本文以Qwen系列大模型為例,介紹如何在人工智能平臺PAI上構建從訓練數據生成、模型微調訓練到服務部署和調用的NL2BI全鏈路解決方案。
背景信息
NL2SQL(自然語言生成SQL)技術旨在將自然語言轉換為數據庫查詢語句,使得即使不熟悉SQL的用戶也能輕松地從數據庫中提取數據進行分析,從而提高決策效率并深入挖掘數據背后的商業洞察(NL2BI)。
通過將NL2SQL與當前先進的大型語言模型相結合,可以顯著增強語義理解能力,并支持更復雜的SQL語法生成,實現更精準的SQL查詢和更流暢的數據提取分析體驗。
盡管如此,NL2BI的應用場景仍面臨諸多挑戰,例如LLM推理服務的高成本和對業務語義理解能力的不足。為了解決這些問題,通常需要在您自己的業務場景下,對LLM的NL2BI能力進行微調訓練。本方案的數據生產過程采用Qwen2-72B-Instruct大語言模型,模型微調采用CodeQwen1.5-7B-Chat模型。
使用流程
基于LLM的NL2BI全鏈路解決方案的使用流程如下:

您可以參照數據格式要求和數據準備策略,并針對特定的業務場景準備相應的訓練數據集。由于NL2SQL人工標注需要較大的工作量,您可以使用PAI-DLC及Qwen2-72B大模型進行批量數據生成,用于后續的模型訓練。
在快速開始中,基于CodeQwen1.5-7B-Chat模型進行訓練。
通過快速開始將訓練好的模型部署為EAS在線服務。
前提條件
在開始執行操作前,請確認您已完成以下準備工作:
已開通PAI(DLC、EAS)后付費,并創建默認工作空間,詳情請參見開通PAI并創建默認工作空間。
已創建OSS存儲空間(Bucket),用于存儲訓練數據和訓練獲得的模型文件。關于如何創建存儲空間,詳情請參見控制臺創建存儲空間。
如果您使用RDS數據庫,則需要配置包含公網訪問的專有網絡,進行數據庫連接用于生成SQL可執行性的驗證。如何創建專有網絡,請參見創建和管理專有網絡。如何配置公網訪問,請參見NAT網關。
使用限制
僅支持在華北6(烏蘭察布)地域,使用以下靈駿智算資源,基于PAI-DLC和Qwen2-72B大模型進行批量數據生成:
ml.gu7xf.8xlarge-gu108
ml.gu8xf.8xlarge-gu108
準備數據集
支持使用以下兩種方式準備訓練數據,本方案以方式二為例,為您介紹如何準備訓練數據:
方式二:基于PAI-DLC及Qwen2-72B大模型進行批量訓練數據生成。只需要少量示例數據和指定規則,就可進行批量數據生成,也可作為人工標注數據的補充,提升模型能力。
本方案提供了如下數據增廣示例的數據庫文件、示例問題文件和證據文件,用于快速跑通數據增廣流程。
數據準備策略
為了提升訓練的有效性和穩定性,您可以參考以下策略準備相關數據:
數據庫DDL優化
盡量減少表中存在歧義的字段,并對所有字段添加詳細的文本說明。
測試模型在處理最多3個表格、包含20列左右的場景時,準確率較優。
示例數據如下:
正確示例
CREATE TABLE `orders` ( `Row ID` int(11) DEFAULT NULL COMMENT '行的唯一標識符', `Order ID` varchar(14) DEFAULT NULL COMMENT '訂單的唯一標識符', `Order Date` date DEFAULT NULL COMMENT '下單日期', `Ship Date` date DEFAULT NULL COMMENT '發貨日期', `Ship Mode` varchar(15) DEFAULT NULL COMMENT '發貨方式', `Customer ID` varchar(8) DEFAULT NULL COMMENT '客戶的唯一標識符', `Customer Name` varchar(25) DEFAULT NULL COMMENT '客戶的名字', `Segment` varchar(15) DEFAULT NULL COMMENT '客戶所屬的市場細分', `Country` varchar(15) DEFAULT NULL COMMENT '訂單發貨國家的名稱', `City` varchar(17) DEFAULT NULL COMMENT '訂單發貨城市的名稱', `State` varchar(20) DEFAULT NULL COMMENT '訂單發貨州的名稱', `Postal Code` int(11) DEFAULT NULL COMMENT '發貨地址的郵政編碼', `Region` varchar(10) DEFAULT NULL COMMENT '訂單發貨的地區', `Product ID` varchar(15) DEFAULT NULL COMMENT '產品的唯一標識符', `Category` varchar(15) DEFAULT NULL COMMENT '產品的高級別類別', `Sub-Category` varchar(11) DEFAULT NULL COMMENT '產品的子類別', `Product Name` varchar(128) DEFAULT NULL COMMENT '產品的名稱', `Sales` double DEFAULT NULL COMMENT '訂單折扣后的總銷售額', `Quantity` int(11) DEFAULT NULL COMMENT '訂購的商品數量', `Discount` double DEFAULT NULL COMMENT '訂單的折扣', `Profit` double DEFAULT NULL COMMENT '訂單產生的利潤' ) ENGINE=InnoDB DEFAULT CHARSET=latin1;錯誤示例
CREATE TABLE `orders` ( `Row ID` int(11) DEFAULT NULL, `Order ID` varchar(14) DEFAULT NULL, `Order Date` date DEFAULT NULL, `Ship Date` date DEFAULT NULL, `Ship Mode` varchar(15) DEFAULT NULL, `Customer ID` varchar(8) DEFAULT NULL, `Customer Name` varchar(25) DEFAULT NULL, `Segment` varchar(15) DEFAULT NULL, `Country` varchar(15) DEFAULT NULL, `City` varchar(17) DEFAULT NULL, `State` varchar(20) DEFAULT NULL, `Postal Code` int(11) DEFAULT NULL, `Region` varchar(10) DEFAULT NULL, `Product ID` varchar(15) DEFAULT NULL, `Category` varchar(15) DEFAULT NULL, `Sub-Category` varchar(11) DEFAULT NULL, `Product Name` varchar(128) DEFAULT NULL, `Sales` double DEFAULT NULL, `Quantity` int(11) DEFAULT NULL, `Discount` double DEFAULT NULL, `Profit` double DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=latin1;訓練數據集問題盡量涵蓋所有實際使用字段,推薦數據集至少包含2000條數據,當模型微調效果不佳時,您可以考慮增加標注數據量。
問題描述需要盡可能豐富問法和場景。
數據格式要求
訓練數據接受JSON格式輸入,每條數據包括如下字段:
"id":序號。
"conversations":對話內容。包括"human"和"gpt"字段,分別表示用戶的問題和模型輸出。
"system":工具列表。包含該數據庫場景的DDL。
具體示例如下所示:
[
{
"id": 0,
"conversations": [
{
"from": "human",
"value": "返回“PVLDB”的主頁。\n"
},
{
"from": "gpt",
"value": "```sql\nSELECT homepage FROM journal WHERE name = \"PVLDB\"\n```\n"
}
],
"system": "你是一個sql助手,根據用戶的問題生成sql。給定以下數據庫信息:\n```sql\nCREATE TABLE IF NOT EXISTS author(\naid BIGINT COMMENT '作者ID',\nhomepage STRING COMMENT '作者主頁',\nname STRING COMMENT '作者名字',\noid BIGINT COMMENT '組織ID'\n);\nCREATE TABLE IF NOT EXISTS conference(\ncid BIGINT COMMENT '會議ID',\nhomepage STRING COMMENT '會議主頁',\nname STRING COMMENT '會議名稱'\n);\nCREATE TABLE IF NOT EXISTS domain(\ndid BIGINT COMMENT '領域ID',\nname STRING COMMENT '領域名稱'\n);\nCREATE TABLE IF NOT EXISTS domain_author(\naid BIGINT COMMENT '作者ID',\ndid BIGINT COMMENT '領域ID'\n);\nCREATE TABLE IF NOT EXISTS domain_conference(\ncid BIGINT COMMENT '會議ID',\ndid BIGINT COMMENT '領域ID'\n);\nCREATE TABLE IF NOT EXISTS journal(\nhomepage STRING COMMENT '期刊主頁',\njid BIGINT COMMENT '期刊ID',\nname STRING COMMENT '期刊名稱'\n);\nCREATE TABLE IF NOT EXISTS domain_journal(\ndid BIGINT COMMENT '領域ID',\njid BIGINT COMMENT '期刊ID'\n);\nCREATE TABLE IF NOT EXISTS keyword(\nkeyword STRING COMMENT '關鍵詞',\nkid BIGINT COMMENT '關鍵詞ID'\n);\nCREATE TABLE IF NOT EXISTS domain_keyword(\ndid BIGINT COMMENT '領域ID',\nkid BIGINT COMMENT '關鍵詞ID'\n);\nCREATE TABLE IF NOT EXISTS publication(\nabstract STRING COMMENT '摘要',\ncitation_num BIGINT COMMENT '引用數',\njid BIGINT COMMENT '期刊ID',\npid BIGINT COMMENT '論文ID',\nreference_num BIGINT COMMENT '參考論文數',\ntitle STRING COMMENT '論文標題',\nyear BIGINT COMMENT '年份'\n);\nCREATE TABLE IF NOT EXISTS domain_publication(\ndid BIGINT COMMENT '領域ID',\npid BIGINT COMMENT '論文ID'\n);\nCREATE TABLE IF NOT EXISTS organization(\ncontinent STRING COMMENT '作者所在大陸',\nhomepage STRING COMMENT '組織主頁',\noid BIGINT COMMENT '組織ID'\n);\nCREATE TABLE IF NOT EXISTS publication_keyword(\npid BIGINT COMMENT '論文ID',\nkid BIGINT COMMENT '關鍵詞ID'\n);\nCREATE TABLE IF NOT EXISTS writes(\naid BIGINT COMMENT '作者ID',\npid BIGINT COMMENT '論文ID'\n);\nCREATE TABLE IF NOT EXISTS cite(\ncited BIGINT COMMENT '被引用論文ID',\nciting BIGINT COMMENT '引用論文ID'\n);\n```\n"
}
]批量訓練數據生成
具體操作步驟如下:
創建云數據庫RDS實例和數據庫(本方案以RDS MySQL為例,您也可以使用自己的數據庫產品),用于生產SQL的可執行性驗證。具體操作,請參見RDS-MySQL使用流程。
配置MySQL數據庫,您需要盡量完善當前場景中的表字段說明。您可以在MySQL命令行中,執行如下命令快速導入數據庫文件(example_superstore.sql)。如何連接MySQL數據庫,請參見通過命令行、客戶端連接RDS MySQL實例。
create database superstore; use superstore; source example_superstore.sql;準備示例問題文件和證據文件。
示例問題文件(few_shot_example.json):包含query和columns兩個字段。其中:
query:代表與當前數據庫相關的示例問題。
columns:代表與該問題相關的列名。
準備3-5個示例問題,列名個數從易到難在1-3個之間,示例問題文件示例內容如下所示:
[ { "query": "總銷售額是多少", "columns": [ "Sales" ] }, { "query": "不同城市的銷售額是多少", "columns": [ "City", "Sales" ] }, { "query": "2016年每個月總銷售額是多少", "columns": [ "Order Date", "Sales" ] }, { "query": "2016年每個月總銷售額是多少,按發貨時間算, 并按地區統計", "columns": [ "Profit", "Ship Date", "Region" ] } ]證據文件(evidence_example.json):包含需要在生成數據prompt中進行描述的列名,其中包含如下三個字段:
table:列名所在的表名。
column:代表列名。
type:代表列名的類型。對于不同的type類型,在數據增廣prompt中會產生額外描述。type類型如下表所示:
type
說明
data_column
代表時間類型,指定后會產生該示例描述:這一列代表日期,日期的范圍是XXX到XXX。
enum_column
代表需要進行枚舉的類型,指定后會產生該示例描述:這一列的值是枚舉值,可以使用的枚舉值為[XXX, XXX, XXX]。
skip_column
表示與業務無關的列名,指定后不會生成與該列相關的問題。
證據文件示例內容如下所示:
[ { "table": "orders", "type": "date_column", "column": "Order Date" }, { "table": "orders", "type": "date_column", "column": "Ship Date" }, { "table": "orders", "type": "enum_column", "column": "Ship Mode" }, { "table": "orders", "type": "enum_column", "column": "Segment" }, { "table": "orders", "type": "enum_column", "column": "Region" }, { "table": "orders", "type": "enum_column", "column": "Country" }, { "table": "orders", "type": "enum_column", "column": "Sub-Category" }, { "table": "orders", "type": "enum_column", "column": "Category" }, { "table": "orders", "type": "skip_column", "column": "Row ID" } ]
將示例問題文件和證據文件上傳到已創建的OSS Bucket存儲空間,詳情請參見步驟三:上傳文件。文件上傳的示例路徑如下:
示例問題文件:oss://example-bucket/simplebi/few_shot_example.json
證據文件:oss://example-bucket/simplebi/evidence_example.json
使用PAI-DLC批量生產數據。
創建分布式訓練(DLC)任務,并配置以下關鍵參數,其他參數配置說明,請參見創建訓練任務。
參數
描述
基本信息
任務名稱
自定義配置任務名稱。
環境信息
節點鏡像
單擊鏡像地址,并在文本框中輸入鏡像
dsw-registry-vpc.<region>.cr.aliyuncs.com/pai-training-algorithm/llm_deepspeed_llamafactory:v0.0.3。其中<region>需要根據實際地域進行調整,例如華北6(烏蘭察布)配置為cn-wulanchabu。掛載配置
單擊添加,將示例問題文件和證據文件所在目錄掛載到訓練容器中。掛載類型選擇對象存儲(OSS),并配置以下參數:
OSS:選擇示例問題文件和證據文件所在的OSS路徑。例如oss://example-bucket/。
掛載路徑:配置為/mnt/data。
啟動命令
在代碼編輯框中配置如下啟動命令:
python -m simplebi.data_augmentation.data_generate \ --generate_number 10000 \ --processes_number 40 \ --fewshot_query_filepath /mnt/data/simplebi/few_shot_example.json \ --evidence_filepath /mnt/data/simplebi/evidence_example.json \ --output_filepath /mnt/data/simplebi/qwen2_72b_1000.json \ --host rm-******o.mysql.rds.aliyuncs.com \ --port 3306 \ --user Simple**** \ --database supers**** \ --passwd SimpleB**** \ --dtype bfloat16 \ --max_model_len 8192 \ --tensor_parallel_size 8 \ --query_temperature 0.8 \ --sql_temperature 0.2 \ --max_tokens 1024參數配置說明,請參見啟動參數說明。
資源信息
資源類型
選擇靈駿智算。
資源來源
選擇競價資源。
任務資源
單擊
 選擇資源規格:ml.gu7xf.8xlarge-gu108或ml.gu8xf.8xlarge-gu108,并配置最高出價。
選擇資源規格:ml.gu7xf.8xlarge-gu108或ml.gu8xf.8xlarge-gu108,并配置最高出價。專有網絡配置
專有網絡配置(ID)
選擇已配置公網訪問的VPC網絡。如何配置公網訪問,請參見NAT網關。
交換機
安全組
選擇安全組。
參數
描述
generate_number
生成的問題和SQL對條數。
processes_number
同時進行數據生成進程數。
fewshot_query_filepath
示例問題文件掛載到容器中的路徑。例如:/mnt/data/simplebi/few_shot_example.json。
evidence_filepath
證據文件掛載到容器中的路徑。例如:/mnt/data/simplebi/evidence_example.json
output_filepath
生成數據文件路徑,同時會生成_llamafactory后綴的JSON文件,該文件可直接用于后續訓練。
host
RDS數據庫的公網地址。如何獲取,請參見通過客戶端、命令行連接RDS MySQL實例。
port
RDS數據庫的連接端口。如何獲取,請參見通過客戶端、命令行連接RDS MySQL實例。
user
RDS數據庫的連接用戶名。如何獲取,請參見通過客戶端、命令行連接RDS MySQL實例。
database
RDS數據庫的連接數據庫名稱。
passwd
RDS數據庫的連接密碼。如何獲取,請參見通過客戶端、命令行連接RDS MySQL實例。
tensor_parallel_size
模型張量并行大小。
query_temperature
生成問題時使用的采樣溫度。
sql_temperature
生成SQL時使用的采樣溫度。
max_tokens
最大生成長度。
訓練模型
快速開始匯集了優秀的國內外AI開源社區預訓練模型。您可以在快速開始>Model Gallery中,實現從訓練到部署再至推理的完整流程,無需編寫代碼,極大簡化了模型的開發過程。
本方案以CodeQwen1.5-7b-NL2SQL模型為例,為您介紹如何使用已準備好的訓練數據,在快速開始中進行模型訓練。具體操作步驟如下:
進入Model Gallery頁面。
登錄PAI控制臺。
在頂部左上角根據實際情況選擇地域。
在左側導航欄選擇工作空間列表,單擊指定工作空間名稱,進入對應工作空間內。
在左側導航欄選擇。
在Model Gallery頁面右側的模型列表中,搜索并單擊CodeQwen1.5-7b-NL2SQL模型卡片,進入模型詳情頁面。
在模型詳情頁面,單擊右上角的微調訓練,并在微調訓練配置面板中,配置以下關鍵參數。
參數
描述
訓練方式
支持以下兩種訓練方式,具體說明如下:
QLoRA:QLoRA訓練屬于高效訓練的一種,會在固定并量化模型本身參數的基礎上,僅對自注意力權重矩陣進行低秩分解,并更新低秩矩陣參數。該訓練方法訓練時間短,但效果可能會略差于LoRA。
LoRA:LoRA訓練屬于高效訓練的一種,會在固定模型本身參數的基礎上,僅對自注意力權重矩陣進行低秩分解,并更新低秩矩陣參數。
數據集配置
訓練數據集
參照以下操作步驟,選擇已準備好的訓練數據集。
在下拉列表中選擇OSS文件或目錄。
單擊
 按鈕,選擇已創建的OSS目錄。
按鈕,選擇已創建的OSS目錄。在選擇OSS文件對話框中,單擊上傳文件,拖拽上傳已準備好的訓練數據集文件(示例文件:qwen2_72b_10000_llamafactory.json),并單擊確定。
說明如果出現“數據解析失敗,請檢查文件內容格式”字樣,請忽略,不影響您執行后續操作。
訓練輸出配置
模型名稱
注冊到AI資產管理>模型中的模型名稱。按照控制臺界面提示自定義配置。
模型輸出路徑
選擇OSS目錄,用來存放訓練輸出的配置文件。
計算資源配置
資源組類型
選擇公共資源組(按量付費)。
任務資源
系統已默認配置了資源規格,您也可以根據需要進行修改:
當訓練方式選擇QLoRA時:最低使用V100/P100/T4(16 GB顯存)及以上卡型。
當訓練方式選擇LoRA時:最低使用V100(32 GB顯存)/A10及以上卡型。
超參數配置
訓練算法支持的超參信息,請參見表1.全量超參數說明。針對不同的訓練方式,關鍵超參數推薦配置,請參見表2.超參數推薦配置。
超參數
類型
是否必選
含義
默認值
learning_rate
FLOAT
是
學習率,用于控制模型權重調整幅度。
3e-4
num_train_epochs
INT
是
訓練數據集被重復使用的次數。
1
per_device_train_batch_size
INT
是
每個GPU在一次訓練迭代中處理的樣本數量。較大的批次大小可以提高效率,也會增加顯存的需求。
1
seq_length
INT
是
序列長度,指模型在一次訓練中處理的輸入數據的長度。
1024
lora_dim
INT
否
LoRA維度,當lora_dim>0時,使用LoRA或QLoRA輕量化訓練。
64
lora_alpha
INT
否
LoRA權重,當lora_dim>0時,使用LoRA或QLoRA輕量化訓練,該參數生效。
32
load_in_4bit
BOOL
是
模型是否以4 bit加載。
當lora_dim>0、load_in_4bit為true且load_in_8bit為false時,使用4 bit QLoRA輕量化訓練。
true
load_in_8bit
BOOL
是
模型是否以8比特加載。
當lora_dim>0、load_in_4bit為false且load_in_8bit為true時,使用8 bit QLoRA輕量化訓練。
false
gradient_accumulation_steps
INT
是
梯度累積步驟數。
8
template
STRING
是
模型使用的prompt拼接模板,該示例使用qwen模板。
qwen
參數配置完成后,單擊訓練,然后在計費提醒對話框中,單擊確定。
系統自動跳轉到訓練任務詳情頁面,訓練任務啟動成功,您可以在該頁面查看訓練任務狀態和任務日志。
部署及調用模型服務
部署模型服務
模型訓練成功后,即可部署模型服務。PAI預置了模型的部署配置信息,您僅需提供推理服務的名稱以及部署配置使用的資源信息,即可將訓練獲得的模型部署到模型在線服務(EAS)平臺。具體操作步驟如下:
在任務詳情頁面,單擊右上角的部署。
在部署配置面板中,系統已默認配置了模型服務信息和資源部署信息,您也可以根據需要進行修改,參數配置完成后,單擊部署。
在計費提醒對話框中,單擊確定。
系統將自動跳轉到部署任務頁面,當狀態為運行中時,表示服務部署成功。
調用模型服務
當模型服務部署成功后,您可以按照以下操作步驟調用模型服務:
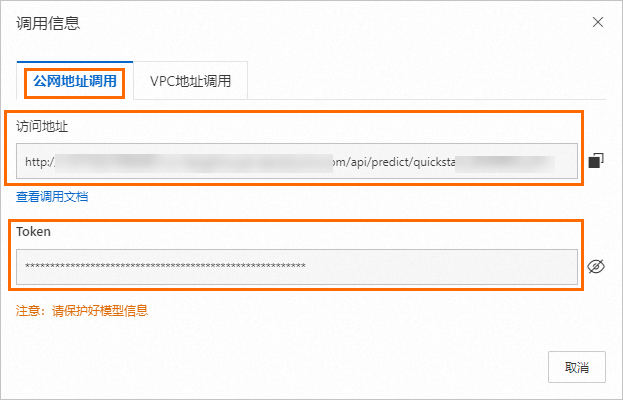
查詢服務訪問地址和Token。
在部署任務頁面,單擊服務名稱,進入服務詳情頁面。
在基本信息區域,單擊查看調用信息。
在調用信息對話框的公網地址調用頁簽,查看訪問地址和Token。
本方案是API方式的模型服務部署,您可以在終端中執行如下Python代碼,使用OpenAPI的SDK調用模型服務。
from openai import OpenAI client = OpenAI( base_url="<eas_service_path>/v1", api_key="<eas_service_token>", ) chat_completion = client.chat.completions.create( model="/model_dir", messages=[ {"role": "system", "content": "你是一個sql助手,根據用戶的問題生成sql,參考如下ddl:\nCREATE TABLE `orders` (\n `Row ID` int DEFAULT NULL COMMENT '行的唯一標識符',\n `Order ID` varchar(14) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '訂單的唯一標識符',\n `Order Date` date DEFAULT NULL COMMENT '下單日期',\n `Ship Date` date DEFAULT NULL COMMENT '發貨日期',\n `Ship Mode` varchar(15) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '發貨方式',\n `Customer ID` varchar(8) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '客戶的唯一標識符',\n `Customer Name` varchar(25) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '客戶的名字',\n `Segment` varchar(15) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '客戶所屬的市場細分',\n `Country` varchar(15) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '客戶所在國家的名稱',\n `City` varchar(17) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '客戶所在城市的名稱',\n `State` varchar(20) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '客戶所在州的名稱',\n `Postal Code` int DEFAULT NULL COMMENT '客戶地址的郵政編碼',\n `Region` varchar(10) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '客戶所在的地區',\n `Product ID` varchar(15) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '產品的唯一標識符',\n `Category` varchar(15) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '產品的高級別類別',\n `Sub-Category` varchar(11) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '產品的子類別',\n `Product Name` varchar(128) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '產品的名稱',\n `Sales` double DEFAULT NULL COMMENT '訂單折扣后的總銷售額',\n `Quantity` int DEFAULT NULL COMMENT '訂購的商品數量',\n `Discount` double DEFAULT NULL COMMENT '訂單的折扣',\n `Profit` double DEFAULT NULL COMMENT '訂單產生的利潤'\n) ENGINE=InnoDB DEFAULT CHARSET=latin1\nCREATE TABLE `people` (\n `Person` varchar(20) DEFAULT NULL,\n `Region` varchar(10) DEFAULT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1\nCREATE TABLE `returns` (\n `Returned` varchar(3) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '訂單是否被退單',\n `Order ID` varchar(15) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL COMMENT '訂單的唯一標識符'\n) ENGINE=InnoDB DEFAULT CHARSET=latin1,回答sql查詢問題"}, {"role": "user", "content": "在2016年,每個月各類產品的訂單數量是多少?"} ], ) print(chat_completion.choices)其中:
<eas_service_path>:替換為上述步驟已查詢的服務訪問地址。
<eas_service_token>:替換為上述步驟已查詢的服務Token。
調用成功后,返回結果示例如下,您的結果以實際為準:
[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content="在2016年,我們可以通過以下SQL查詢獲取每個月各類產品的訂單數量:\n\n```sql\nSELECT \n DATE_FORMAT(`Order Date`, '%Y-%m') AS YearMonth,\n `Category`,\n COUNT(*) AS OrderCount\nFROM \n orders\nWHERE \n YEAR(`Order Date`) = 2016\nGROUP BY \n YearMonth,\n `Category`;\n```\n\n這個查詢首先通過DATE_FORMAT函數將訂單日期格式化為年月(YYYY-MM),然后按照年月和類別進行分組,最后計算每個月各類產品的訂單數量。", role='assistant', function_call=None, tool_calls=None), stop_reason=None)]服務調用成功后,您可在終端中執行如下Python代碼,基于RDS-MySQL驗證模型生成SQL。
import re import pymysql def parse(text): pattern = r"```sql\n(.*?)\n```" matches = re.findall(pattern, text, re.DOTALL) if matches: sql_content = matches[0].strip() if not sql_content.endswith(";"): sql_content += ";" return sql_content else: if not text.endswith(";"): text += ";" return text def excute_sql(input_text: str) -> tuple: sql = parse(input_text) cursor = db.cursor() try: cursor.execute(sql) col = cursor.description sql_data = cursor.fetchall() return sql_data except Exception as e: return "error" db = pymysql.connect( host="數據庫連接", user="數據庫用戶名", passwd="數據庫密碼", port=3306, db="數據庫名稱", ) print( excute_sql( "填寫模型輸出文本" ) )其中關鍵配置說明如下:
關鍵配置
描述
host
配置為RDS數據庫的公網地址。
user
配置為RDS數據庫的連接用戶名。
passwd
配置為RDS數據庫的連接密碼。
port
配置為RDS數據庫的連接端口。
db
配置為RDS數據庫的連接數據庫名稱。
excute_sql
將文本內容配置為步驟2調用服務返回結果中的content字段內容。