基于LLM的意圖識(shí)別解決方案
該解決方案基于大語(yǔ)言模型(LLM)的意圖識(shí)別技術(shù),能夠從海量的數(shù)據(jù)中學(xué)習(xí)到復(fù)雜的語(yǔ)言規(guī)律和用戶(hù)行為模式,實(shí)現(xiàn)對(duì)用戶(hù)意圖的更精準(zhǔn)識(shí)別和更自然流暢的交互體驗(yàn)。本方案以通義千問(wèn)1.5(Qwen1.5)大語(yǔ)言模型為基礎(chǔ),為您介紹基于LLM的意圖識(shí)別解決方案的完整開(kāi)發(fā)流程。
背景信息
什么是意圖識(shí)別
即AI智能體通過(guò)理解人們用自然語(yǔ)言所表達(dá)的需求,來(lái)執(zhí)行相應(yīng)的操作或提供相應(yīng)的信息,它是智能交互系統(tǒng)中不可或缺的一環(huán)。目前,基于大語(yǔ)言模型(LLM)的意圖識(shí)別技術(shù)已經(jīng)得到業(yè)界的廣泛關(guān)注,并被廣泛應(yīng)用。
意圖識(shí)別技術(shù)的典型場(chǎng)景示例
在智能語(yǔ)音助手領(lǐng)域,用戶(hù)通過(guò)簡(jiǎn)單的語(yǔ)音命令與語(yǔ)音助手進(jìn)行交互。例如,當(dāng)用戶(hù)對(duì)語(yǔ)音助手說(shuō)“我想聽(tīng)音樂(lè)”時(shí),系統(tǒng)需要準(zhǔn)確識(shí)別出用戶(hù)的需求是播放音樂(lè),然后執(zhí)行相應(yīng)操作。
在智能客服場(chǎng)景中,挑戰(zhàn)則體現(xiàn)在如何處理各種客戶(hù)服務(wù)請(qǐng)求,并將它們快速準(zhǔn)確地分類(lèi)至例如退貨、換貨、投訴等不同的處理流程中。例如,在電子商務(wù)平臺(tái)上,用戶(hù)可能會(huì)表達(dá)“我收到的商品有瑕疵,我想要退貨”。在這里,基于LLM的意圖識(shí)別系統(tǒng)要能夠迅速捕捉到用戶(hù)的意圖是“退貨”,并且自動(dòng)觸發(fā)退貨流程,進(jìn)一步引導(dǎo)用戶(hù)完成后續(xù)操作。
使用流程
基于LLM的意圖識(shí)別解決方案的使用流程如下:

您可以參照數(shù)據(jù)格式要求和數(shù)據(jù)準(zhǔn)備策略并針對(duì)特定的業(yè)務(wù)場(chǎng)景準(zhǔn)備相應(yīng)的訓(xùn)練數(shù)據(jù)集。您也可以參照數(shù)據(jù)準(zhǔn)備策略準(zhǔn)備業(yè)務(wù)數(shù)據(jù),然后通過(guò)智能標(biāo)注(iTAG)進(jìn)行原始數(shù)據(jù)標(biāo)注。導(dǎo)出標(biāo)注結(jié)果,并轉(zhuǎn)換為PAI-QuickStart支持的數(shù)據(jù)格式,用于后續(xù)的模型訓(xùn)練。
訓(xùn)練及離線(xiàn)評(píng)測(cè)模型
在快速開(kāi)始(QuickStart)中,基于Qwen1.5-1.8B-Chat模型進(jìn)行模型訓(xùn)練。模型訓(xùn)練完成后,對(duì)模型進(jìn)行離線(xiàn)評(píng)測(cè)。
當(dāng)模型評(píng)測(cè)結(jié)果符合您的預(yù)期后,通過(guò)快速開(kāi)始(QuickStart)將訓(xùn)練好的模型部署為EAS在線(xiàn)服務(wù)。
前提條件
在開(kāi)始執(zhí)行操作前,請(qǐng)確認(rèn)您已完成以下準(zhǔn)備工作:
已開(kāi)通PAI(DLC、EAS)后付費(fèi),并創(chuàng)建默認(rèn)工作空間,詳情請(qǐng)參見(jiàn)開(kāi)通PAI并創(chuàng)建默認(rèn)工作空間。
已創(chuàng)建OSS存儲(chǔ)空間(Bucket),用于存儲(chǔ)訓(xùn)練數(shù)據(jù)和訓(xùn)練獲得的模型文件。關(guān)于如何創(chuàng)建存儲(chǔ)空間,詳情請(qǐng)參見(jiàn)控制臺(tái)創(chuàng)建存儲(chǔ)空間。
準(zhǔn)備訓(xùn)練數(shù)據(jù)
支持使用以下兩種方式準(zhǔn)備訓(xùn)練數(shù)據(jù):
方式一:依據(jù)數(shù)據(jù)準(zhǔn)備策略和數(shù)據(jù)格式要求,自行完成訓(xùn)練數(shù)據(jù)集的構(gòu)建。
方式二:依據(jù)數(shù)據(jù)準(zhǔn)備策略,使用iTAG平臺(tái)進(jìn)行數(shù)據(jù)標(biāo)注。適用于大規(guī)模數(shù)據(jù)場(chǎng)景,顯著提升標(biāo)注效率。
數(shù)據(jù)準(zhǔn)備策略
為了提升訓(xùn)練的有效性和穩(wěn)定性,您可以參考以下策略準(zhǔn)備數(shù)據(jù):
對(duì)于單意圖識(shí)別場(chǎng)景,確保每類(lèi)意圖的標(biāo)注數(shù)量至少為50至100條,當(dāng)模型微調(diào)效果不佳時(shí),您可以考慮增加標(biāo)注數(shù)據(jù)量。同時(shí),您需要注意每類(lèi)意圖的標(biāo)注數(shù)據(jù)量盡量均衡,不宜出現(xiàn)某類(lèi)意圖的標(biāo)注數(shù)據(jù)量過(guò)多的情況。
對(duì)于多意圖識(shí)別場(chǎng)景或多輪對(duì)話(huà)場(chǎng)景,建議標(biāo)注數(shù)據(jù)量在單意圖識(shí)別場(chǎng)景數(shù)據(jù)量的20%以上,同時(shí)多意圖識(shí)別場(chǎng)景或多輪對(duì)話(huà)場(chǎng)景涉及的意圖需要在單意圖識(shí)別場(chǎng)景中出現(xiàn)過(guò)。
意圖描述需要覆蓋盡可能豐富的問(wèn)法和場(chǎng)景。
數(shù)據(jù)格式要求
訓(xùn)練數(shù)據(jù)格式要求為:JSON格式的文件,包含instruction和output兩個(gè)字段,分別對(duì)應(yīng)輸入的指令和模型預(yù)測(cè)的意圖以及對(duì)應(yīng)的關(guān)鍵參數(shù)。對(duì)于不同的意圖識(shí)別場(chǎng)景,相應(yīng)的訓(xùn)練數(shù)據(jù)示例如下:
對(duì)于單意圖識(shí)別場(chǎng)景,您需要針對(duì)特定的業(yè)務(wù)場(chǎng)景,準(zhǔn)備相應(yīng)的業(yè)務(wù)數(shù)據(jù),用于大語(yǔ)言模型(LLM)的微調(diào)訓(xùn)練。以智能家居的單輪對(duì)話(huà)為例,訓(xùn)練數(shù)據(jù)示例如下:
[ { "instruction": "我想聽(tīng)音樂(lè)", "output": "play_music()" }, { "instruction": "太吵了,把聲音開(kāi)小一點(diǎn)", "output": "volume_down()" }, { "instruction": "我不想聽(tīng)了,把歌關(guān)了吧", "output": "music_exit()" }, { "instruction": "我想去杭州玩,幫我查下天氣預(yù)報(bào)", "output": "weather_search(杭州)" }, ]對(duì)于多意圖識(shí)別場(chǎng)景或多輪對(duì)話(huà)場(chǎng)景,用戶(hù)的意圖可能會(huì)在多個(gè)對(duì)話(huà)輪次中表達(dá)。在這種情況下,您可以準(zhǔn)備多輪對(duì)話(huà)數(shù)據(jù),并對(duì)多輪用戶(hù)的輸入進(jìn)行標(biāo)注。以語(yǔ)音助手為例,給定一個(gè)多輪對(duì)話(huà)流:
User:我想聽(tīng)音樂(lè)。 Assistant:什么類(lèi)型的音樂(lè)? User:給我放個(gè)***的音樂(lè)吧。 Assistant:play_music(***)相應(yīng)的多輪對(duì)話(huà)訓(xùn)練數(shù)據(jù)格式如下:
[ { "instruction": "我想聽(tīng)音樂(lè)。給我放個(gè)***的音樂(lè)吧。", "output": "play_music(***)" } ]
由于多輪對(duì)話(huà)模型訓(xùn)練的長(zhǎng)度明顯提升,而且在實(shí)際應(yīng)用中,多輪對(duì)話(huà)意圖識(shí)別場(chǎng)景數(shù)量有限。建議您僅當(dāng)單輪對(duì)話(huà)的意圖識(shí)別無(wú)法滿(mǎn)足實(shí)際業(yè)務(wù)需求時(shí),考慮應(yīng)用多輪對(duì)話(huà)的模型訓(xùn)練方式。本方案將以單輪對(duì)話(huà)為例,為您展示該解決方案的整個(gè)使用流程。
使用iTAG平臺(tái)進(jìn)行數(shù)據(jù)標(biāo)注
您也可以參考以下操作步驟,使用PAI-iTAG平臺(tái)對(duì)數(shù)據(jù)進(jìn)行標(biāo)注,以生成滿(mǎn)足特定要求的訓(xùn)練數(shù)據(jù)集。
將用于iTAG標(biāo)注的數(shù)據(jù)注冊(cè)到PAI數(shù)據(jù)集。
參考數(shù)據(jù)準(zhǔn)備策略,準(zhǔn)備manifest格式的數(shù)據(jù)文件,內(nèi)容示例如下。
{"data":{"instruction": "我想聽(tīng)音樂(lè)"}} {"data":{"instruction": "太吵了,把聲音開(kāi)小一點(diǎn)"}} {"data":{"instruction": "我不想聽(tīng)了,把歌關(guān)了吧"}} {"data":{"instruction": "我想去杭州玩,幫我查下天氣預(yù)報(bào)"}}創(chuàng)建數(shù)據(jù)集,其中關(guān)鍵參數(shù)說(shuō)明如下,其他參數(shù)配置詳情,請(qǐng)參見(jiàn)創(chuàng)建及管理數(shù)據(jù)集。
參數(shù)
描述
選擇數(shù)據(jù)存儲(chǔ)
選擇阿里云對(duì)象存儲(chǔ)(OSS)。
屬性
選擇文件。
從阿里云云存儲(chǔ)創(chuàng)建
選擇已創(chuàng)建的OSS目錄,按照以下操作步驟上傳已準(zhǔn)備好的manifest文件:
在選擇OSS目錄對(duì)話(huà)框,單擊上傳文件。
單擊查看本地文件或拖拽上傳文件,根據(jù)提示上傳manifest文件。
在智能標(biāo)注iTAG頁(yè)面創(chuàng)建模板,其中關(guān)鍵配置說(shuō)明如下,其他配置詳情,請(qǐng)參見(jiàn)模板管理。
配置
描述
顯示內(nèi)容
將內(nèi)容組件下的文本組件拖拽到顯示內(nèi)容區(qū)域,然后單擊文本組件,并在配置面板中,將選擇文本內(nèi)容所在字段配置為instruction。
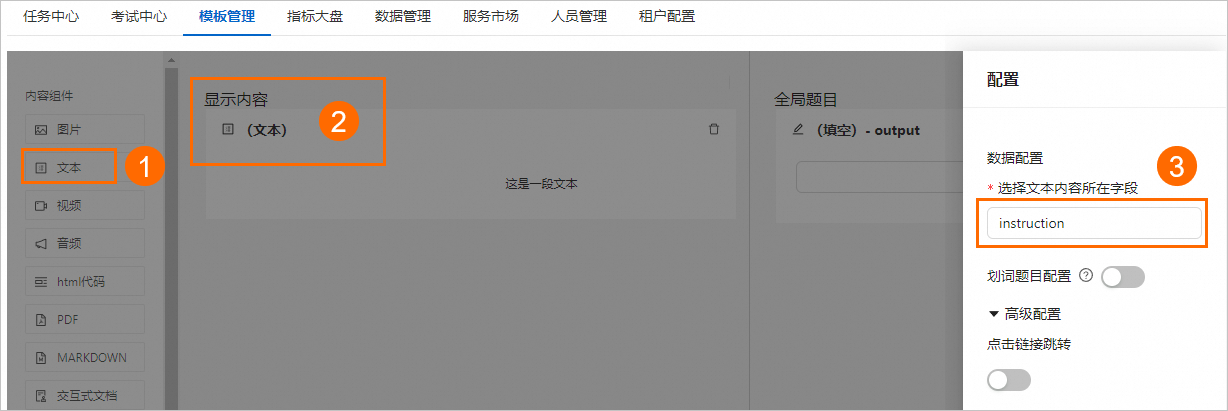
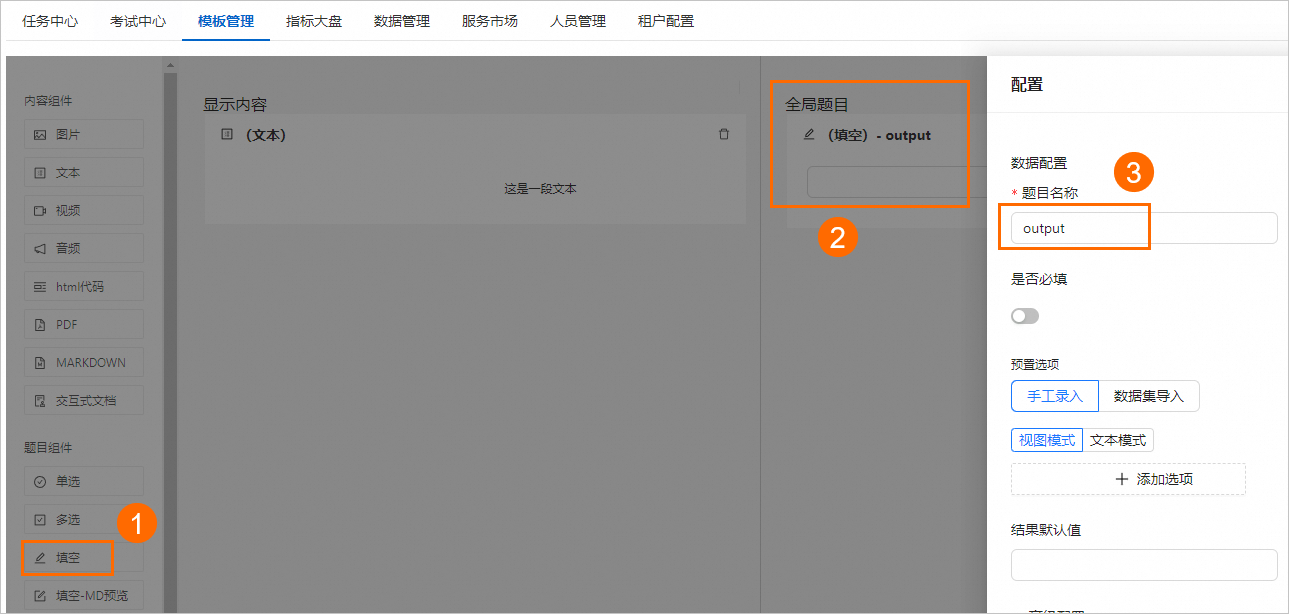
全局題目
將題目組件下的填空組件拖拽到全局題目區(qū)域,然后單擊填空組件,并在配置面板中,將題目名稱(chēng)設(shè)置為output。
創(chuàng)建標(biāo)注任務(wù),其中關(guān)鍵配置說(shuō)明如下,其他參數(shù)配置詳情,請(qǐng)參見(jiàn)創(chuàng)建標(biāo)注任務(wù)。
參數(shù)
描述
輸入數(shù)據(jù)集
選擇上述步驟已創(chuàng)建的數(shù)據(jù)集。
說(shuō)明請(qǐng)注意,輸入的數(shù)據(jù)和使用的模板對(duì)應(yīng)。
模板類(lèi)型
選擇自定義模板,并在已有模板下拉框中,選擇已創(chuàng)建的模板。
標(biāo)注任務(wù)創(chuàng)建完成后,開(kāi)始標(biāo)注數(shù)據(jù)。具體操作,請(qǐng)參見(jiàn)處理標(biāo)注任務(wù)。

完成數(shù)據(jù)標(biāo)注后,將標(biāo)注結(jié)果導(dǎo)出至OSS目錄中。具體操作,請(qǐng)參見(jiàn)導(dǎo)出標(biāo)注結(jié)果數(shù)據(jù)。
在本方案中,輸出的manifest文件的內(nèi)容示例如下,數(shù)據(jù)格式說(shuō)明,請(qǐng)參見(jiàn)標(biāo)注數(shù)據(jù)格式概述。
{"data":{"instruction":"我想聽(tīng)音樂(lè)","_itag_index":""},"label-1787402095227383808":{"results":[{"questionId":"2","data":"play_music()","markTitle":"output","type":"survey/value"}]},"abandonFlag":0,"abandonRemark":null} {"data":{"instruction":"太吵了,把聲音開(kāi)小一點(diǎn)","_itag_index":""},"label-1787402095227383808":{"results":[{"questionId":"2","data":"volume_down()","markTitle":"output","type":"survey/value"}]},"abandonFlag":0,"abandonRemark":null} {"data":{"instruction":"我不想聽(tīng)了,把歌關(guān)了吧","_itag_index":""},"label-1787402095227383808":{"results":[{"questionId":"2","data":"music_exit()","markTitle":"output","type":"survey/value"}]},"abandonFlag":0,"abandonRemark":null} {"data":{"instruction":"我想去杭州玩,幫我查下天氣預(yù)報(bào)","_itag_index":""},"label-1787402095227383808":{"results":[{"questionId":"2","data":"weather_search(杭州)","markTitle":"output","type":"survey/value"}]},"abandonFlag":0,"abandonRemark":null}在終端中,使用如下Python腳本,將上述生成的manifest格式的數(shù)據(jù)標(biāo)注結(jié)果文件,轉(zhuǎn)換為適用于快速開(kāi)始(QuickStart)的訓(xùn)練數(shù)據(jù)格式。
import json # 輸入文件路徑和輸出文件路徑。 input_file_path = 'test_json.manifest' output_file_path = 'train.json' converted_data = [] with open(input_file_path, 'r', encoding='utf-8') as file: for line in file: data = json.loads(line) instruction = data['data']['instruction'] for key in data.keys(): if key.startswith('label-'): output = data[key]['results'][0]['data'] converted_data.append({'instruction': instruction, 'output': output}) break with open(output_file_path, 'w', encoding='utf-8') as outfile: json.dump(converted_data, outfile, ensure_ascii=False, indent=4)輸出結(jié)果為JSON格式的文件。
訓(xùn)練及離線(xiàn)評(píng)測(cè)模型
訓(xùn)練模型
快速開(kāi)始(QuickStart)匯集了優(yōu)秀的AI開(kāi)源社區(qū)預(yù)訓(xùn)練模型。您可以在快速開(kāi)始(QuickStart)中,實(shí)現(xiàn)從訓(xùn)練到部署再至推理的完整流程,無(wú)需編寫(xiě)代碼,極大簡(jiǎn)化了模型的開(kāi)發(fā)過(guò)程。
本方案以Qwen1.5-1.8B-Chat模型為例,為您介紹如何使用已準(zhǔn)備好的訓(xùn)練數(shù)據(jù),在快速開(kāi)始(QuickStart)中進(jìn)行模型訓(xùn)練。具體操作步驟如下:
進(jìn)入Model Gallery頁(yè)面。
登錄PAI控制臺(tái)。
在頂部左上角根據(jù)實(shí)際情況選擇地域。
在左側(cè)導(dǎo)航欄選擇工作空間列表,單擊指定工作空間名稱(chēng),進(jìn)入對(duì)應(yīng)工作空間內(nèi)。
在左側(cè)導(dǎo)航欄選擇快速開(kāi)始 > Model Gallery。
在快速開(kāi)始頁(yè)面右側(cè)的模型列表中,單擊通義千問(wèn)1.5-1.8B-Chat模型卡片,進(jìn)入模型詳情頁(yè)面。
在模型詳情頁(yè)面,單擊右上角的微調(diào)訓(xùn)練。
在微調(diào)訓(xùn)練配置面板中,配置以下關(guān)鍵參數(shù),其他參數(shù)取默認(rèn)配置。
參數(shù)
描述
訓(xùn)練方式
訓(xùn)練方式
全參數(shù)微調(diào):資源要求高,訓(xùn)練時(shí)間長(zhǎng),效果一般更好。
說(shuō)明參數(shù)量較小的模型支持全參數(shù)微調(diào),請(qǐng)根據(jù)您的場(chǎng)景需要進(jìn)行選擇。
QLoRA:表示輕量化微調(diào)。相較于全參數(shù)微調(diào),資源要求更低,訓(xùn)練時(shí)間更短,效果一般會(huì)差一些。
LoRA:同QLoRA。
數(shù)據(jù)集配置
訓(xùn)練數(shù)據(jù)集
參照以下操作步驟,選擇已準(zhǔn)備好的訓(xùn)練數(shù)據(jù)集。
在下拉列表中選擇OSS文件或目錄。
單擊
 按鈕,選擇已創(chuàng)建的OSS目錄。
按鈕,選擇已創(chuàng)建的OSS目錄。在選擇OSS目錄或文件對(duì)話(huà)框中,單擊上傳文件,拖拽上傳已準(zhǔn)備好的訓(xùn)練數(shù)據(jù)集文件,并單擊確定。
訓(xùn)練輸出配置
model
選擇OSS目錄,用來(lái)存放訓(xùn)練輸出的配置文件。
超參數(shù)配置
關(guān)于超參數(shù)詳細(xì)介紹,請(qǐng)參見(jiàn)表1.全量超參數(shù)說(shuō)明。
建議您按照以下超參數(shù)配置策略進(jìn)行配置,針對(duì)不同的訓(xùn)練方式,關(guān)鍵超參數(shù)推薦配置,請(qǐng)參見(jiàn)表2.超參數(shù)推薦配置。
注意根據(jù)不同的訓(xùn)練方式配置超參數(shù)。
全局批次大小=卡數(shù)*per_device_train_batch_size*gradient_accumulation_steps為了最大化訓(xùn)練性能,優(yōu)先調(diào)大卡數(shù)和per_device_train_batch_size。
一般將全局批次大小設(shè)置為64至256,當(dāng)訓(xùn)練數(shù)據(jù)量很少時(shí),可以適當(dāng)調(diào)小。
序列長(zhǎng)度(seq_length)可以根據(jù)實(shí)際場(chǎng)景進(jìn)行調(diào)整。例如,數(shù)據(jù)集中本文序列最大長(zhǎng)度為50,則可以將序列長(zhǎng)度設(shè)置為64(一般設(shè)置為2的次冪數(shù))。
當(dāng)訓(xùn)練loss下降過(guò)慢或者不收斂時(shí),建議您適當(dāng)調(diào)大學(xué)習(xí)率(learning_rate)。同時(shí),需要確認(rèn)訓(xùn)練數(shù)據(jù)的數(shù)據(jù)質(zhì)量是否有保證。
參數(shù)
全參數(shù)微調(diào)
LoRA/QLoRA
learning_rate
5e-6、5e-5
3e-4
全局批次大小
256
256
seq_length
256
256
num_train_epochs
3
5
lora_dim
0
64
lora_alpha
0
16
load_in_4bit
False
True/False
load_in_8bit
False
True/False
單擊訓(xùn)練按鈕,在計(jì)費(fèi)提醒對(duì)話(huà)框中單擊確定。
系統(tǒng)自動(dòng)跳轉(zhuǎn)到訓(xùn)練任務(wù)詳情頁(yè)面,訓(xùn)練任務(wù)啟動(dòng)成功,您可以在該頁(yè)面查看訓(xùn)練任務(wù)狀態(tài)和訓(xùn)練日志。
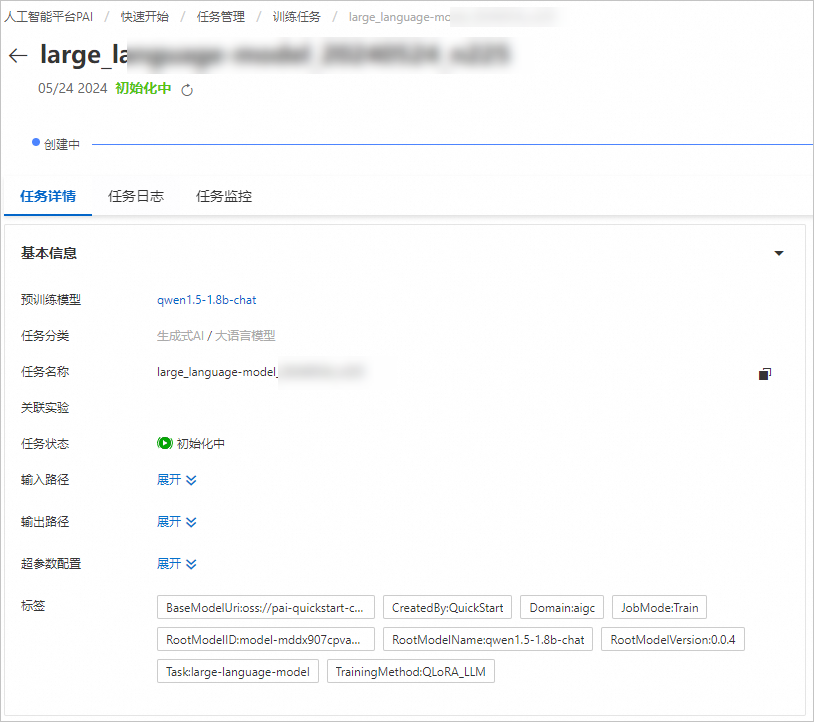
離線(xiàn)評(píng)測(cè)模型
當(dāng)模型訓(xùn)練結(jié)束后,您可以在終端使用Python腳本,來(lái)評(píng)測(cè)模型效果。
準(zhǔn)備評(píng)測(cè)數(shù)據(jù)文件testdata.json,內(nèi)容示例如下:
[ { "instruction": "想知道的十年是誰(shuí)唱的?", "output": "music_query_player(十年)" }, { "instruction": "今天北京的天氣怎么樣?", "output": "weather_search(杭州)" } ]在終端中,使用如下Python腳本來(lái)離線(xiàn)評(píng)測(cè)模型。
#encoding=utf-8 from transformers import AutoModelForCausalLM, AutoTokenizer import json from tqdm import tqdm device = "cuda" # the device to load the model onto # 修改模型路徑 model_name = '/mnt/workspace/model/qwen14b-lora-3e4-256-train/' print(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained(model_name) count = 0 ecount = 0 # 修改訓(xùn)練數(shù)據(jù)路徑 test_data = json.load(open('/mnt/workspace/data/testdata.json')) system_prompt = '你是一個(gè)意圖識(shí)別專(zhuān)家,可以根據(jù)用戶(hù)的問(wèn)題識(shí)別出意圖,并返回對(duì)應(yīng)的函數(shù)調(diào)用和參數(shù)。' for i in tqdm(test_data[:]): prompt = '<|im_start|>system\n' + system_prompt + '<|im_end|>\n<|im_start|>user\n' + i['instruction'] + '<|im_end|>\n<|im_start|>assistant\n' gold = i['output'] gold = gold.split(';')[0] if ';' in gold else gold model_inputs = tokenizer([prompt], return_tensors="pt").to(device) generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=64, pad_token_id=tokenizer.eos_token_id, eos_token_id=tokenizer.eos_token_id, do_sample=False ) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] pred = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] if gold.split('(')[0] == pred.split('(')[0]: count += 1 gold_list = set(gold.strip()[:-1].split('(')[1].split(',')) pred_list = set(pred.strip()[:-1].split('(')[1].split(',')) if gold_list == pred_list: ecount += 1 else: pass print("意圖識(shí)別準(zhǔn)確率:", count/len(test_data)) print("參數(shù)識(shí)別準(zhǔn)確率:", ecount/len(test_data))
部署及調(diào)用模型服務(wù)
部署模型服務(wù)
當(dāng)評(píng)測(cè)模型效果符合預(yù)期時(shí),您可以按照以下操作步驟,將訓(xùn)練獲得的模型部署為EAS在線(xiàn)服務(wù)。
在任務(wù)詳情頁(yè)面的模型部署區(qū)域,系統(tǒng)已默認(rèn)配置了模型服務(wù)信息和資源部署信息,您也可以根據(jù)需要進(jìn)行修改,參數(shù)配置完成后單擊部署按鈕。
在計(jì)費(fèi)提醒對(duì)話(huà)框中,單擊確定。
系統(tǒng)自動(dòng)跳轉(zhuǎn)到部署任務(wù)頁(yè)面,當(dāng)狀態(tài)為運(yùn)行中時(shí),表示服務(wù)部署成功。
在語(yǔ)音助手的意圖識(shí)別場(chǎng)景中,為了保證用戶(hù)的交互體驗(yàn),通常要求更高的延時(shí)。因此建議您使用PAI提供的BladeLLM推理引擎進(jìn)行LLM服務(wù)的部署,詳情請(qǐng)參見(jiàn)如何提升推理并發(fā)且降低延遲?。
調(diào)用模型服務(wù)
服務(wù)部署成功后,您可以在服務(wù)詳情頁(yè)面右側(cè),單擊查看WEB應(yīng)用,使用ChatLLM WebUI進(jìn)行實(shí)時(shí)交互,也可以使用API進(jìn)行模型推理。具體使用方法參考5分鐘使用EAS一鍵部署LLM大語(yǔ)言模型應(yīng)用。
以下提供一個(gè)示例,展示如何通過(guò)客戶(hù)端發(fā)起Request調(diào)用:
獲取服務(wù)訪(fǎng)問(wèn)地址和Token。
在服務(wù)詳情頁(yè)面,單擊資源信息區(qū)域的查看調(diào)用信息。

在調(diào)用信息對(duì)話(huà)框中,查詢(xún)服務(wù)訪(fǎng)問(wèn)地址和Token,并保存到本地。
在終端中,執(zhí)行如下代碼調(diào)用服務(wù)。
import argparse import json from typing import Iterable, List import requests def post_http_request(prompt: str, system_prompt: str, history: list, host: str, authorization: str, max_new_tokens: int = 2048, temperature: float = 0.95, top_k: int = 1, top_p: float = 0.8, langchain: bool = False, use_stream_chat: bool = False) -> requests.Response: headers = { "User-Agent": "Test Client", "Authorization": f"{authorization}" } pload = { "prompt": prompt, "system_prompt": system_prompt, "top_k": top_k, "top_p": top_p, "temperature": temperature, "max_new_tokens": max_new_tokens, "use_stream_chat": use_stream_chat, "history": history } response = requests.post(host, headers=headers, json=pload, stream=use_stream_chat) return response def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] history = data["history"] return output, history if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument("--top-k", type=int, default=4) parser.add_argument("--top-p", type=float, default=0.8) parser.add_argument("--max-new-tokens", type=int, default=2048) parser.add_argument("--temperature", type=float, default=0.95) parser.add_argument("--prompt", type=str, default="How can I get there?") parser.add_argument("--langchain", action="store_true") args = parser.parse_args() prompt = args.prompt top_k = args.top_k top_p = args.top_p use_stream_chat = False temperature = args.temperature langchain = args.langchain max_new_tokens = args.max_new_tokens host = "EAS服務(wù)公網(wǎng)地址" authorization = "EAS服務(wù)公網(wǎng)Token" print(f"Prompt: {prompt!r}\n", flush=True) # 在客戶(hù)端請(qǐng)求中可設(shè)置語(yǔ)言模型的system prompt。 system_prompt = "你是一個(gè)意圖識(shí)別專(zhuān)家,可以根據(jù)用戶(hù)的問(wèn)題識(shí)別出意圖,并返回對(duì)應(yīng)的意圖和參數(shù)" # 客戶(hù)端請(qǐng)求中可設(shè)置對(duì)話(huà)的歷史信息,客戶(hù)端維護(hù)當(dāng)前用戶(hù)的對(duì)話(huà)記錄,用于實(shí)現(xiàn)多輪對(duì)話(huà)。通常情況下可以使用上一輪對(duì)話(huà)返回的histroy信息,history格式為List[Tuple(str, str)]。 history = [] response = post_http_request( prompt, system_prompt, history, host, authorization, max_new_tokens, temperature, top_k, top_p, langchain=langchain, use_stream_chat=use_stream_chat) output, history = get_response(response) print(f" --- output: {output} \n --- history: {history}", flush=True) # 服務(wù)端返回JSON格式的響應(yīng)結(jié)果,包含推理結(jié)果與對(duì)話(huà)歷史。 def get_response(response: requests.Response) -> List[str]: data = json.loads(response.content) output = data["response"] history = data["history"] return output, history其中:
host:配置為已獲取的服務(wù)訪(fǎng)問(wèn)地址。
authorization:配置為已獲取的服務(wù)Token。
相關(guān)文檔
更多關(guān)于iTAG的使用流程以及標(biāo)注數(shù)據(jù)格式要求,請(qǐng)參見(jiàn)智能標(biāo)注(iTAG)。
更多關(guān)于EAS產(chǎn)品的內(nèi)容介紹,請(qǐng)參見(jiàn)模型在線(xiàn)服務(wù)(EAS)。
使用快速開(kāi)始(QuickStart)功能,您可以輕松完成更多場(chǎng)景的部署與微調(diào)任務(wù),包括Llama-3、Qwen1.5、Stable Diffusion V1.5等系列模型。詳情請(qǐng)參見(jiàn)場(chǎng)景實(shí)踐。