CTR模型介紹
點擊率(click-through rate, CTR)預估是搜索平臺的核心任務之一。它所解決的問題是:給定一個user和一個query,以及與該query所匹配的doc,預測這些doc曝光之后獲得點擊的概率。這個概率值可以用于排序腳本中,用來提升搜索效果,提升ctr等業務指標。
優勢/場景
為了更好的滿足用戶多場景、多樣化的搜索排序業務需求,開放搜索推出了CTR模型功能,可以實現個性化、千人千面的搜索排序效果。
創建并訓練模型
創建行業模板,之后進入開放搜索控制臺頁面,左側導航欄選擇:搜索算法中心>排序配置>CTR預估模型,然后點擊創建按鈕:
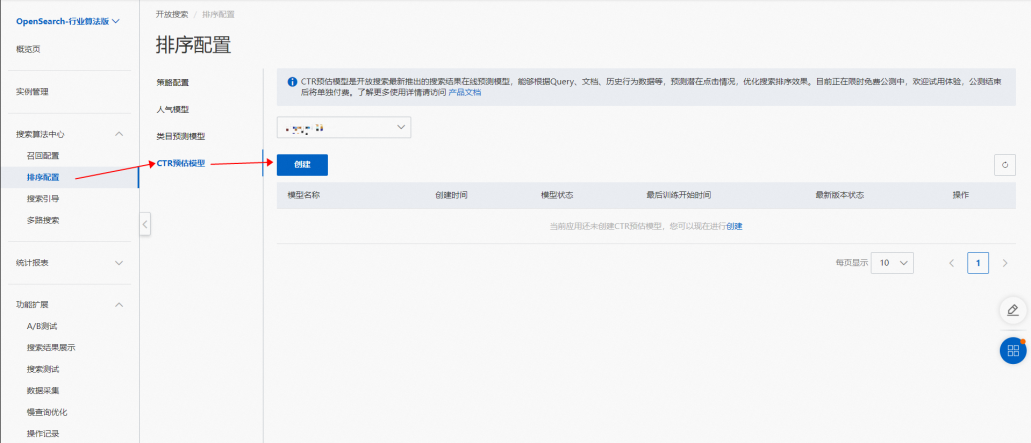
創建CTR預估模型,填寫模型名稱,設置訓練字段:
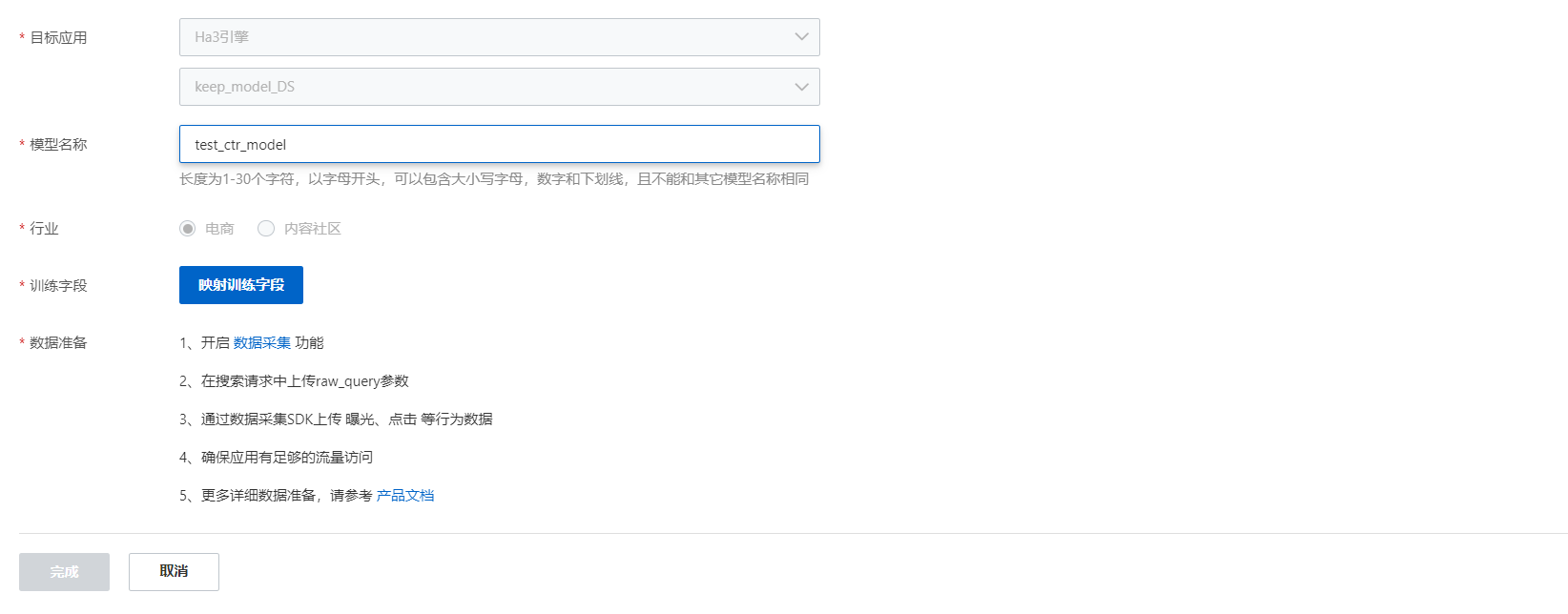
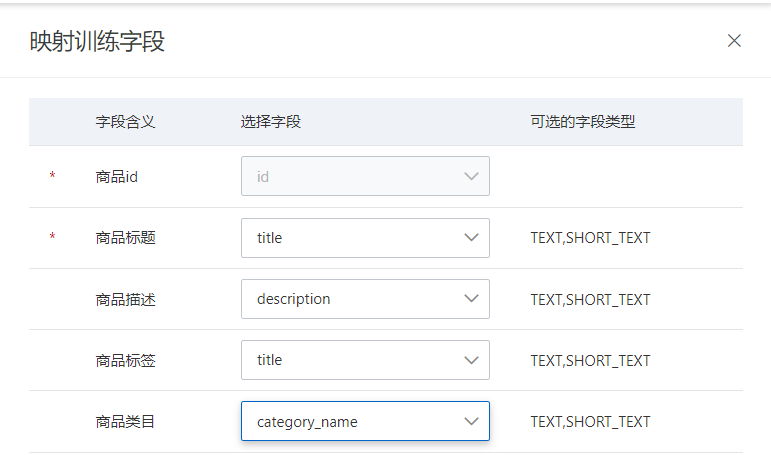
映射訓練字段:(目前商品ID,和商品標題是必選項,其他字段設置的越多,模型效果越好)
模型創建完成后,在CTR預估模型列表頁,找到剛創建的模型,在右側操作欄中點擊“訓練模型”:
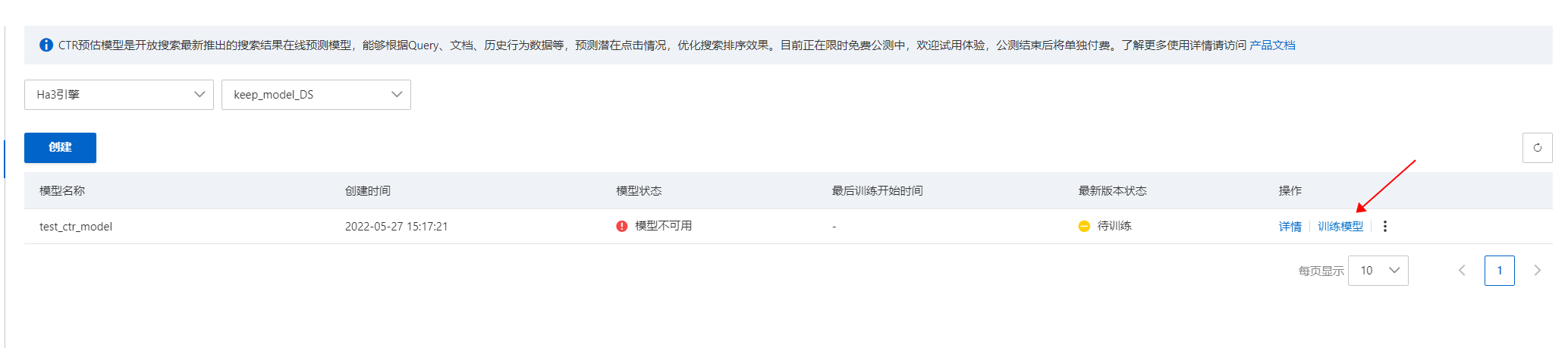
開始訓練后,可在CTR預估模型詳情頁,可查看模型訓練進度:
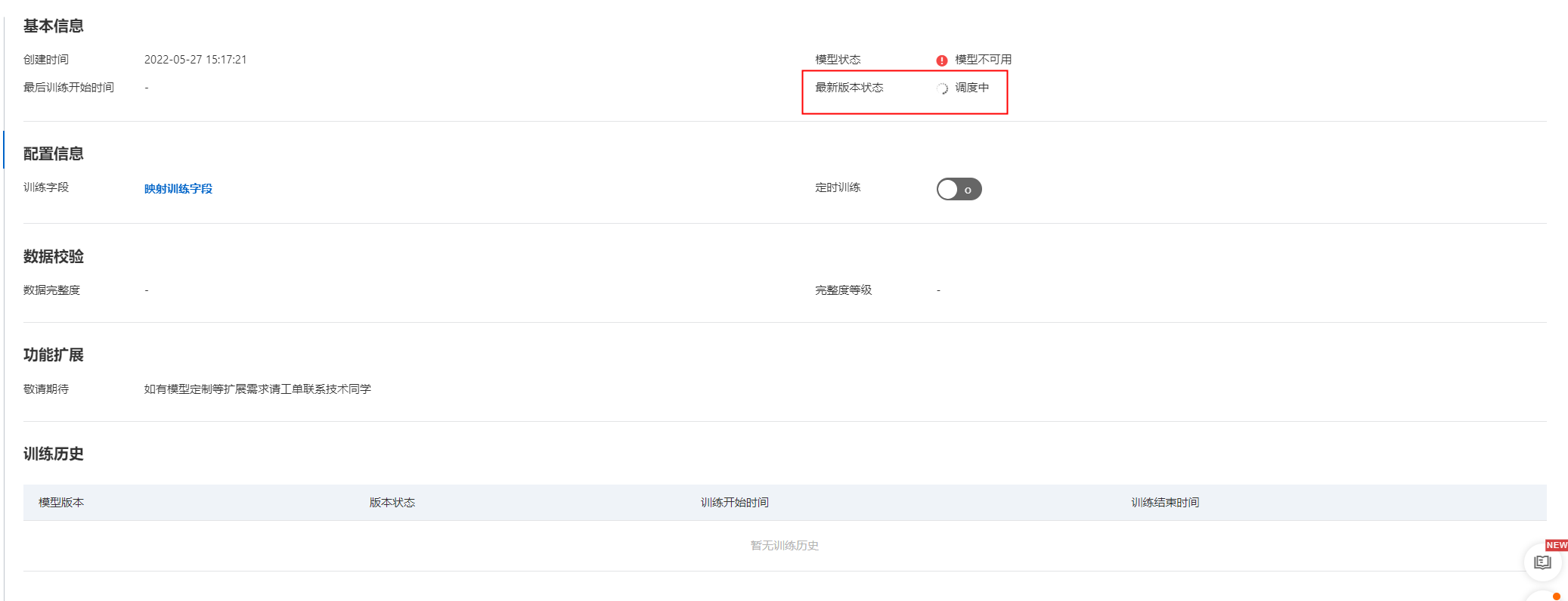
訓練完成后,若模型狀態會變為可用狀態,即可進行使用(若模型狀態為不可用,請根據數據校驗的完整度等級的升級條件進行調整,滿足要求后,第二天再訓練即可,若還有問題,可以提工單聯系技術同學):
定時訓練周期建議設置為每天。
搜索測試
創建一個cava類型的業務排序策略:
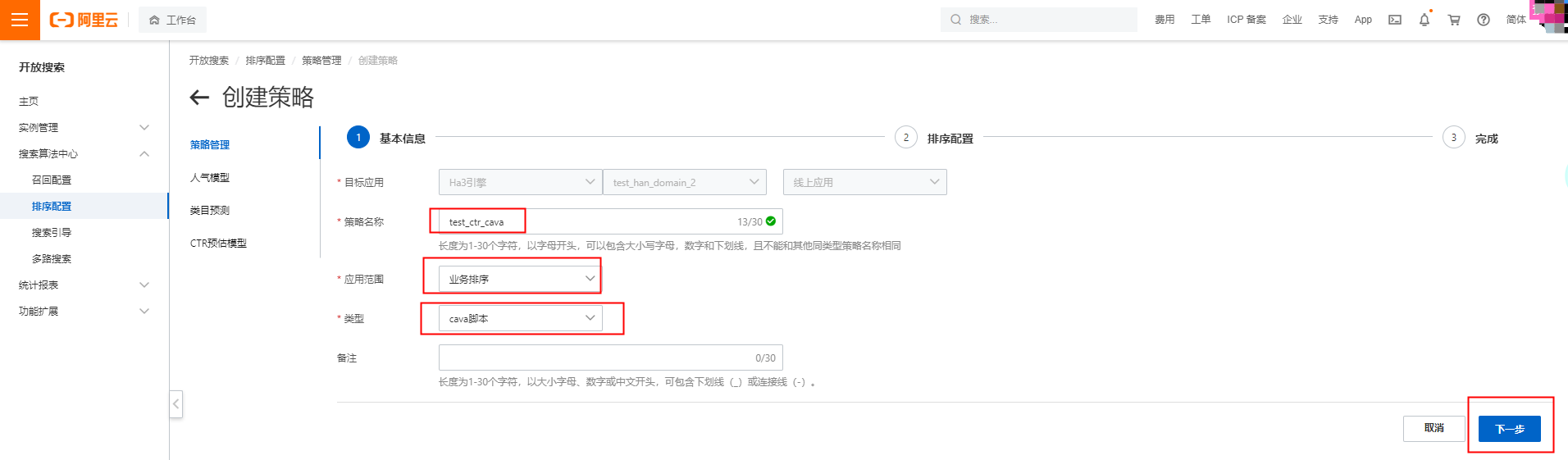
填寫策略名稱,應用范圍選擇業務排序,類型選擇cava腳本:
點擊添加文件,將cava腳本示例貼到腳本代碼中,點擊編譯,如提示編譯成功,點擊保存、發布后即可進行
搜索測試:
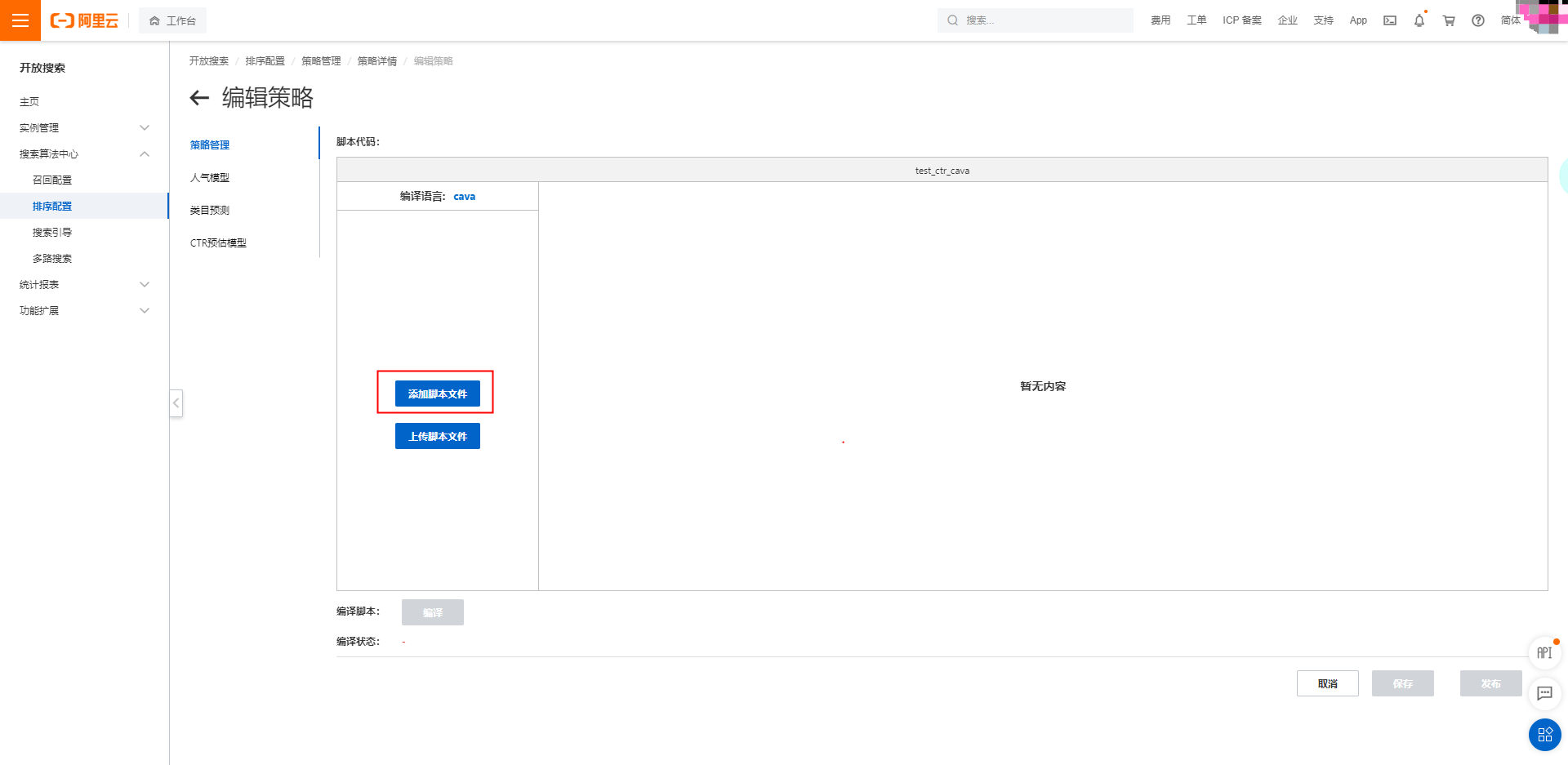
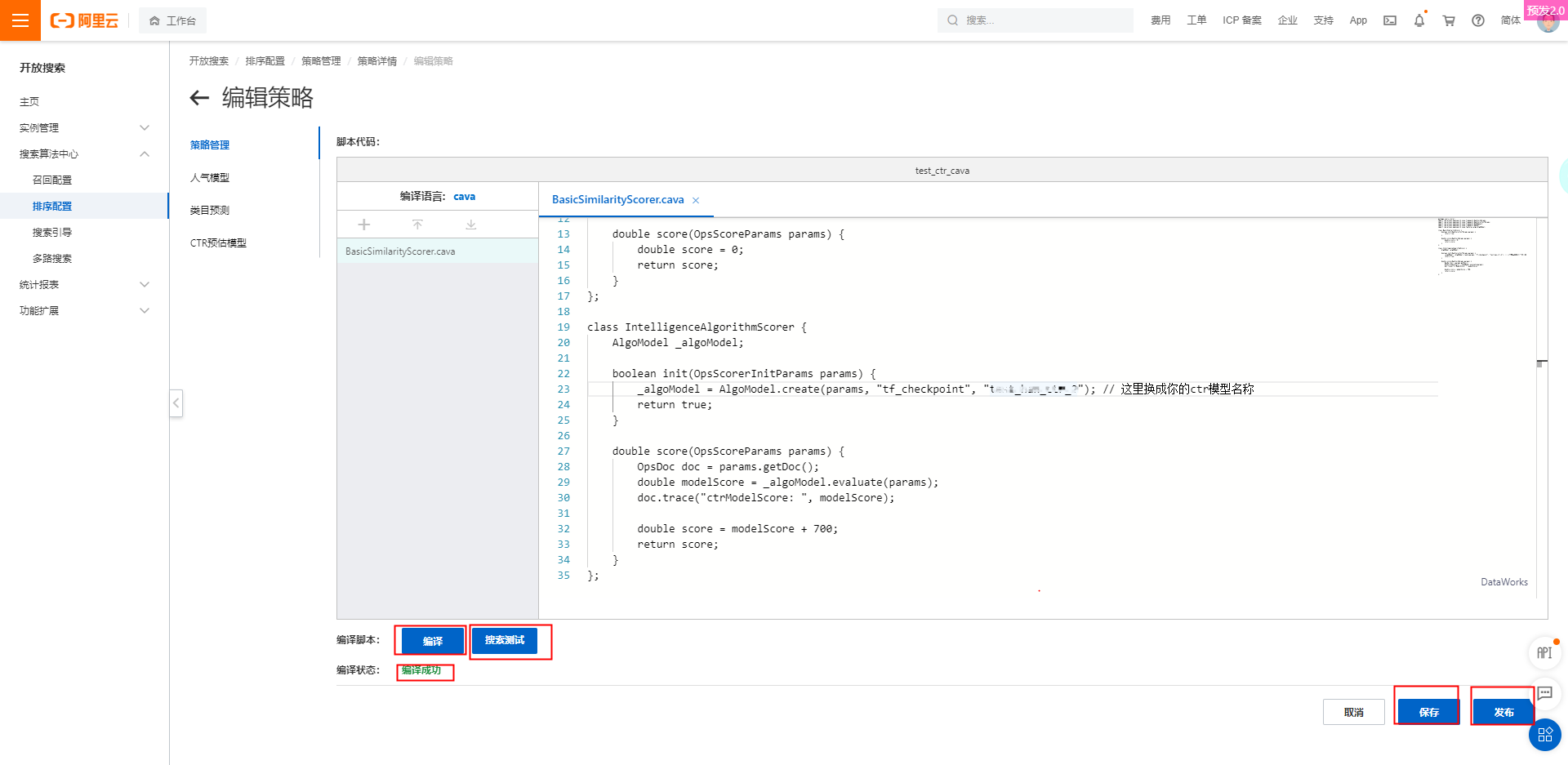
cava腳本示例如下:
package users.scorer;
import com.aliyun.opensearch.cava.framework.OpsScoreParams;
import com.aliyun.opensearch.cava.framework.OpsScorerInitParams;
import com.aliyun.opensearch.cava.framework.OpsRequest;
import com.aliyun.opensearch.cava.framework.OpsDoc;
import com.aliyun.opensearch.cava.features.algo.AlgoModel;
class BasicSimilarityScorer {
boolean init(OpsScorerInitParams params) {
return true;
}
double score(OpsScoreParams params) {
double score = 0;
return score;
}
};
class IntelligenceAlgorithmScorer {
AlgoModel _algoModel;
boolean init(OpsScorerInitParams params) {
//注意tf_checkpoint 為固定參數
_algoModel = AlgoModel.create(params, "tf_checkpoint","ctr", "這里換成你的ctr模型名稱");
return true;
}
double score(OpsScoreParams params) {
OpsDoc doc = params.getDoc();
double modelScore = _algoModel.evaluate(params);
doc.trace("ctrModelScore: ", modelScore);
double score = modelScore + 700;
return score;
}
};進行搜索測試:
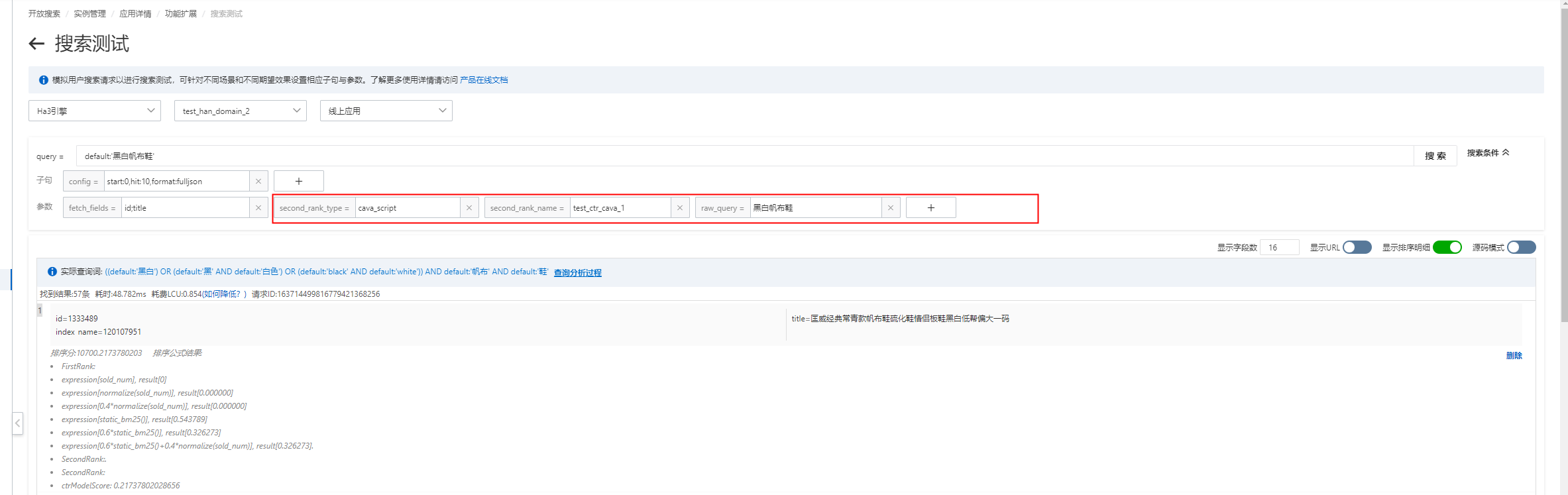
注意:
second_rank_type 、second_rank_name 、raw_query 是必要參數,搜索請求時必須配置;
如果行為數據以及查詢時都上傳了user_id 參數,模型的打分效果會更好;
CTR模型詳情頁說明
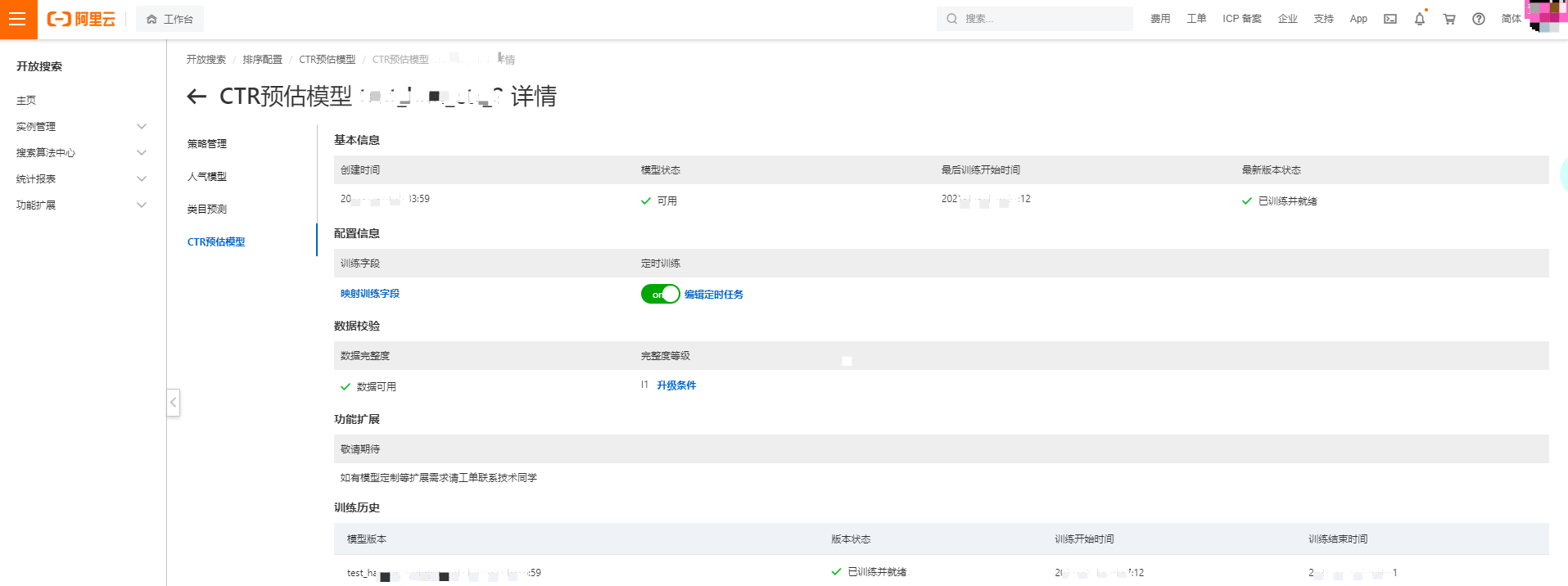
基本信息
可查看模型的創建時間、狀態、最后訓練開始時間以及最新版本狀態。

配置信息
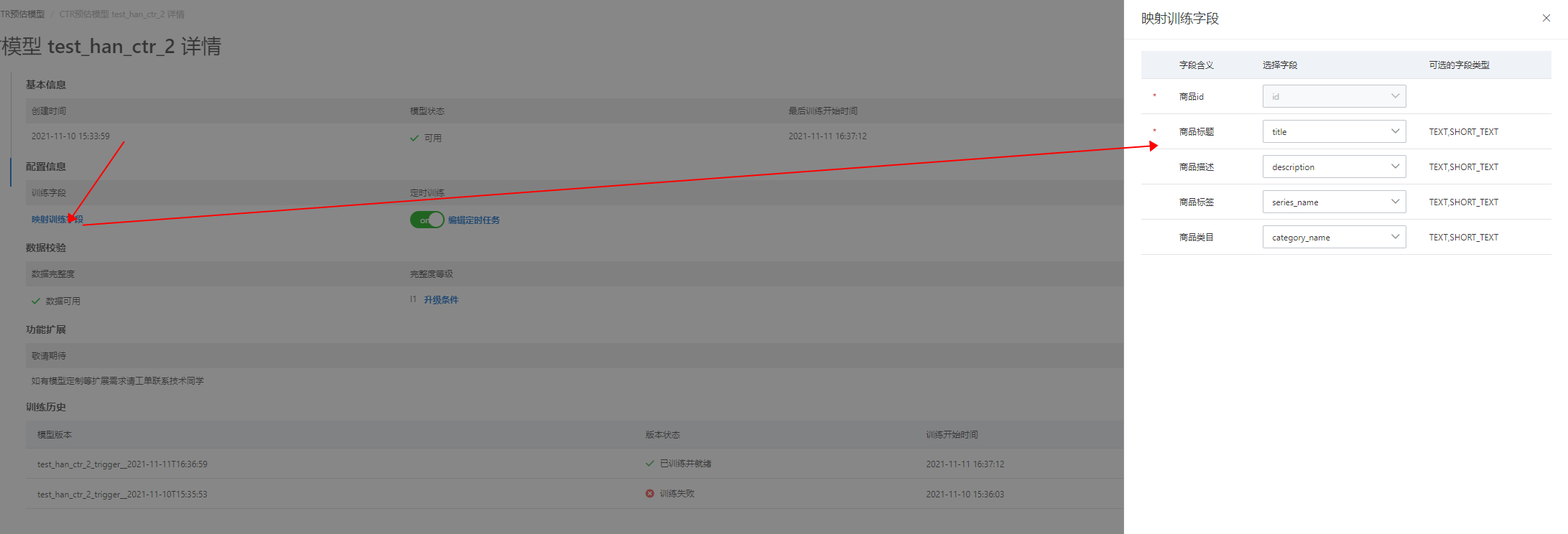
訓練字段:點擊“映射訓練字段”后,彈出映射訓練字段選框,可以修改或刪除模型訓練字段,修改訓練字段后需重新訓練模型才會生效:
定時訓練:默認開啟并每天訓練一次,也可以編輯定時任務,自定義訓練周期。
數據校驗
數據完整度狀態包含可用、數據異常;
完整度報告顯示當前應用的完整度等級,具體完整度等級可見:
數據完整度 | 介紹 | 晉升條件 |
l0 | 表示數據完全不可用,缺少必要的核心字段,數據量太少,后續的數據處理不能繼續進行 | l0-->l1:
|
l1 | 表示數據的核心字段已經具備,滿足最基本的入口條件,但行為數據仍存在字段缺失和數據量不足的問題,部分不依賴行為數據的優化可以進行,全面的優化還需要繼續解決行為數據的問題 | l1-->l2:
|
l2 | 表示數據質量滿足要求,后續的優化可以正常進行,但數據量較小,對優化的最終效果存在一定影響 | l2-->l3:
|
l3 | 表示數據質量和數據量達到合理的水平,具備了正常優化的前提條件 | l3-->l4:
|
l4 | 表示數據規模較大,數據量充足,達到千萬級,數據完整度水平較高 | l4-->l5:
|
l5 | 表示數據規模很大,數據量很充足,達到億級以上,具備深度優化的條件 |
ipv表示每次搜索的點擊率,即bhv_type=click;
有上報曝光行為事件且數量大于ipv數量,表示bhv_type=expose的數量大于bhv_type=click的數量(補充:用戶有點擊某商品,說明該商品一定有曝光,此處該條行為數據需要上傳2次,即bhv_type=click和bhv_type=expose都需要上傳)
注意事項
現階段僅支持CTR模型在Cava插件中使用;
現階段僅支持獨享集群規格的實例創建CTR模型;
每個實例最多支持3個CTR模型;
訓練字段越多,模型訓練效果越好;
訓練晉升條件中的raw_query是搜索請求時需要攜帶的參數,并且要求是獨立的、有召回結果的、非重復的查詢詞,具體用法可參考Java SDK 搜索Demo;
相關API/SDK參考:算法周邊。