本文介紹如何使用PAI提供的LLM大語言模型數據處理組件、訓練組件和推理組件,端到端完成大模型的開發(fā)和使用。
前提條件
已創(chuàng)建工作空間,詳情請參見創(chuàng)建工作空間。
已將MaxCompute資源和通用計算資源關聯到工作空間,詳情請參見管理工作空間。
數據集
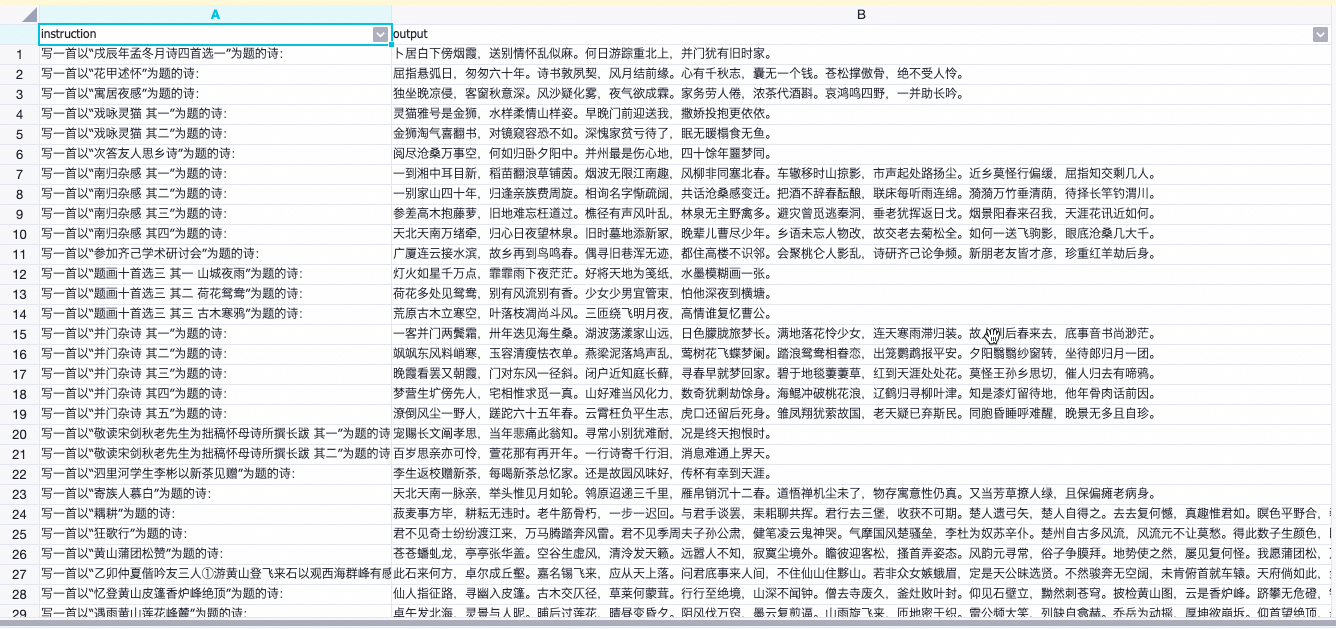
輸入的訓練數據需遵循問答對格式,包含以下兩個字段:
instruction:問題字段。
output:答案字段。
示例如下:
如果您的數據字段名不符合要求,可以提前通過自定義SQL腳本等方式進行預處理。如果您的數據直接來自互聯網,可能存在數據冗余或臟數據,可以利用LLM數據預處理組件進行初步清洗和整理。具體操作,請參見LLM數據處理。
使用流程
進入Designer頁面。
登錄PAI控制臺。
在左側導航欄單擊工作空間列表,在工作空間列表頁面中單擊待操作的工作空間名稱,進入對應工作空間內。
在工作空間頁面的左側導航欄選擇,進入Designer頁面。
構建工作流。
在Designer頁面,單擊預置模板頁簽。
在LLM大語言模型頁簽的LLM大語言模型端到端鏈路:數據處理+模型訓練+模型推理區(qū)域中,單擊創(chuàng)建。
在新建工作流對話框中,配置參數(可以全部使用默認參數),然后單擊確定。
其中:工作流數據存儲配置為OSS Bucket路徑,用于存儲工作流運行中產出的臨時數據和模型。
在工作流列表中,雙擊目標工作流,進入工作流。
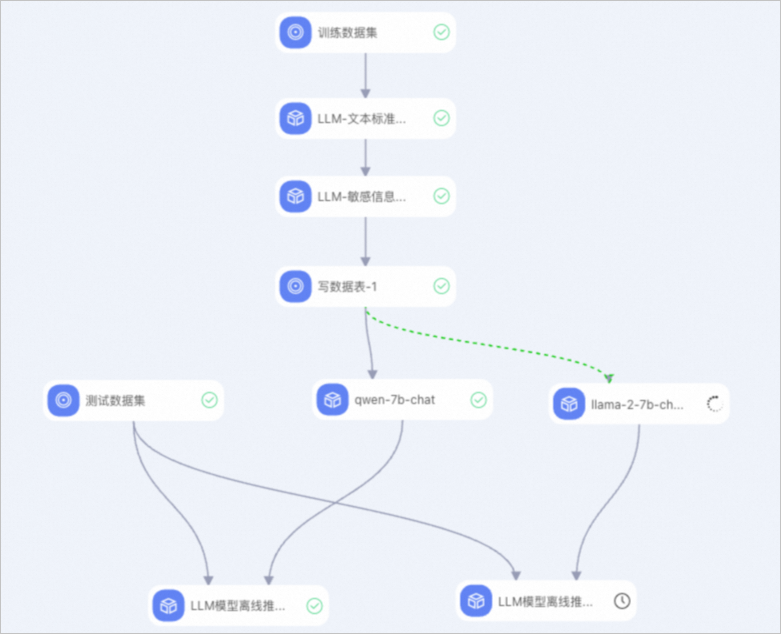
系統根據預置的模板,自動構建工作流,如下圖所示。
區(qū)域
描述
①
進行簡單的數據預處理,僅供端到端鏈路演示使用。更詳細的數據預處理流程,請參見LLM數據處理。
②
進行模型訓練和離線推理。其中:
LLM模型訓練組件
該組件封裝了快速開始(QuickStart)提供的LLM模型,底層計算基于DLC容器任務。單擊該組件,在右側的字段設置頁簽可以選擇模型名稱。該組件支持多種主流的LLM模型,在本工作流程中,選擇使用qwen-7b-chat模型進行示例訓練。
LLM模型離線推理組件
使用該組件進行離線推理。在本工作流程中,選擇使用qwen-7b-chat模型進行離線批量推理。
單擊畫布上方的運行按鈕
 ,運行工作流。
,運行工作流。工作流成功運行后,右鍵單擊LLM模型離線推理-1組件,在快捷菜單中選擇,查看推理結果。
后續(xù)步驟
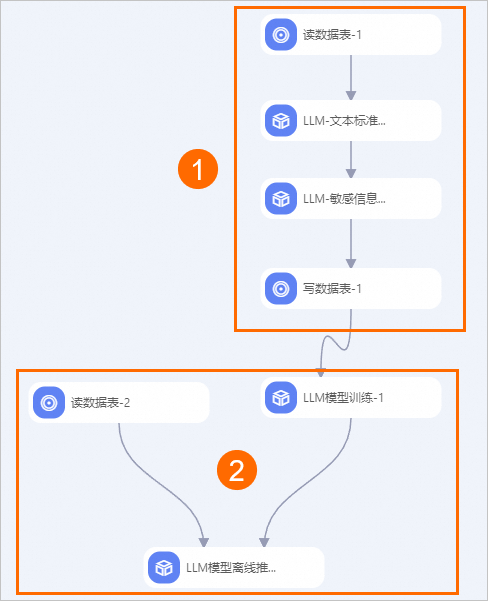
您還可以使用經過相同預處理的數據,同時針對多個模型進行訓練和推理。例如,構建如下工作流來并行地對qwen-7b-chat和llama2-7b-chat兩個模型進行微調,然后使用同一批測試數據來比較它們推理后生成的結果。