LLM數據處理算法提供了對數據樣本進行編輯和轉換、過濾低質量樣本、識別和刪除重復樣本等功能。您可以根據實際需求組合不同的算法,從而過濾出合適的數據并生成符合要求的文本,方便為后續的LLM訓練提供優質的數據。本文以開源Alpaca-Cot中的少量數據為例,為您介紹如何使用PAI提供的大模型數據處理組件,對SFT數據進行數據清洗和處理。
數據集說明
本文Designer中“LLM大語言模型數據處理-Alpaca-Cot(sft數據)-DLC組件”預置模板用的數據集為開源項目Alpaca-CoT的原始數據中抽取的5000個樣本數據。
創建并運行工作流
進入Designer頁面。
登錄PAI控制臺。
在頂部左上角根據實際情況選擇地域。
在左側導航欄選擇工作空間列表,單擊指定工作空間名稱,進入對應工作空間。
在左側導航欄選擇模型開發與訓練 > 可視化建模(Designer),進入Designer頁面。
創建工作流。
在預置模板頁簽下,選擇業務領域 > LLM 大語言模型,單擊LLM大語言模型數據處理-Alpaca-Cot (sft數據)- DLC組件模板卡片上的創建。
配置工作流參數(或保持默認),單擊確定。
在工作流列表,選擇已創建的工作流,單擊進入工作流。
工作流說明:
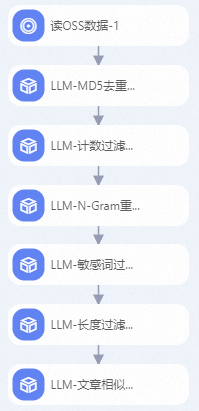
工作流中關鍵算法組件說明:
LLM-MD5去重(DLC)-1
計算“text”字段文本哈希值,并去除重復的文本(哈希值相同的文本僅保留一個)。
LLM-計數過濾(DLC)-1
將“text”字段中不符合數字和字母字符占比的樣本去除。SFT數據集中大部分字符都由字母和數字組成,通過該組件可以去除部分臟數據。
LLM-N-Gram重復比率過濾(DLC)-1
根據“text”字段的字符級N-Gram重復比率進行樣本過濾,即將文本里的內容按照字符進行大小為N的滑動窗口操作,形成了長度為N的片段序列。每一個片段稱為gram,對所有gram的出現次數進行統計。最后統計
頻次大于1的gram的頻次總和 / 所有gram的頻次總和兩者比率作為重復比率進行樣本過濾。LLM-敏感詞過濾(DLC)-1
使用系統預置敏感詞文件過濾“text”字段中包含敏感詞的樣本。
LLM-長度過濾(DLC)-1
根據“text”字段的長度和對應最大行長度進行樣本過濾。最大行長度基于換行符
\n分割樣本。LLM-文章相似度去重(DLC)-1
根據設置的window_size、num_blocks和hamming_distance值去除相似的樣本。
運行工作流。
運行結束后,右鍵單擊LLM-文章相似度去重(DLC)-1組件,選擇查看數據 > 輸出數據(OSS),查看經過上述所有組件處理后的樣本文件。
相關參考
LLM算法組件詳細說明,請參見LLM數據處理(DLC)。
在完成數據處理后,您可以使用PAI平臺提供的一系列大模型組件(包括數據處理組件、訓練組件以及推理組件),來實現大模型從開發到使用的端到端流程。詳情請參見LLM大語言模型端到端鏈路-DLC組件:數據處理+模型訓練+模型推理。