教育搜題業務特點
海量題庫且持續增長,數據庫壓力大;
存在高峰時段集中,用戶搜索并發量大,搜索延遲直接影響用戶體驗;
覆蓋不同階段學習、用戶場景越來越豐富;
學科分類眾多,數據越來越復雜,搜索存在跨學科錯誤;
需要強大的算法算力支撐,提升搜題準確性;
依賴多模態搜索能力來解決圖文搜索需求
依賴多語言處理能力來處理英語等其他語言搜題需求
阿里云開放搜索教育行業最佳實踐
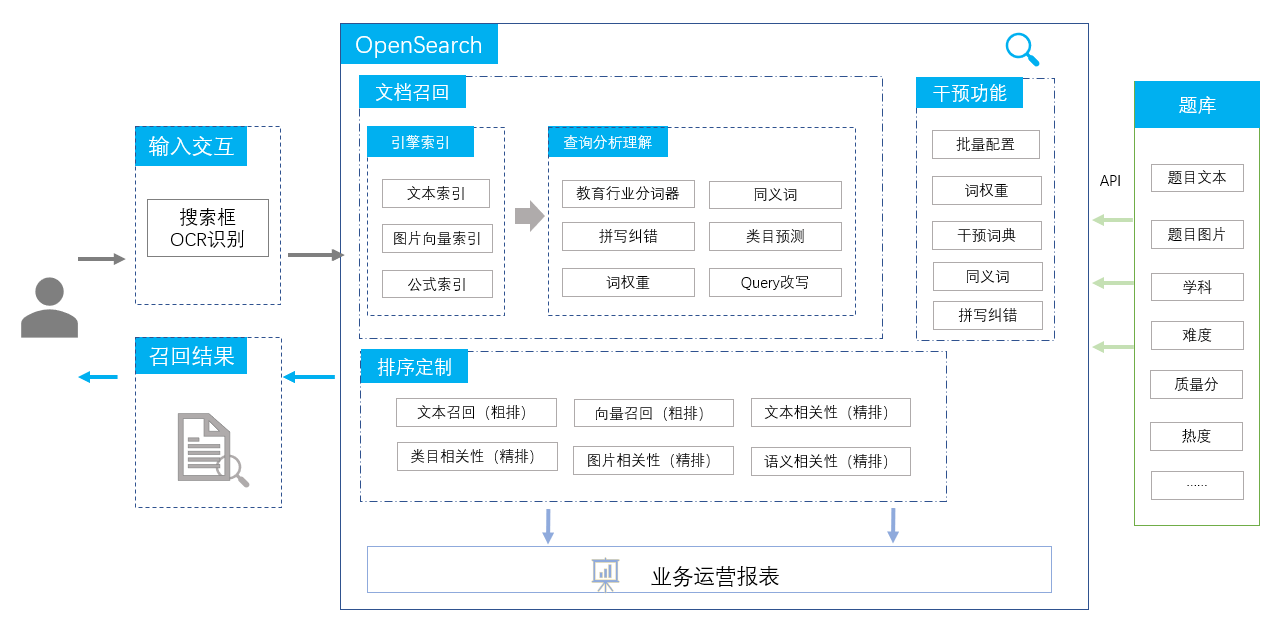
教育搜題行業專屬的教育分詞器
query處理流程:

2. 查詢語義理解:
分詞是影響搜索效果的最基礎的模塊。開放搜索集成了教育搜題行業專屬的教育分詞器,同時在此基礎之上用戶還可上傳自己的分詞詞條定制個性化的分詞器。
示例
Query
下面三角形的面積是多少平方厘采?
拼寫糾錯
下面三角形的面積是多少平方厘米?
學科類目預測
數學
分詞
下面 三角形 的 面積 是 多少 平方 厘米 ?
詞權重
1 7 1 7 1 4 7 7 1
同義詞改寫
平方 厘米 -> (cm ^ 2)
文本向量化
-0.100582,-0.0540699,-0.0417337,0.0602,...
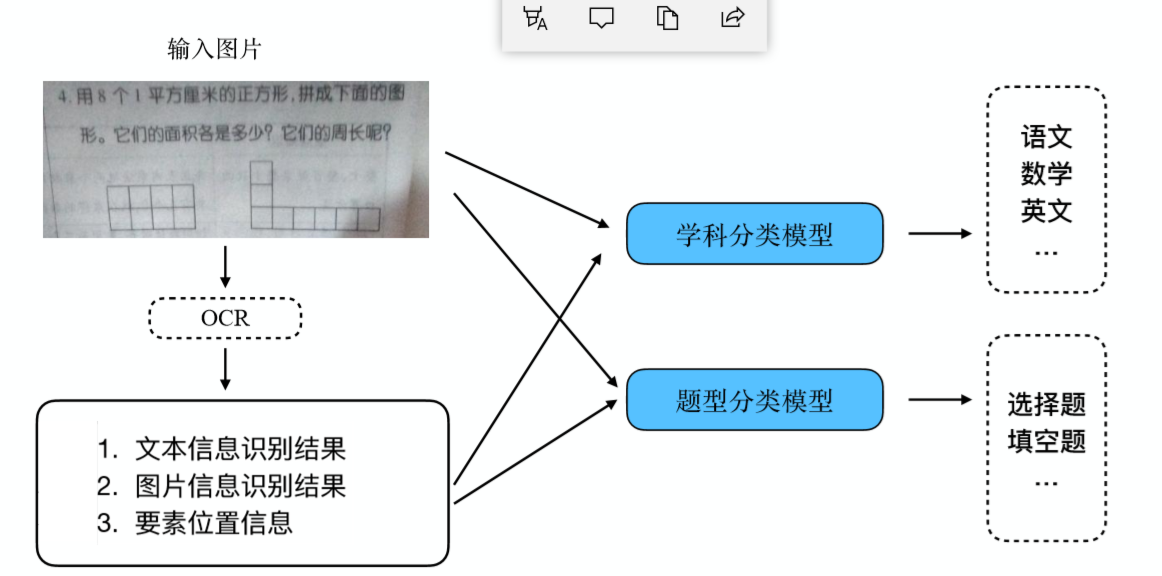
3. 類目預測:
什么是類目預測?
簡單來說,用戶輸入一個query,查詢得到一批物品,通過計算每一個物品所屬的類目與query之間的相關度,只要物品的排序公式中引用了這個相關度,那么對于這個物品來說,它所屬的類目與query的相關度越高,它的排序公式的計算結果就獲得了越高的排序得分,從而這個物品就會排在越前面。
類目預測在教育行業的應用:
結合輸?的圖?信息和OCR識別之后的結果預測輸?題?的學科類別、題目類型;
預測各?本?段的字段類型(題干描述、選項等等);
4. 詞權重分析:
功能介紹:該功能主要分析了查詢中每一個詞在文本中的重要程度,并將其量化成權重,權重較低的詞可能不會參與召回。這樣可以避免當用戶輸入的查詢詞中包含一些權重低的詞時,仍然按用戶輸入的查詢詞限制召回,導致命中結果過少。
功能用途: Query丟詞、改寫、文本相關性分析;
1)基于用戶行為生成訓練數據:

2)詞權重模型訓練:
序列標注模型 ;
預測標簽(7,4,1), 分值越?表?term的重要性越?,召回結果更準確;
示例:
query | 35 的 因數有 ( ) , 100 以內 24 的 倍數有 ( ) |
對應權重分 | 4 1 71 1 1 1 1 1 4 1 7 1 1 1 |
此題目中“因數”和“倍數”的權重分最高7分,參與召回的權重也就最高,其次是“35”和“24”為4分,其他權重分為1分的,不參與召回;
5. query改寫:
為了滿足業務的靈活需求,開放搜索支持批量干預:詞典、拼寫糾錯,同義詞,詞權重等。
示例
1)OCR識別可能會把一些非題目要素識別進來干擾query分析的結果,這時候可以使用詞權重干預的方式保證非題目要素字段被打標成低權重,保證召回和排序效果
2)用戶可以自定義同義詞來擴召回,例如"立方米" -> "噸"
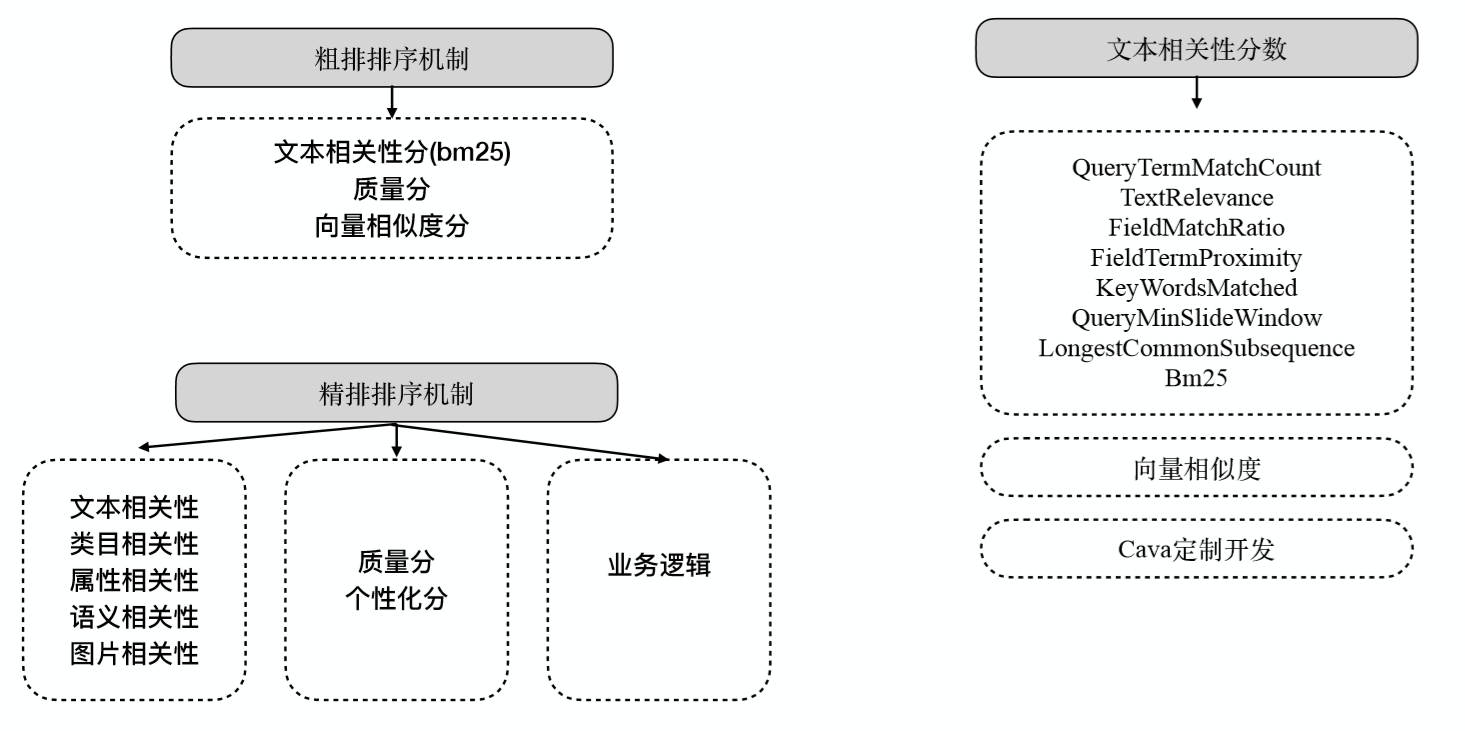
排序定制
系統開放了兩階段排序過程:基礎排序和業務排序,即粗排和精排;基礎排序即是海選,從檢索結果中快速找到質量高的文檔,取出TOP N個結果再按照精排進行精細算分,最終返回最優的結果給用戶。為了實現更細粒度的排序效果,結合排序表達式(Ranking Formula)可以為應用自定義搜索結果排序方式。
,
客戶效果對比
某在線教育平臺,主打K12教育,用戶數千萬級別,題庫量8千萬左右且持續增加,由自建題庫和第三方題庫兩部分組成,之前通過OCR+自建ES搜索服務實現拍照搜索功能,面臨的主要問題是搜索準確率待優化提升,降低搜索延遲等問題。
開放搜索接入后:
搜題準確率絕對值提升5%;
延時從100ms-300ms降到穩定50ms;
離線數據同步大于4000TPS
搜題Query:"張慧研所指與小磁大概相近的是樂府之音"
級別 | 舊版自建召回結果 | 開放搜索召回結果 |
top1 | 某歌舞團獨唱演員張慧月工資RMB 5,800,2006年6月,張慧參加了該團在上海的3場演出,得到RMB 3800元報酬... | 張惠言所指與“小詞”大概相近的是樂府之音。 |
top2 | 張慧研對音樂的喜好源于... | 張惠言所指與“小詞”大概相近的是樂府之音。() |
top3 | 下列文獻中,屬于張慧老師在中國音樂期刊上發表文章的引證文獻是 | 下列選項中屬于張惠言所指與“小詞”大概相近的是()。 |
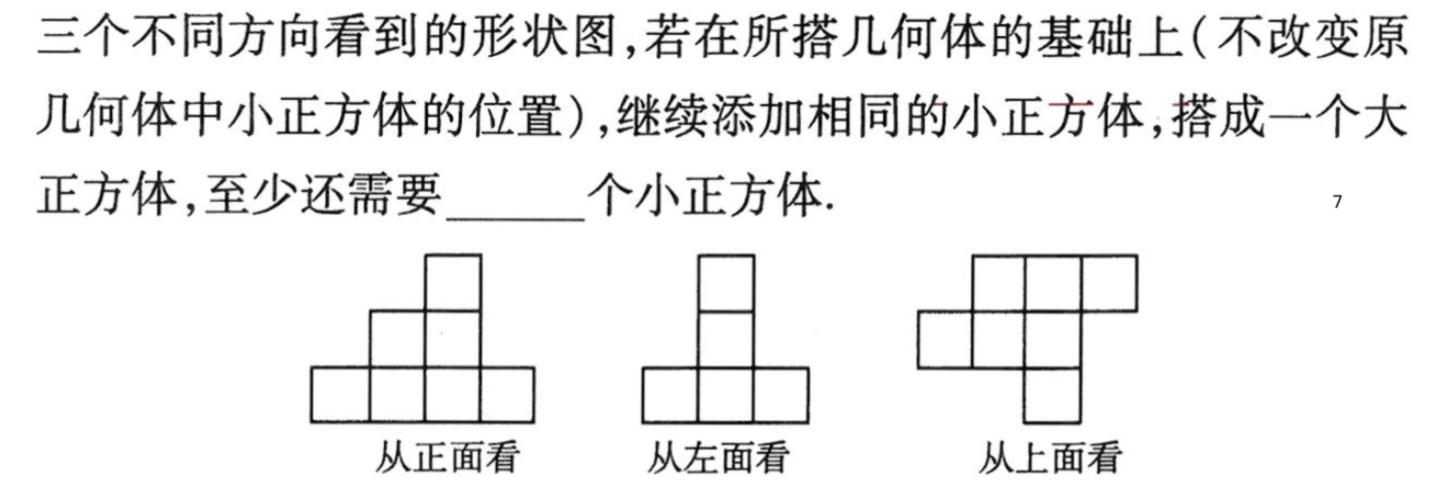
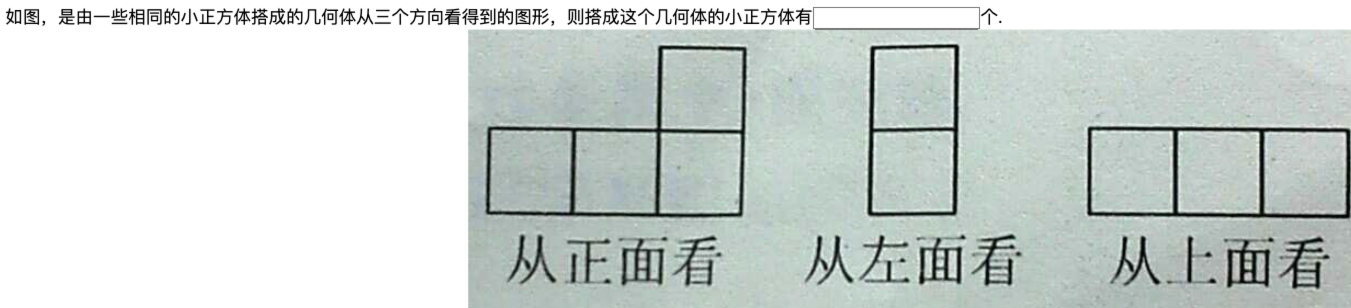
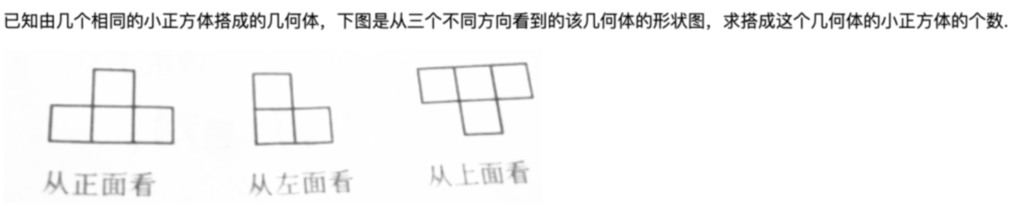
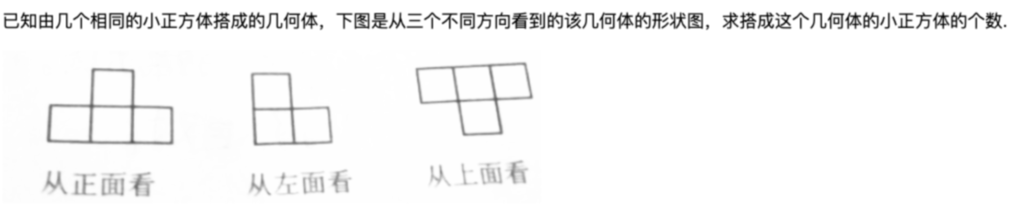
搜題Query: “如圖是由一些相同的小正方體搭成的幾何體從三個不同方向看得到的形狀圖,則搭成這樣的幾何體需要__個小正方體. 0 A 3 從上面看看從正面看”
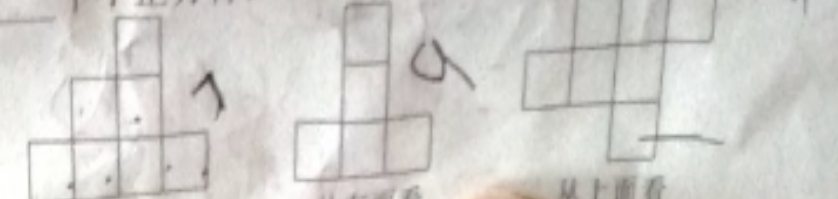
級別 | 舊版自建召回結果 | 開放搜索召回結果 |
top1 |
|
|
top2 |
|
|
top3 |
|
|