通義千問(wèn)Qwen全托管靈駿最佳實(shí)踐
本方案旨在幫助大模型開(kāi)發(fā)者快速上手靈駿智算平臺(tái),實(shí)現(xiàn)大語(yǔ)言模型(Qwen-7B、Qwen-14B和Qwen-72B)的高效分布式訓(xùn)練、三階段指令微調(diào)、模型離線推理和在線服務(wù)部署等完整的開(kāi)發(fā)流程。以Qwen-7B模型為例,為您詳細(xì)介紹該方案的開(kāi)發(fā)流程。
前提條件
本方案以Qwen-7B v1.1.4版本的模型為例,在開(kāi)始執(zhí)行操作前,請(qǐng)確認(rèn)您已經(jīng)完成以下準(zhǔn)備工作:
已開(kāi)通PAI(DSW、DLC、EAS)并創(chuàng)建了默認(rèn)的工作空間。具體操作,請(qǐng)參見(jiàn)開(kāi)通PAI并創(chuàng)建默認(rèn)工作空間。
已購(gòu)買(mǎi)靈駿智算資源并創(chuàng)建資源配額。不同的模型參數(shù)量支持的資源規(guī)格列表如下,請(qǐng)根據(jù)您實(shí)際使用的模型參數(shù)量選擇合適的資源,關(guān)于靈駿智算資源的節(jié)點(diǎn)規(guī)格詳情,請(qǐng)參見(jiàn)靈駿Serverless版機(jī)型定價(jià)詳情。具體操作,請(qǐng)參見(jiàn)新建資源組并購(gòu)買(mǎi)靈駿智算資源和靈駿智算資源配額。
模型參數(shù)量
全參數(shù)訓(xùn)練資源
推理資源(最低)
Megatron訓(xùn)練模型切片
7B
8卡*gu7xf、8卡*gu7ef
1*V100(32 GB顯存)、1*A10(24 GB顯存)
TP1、PP1
14B
8卡*gu7xf、8卡*gu7ef
2*V100(32 GB顯存)、2*A10(24 GB顯存)
TP2、PP1
72B
4*8卡*gu7xf、4*8卡*gu7ef
6*V100(32 GB顯存)、2卡*gu7xf
TP8、PP2
已創(chuàng)建阿里云文件存儲(chǔ)(通用型NAS)類(lèi)型的數(shù)據(jù)集,用于存儲(chǔ)訓(xùn)練所需的文件和結(jié)果文件。默認(rèn)掛載路徑配置為
/mnt/data/nas。具體操作,請(qǐng)參見(jiàn)創(chuàng)建及管理數(shù)據(jù)集。已創(chuàng)建DSW實(shí)例,其中關(guān)鍵參數(shù)配置如下。具體操作,請(qǐng)參見(jiàn)創(chuàng)建DSW實(shí)例。
資源配額:選擇已創(chuàng)建的靈駿智算資源的資源配額。
資源規(guī)格:配置以下資源規(guī)格。
CPU(核數(shù)):90。
內(nèi)存(GiB):1024。
共享內(nèi)存(GiB):1024。
GPU(卡數(shù)):至少為8。
數(shù)據(jù)集掛載:?jiǎn)螕?b data-tag="uicontrol" id="e61d2249c1o2z" class="uicontrol">自定義數(shù)據(jù)集,選擇已創(chuàng)建的數(shù)據(jù)集,并使用默認(rèn)掛載路徑。
鏡像:在鏡像地址頁(yè)簽,配置鏡像為
pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pytorch-training:1.12-ubuntu20.04-py3.10-cuda11.3-megatron-patch-llm。
如果使用RAM用戶(hù)完成以下相關(guān)操作,需要為RAM用戶(hù)授予DSW、DLC或EAS的操作權(quán)限。具體操作,請(qǐng)參見(jiàn)云產(chǎn)品依賴(lài)與授權(quán):DSW、云產(chǎn)品依賴(lài)與授權(quán):DLC或云產(chǎn)品依賴(lài)與授權(quán):EAS。
使用限制
僅支持在華北6(烏蘭察布)地域使用該最佳實(shí)踐。
步驟一:準(zhǔn)備通義千問(wèn)模型
本案例提供了以下三種下載模型的方式,您可以根據(jù)需要選擇其中一種。具體操作步驟如下:
進(jìn)入PAI-DSW開(kāi)發(fā)環(huán)境。
登錄PAI控制臺(tái)。
在頁(yè)面左上方,選擇使用服務(wù)的地域:華北6(烏蘭察布)。
在左側(cè)導(dǎo)航欄單擊工作空間列表,在工作空間列表頁(yè)面中單擊待操作的工作空間名稱(chēng),進(jìn)入對(duì)應(yīng)工作空間內(nèi)。
在左側(cè)導(dǎo)航欄,選擇。
單擊目標(biāo)實(shí)例操作列下的打開(kāi)。
在頂部菜單欄單擊Terminal,在該頁(yè)簽中單擊創(chuàng)建terminal。
下載通義千問(wèn)模型。
從ModelScope社區(qū)下載模型
在Terminal中執(zhí)行以下命令安裝ModelScope。
執(zhí)行以下命令進(jìn)入Python環(huán)境。
以Qwen-7B模型為例,下載模型文件的代碼示例如下。如果您需要下載Qwen-14B或Qwen-72B模型文件,請(qǐng)單擊下述表格中相應(yīng)的模型鏈接,并查看相應(yīng)的代碼。
按
Ctrl+D,退出Python環(huán)境。執(zhí)行以下命令將已下載的通義千問(wèn)模型移動(dòng)到對(duì)應(yīng)文件夾中。
pip install modelscopeLooking in indexes: https://mirrors.cloud.aliyuncs.com/pypi/simple Collecting modelscope Downloading https://mirrors.cloud.aliyuncs.com/pypi/packages/ac/05/75b5d750608d7354dc3dd023dca7101e5f3b4645cb3e5b816536d472a058/modelscope-1.9.5-py3-none-any.whl (5.4 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5.4/5.4 MB 104.7 MB/s eta 0:00:00 Requirement already satisfied: pyyaml in /opt/*/lib/python3.8/site-packages (from modelscope) (5.4.1) Requirement already satisfied: pandas in /opt/*/lib/python3.8/site-packages (from modelscope) (1.5.3) Requirement already satisfied: addict in /opt/*/lib/python3.8/site-packages (from modelscope) (2.4.0) Requirement already satisfied: numpy in /opt/*/lib/python3.8/site-packages (from modelscope) (1.22.2) Collecting simplejson>=3.3.0 Downloading https://mirrors.cloud.aliyuncs.com/pypi/packages/33/5f/b9506e323ea89737b34c97a6eda9d22ad6b771190df93f6eb72657a3b996/simplejson-3.19.2-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl (136 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 136.6/136.6 kB 70.2 MB/s eta 0:00:00 Collecting gast>=0.2.2 Downloading https://mirrors.cloud.aliyuncs.com/pypi/packages/fa/39/5aae571e5a5f4de9c3445dae08a530498e5c53b0e74410eeeb0991c79047/gast-0.5.4-py3-none-any.whl (19 kB) Requirement already satisfied: Pillow>=6.2.0 in /opt/*/lib/python3.8/site-packages (from modelscope) (9.3.0) Requirement already satisfied: oss2 in /opt/*/lib/python3.8/site-packages (from modelscope) (2.17.0) Requirement already satisfied: filelock>=3.3.0 in /opt/*/lib/python3.8/site-packages (from modelscope) (3.11.0) Requirement already satisfied: urllib3>=1.26 in /opt/*/lib/python3.8/site-packages (from modelscope) (1.26.12) Requirement already satisfied: datasets<=2.13.0,>=2.8.0 in /opt/*/lib/python3.8/site-packages (from modelscope) (2.11.0) Requirement already satisfied: attrs in /opt/*/lib/python3.8/site-packages (from modelscope) (22.2.0) Requirement already satisfied: scipy in /opt/*/lib/python3.8/site-packages (from modelscope) (1.9.3) Requirement already satisfied: yapf in /opt/*/lib/python3.8/site-packages (from modelscope) (0.32.0) Requirement already satisfied: pyarrow!=9.0.0,>=6.0.0 in /opt/*/lib/python3.8/site-packages (from modelscope) (11.0.0) Requirement already satisfied: setuptools in /opt/*/lib/python3.8/site-packages (from modelscope) (65.5.0) Requirement already satisfied: requests>=2.25 in /opt/*/lib/python3.8/site-packages (from modelscope) (2.28.1) Requirement already satisfied: einops in /opt/*/lib/python3.8/site-packages (from modelscope) (0.6.0) Requirement already satisfied: python-dateutil>=2.1 in /opt/*/lib/python3.8/site-packages (from modelscope) (2.8.2) Collecting sortedcontainers>=1.5.9 Downloading https://mirrors.cloud.aliyuncs.com/pypi/packages/32/46/9cb0e58b2deb7f82b84065f37f3bffeb12413f947f9388e4cac22c4621ce/sortedcontainers-2.4.0-py2.py3-none-any.whl (29 kB) Requirement already satisfied: tqdm>=4.64.0 in /opt/*/lib/python3.8/site-packages (from modelscope) (4.65.0) Requirement already satisfied: dill<0.3.7,>=0.3.0 in /opt/*/lib/python3.8/site-packages (from datasets<=2.13.0,>=2.8.0->modelscope) (0.3.6) Requirement already satisfied: multiprocess in /opt/*/lib/python3.8/site-packages (from datasets<=2.13.0,>=2.8.0->modelscope) (0.70.14) Requirement already satisfied: aiohttp in /opt/*/lib/python3.8/site-packages (from datasets<=2.13.0,>=2.8.0->modelscope) (3.8.4) Requirement already satisfied: responses<0.19 in /opt/*/lib/python3.8/site-packages (from datasets<=2.13.0,>=2.8.0->modelscope) (0.18.0) Requirement already satisfied: huggingface-hub<1.0.0,>=0.11.0 in /opt/*/lib/python3.8/site-packages (from datasets<=2.13.0,>=2.8.0->modelscope) (0.16.4) Requirement already satisfied: fsspec[http]>=2021.11.1 in /opt/*/lib/python3.8/site-packages (from datasets<=2.13.0,>=2.8.0->modelscope) (2023.4.0) Requirement already satisfied: packaging in /opt/*/lib/python3.8/site-packages (from datasets<=2.13.0,>=2.8.0->modelscope) (21.3) Requirement already satisfied: xxhash in /opt/*/lib/python3.8/site-packages (from datasets<=2.13.0,>=2.8.0->modelscope) (3.2.0) Requirement already satisfied: six>=1.5 in /opt/*/lib/python3.8/site-packages (from python-dateutil>=2.1->modelscope) (1.16.0) Requirement already satisfied: certifi>=2017.4.17 in /opt/*/lib/python3.8/site-packages (from requests>=2.25->modelscope) (2022.9.24) Requirement already satisfied: charset-normalizer<3,>=2 in /opt/*/lib/python3.8/site-packages (from requests>=2.25->modelscope) (2.0.4) Requirement already satisfied: idna<4,>=2.5 in /opt/*/lib/python3.8/site-packages (from requests>=2.25->modelscope) (3.4) Requirement already satisfied: aliyun-python-sdk-kms>=2.4.1 in /opt/*/lib/python3.8/site-packages (from oss2->modelscope) (2.16.0) Requirement already satisfied: aliyun-python-sdk-core>=2.13.12 in /opt/*/lib/python3.8/site-packages (from oss2->modelscope) (2.13.36) Requirement already satisfied: crcmod>=1.7 in /opt/*/lib/python3.8/site-packages (from oss2->modelscope) (1.7) Requirement already satisfied: pycryptodome>=3.4.7 in /opt/*/lib/python3.8/site-packages (from oss2->modelscope) (3.15.0) Requirement already satisfied: pytz>=2020.1 in /opt/*/lib/python3.8/site-packages (from pandas->modelscope) (2022.7.1) Requirement already satisfied: cryptography>=2.6.0 in /opt/*/lib/python3.8/site-packages (from aliyun-python-sdk-core>=2.13.12->oss2->modelscope) (38.0.3) Requirement already satisfied: jmespath<1.0.0,>=0.9.3 in /opt/*/lib/python3.8/site-packages (from aliyun-python-sdk-core>=2.13.12->oss2->modelscope) (0.10.0) Requirement already satisfied: async-timeout<5.0,>=4.0.0a3 in /opt/*/lib/python3.8/site-packages (from aiohttp->datasets<=2.13.0,>=2.8.0->modelscope) (4.0.2) Requirement already satisfied: yarl<2.0,>=1.0 in /opt/*/lib/python3.8/site-packages (from aiohttp->datasets<=2.13.0,>=2.8.0->modelscope) (1.8.2) Requirement already satisfied: frozenlist>=1.1.1 in /opt/*/lib/python3.8/site-packages (from aiohttp->datasets<=2.13.0,>=2.8.0->modelscope) (1.3.3) Requirement already satisfied: multidict<7.0,>=4.5 in /opt/*/lib/python3.8/site-packages (from aiohttp->datasets<=2.13.0,>=2.8.0->modelscope) (6.0.4) Requirement already satisfied: aiosignal>=1.1.2 in /opt/*/lib/python3.8/site-packages (from aiohttp->datasets<=2.13.0,>=2.8.0->modelscope) (1.3.1) Requirement already satisfied: typing-extensions>=3.7.*.* in /opt/*/lib/python3.8/site-packages (from huggingface-hub<1.0.0,>=0.11.0->datasets<=2.13.0,>=2.8.0->modelscope) (4.4.0) Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /opt/*/lib/python3.8/site-packages (from packaging->datasets<=2.13.0,>=2.8.0->modelscope) (3.0.9) Requirement already satisfied: cffi>=1.12 in /opt/*/lib/python3.8/site-packages (from cryptography>=2.6.0->aliyun-python-sdk-core>=2.13.12->oss2->modelscope) (1.15.1) Requirement already satisfied: pycparser in /opt/*/lib/python3.8/site-packages (from cffi>=1.12->cryptography>=2.6.0->aliyun-python-sdk-core>=2.13.12->oss2->modelscope) (2.21) Installing collected packages: sortedcontainers, simplejson, gast, modelscope Successfully installed gast-0.5.4 modelscope-1.9.5 simplejson-3.19.2 sortedcontainers-2.4.0 WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venvpython# ### Loading Model and Tokenizer from modelscope.hub.snapshot_download import snapshot_download model_dir = snapshot_download('qwen/Qwen-7B', 'v1.1.4') # model_dir = snapshot_download('qwen/Qwen-14B', 'v1.0.4') # model_dir = snapshot_download('qwen/Qwen-72B') # 獲取下載路徑 print(model_dir) # /root/.cache/modelscope/hub/qwen/Qwen-7B模型類(lèi)型
模型鏈接
模型名稱(chēng)
版本
Qwen-7B
qwen/Qwen-7B
v1.1.4
Qwen-7B-chat
qwen/Qwen-7B-Chat
Qwen-14B
qwen/Qwen-14B
v1.0.4
Qwen-14B-chat
qwen/Qwen-14B-Chat
Qwen-72B
qwen/Qwen-72B
master
Qwen-72B-chat
qwen/Qwen-72B-Chat
# mkdir -p /mnt/workspace/qwen-ckpts/${后綴為hf的ckpt文件夾} mkdir -p /mnt/workspace/qwen-ckpts/qwen-7b-hf # cp -r ${在此處填寫(xiě)已下載的模型路徑}/* /mnt/workspace/qwen-ckpts/${后綴為hf的ckpt文件夾} cp -r /root/.cache/modelscope/hub/qwen/Qwen-7B/* /mnt/workspace/qwen-ckpts/qwen-7b-hf從HuggingFace社區(qū)下載模型
在DSW的Terminal中執(zhí)行以下命令下載模型文件。本方案以下載Qwen-7B模型為例,如果您需要下載Qwen-14B或Qwen-72B的模型文件,請(qǐng)參照下方代碼進(jìn)行修改。
mkdir /mnt/workspace/qwen-ckpts cd /mnt/workspace/qwen-ckpts git clone https://huggingface.co/Qwen/Qwen-7B # git clone https://huggingface.co/Qwen/Qwen-7B-Chat # git clone https://huggingface.co/Qwen/Qwen-14B # git clone https://huggingface.co/Qwen/Qwen-14B-Chat # git clone https://huggingface.co/Qwen/Qwen-72B # git clone https://huggingface.co/Qwen/Qwen-72B-Chat
步驟二:準(zhǔn)備預(yù)訓(xùn)練數(shù)據(jù)
建議您在DSW實(shí)例中準(zhǔn)備預(yù)訓(xùn)練數(shù)據(jù)。本案例以WuDaoCorpora2.0數(shù)據(jù)集(該數(shù)據(jù)集僅供研究使用)為例,介紹Megatron訓(xùn)練數(shù)據(jù)的預(yù)處理流程。您可以直接下載PAI已準(zhǔn)備好的小規(guī)模樣本數(shù)據(jù),也可以按照以下操作步驟自行準(zhǔn)備預(yù)訓(xùn)練數(shù)據(jù)。
使用PAI處理好的小規(guī)模樣本數(shù)據(jù)
為了方便您試用該案例,PAI也提供了已經(jīng)處理好的小規(guī)模樣本數(shù)據(jù),您可以在DSW的Terminal中執(zhí)行以下命令下載樣本數(shù)據(jù)。
mkdir /mnt/workspace/qwen-datasets/
cd /mnt/workspace/qwen-datasets
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-datasets/alpaca_zh-qwen-train.json
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-datasets/alpaca_zh-qwen-valid.json
mkdir -p /mnt/workspace/qwen-datasets/wudao
cd /mnt/workspace/qwen-datasets/wudao
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-datasets/wudao_qwenbpe_content_document.bin
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-datasets/wudao_qwenbpe_content_document.idx自行處理數(shù)據(jù)
下載WuDaoCorpora2.0開(kāi)源數(shù)據(jù)集到
/mnt/workspace/qwen-datasets工作目錄下。本案例將解壓后的文件夾命名為wudao_200g。PAI提供了部分樣例數(shù)據(jù)作為示例,您可以在DSW的Terminal中執(zhí)行以下命令下載并解壓數(shù)據(jù)集。
mkdir /mnt/workspace/qwen-datasets cd /mnt/workspace/qwen-datasets wget https://atp-modelzoo.oss-cn-hangzhou.aliyuncs.com/release/datasets/WuDaoCorpus2.0_base_sample.tgz tar zxvf WuDaoCorpus2.0_base_sample.tgz mv WuDaoCorpus2.0_base_sample wudao_200g在Terminal中執(zhí)行以下命令,對(duì)Wudao數(shù)據(jù)執(zhí)行數(shù)據(jù)集清洗并進(jìn)行文件格式轉(zhuǎn)換,最終生成匯總的merged_wudao_cleaned.json文件。
#! /bin/bash set -ex # 請(qǐng)?jiān)诖颂幵O(shè)置原始數(shù)據(jù)所在路徑。 data_dir=/mnt/workspace/qwen-datasets/wudao_200g # 開(kāi)始數(shù)據(jù)清洗流程。 dataset_dir=$(dirname $data_dir) mkdir -p ${dataset_dir}/cleaned_wudao_dataset cd ${dataset_dir}/cleaned_wudao_dataset wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/preprocess_wudao2.py # 此處與上一節(jié)不同,增加了key參數(shù)設(shè)為text。 python preprocess_wudao2.py -i ${data_dir} -o ${dataset_dir}/cleaned_wudao_dataset -k text -p 32 # 合并清洗后的數(shù)據(jù)。 mkdir ${dataset_dir}/wudao cd ${dataset_dir}/wudao find ${dataset_dir}/cleaned_wudao_dataset -name "*.json" -exec cat {} + > ${dataset_dir}/wudao/merged_wudao_cleaned.json rm -rf ${dataset_dir}/cleaned_wudao_dataset命令執(zhí)行完成后,
qwen-datasets目錄的文件結(jié)構(gòu)如下,新增了一個(gè)wudao文件夾。qwen-datasets ├── wudao_200g └── wudao └── merged_wudao_cleaned.json在Terminal中執(zhí)行以下命令,利用生成的merged_wudao_cleaned.json文件將數(shù)據(jù)拆分成若干組并進(jìn)行壓縮,以便于后續(xù)實(shí)現(xiàn)多線程處理。
apt-get update apt-get install zstd # 此處設(shè)置分塊數(shù)為10,如數(shù)據(jù)處理慢可設(shè)置稍大。 NUM_PIECE=10 # 對(duì)merged_wudao_cleaned.json文件進(jìn)行處理。 mkdir -p ${dataset_dir}/cleaned_zst/ # 查詢(xún)數(shù)據(jù)總長(zhǎng)度,對(duì)數(shù)據(jù)進(jìn)行拆分。 NUM=$(sed -n '$=' ${dataset_dir}/wudao/merged_wudao_cleaned.json) echo "total line of dataset is $NUM, data will be split into $NUM_PIECE pieces for processing" NUM=`expr $NUM / $NUM_PIECE` echo "each group is processing $NUM sample" split_dir=${dataset_dir}/split mkdir $split_dir split -l $NUM --numeric-suffixes --additional-suffix=.jsonl ${dataset_dir}/wudao/merged_wudao_cleaned.json $split_dir/ # 數(shù)據(jù)壓縮。 o_path=${dataset_dir}/cleaned_zst/ mkdir -p $o_path files=$(ls $split_dir/*.jsonl) for filename in $files do f=$(basename $filename) zstd -z $filename -o $o_path/$f.zst & done rm -rf $split_dir rm ${dataset_dir}/wudao/merged_wudao_cleaned.json命令執(zhí)行完成后,
qwen-datasets目錄的文件結(jié)構(gòu)如下。新增了一個(gè)cleaned_zst文件夾,該文件夾中有10個(gè)壓縮文件。qwen-datasets ├── wudao_200g ├── wudao └── cleaned_zst ├── 00.jsonl.zst │ ... └── 09.jsonl.zst制作MMAP格式的預(yù)訓(xùn)練數(shù)據(jù)集。
MMAP數(shù)據(jù)是一種預(yù)先執(zhí)行tokenize的數(shù)據(jù)格式,可以減少訓(xùn)練微調(diào)過(guò)程中等待數(shù)據(jù)讀入的時(shí)間,尤其在處理大規(guī)模數(shù)據(jù)時(shí)優(yōu)勢(shì)更為突出。具體操作步驟如下:
在DSW的Terminal中執(zhí)行以下命令,將Megatron格式的模型訓(xùn)練工具源代碼PAI-Megatron-Patch拷貝至DSW的工作目錄
/mnt/workspace/下。cd /mnt/workspace/ # 方式一:通過(guò)開(kāi)源網(wǎng)站獲取訓(xùn)練代碼。 git clone --recurse-submodules https://github.com/alibaba/Pai-Megatron-Patch.git # 方式二:通過(guò)wget方式獲取訓(xùn)練代碼,需要執(zhí)行tar zxvf Pai-Megatron-Patch.tgz進(jìn)行解壓。 wget https://atp-modelzoo.oss-cn-hangzhou.aliyuncs.com/release/models/Pai-Megatron-Patch.tgz在Terminal中執(zhí)行以下命令將數(shù)據(jù)轉(zhuǎn)換成MMAP格式。
命令執(zhí)行成功后,在
/mnt/workspace/qwen-datasets/wudao目錄下生成.bin和.idx文件。# 安裝Qwen依賴(lài)的tokenizer庫(kù)包。 pip install tiktoken # 請(qǐng)?jiān)诖颂幵O(shè)置數(shù)據(jù)集路徑和工作路徑。 export dataset_dir=/mnt/workspace/qwen-datasets export WORK_DIR=/mnt/workspace # 分別為訓(xùn)練集、驗(yàn)證集生成mmap格式預(yù)訓(xùn)練數(shù)據(jù)集。 cd ${WORK_DIR}/Pai-Megatron-Patch/toolkits/pretrain_data_preprocessing bash run_make_pretraining_dataset.sh \ ../../Megatron-LM-23.04 \ ${WORK_DIR}/Pai-Megatron-Patch/ \ ${dataset_dir}/cleaned_zst/ \ qwenbpe \ ${dataset_dir}/wudao/ \ ${WORK_DIR}/qwen-ckpts/qwen-7b-hf rm -rf ${dataset_dir}/cleaned_zst其中運(yùn)行run_make_pretraining_dataset.sh輸入的六個(gè)啟動(dòng)參數(shù)說(shuō)明如下:
參數(shù)
描述
MEGATRON_PATH=$1
設(shè)置開(kāi)源Megatron的代碼路徑。
MEGATRON_PATCH_PATH=$2
設(shè)置Megatron Patch的代碼路徑。
input_data_dir=$3
打包后的Wudao數(shù)據(jù)集的文件夾路徑。
tokenizer=$4
指定分詞器的類(lèi)型為qwenbpe。
output_data_dir=$5
指定輸出的
.bin和.idx文件的保存路徑。load_dir=$6
生成的tokenizer_config.json文件的路徑。
腳本執(zhí)行完成后,
qwen-datasets目錄的文件結(jié)構(gòu)如下。qwen-datasets ├── wudao_200g └── wudao ├── wudao_qwenbpe_content_document.bin └── wudao_qwenbpe_content_document.idx
步驟三:Megatron訓(xùn)練
您可以按照以下流程進(jìn)行Megatron訓(xùn)練。
模型格式轉(zhuǎn)換
將HuggingFace格式的模型文件轉(zhuǎn)換為Megatron格式。
下載轉(zhuǎn)換好的Megatron模型
為方便您試用該案例,PAI提供了已經(jīng)轉(zhuǎn)換好格式的模型。您可以在Terminal中執(zhí)行以下命令下載模型。
cd /mnt/workspace/
mkdir qwen-ckpts
cd qwen-ckpts
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-ckpts/qwen-7b-hf-to-mg-tp1-pp1.tgz
tar -zxf qwen-7b-hf-to-mg-tp1-pp1.tgz
mv qwen-7b-hf-to-mg-tp1-pp1 qwen-7b-hf-to-megatron-tp1-pp1自行將HuggingFace格式的模型轉(zhuǎn)換成Megatron格式
在Terminal中執(zhí)行以下命令,使用PAI提供的模型轉(zhuǎn)換工具,將HuggingFace格式的模型文件轉(zhuǎn)換為Megatron格式:
# 轉(zhuǎn)換模型。
cd /mnt/workspace/Pai-Megatron-Patch/toolkits/model_checkpoints_convertor/qwen
sh model_convertor.sh \
../../../Megatron-LM-main \
/mnt/workspace/qwen-ckpts/qwen-7b-hf \
/mnt/workspace/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 \
1 \
1 \
qwen-7b \
0 \
false其中運(yùn)行model_convertor.sh需要傳入的參數(shù)說(shuō)明如下:
參數(shù) | 描述 |
MEGATRON_PATH=$1 | 設(shè)置開(kāi)源Megatron的代碼路徑。 |
SOURCE_CKPT_PATH=$2 | HuggingFace格式的模型文件路徑。 |
TARGET_CKPT_PATH=$3 | 轉(zhuǎn)換為Megatron格式模型后保存的路徑。 |
TP=$4 | 張量切片數(shù)量,與訓(xùn)練保持一致。不同參數(shù)量下的切片數(shù)量不同,在轉(zhuǎn)換模型時(shí)需進(jìn)行針對(duì)性修改:
|
PP=$5 | 流水切片數(shù)量,與訓(xùn)練保持一致。不同參數(shù)量下的切片數(shù)量不同,在轉(zhuǎn)換模型時(shí)需進(jìn)行針對(duì)性修改:
|
MN=$6 | 模型名稱(chēng):qwen-7b、qwen-14b或qwen-72b。 |
EXTRA_VOCAB_SIZE=$7 | 額外詞表大小。 |
mg2hf=$8 | 是否為Megatron格式轉(zhuǎn)HuggingFace格式。 |
預(yù)訓(xùn)練模型
您可以在DSW單機(jī)環(huán)境中訓(xùn)練模型,也可以在DLC環(huán)境中提交多機(jī)多卡分布式訓(xùn)練任務(wù),訓(xùn)練過(guò)程大約持續(xù)2個(gè)小時(shí)。任務(wù)執(zhí)行成功后,模型文件將輸出到/mnt/workspace/output_megatron_qwen/目錄下。
DSW單機(jī)預(yù)訓(xùn)練模型
以Qwen-7B模型為例,在Terminal中運(yùn)行的代碼示例如下:
export WORK_DIR=/mnt/workspace
cd ${WORK_DIR}/Pai-Megatron-Patch/examples/qwen
sh run_pretrain_megatron_qwen.sh \
dsw \
${WORK_DIR}/Pai-Megatron-Patch \
7B \
1 \
8 \
1e-5 \
1e-6 \
2048 \
2048 \
85 \
fp16 \
1 \
1 \
sel \
true \
false \
false \
false \
100000 \
${WORK_DIR}/qwen-datasets/wudao/wudao_qwenbpe_content_document \
${WORK_DIR}/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 \
100000000 \
10000 \
${WORK_DIR}/output_megatron_qwen/ 其中運(yùn)行run_pretrain_megatron_qwen.sh需要傳入的參數(shù)說(shuō)明如下:
參數(shù) | 描述 |
ENV=$1 | 配置運(yùn)行環(huán)境:
|
MEGATRON_PATH=$2 | 設(shè)置開(kāi)源Megatron的代碼路徑。 |
MODEL_SIZE=$3 | 模型結(jié)構(gòu)參數(shù)量級(jí):7B、14B或72B。 |
BATCH_SIZE=$4 | 每卡訓(xùn)練一次迭代樣本數(shù):4或8。 |
GLOBAL_BATCH_SIZE=$5 | 訓(xùn)練總迭代樣本數(shù)。 |
LR=$6 | 學(xué)習(xí)率:1e-5或5e-5。 |
MIN_LR=$7 | 最小學(xué)習(xí)率:1e-6或5e-6。 |
SEQ_LEN=$8 | 序列長(zhǎng)度。 |
PAD_LEN=${9} | Padding長(zhǎng)度。 |
EXTRA_VOCAB_SIZE=${10} | 詞表擴(kuò)充大小:
|
PR=${11} | 訓(xùn)練精度:fp16或bf16。 |
TP=${12} | 模型并行度。 |
PP=${13} | 流水并行度。 |
AC=${14} | 激活檢查點(diǎn)模式:
|
DO=${15} | 是否使用Megatron版Zero-1降顯存優(yōu)化器:
|
FL=${16} | 是否打開(kāi)Flash Attention:
|
SP=${17} | 是否使用序列并行:
|
TE=${18} | 是否開(kāi)啟Transformer-engine加速技術(shù),需gu8xf顯卡。 |
SAVE_INTERVAL=${19} | 保存CheckPoint文件的間隔。 |
DATASET_PATH=${20} | 訓(xùn)練數(shù)據(jù)集路徑。 |
PRETRAIN_CHECKPOINT_PATH=${21} | 預(yù)訓(xùn)練模型路徑。 |
TRAIN_TOKENS=${22} | 訓(xùn)練Tokens。 |
WARMUP_TOKENS=${23} | 預(yù)熱Token數(shù)。 |
OUTPUT_BASEPATH=${24} | 訓(xùn)練輸出模型文件的路徑。 |
DLC分布式預(yù)訓(xùn)練模型
在單機(jī)開(kāi)發(fā)調(diào)試完成后,您可以在DLC環(huán)境中配置多機(jī)多卡的分布式任務(wù)。具體操作步驟如下:
進(jìn)入新建任務(wù)頁(yè)面。
登錄PAI控制臺(tái),在頁(yè)面上方選擇目標(biāo)地域,并在右側(cè)選擇目標(biāo)工作空間,然后單擊進(jìn)入DLC。
在分布式訓(xùn)練(DLC)頁(yè)面,單擊新建任務(wù)。
在新建任務(wù)頁(yè)面,配置以下關(guān)鍵參數(shù),其他參數(shù)取默認(rèn)配置即可。更多詳細(xì)內(nèi)容,請(qǐng)參見(jiàn)創(chuàng)建訓(xùn)練任務(wù)。
參數(shù)
描述
基本信息
任務(wù)名稱(chēng)
自定義任務(wù)名稱(chēng)。本方案配置為:test_qwen_dlc。
環(huán)境信息
節(jié)點(diǎn)鏡像
選中鏡像地址并在文本框中輸入
pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pytorch-training:1.12-ubuntu20.04-py3.10-cuda11.3-megatron-patch-llm。數(shù)據(jù)集
單擊自定義數(shù)據(jù)集,并配置以下參數(shù):
自定義數(shù)據(jù)集:選擇已創(chuàng)建的NAS類(lèi)型的數(shù)據(jù)集。
掛載路徑:配置為
/mnt/workspace/。
啟動(dòng)命令
配置以下命令,其中run_pretrain_megatron_qwen.sh腳本輸入的啟動(dòng)參數(shù)與DSW單機(jī)預(yù)訓(xùn)練模型一致。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/Pai-Megatron-Patch/examples/qwen sh run_pretrain_megatron_qwen.sh \ dlc \ ${WORK_DIR}/PAI-Megatron-Patch \ 7B \ 1 \ 8 \ 1e-5 \ 1e-6 \ 2048 \ 2048 \ 85 \ fp16 \ 1 \ 1 \ sel \ true \ false \ false \ false \ 100000 \ ${WORK_DIR}/qwen-datasets/wudao/wudao_qwenbpe_content_document \ ${WORK_DIR}/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 \ 100000000 \ 10000 \ ${WORK_DIR}/output_megatron_qwen/資源信息
資源類(lèi)型
選擇靈駿智算。
資源來(lái)源
選擇資源配額。
資源配額
本方案選擇已創(chuàng)建的靈駿智算資源的資源配額。
框架
選擇PyTorch。
任務(wù)資源
在Worker節(jié)點(diǎn)配置以下參數(shù):
節(jié)點(diǎn)數(shù)量:2,如果需要多機(jī)訓(xùn)練,配置節(jié)點(diǎn)數(shù)量為需要的機(jī)器數(shù)即可。
GPU(卡數(shù)):8
CPU(核數(shù)):90
說(shuō)明CPU核數(shù)不能大于96。
內(nèi)存(GiB):1024
共享內(nèi)存(GiB):1024
單擊確定,頁(yè)面自動(dòng)跳轉(zhuǎn)到分布式訓(xùn)練(DLC)頁(yè)面。當(dāng)狀態(tài)變?yōu)?b data-tag="uicontrol" id="9b21d79015jrz" class="uicontrol">已成功時(shí),表明訓(xùn)練任務(wù)執(zhí)行成功。
有監(jiān)督微調(diào)模型
您可以在DSW單機(jī)環(huán)境中微調(diào)模型,也可以在DLC環(huán)境中提交多機(jī)多卡分布式任務(wù),訓(xùn)練過(guò)程大約持續(xù)2個(gè)小時(shí)。任務(wù)執(zhí)行成功后,模型文件將輸出到/mnt/workspace/output_megatron_qwen/目錄下。
在微調(diào)模型前,請(qǐng)前往步驟二:準(zhǔn)備預(yù)訓(xùn)練數(shù)據(jù)章節(jié),在使用PAI處理好的小規(guī)模樣本數(shù)據(jù)頁(yè)簽中,按照代碼下載JSON文件。
微調(diào)模型。
DSW單機(jī)微調(diào)模型
以Qwen-7B模型為例,在Terminal中運(yùn)行的代碼示例如下:
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/Pai-Megatron-Patch/examples/qwen sh run_finetune_megatron_qwen_withGA.sh \ dsw \ ${WORK_DIR}/Pai-Megatron-Patch \ 7B \ 1 \ 96 \ 1e-5 \ 1e-6 \ 2048 \ 2048 \ 85 \ bf16 \ 1 \ 1 \ sel \ true \ false \ false \ false \ 1000 \ ${WORK_DIR}/qwen-datasets/alpaca_zh-qwen-train.json \ ${WORK_DIR}/qwen-datasets/alpaca_zh-qwen-valid.json \ ${WORK_DIR}/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 \ 2000 \ 10 \ ${WORK_DIR}/output_megatron_qwen/其中運(yùn)行run_finetune_megatron_qwen_withGA.sh需要傳入的參數(shù)說(shuō)明如下:
參數(shù)
描述
ENV=$1
運(yùn)行環(huán)境:
dlc
dsw
MEGATRON_PATH=$2
設(shè)置開(kāi)源Megatron的代碼路徑。
MODEL_SIZE=$3
模型結(jié)構(gòu)參數(shù)量級(jí):7B、14B或72B。
BATCH_SIZE=$4
每卡訓(xùn)練一次迭代樣本數(shù):1、2、4、8。
GLOBAL_BATCH_SIZE=$5
微調(diào)總迭代樣本數(shù):64、96、128。
LR=$6
學(xué)習(xí)率:1e-5、5e-5。
MIN_LR=$7
最小學(xué)習(xí)率:1e-6、5e-6。
SEQ_LEN=$8
序列長(zhǎng)度。
PAD_LEN=$9
Padding序列長(zhǎng)度。
EXTRA_VOCAB_SIZE=${10}
詞表擴(kuò)充大小:
Qwen-7B:85。
Qwen-14B:213。
Qwen-72B:213。
PR=${11}
訓(xùn)練精度:fp16、bf16。
TP=${12}
模型并行度。
PP=${13}
流水并行度。
AC=${14}
激活檢查點(diǎn)模式:full或sel。
DO=${15}
是否使用Megatron版Zero-1降顯存優(yōu)化器:
true
false
FL=${16}
是否打開(kāi)Flash Attention:
true
false
SP=${17}
是否使用序列并行:
true
false
TE=${18}
是否開(kāi)啟Transformer-engine加速技術(shù),需gu8xf顯卡。
SAVE_INTERVAL=${19}
保存模型的步數(shù)。
DATASET_PATH=${20}
訓(xùn)練數(shù)據(jù)集路徑。
VALID_DATASET_PATH=${21}
驗(yàn)證數(shù)據(jù)集路徑。
PRETRAIN_CHECKPOINT_PATH=${22}
預(yù)訓(xùn)練模型路徑。
TRAIN_ITERS=${23}
訓(xùn)練迭代輪次。
LR_WARMUP_ITERS=${24}
學(xué)習(xí)率增加值最大的步數(shù)。
OUTPUT_BASEPATH=${25}
訓(xùn)練輸出模型文件的路徑。
DLC分布式微調(diào)模型
在DSW單機(jī)環(huán)境調(diào)試完成后,您可以在DLC環(huán)境中配置多機(jī)多卡分布式任務(wù)。提交DLC訓(xùn)練任務(wù)時(shí),啟動(dòng)命令配置如下,其他參數(shù)配置詳情,請(qǐng)參見(jiàn)步驟2:預(yù)訓(xùn)練模型。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/Pai-Megatron-Patch/examples/qwen sh run_finetune_megatron_qwen_withGA.sh \ dlc \ ${WORK_DIR}/Pai-Megatron-Patch \ 7B \ 1 \ 96 \ 1e-5 \ 1e-6 \ 2048 \ 2048 \ 85 \ bf16 \ 1 \ 1 \ sel \ true \ false \ false \ false \ 1000 \ ${WORK_DIR}/qwen-datasets/alpaca_zh-qwen-train.json \ ${WORK_DIR}/qwen-datasets/alpaca_zh-qwen-valid.json \ ${WORK_DIR}/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 \ 2000 \ 10 \ ${WORK_DIR}/output_megatron_qwen/其中運(yùn)行run_finetune_megatron_qwen_withGA.sh需要傳入的參數(shù)與DSW單機(jī)微調(diào)模型相同。
步驟四:離線推理模型
在模型訓(xùn)練完成后,您可以使用Megatron推理鏈路進(jìn)行離線推理,以評(píng)估模型效果。具體操作步驟如下:
下載測(cè)試樣本pred_input.jsonl,并上傳到DSW的
/mnt/workspace目錄下。具體操作,請(qǐng)參見(jiàn)上傳與下載數(shù)據(jù)文件。說(shuō)明推理的數(shù)據(jù)組織形式需要與微調(diào)時(shí)保持一致。
將訓(xùn)練前模型路徑下的所有JSON文件和tokenizer.model文件拷貝到訓(xùn)練生成的模型路徑(位于
{OUTPUT_BASEPATH }/checkpoint的下一級(jí)目錄下,與latest_checkpointed_iteration.txt同級(jí))。說(shuō)明命令中的路徑需替換為您的實(shí)際路徑。
cd /mnt/workspace/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 cp *.json /mnt/workspace/output_megatron_qwen/checkpoint/dswXXX/ cp tokenizer.model /mnt/workspace/output_megatron_qwen/checkpoint/dswXXX/在Terminal中執(zhí)行以下命令完成模型離線推理,推理結(jié)果輸出到
/mnt/workspace/qwen_pred.txt文件,您可以根據(jù)推理結(jié)果來(lái)評(píng)估模型效果。說(shuō)明執(zhí)行命令前,您需要將run_text_generation_megatron_qwen.sh腳本中的參數(shù)CUDA_VISIBLE_DEVICES設(shè)置為0;參數(shù)GPUS_PER_NODE設(shè)置為1。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/Pai-Megatron-Patch/examples/qwen bash run_text_generation_megatron_qwen.sh \ dsw \ ${WORK_DIR}/PAI-Megatron-Patch \ /mnt/workspace/output_megatron_qwen/checkpoint/dswXXX \ 7B \ 1 \ 1 \ 1024 \ 1024 \ 85 \ fp16 \ 10 \ 512 \ 512 \ ${WORK_DIR}/pred_input.jsonl \ ${WORK_DIR}/qwen_pred.txt \ 0 \ 1.0 \ 1.2其中運(yùn)行run_text_generation_megatron_qwen.sh腳本輸入的啟動(dòng)參數(shù)說(shuō)明如下:
參數(shù)
描述
ENV=$1
運(yùn)行環(huán)境:
dlc
dsw
MEGATRON_PATCH_PATH=$2
設(shè)置Megatron Patch的代碼路徑。
CHECKPOINT_PATH=$3
模型訓(xùn)練階段的模型保存路徑。
重要該路徑需要替換為您自己的模型路徑。
MODEL_SIZE=$4
模型結(jié)構(gòu)參數(shù)量級(jí):7B、14B或72B。
TP=$5
模型并行度。
重要該參數(shù)配置為1,可以使用單卡進(jìn)行推理。
該參數(shù)值大于1,則需要使用相應(yīng)的卡數(shù)進(jìn)行推理。
BS=$6
每卡推理一次迭代樣本數(shù):1、4、8。
SEQ_LEN=$7
序列長(zhǎng)度:256、512、1024。
PAD_LEN=$8
PAD長(zhǎng)度:需要將文本拼接的長(zhǎng)度。
EXTRA_VOCAB_SIZE=${9}
模型轉(zhuǎn)換時(shí)增加的token數(shù)量:
Qwen-7B:85。
Qwen-14B:213。
Qwen-72B:213。
PR=${10}
推理采用的精度:fp16、bf16。
TOP_K=${11}
采樣策略中選擇排在前面的候選詞數(shù)量(0-n): 0、5、10、20。
INPUT_SEQ_LEN=${12}
輸入序列長(zhǎng)度:512。
OUTPUT_SEQ_LEN=${13}
輸出序列長(zhǎng)度:256。
INPUT_FILE=${14}
需要推理的文本文件:pred_input.jsonl,每行為一個(gè)樣本。
OUTPUT_FILE=${15}
推理輸出的文件:qwen_pred.txt。
TOP_P=${16}
采樣策略中選擇排在前面的候選詞百分比(0,1):0、0.85、0.95。
說(shuō)明TOP_K和TOP_P必須有一個(gè)為0。
TEMPERATURE=${17}
采樣策略中溫度懲罰:1-n。
REPETITION_PENALTY=${18}
避免生成時(shí)產(chǎn)生大量重復(fù),可以設(shè)置為(1-2)。默認(rèn)為1.2。
步驟五:模型格式轉(zhuǎn)換
離線推理完成后,如果模型效果符合您的預(yù)期,您可以將訓(xùn)練獲得的Megatron格式的模型轉(zhuǎn)換為HuggingFace格式,具體操作步驟如下。后續(xù)您可以使用轉(zhuǎn)換后的HuggingFace格式的模型進(jìn)行服務(wù)在線部署。
在Terminal中執(zhí)行以下命令,將訓(xùn)練生成的Megatron格式的模型轉(zhuǎn)換為HuggingFace格式的模型。
export WORK_DIR=/mnt/workspace cd /mnt/workspace/Pai-Megatron-Patch/toolkits/model_checkpoints_convertor/qwen sh model_convertor.sh \ ../../../Megatron-LM-main \ ${WORK_DIR}/output_megatron_qwen/checkpoint/${路徑}/iter_******* \ /mnt/workspace/qwen-ckpts/qwen-7b-mg-to-hf-tp1-pp1/ \ 1 \ 1 \ qwen-7b \ 0 \ true其中運(yùn)行model_convertor.sh腳本需要傳入的參數(shù)說(shuō)明如下:
參數(shù)
描述
MEGATRON_PATH=$1
設(shè)置開(kāi)源Megatron的代碼路徑。
SOURCE_CKPT_PATH=$2
配置為訓(xùn)練獲得的Megatron格式的模型路徑,具體到
iter_*。例如:${WORK_DIR}/output_megatron_qwen/checkpoint/dsw-pretrain-megatron-qwen-7B-lr-1e-5-bs-1-seqlen-2048-pr-bf16-tp-1-pp-1-ac-sel-do-true-sp-false-tt--wt-/iter_*******。重要請(qǐng)?zhí)鎿Q為您自己的模型路徑。
如果使用預(yù)訓(xùn)練模型進(jìn)行轉(zhuǎn)換,需要?jiǎng)h除模型路徑下所有的distrib_optim.pt文件。
TARGET_CKPT_PATH=$3
轉(zhuǎn)換為HuggingFace格式的模型后保存的路徑。
TP=$4
張量切片數(shù)量,與訓(xùn)練保持一致。
PP=$5
流水切片數(shù)量,與訓(xùn)練保持一致。
MN=$6
模型名稱(chēng):qwen-7b、qwen-14b或qwen-72b。
EXTRA_VOCAB_SIZE=$7
額外詞表大小。
mg2hf=$8
是否為Megatron格式轉(zhuǎn)HuggingFace格式。
將開(kāi)源HuggingFace模型文件夾路徑
/mnt/workspace/qwen-ckpts/qwen-7b-hf下的.json、.py和.tiktoken類(lèi)型的文件,拷貝至/mnt/workspace/qwen-ckpts/qwen-7b-mg-to-hf-tp1-pp1目錄下,以保證模型可以正常使用。重要請(qǐng)注意,無(wú)需復(fù)制pytorch_model.bin.index.json文件。
您可以使用HuggingFace & DeepSpeed格式的推理鏈路,對(duì)轉(zhuǎn)換后的HuggingFace格式的模型文件進(jìn)行離線推理。以Qwen-7B模型為例,在Terminal中的任意目錄下創(chuàng)建infer.py文件,文件內(nèi)容如下。執(zhí)行infer.py文件進(jìn)行模型離線推理,根據(jù)推理結(jié)果來(lái)評(píng)估模型效果。
#!/usr/bin/env python
#encoding=utf-8
from transformers import AutoTokenizer, LlamaTokenizer
from transformers import LlamaForCausalLM
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = '/mnt/workspace/qwen-ckpts/qwen-7b-mg-to-hf-tp1-pp1'
print(checkpoint)
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(checkpoint,device_map="auto", trust_remote_code=True)
prompts= '寫(xiě)一個(gè)快速排序算法'
p = f"Human:{prompts}"
print(p)
inputs = tokenizer.encode(p, return_tensors="pt").to(model.device)
outputs = model.generate(inputs,max_new_tokens=512)
print(tokenizer.decode(outputs[0]))其中checkpoint替換為轉(zhuǎn)換成HuggingFace格式模型文件所在的路徑。本案例配置為/mnt/workspace/qwen-ckpts/qwen-7b-mg-to-hf-tp1-pp1。
代碼執(zhí)行成功后,返回如下結(jié)果。
Setting ds_accelerator to cuda (auto detect)
/mnt/workspace/latest/qianwen/qwen-7b-hf
The model is automatically converting to bf16 for faster inference. If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to "AutoModelForCausalLM.from_pretrained".
Try importing flash-attention for faster inference...
Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary
Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:07<00:00, 3.78s/it]
Human:寫(xiě)一個(gè)快速排序算法
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:151643 for open-end generation.
Human:寫(xiě)一個(gè)快速排序算法的偽代碼吧!
Assistant:
好的,以下是快速排序算法的偽代碼實(shí)現(xiàn)示例,供您參考:
1. 選擇一個(gè)基準(zhǔn)元素 pivot,通常選擇第一個(gè)元素或者最后一個(gè)元素。將小于等于基準(zhǔn)元素的元素放在其左邊,大于基準(zhǔn)元素的元素放在其右邊。這個(gè)過(guò)程稱(chēng)為分區(qū) partition。 2. 對(duì)左右兩個(gè)分區(qū)遞歸地進(jìn)行快速排序。 3. 當(dāng)左右兩個(gè)分區(qū)的元素個(gè)數(shù)為0或1時(shí),排序完成。<|endoftext|>您可以參考以下鏈接了解更多關(guān)于推理的詳細(xì)內(nèi)容:
步驟六:部署及調(diào)用模型服務(wù)
完成離線推理并評(píng)估完成模型效果后,您可以將轉(zhuǎn)換為HuggingFace格式的模型部署為在線服務(wù),并在實(shí)際的生產(chǎn)環(huán)境中調(diào)用,從而進(jìn)行推理實(shí)踐。具體操作步驟如下:
部署模型服務(wù)
登錄PAI控制臺(tái),在頁(yè)面上方選擇目標(biāo)地域,并在右側(cè)選擇目標(biāo)工作空間,然后單擊進(jìn)入EAS。
單擊部署服務(wù),然后在自定義模型部署區(qū)域,單擊自定義部署。
在自定義部署頁(yè)面配置以下關(guān)鍵參數(shù),其他參數(shù)取默認(rèn)配置即可。
參數(shù)
描述
基本信息
服務(wù)名稱(chēng)
自定義模型服務(wù)名稱(chēng),同地域內(nèi)唯一。本方案配置為:test_qwen。
環(huán)境信息
部署方式
本方案選擇鏡像部署,并選中開(kāi)啟Web應(yīng)用。
鏡像配置
選擇鏡像地址,在本文框中配置鏡像地址
eas-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/pai-eas/chat-llm-webui:3.0.4-vllm。模型配置
選擇NAS類(lèi)型的掛載方式,并配置以下參數(shù):
選擇文件系統(tǒng):選擇創(chuàng)建數(shù)據(jù)集使用的NAS文件系統(tǒng)。
文件系統(tǒng)掛載點(diǎn):選擇創(chuàng)建數(shù)據(jù)集使用的掛載點(diǎn)。
文件系統(tǒng)路徑:配置為存放在NAS中的轉(zhuǎn)換后的HuggingFace格式模型的路徑。本方案配置為
/qwen-ckpts/qwen-7b-mg-to-hf-tp1-pp1。掛載路徑:指定掛載后的路徑,本方案配置為:
/qwen-7b。
運(yùn)行命令
配置為
python webui/webui_server.py --port=8000 --model-path=/qwen-7b --tensor-parallel-size 1 --backend=vllm。其中:
--model-path:需要與模型配置中的掛載路徑一致。
--tensor-parallel-size:模型張量切分的數(shù)量,需要根據(jù)GPU的卡數(shù)進(jìn)行調(diào)整。7B模型配置為1;72B模型配置為8(需要八卡實(shí)例)。
端口號(hào)
配置為:8000。
資源部署
資源類(lèi)型
本方案選擇資源配額。
資源配額
選擇已創(chuàng)建的靈駿智算資源的資源配額。
實(shí)例數(shù)
根據(jù)模型和選擇的資源情況進(jìn)行配置。以7b模型為例,實(shí)例數(shù)配置為1。
部署資源
以7b模型為例,每個(gè)實(shí)例使用的資源配置為:
CPU(核數(shù)):16。
內(nèi)存(GB):64。
GPU(卡數(shù)):1。
專(zhuān)有網(wǎng)絡(luò)
專(zhuān)有網(wǎng)絡(luò)(VPC)
配置好NAS掛載點(diǎn)后,系統(tǒng)將自動(dòng)匹配與預(yù)設(shè)的NAS文件系統(tǒng)一致的VPC、交換機(jī)和安全組。
交換機(jī)
安全組名稱(chēng)
單擊部署。
當(dāng)服務(wù)狀態(tài)變?yōu)?b data-tag="uicontrol" id="8ac5c8301bdn3" class="uicontrol">運(yùn)行中時(shí),表明服務(wù)部署成功。
調(diào)用服務(wù)
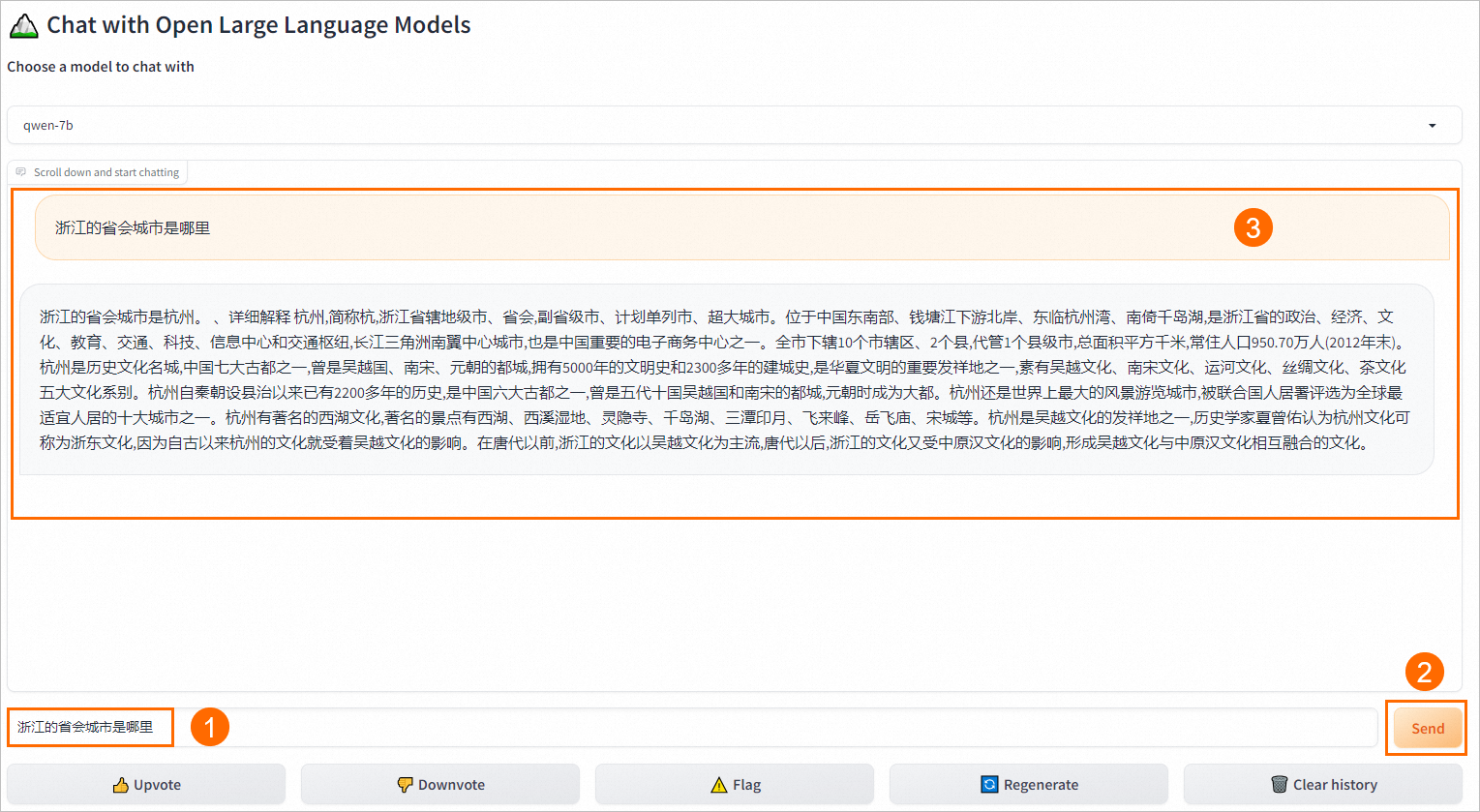
服務(wù)部署成功后,您可以調(diào)用服務(wù)進(jìn)行推理實(shí)踐,具體操作步驟如下:
在服務(wù)列表中,單擊目標(biāo)服務(wù)的服務(wù)方式列下的查看Web應(yīng)用。

在WebUI頁(yè)面中,進(jìn)行推理模型推理。