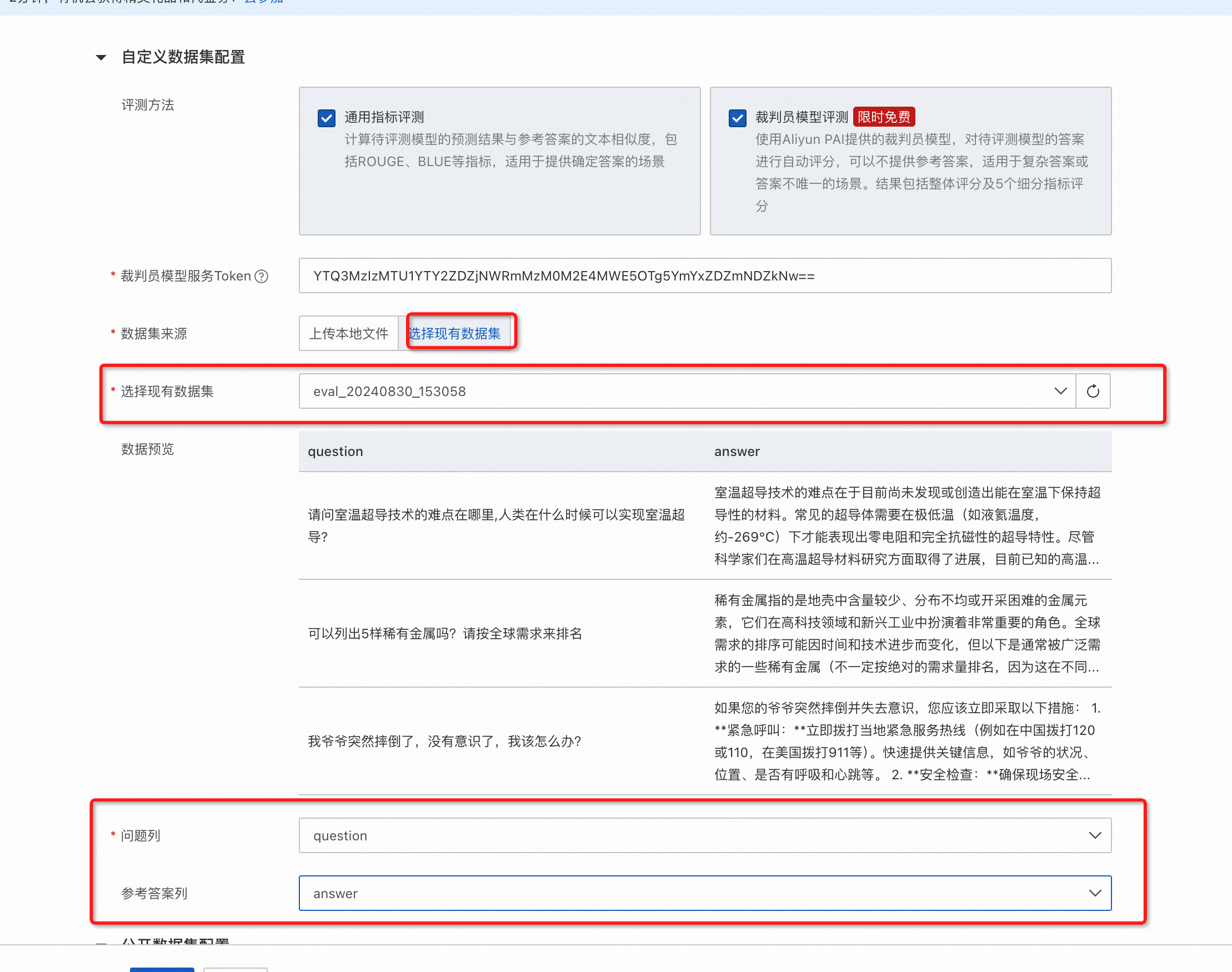
專家模式支持同時選擇公開數據集和自定義數據集,其中:
公開數據集可以選擇多個。
自定義數據集支持裁判員模型評測和通用指標評測。
自定義數據集支持指定問題和參考答案列,其中如果僅需要裁判員模型評測,則參考答案列可空。
支持直接使用OSS中符合格式要求的數據文件。
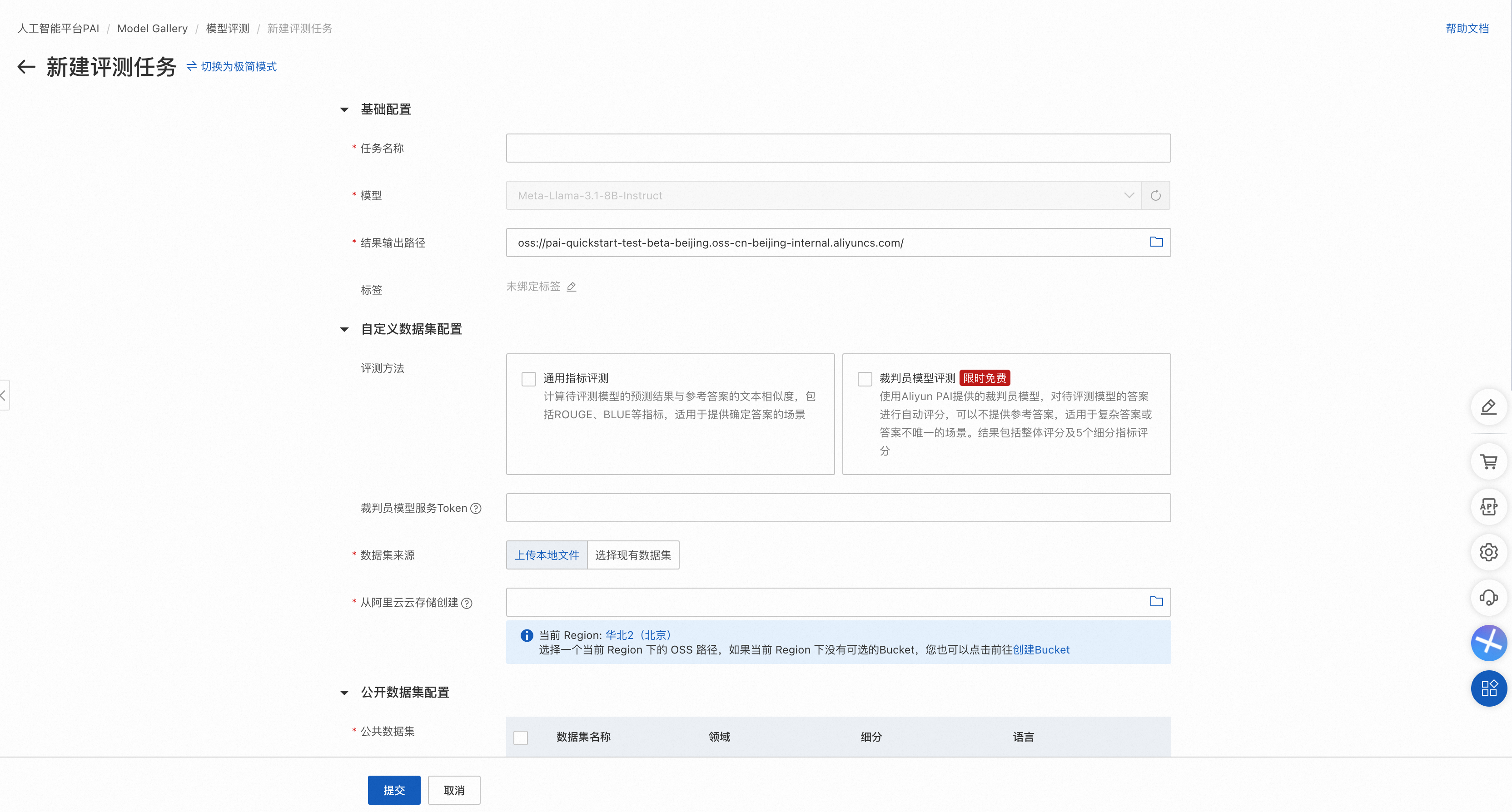
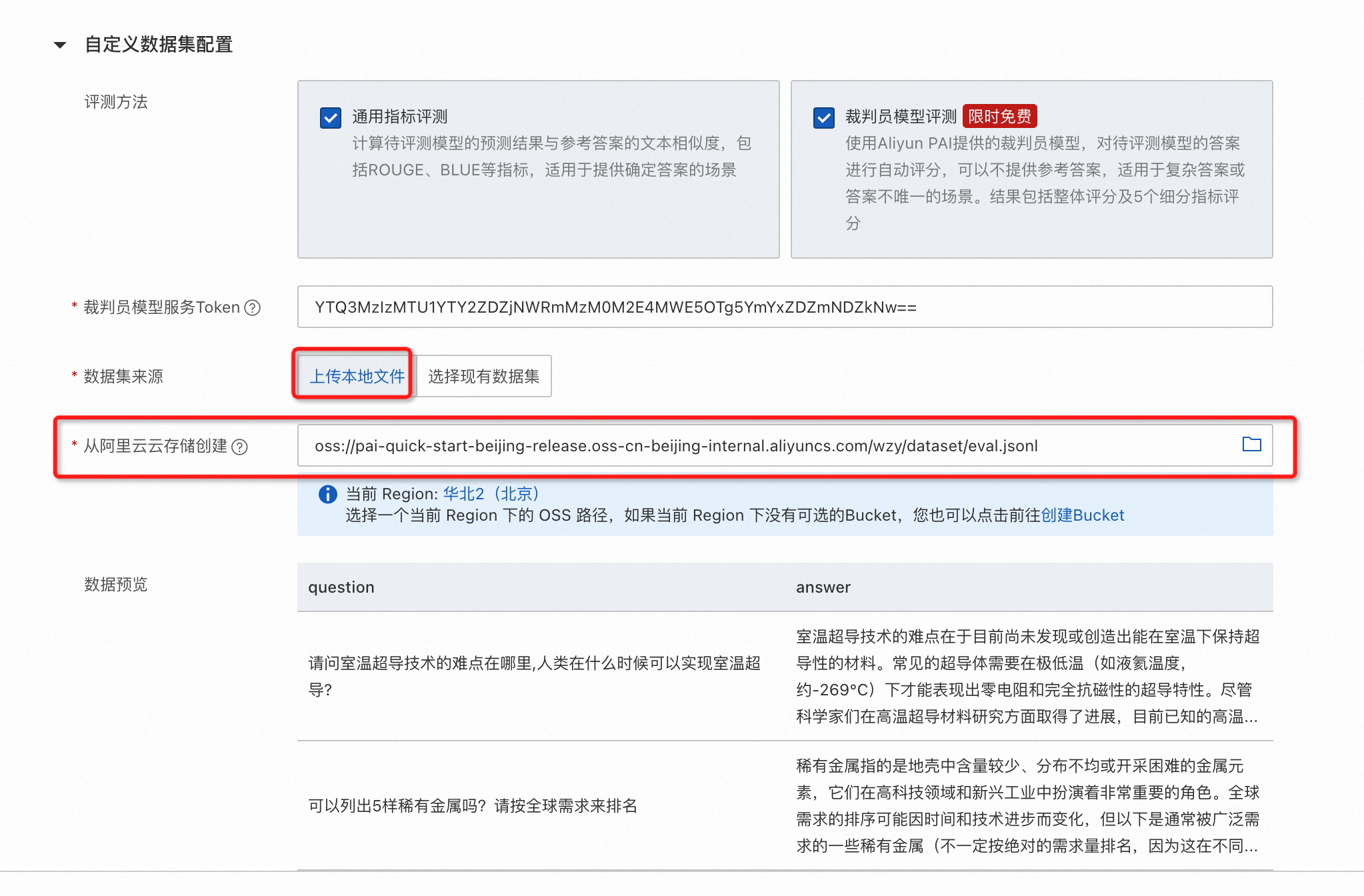
配置被評測模型推理超參數。

左下角點擊提交任務,提交成功后自動跳轉到評測任務詳情頁,等待任務成功,點擊評測報告,即可查看評測報告。
查看評測結果
評測任務列表
在Model Gallery頁面,單擊搜索框左側的任務管理。
在任務管理頁面,選擇模型評測標簽頁。

單任務結果
在模型評測列表頁,點擊評測任務的查看報告選項,即可進入評測任務詳情頁,在詳情頁評測報告一欄會展示模型在自定義數據集和公開數據集上的評測得分。
自定義數據集評測結果頁面
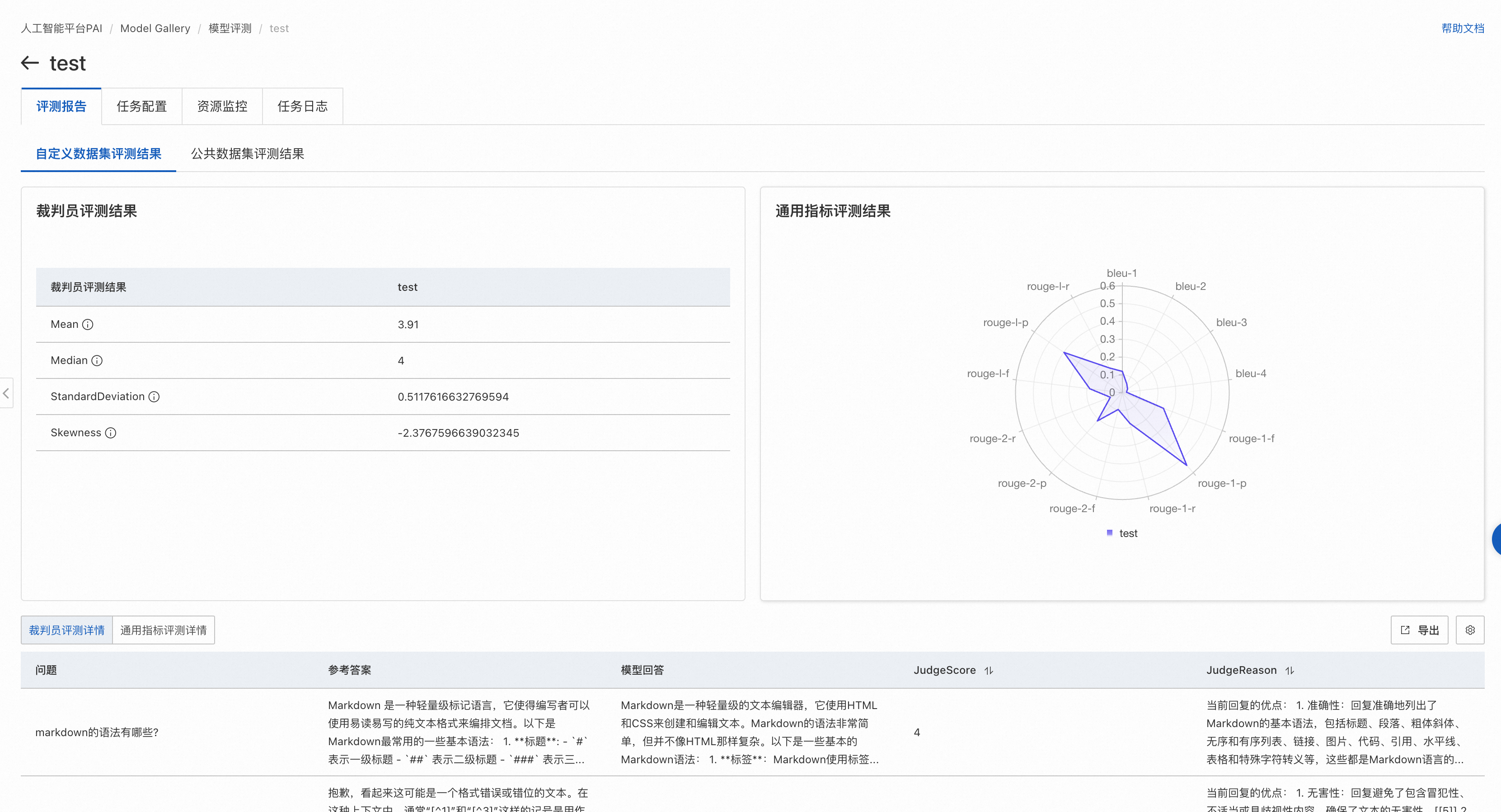
如果評測任務選中了通用指標評測,則通過雷達圖展示了該模型在ROUGE和BLEU系列指標上的得分。自定義數據集的默認評測指標包括:rouge-1-f,rouge-1-p,rouge-1-r,rouge-2-f,rouge-2-p,rouge-2-r,rouge-l-f,rouge-l-p,rouge-l-r,bleu-1,bleu-2,bleu-3,bleu-4。
rouge指標:
rouge-n類指標計算N-gram(連續的N個詞)的重疊度,其中rouge-1和rouge-2是最常用的,分別對應unigram和bigram:
rouge-1-p (Precision):系統摘要中的unigrams與參考摘要中的unigrams匹配的比例。
rouge-1-r (Recall):參考摘要中的unigrams在系統摘要中出現的比例。
rouge-1-f (F-score):精確率和召回率的調和平均數。
rouge-2-p (Precision):系統摘要中的bigrams與參考摘要中的bigrams匹配的比例。
rouge-2-r (Recall):參考摘要中的bigrams在系統摘要中出現的比例。
rouge-2-f (F-score):精確率和召回率的調和平均數。
rouge-l 指標基于最長公共子序列(LCS):
rouge-l-p (Precision):基于LCS的系統摘要與參考摘要的匹配程度的精確率。
rouge-l-r (Recall):基于LCS的系統摘要與參考摘要的匹配程度的召回率。
rouge-l-f (F-score):基于LCS的系統摘要與參考摘要的匹配程度的F-score。
bleu指標:
bleu (Bilingual Evaluation Understudy) 是另一種流行的評估機器翻譯質量的指標,它通過測量機器翻譯輸出與一組參考翻譯之間的N-gram重疊度來評分。
bleu-1:考察unigram的匹配。
bleu-2:考察bigram的匹配。
bleu-3:考察trigram(連續三個詞)的匹配。
bleu-4:考察4-gram的匹配。
如果評測任務選中了裁判員模型評測,則通過列表展示裁判員模型評分的統計指標。
裁判員模型是PAI基于Qwen2模型微調后得到,在開源的Alighbench等數據集上表現與GPT-4持平,部分場景優于GPT-4的評測效果。
頁面展示了裁判員模型對被評測模型的打分的四個統計指標:
Mean,表示裁判員大模型對模型生成結果打分的平均值(不含無效打分),最低值1,最大值5,越大表示模型回答越好。
Median,表示裁判員大模型對模型生成結果打分的中位數(不含無效打分),最低值1,最大值5,越大表示模型回答越好。
StandardDeviation,表示裁判員大模型對模型生成結果打分的標準差(不含無效打分),在均值和中位數相同情況下,標準差越小,模型越好。
Skewness,表示裁判員大模型打分結果的分布偏度(不含無效打分),正偏度表示分布右側(高分段)有較長尾部;負偏度則表示左側(低分段)有較長尾部。
此外還會在頁面底部展示評測文件每條數據的評測詳情。
公開數據集評測結果頁面
如果評測任務選擇了公開數據集,則在雷達圖展示該模型在公開數據集上的得分。
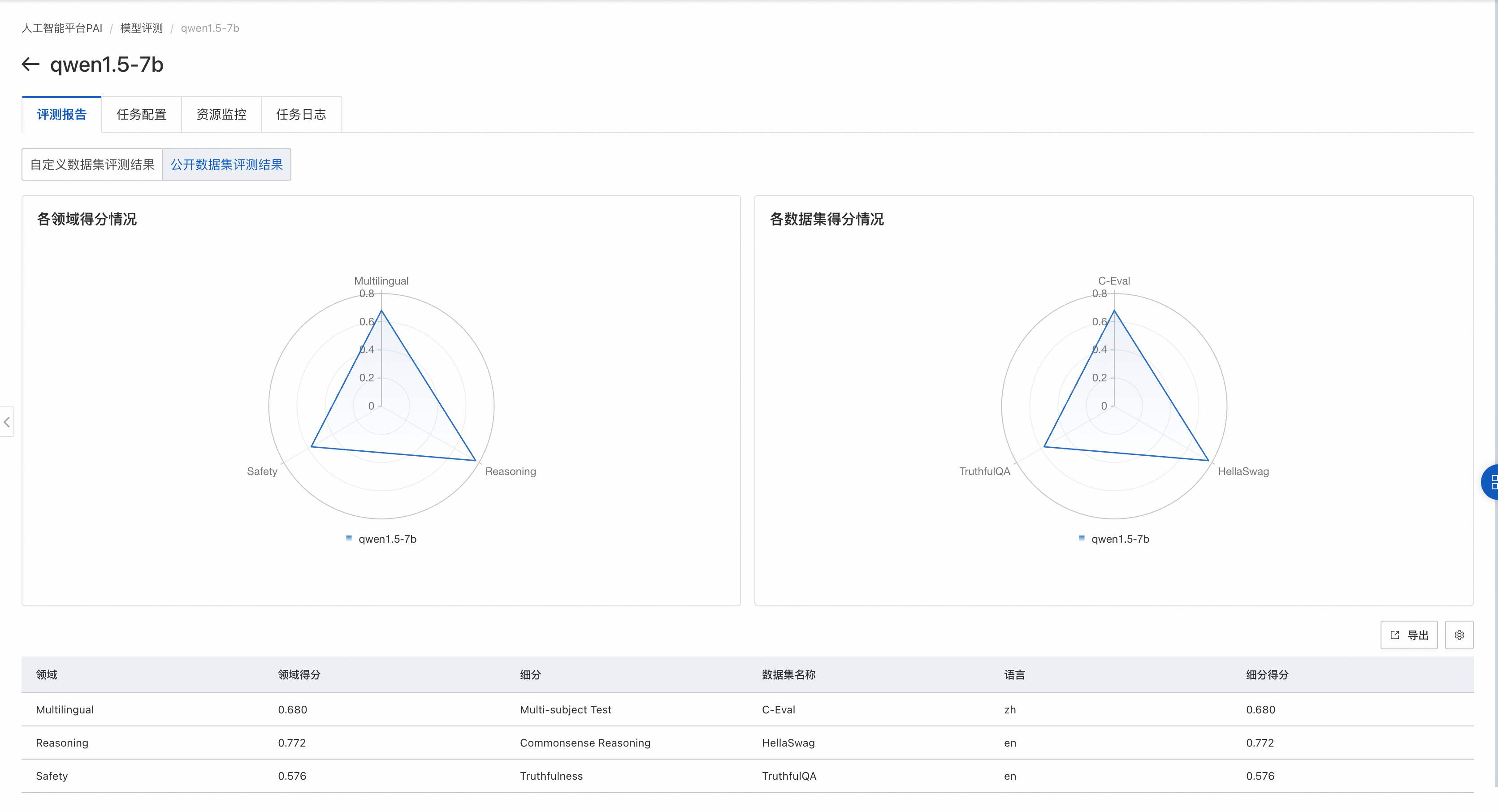
左側圖片展示了模型在不同領域的得分情況。每個領域可能會有多個與之相關的數據集,對屬于同一領域的數據集,我們會把模型在這些數據集上的評測得分取均值,作為領域得分。
右側圖片展示模型在各個公開數據集的得分情況。每個公開數據集的評測范圍見數據集官方介紹。
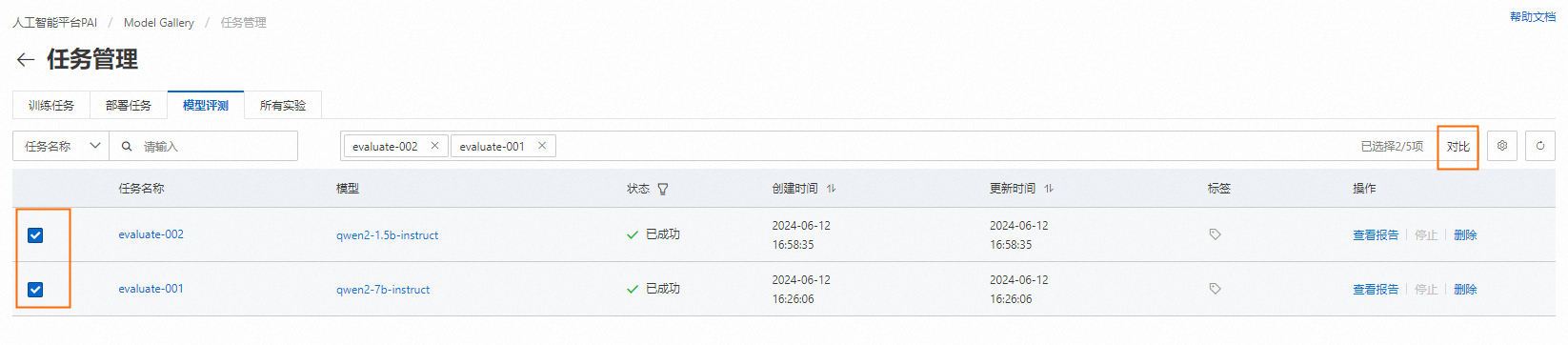
多評測任務對比
當需要對比多個模型的評測結果時,可以將它們在聚合在一個頁面上展示,以便于比較效果。具體操作為在評測任務列表頁左側選擇想要對比的模型評測任務,右上角點擊對比,進入對比頁面:
自定義數據集對比結果
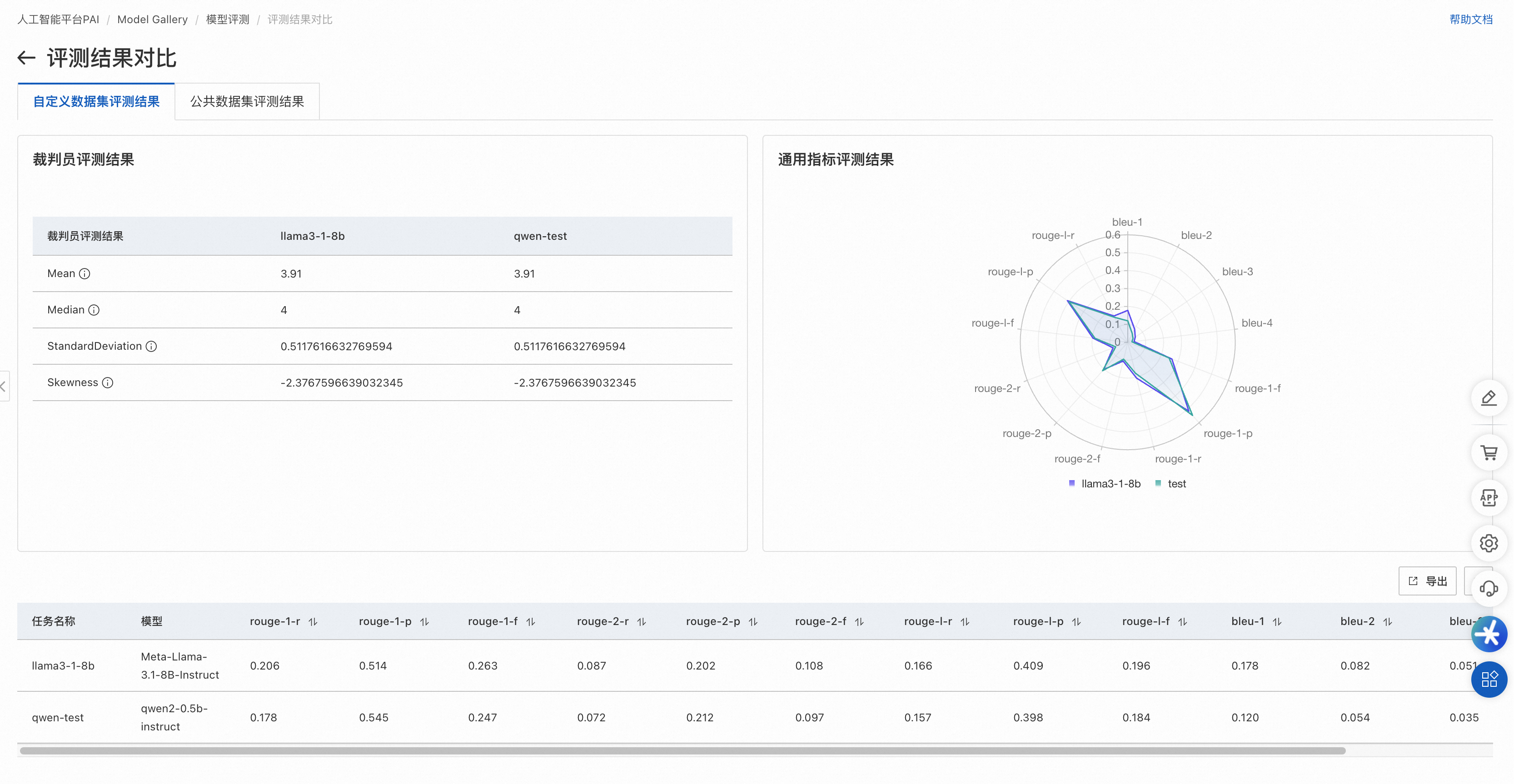
公開數據集對比結果
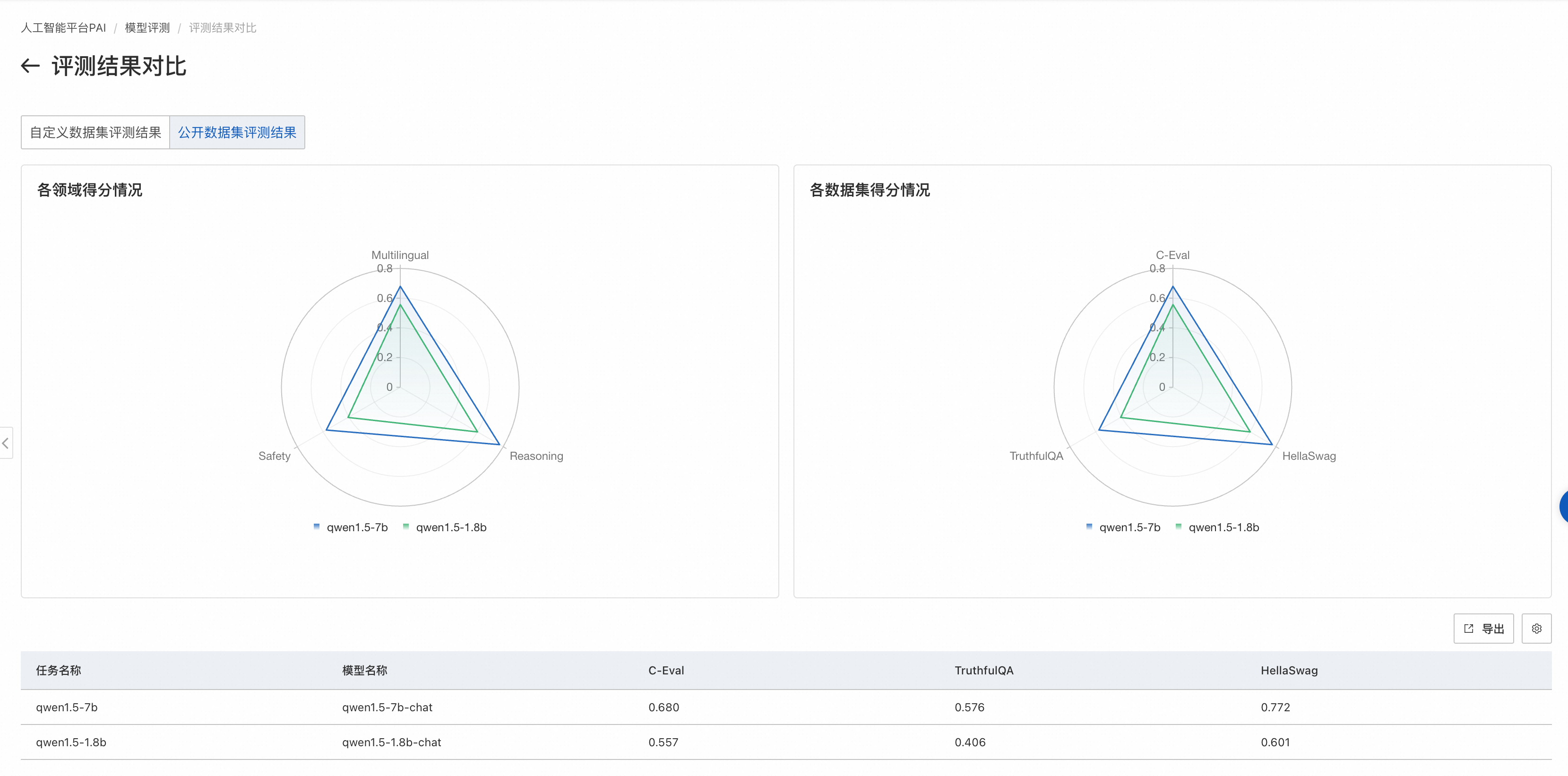
結果分析
模型評測包含自定義數據集和公開數據集的結果:
自定義數據集評測:
使用NLP領域標準的文本匹配方式,計算模型輸出結果和真實結果的匹配度,值越大,模型越好。
使用裁判員模型評價被評測模型的輸出,可以發揮大語言模型的優勢,從語意層面更準確的評價模型輸出的好壞。均值和中位數越高,標準差越小,模型越好。
使用該評測方式,基于自己場景的獨特數據,可以評測所選模型是否適合自己的場景。
公開數據集評測:使用開源的各領域評測數據集,對LLM模型進行綜合能力評估,例如數學能力、代碼能力等,值越大,模型越好,這種評測方式是LLM領域最常見的評測方式。PAI正在跟隨業界逐步接入更多公開評測集。
附錄
除了控制臺頁面,也可以通過PAI Python SDK使用模型評測功能,詳情可參考如下NoteBook: