本文介紹如何查看增加Shard節點或刪除Shard節點的任務進度,以及檢查是否有異常阻塞任務進程的方法。
背景信息
當您對分片集群實例執行增加Shard節點或刪除Shard節點操作后,可能會出現任務提交后很長時間都沒完成的情況,以下內容將指導您如何檢查上述問題。
在進行操作前,您需要了解以下基本知識:
了解均衡器Balancer的基本工作原理。更多介紹,請參見管理MongoDB均衡器Balancer。
了解MongoDB數據的劃分方式,MongoDB的數據是根據Chunk(塊)進行劃分的。
了解MongoDB分片集群實例常見的運維命令,例如
sh.status()等。了解mongo shell、mongosh或其他可視化工具的基礎使用方式。
檢查任務進程
步驟一:檢查Balancer是否開啟
在增加或刪除分片任務中,Chunk的遷移是依賴Balancer完成的。如果未開啟Balancer則會導致如下情況:
新增Shard節點:Chunk數據無法遷移到新的Shard節點上,同時也無法承載業務流量。
刪除Shard節點:待刪除Shard節點上的Chunk數據無法遷移,導致刪除Shard節點的任務被阻塞。
因此,您需要開啟Balancer來保障Chunk數據的正常遷移。開啟Balancer的方法,請參見管理MongoDB均衡器Balancer。
確認Balancer是否開啟有如下兩種方法:
方法一:
sh.status()命令Balancer已開啟的狀態下,返回示例如下。
... autosplit: Currently enabled: yes balancer: Currently enabled: yes Currently running: yes Balancer active window is set between 08:30 and 11:30 server local time ...如果顯示
“Currently enabled: no”,則表示Balancer未開啟。方法二:
sh.getBalancerState()命令如果返回
true,則表示已開啟Balancer。如果返回
false,則表示未開啟Balancer。
步驟二:檢查Balancer窗口期是否過小
Balancer控制了Chunk數據遷移的速度,Balancer僅會在窗口期時間段內遷移Chunk數據,若當前窗口期未遷移完成,會在下個窗口期繼續遷移,直至遷移完成。當窗口期過小時,可能會拖慢增加Shard節點或刪除Shard節點任務流的整體進度。調整Balancer窗口期的方法,請參見管理MongoDB均衡器Balancer。
您可以通過如下兩種方法檢查Balancer的窗口期:
方法一:
sh.status()命令返回示例如下,可以了解到Balancer的窗口期為當地時間的08:30至11:30,共計3個小時。
... autosplit: Currently enabled: yes balancer: Currently enabled: yes Currently running: yes Balancer active window is set between 08:30 and 11:30 server local time ...方法二:
sh.getBalancerWindow()命令返回示例如下,當實例中的分片集合較多時,采用此方法能夠更直觀的顯示窗口期時間。
{ "start" : "08:30", "stop" : "11:30" }
步驟三:獲取預估任務進度的必要信息
評估任務進度前,您需要獲取Balancer的運行結果(成功和失敗數量的統計)以及待遷移分片表的Chunk信息。
您可以通過如下兩種方法獲取Balancer的運行結果和待遷移分片表Chunk信息:
方法一:通過
sh.status()命令的輸出結果獲取sh.status()命令的輸出結果僅需要關注兩部分信息,第一部分為最近時間Balancer運行的結果,示例如下。... balancer: Collections with active migrations: <db>.<collection> started at Wed Sep 27 2023 10:25:21 GMT+0800 (CST) Failed balancer rounds in last 5 attempts: 0 Migration Results for the last 24 hours: 300 : Success databases: ...第二部分為待遷移的分片表的Chunk信息,示例如下。
... databases: ... { "_id" : "<db>", "primary" : "d-xxxxxxxxxxxxxxx3", "partitioned" : true, "version" : { "uuid" : UUID("3409a337-c370-4425-ad72-8b8c6b0abd52"), "lastMod" : 1 } } <db>.<collection> shard key: { "<shard_key>" : "hashed" } unique: false balancing: true chunks: d-xxxxxxxxxxxxxxx1 13630 d-xxxxxxxxxxxxxxx2 13629 d-xxxxxxxxxxxxxxx3 13652 d-xxxxxxxxxxxxxxx4 13630 d-xxxxxxxxxxxxxxx5 3719 too many chunks to print, use verbose if you want to force print ...以上示例中的“d-xxxxxxxxxxxxxxx5”即為新增的Shard節點。您也可以在分區表所在的庫執行
getShardDistribution命令來獲取Chunk數據的分布信息,示例如下。use <db> db.<collection>.getShardDistribution()方法二:直接讀取config庫中的相關信息
查看Chunks統計,按分片聚合,示例如下。
db.getSiblingDB("config").chunks.aggregate([{$group: {_id: "$shard", count: {$sum: 1}}}])查看指定分片上的Chunks,按namespace聚合,示例如下。
db.getSiblingDB("config").chunks.aggregate([{$match: {shard: "d-xxxxxxxxxxxxxx"}},{$group: {_id: "$ns", count: {$sum: 1}}}])查看過去1天內成功遷移到指定Shard節點的Chunk數量,示例如下。
// details.to指定chunk遷移的目標shard // time字段用ISODate指定時間范圍 db.getSiblingDB("config").changelog.find({"what" : "moveChunk.commit", "details.to" : "d-xxxxxxxxxxxxx","time" : {"$gte": ISODate("2023-09-26T00:00:00")}}).count()
步驟四:預估任務進度及完成時間
獲取分片表已成功遷移的Chunk數量以及當前分片表數據分布情況后,您就可以預估出任務的整體進度和預期完成時間。
假如當前增加Shard節點的場景中,總Chunk數量保持不變,Shard節點數量也保持不變(期間不會有新增或刪除Shard節點的任務),增加Shard節點的過程中業務負載基本保持固定,且Balancer的參數設置均為默認值。以上述步驟的示例為例,可以得知以下信息:
Shard節點數量為5。
在Balancer窗口期內,成功遷移的Chunk數量為300個。
分片表
<db>.<collection>的總Chunk數量為58260個(13630+13629+13652+13630+3719=58260)。
因此可以計算出:
達到均衡狀態時,每個分片上的Chunk數量應為11652個(58260÷5=11652)。
按照當前的遷移速度,任務完成還需要26.4天((11652-3719)÷300≈26.4)。
該增加Shard節點任務進度為32%(3719÷11652=32%)。
實際的業務場景中,總Chunk數量還會隨著業務寫入以及Chunk分裂而增加。因此假設條件為理想情況,實際耗時可能會更久。
步驟五:確認任務流是否阻塞(刪除Shard節點)
如果刪除Shard節點的任務被阻塞,執行sh.status()命令后,返回信息中沒有看到過去時間段有Chunk數據遷移成功,且待刪除Shard節點上依然殘留部分Chunk數據未遷移走。此時刪除Shard節點任務無法完成,并且會影響您在云數據庫MongoDB控制臺對實例的其他運維操作。
上述場景中sh.status()命令的返回信息示例如下圖所示。
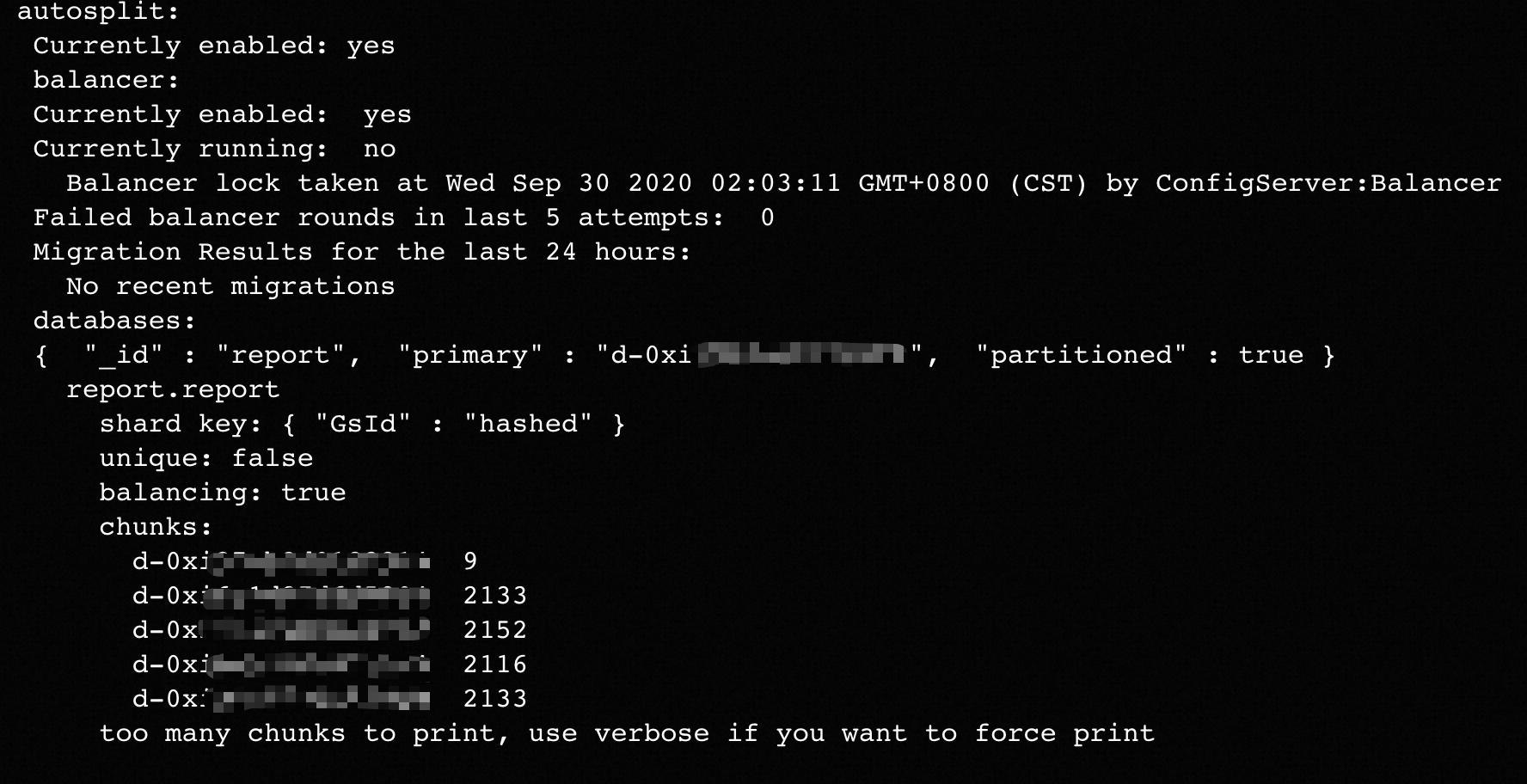
出現上述問題可能是因為Jumbo Chunk阻塞了刪除Shard節點的進程,您可以通過如下的命令確認。
db.getSiblingDB("config").chunks.aggregate([{$match: {shard: "d-xxxxxxxxxxxxxx", jumbo:true}},{$group: {_id: "$ns", count: {$sum: 1}}}])一般情況下,出現Jumbo Chunk是因為設計的分片鍵(Shard Key)不合理(例如存在熱點Key)等因素導致。您可以在業務側進行如下方法嘗試解決:
如果您的MongoDB數據庫的大版本為4.4,則可以通過refineCollectionShardKey命令來優化您的Shard key設計,通過為原本分片鍵添加后綴的方式來使得分片鍵的基數更大,從而解決Jumbo Chunk的問題。
如果您的MongoDB數據庫的大版本為5.0及以上,則可以通過reshardCollection命令來將指定分片表按照新的分片鍵重新分片。更多介紹,請參見Reshard a Collection。
如果您確認部分業務數據可刪除的話,則可以刪除對應Jumbo Chunk中的數據,該方法可以減少Jumbo Chunk的大小。減少數據后Jumbo Chunk可能成為一個普通的Chunk,然后被均衡器Balancer遷出。
您可以調大
chunkSize參數來使判斷Jumbo Chunk的條件發生變化,建議在阿里云技術支持工程師的協助下進行操作。
如果以上方法都無法解決您的問題,建議您提交工單聯系技術支持協助解決。
加速新增或刪除任務進程
如果您希望增加Shard節點或刪除Shard節點的整體流程可以在更短的時間內完成,您可以嘗試以下加速方法:
將Balancer的窗口期時間調大,Chunk遷移過程帶來的額外負載可能會對業務側產生影響,請您評估風險后再進行調整。調整Balancer窗口期的方法,請參見管理MongoDB均衡器Balancer。
在業務低峰期手動執行
moveChunk操作,更多介紹,請參見sh.moveChunk()。示例如下。sh.moveChunk("<db>.<collection>", {"<shard_key>": <value>}, "d-xxxxxxxxxxxxx") // example: sh.moveChunk("records.people", { zipcode: "53187" }, "shard0019")提交工單聯系技術支持對相關內核參數進行調整。