阿里云作為MongoDB官方戰略合作伙伴,全網首次引入MongoDB 4.4版本并已于2020年11月發布。而MongoDB官方4.4版本已經在2020年7月30日正式發布。和往年的大版本不同,本次的4.4版本是以往版本的全面加強版,主要針對用戶呼聲最高的一些痛點重點進行了改進。
隱藏索引(Hidden Indexes)
眾所周知數據庫維護太多的索引會導致寫性能下降,但是往往業務上的復雜性導致了運維人員不敢輕易去刪除一個潛在的低效率索引,擔心誤刪除會帶來業務性能的抖動,而重建索引的代價也非常大。
為了解決上述問題,阿里云數據庫MongoDB版和MongoDB官方達成戰略合作后共同開發了Hidden Indexes功能。該功能支持通過collMod命令隱藏現有的索引,保證該索引在后續的查詢中不會被使用。在觀察一段時間后,確定業務沒有異常即可以放心刪除該索引。
參考代碼:
db.runCommand( {
collMod: 'testcoll',
index: {
keyPattern: 'key_1',
hidden: false
}
} )需要注意的是,索引被隱藏之后僅對MongoDB的執行計劃器不可見,這并不會改變索引本身的一些特殊行為,如唯一鍵約束、TTL淘汰等。
索引在隱藏期間也不會停止更新,所以當需要該索引時,可以通過取消隱藏使其立刻可用。
重定義分片鍵(Refinable Shard Keys)
在MongoDB分片集群中,一個好的Shard key至關重要,因為它決定了分片集群在指定的Workload(工作量)下是否有良好的擴展性。但是在實際使用MongoDB的過程中,即使我們事先仔細斟酌了要選擇的Shard Key,也會因為Workload的變化而導致出現Jumbo Chunk(超過預設大小的Chunk),或者業務流量都打向單一分片的情況。
在4.0及之前的版本中,集合選定的Shard Key及其對應的Value都是不能更改的,到了4.2版本,雖然可以修改Shard Key的Value,但是數據的跨分片遷移以及基于分布式事務的實現機制導致性能開銷很大,而且并不能完全解決Jumbo Chunk或訪問熱點的問題。例如,現在有一個訂單表,Shard Key為{customer_id:1},在業務初期每個客戶不會有很多的訂單,這樣的Shard Key完全可以滿足需求,但是隨著業務的發展,某個大客戶累積的訂單越來越多,進而對這個客戶訂單的訪問成為某個單一分片的熱點,由于訂單和customer_id天然的關聯關系,修改customer_id并不能改善訪問不均的情況。
針對上述類似場景,在4.4版本中,您可以通過refineCollectionShardKey命令給現有的Shard Key增加一個或多個Suffix Field來改善現有的文檔在Chunk上的分布問題。例如在上面描述的訂單業務場景中,通過refineCollectionShardKey命令把Shard key更改為{customer_id:1, order_id:1},即可避免單一分片上的訪問熱點問題。
并且,refineCollectionShardKey命令的性能開銷非常低,僅更改Config Server節點上的元數據,不需要任何形式的數據遷移,數據的打散仍然在后續正常的Chunk自動分裂和遷移的流程中逐步進行。此外,Shard Key需要有對應的Index來支撐,因此refineCollectionShardKey命令要求提前創建新Shard Key所對應的Index。
由于并不是所有的文檔都存在新增的Suffix Field,因此在4.4版本中隱式支持了Missing Shard Key功能,即新插入的文檔可以不包含指定的Shard Key Field。但是由于很容易產生Jumbo Chunk,因此并不建議使用。
復合哈希分片鍵(Compound Hashed Shard Keys)
在4.4之前的版本中,您只能指定單字段的哈希片鍵,原因是當時版本的MongoDB不支持復合哈希索引,這樣就很容易導致集合數據在分片上分布不均勻。
在最新的4.4版本中加入了復合哈希索引,即您可以在復合索引中指定單個哈希字段,位置不限,可以作為前綴,也可以作為后綴,進而也就提供了對復合哈希片鍵的支持。
參考代碼:
sh.shardCollection(
"examples.compoundHashedCollection",
{ "region_id" : 1, "city_id": 1, field1" : "hashed" }
)
sh.shardCollection(
"examples.compoundHashedCollection",
{ "_id" : "hashed", "fieldA" : 1}
)復合哈希索引有很多優點,例如如下兩個場景:
應法律法規的要求,需要使用MongoDB的zone sharding功能,把數據盡量均勻打散在某個地域的分片上。
集合指定的片鍵的值是遞增的,例如上文例子中的
{customer_id:1, order_id:1}這個片鍵,如果customer_id是遞增的,并且業務也總是訪問最新顧客的數據,導致大部分的流量總是訪問單一分片。
在沒有復合哈希片鍵支持的情況下,只能提前對需要的字段進行哈希值的計算,并將結果存儲到文檔中的某個特殊字段中,然后再通過范圍分片的方式指定其作為片鍵來解決上述問題。
而在4.4版本中只需直接把目標字段指定為哈希即可輕松解決上述問題。例如,針對上述第二個場景,僅需將片鍵設置為{customer_id:'hashed', order_id:1}即可在極大程度上簡化業務邏輯的復雜性。
對沖讀(Hedged Reads)
頁面的響應速度和經濟損失直接掛鉤。Google有一個研究報告表明,如果網頁的加載時間超過3秒,用戶的跳出率會增加50%。針對這個問題,MongoDB在4.4版本中提供了Hedged Reads功能,即在分片集群場景下,mongos節點會把一個讀請求同時發送給某個分片的兩個副本集成員,然后選擇最快的返回結果回復客戶端,來減少業務上的P95(指過去十秒內95%的請求延遲均在規定范圍內)和P99延遲(指過去十秒內99%的請求延遲均在規定范圍內)。
Hedged Reads功能作為Read Preference參數的一部分來提供, 因此可以在Operation粒度上進行配置,當Read Preference指定為nearest時,系統默認啟用Hedged Reads功能,當指定為primary時,不支持Hedged Reads功能,當指定為其他時,需要顯式地指定hedgeOptions才可以啟用Hedged Reads。如下所示:
db.collection.find({ }).readPref(
"secondary", // mode
[ { "datacenter": "B" }, { } ], // tag set
{ enabled: true } // hedge options
)此外,Hedged Reads也需要mongos開啟支持,配置readHedgingMode參數為on,使mongos開啟該功能支持。
參考代碼:
db.adminCommand( { setParameter: 1, readHedgingMode: "on" } )降低復制延遲
本次4.4的更新帶來了主備復制延遲的降低。對于MongoDB來說,主備復制的延遲會對讀寫有非常大的影響。在某些特定的場景下,備庫需要及時地復制并應用主庫的增量更新,才可以繼續進行讀寫操作。因此,更低的復制延遲會帶來更好的一致性體驗。
流式復制(Streaming Replication)
在4.4之前的版本中,備庫需要通過不斷地輪詢upstream來獲取增量更新操作。每次輪詢時,備庫主動給主庫發送一個getMore命令讀取Oplog集合,如果有數據,會返回一個最大16MB的Batch,如果沒有數據,備庫也會通過awaitData選項來控制備庫無謂的getMore開銷,同時能夠在有新的增量更新時,第一時間獲取到對應的Oplog。拉取操作是通過單個OplogFetcher線程來完成,每個Batch的獲取都需要經歷一個完整的RTT(Round-Trip Time,往返時間),在副本集網絡狀況不好的情況下,復制的性能就嚴重受限于網絡延遲。
而在4.4版本中,增量的Oplog是不斷地主動流向備庫的,而不是被動地依靠備庫輪詢。相比于備庫輪詢的方式,至少在Oplog的獲取上節省了一半的RTT。在以下兩個場景中,Streaming Replication功能會大大提升性能:
當用戶的寫操作指定了writeConcern參數為
"majority"時,寫操作需要等待足夠多次數的“備庫返回復制成功”。而在新的復制機制下,高延遲的網絡環境也可以平均提升50%的majority寫性能。當用戶使用了因果一致性(Causal Consistency)的場景下,為了保證可以在備庫讀到自己的寫操作(Read Your Write),同樣強依賴備庫對主庫Oplog的及時復制。
同步建索引(Simultaneous Indexing)
4.4 之前的版本中,索引的創建需要在主庫中完成之后,才會到備庫上執行。備庫上的創建動作在不同的版本中,因為創建機制和創建方式的不同,對備庫Oplog的影響也大有不同。
但即使在4.2版本中統一了前后臺索引創建機制,使用了相當細粒度的加鎖機制(只在索引創建的開始和結束階段對集合加獨占鎖),也會因為索引創建本身的CPU、IO性能開銷導致復制延遲,或是因為一些特殊操作,例如使用collMod命令修改集合元信息,而導致Oplog的應用阻塞,甚至會因為主庫歷史Oplog被覆蓋而進入Recovering狀態。
在4.4版本中,主庫和備庫上的索引創建操作是同時進行的,這樣可以大幅減少上述情況所帶來的主備延遲,即使在索引創建過程中,也可以保證備庫訪問到最新的數據。
此外,新的索引創建機制規定,只有在大多數具備投票權限節點返回成功后,索引才會真正生效。所以,也可以減輕在讀寫分離場景下因為索引不同而導致的性能差異。
復制讀請求(Mirrored Reads)
在阿里云數據庫MongoDB版以往提供服務的過程中,有一個現象,即大多數用戶雖然購買的是三節點副本集實例,但是實際在使用過程中讀寫都是在Primary節點進行,其中一個可見的Secondary節點并未承載任何讀流量,導致在偶爾的宕機切換之后,用戶能明顯感受到業務的訪問延遲,經過一段時間后才會恢復到之前的水平,原因就在于新選舉出的主節點之前從未提供過讀服務,并不了解業務的訪問特征,沒有針對性地對數據做緩存,所以在突然提供服務后,讀操作會出現大量的緩存未命中(Cache Miss),需要從磁盤重新加載數據,造成訪問延遲上升。在大內存實例的情況下,這個問題尤為明顯。
在4.4版本中,MongoDB針對上述問題實現了Mirrored Reads功能,即主節點會按一定的比例把讀流量復制到備庫上執行,來幫助備庫預熱緩存。這是一個非阻塞執行(Fire and Forgot)的行為,不會對主庫的性能產生任何實質性的影響,但是備庫負載會有一定程度的上升。
流量復制的比例是可動態配置的,通過mirrorReads參數設置,默認復制1%的流量。
參考代碼:
db.adminCommand( { setParameter: 1, mirrorReads: { samplingRate: 0.10 } } )此外,還可以通過db.serverStatus( { mirroredReads: 1 } )來查看Mirrored Reads相關的統計信息,如下所示:
SECONDARY> db.serverStatus( { mirroredReads: 1 } ).mirroredReads
{ "seen" : NumberLong(2), "sent" : NumberLong(0) }可恢復的全量同步(Resumable Initial Sync)
在4.4之前的版本中,如果備庫在做全量同步時出現網絡抖動而導致連接閃斷,那么備庫需要從頭開始全量同步,導致之前的工作全部白費,這個情況在數據量比較大時會對業務造成巨大的影響。
在4.4版本中,MongoDB提供了從中斷位置繼續執行同步的能力。如果在閃斷后一直無法連接成功,系統會重新選擇一個同步源進行新的全量同步。該過程的默認超時時間為24小時,您可以通過replication.initialSyncTransientErrorRetryPeriodSeconds在進程啟動時更改。
需要注意的是,對于全量同步過程中遇到的非網絡異常導致的中斷,仍然需要重新發起全量同步。
基于時間保留Oplog(Time-Based Oplog Retention)
MongoDB中的Oplog集合記錄了所有數據的變更操作,除了用于復制,還可用于增量備份、數據遷移、數據訂閱等場景,是MongoDB數據生態的重要基礎設施。
Oplog是通過Capped Collection來實現的,雖然從3.6版本開始,MongoDB支持通過replSetResizeOplog命令動態修改Oplog集合的大小,但是往往不能準確反映下游對Oplog增量數據的需求,您可以考慮如下場景:
計劃在凌晨2~4點對某個Secondary節點進行停機維護,需要避免上游Oplog被清理而觸發全量同步。
下游的數據訂閱組件可能會因為一些異常情況而停止服務,但是最慢會在3個小時之內恢復服務并繼續進行增量拉取,也需要避免上游的增量缺失。
由此可見,在大部分應用場景下,需要保留最近一個時間段內的Oplog,而這個時間段內產生多少Oplog往往是很難確定的。
在4.4版本中,MongoDB支持通過storage.oplogMinRetentionHours參數定義需要保留的Oplog時長,也可以通過replSetResizeOplog命令在線修改這個值,參考代碼如下:
// First, show current configured value
db.getSiblingDB("admin").serverStatus().oplogTruncation.oplogMinRetentionHours
// Modify
db.adminCommand({
"replSetResizeOplog" : 1,
"minRetentionHours" : 2
})多表聯合增強(Union)
在多表聯合查詢能力上,4.4之前的版本只提供了一個$lookup stage用于實現類似于SQL中的left outer join功能,而4.4版本中新增了$unionWith stage用于實現類似于SQL的union all功能,用于將兩個集合中的數據聚合到一個結果集中,然后做指定的查詢和過濾。區別于$lookup stage的是,$unionWith stage支持分片集合。在Aggregate Pipeline中使用多個$unionWith stage,可以對多個集合數據做聚合,使用方式如下:
{ $unionWith: { coll: "<collection>", pipeline: [ <stage1>, ... ] } }您也可以在pipeline參數中指定不同的stage,用于在對集合數據做聚合前進行一定的過濾,使用起來非常靈活。例如,某個業務上對訂單數據按表拆分存儲到不同的集合中,第二季度有如下數據:
db.orders_april.insertMany([
{ _id:1, item: "A", quantity: 100 },
{ _id:2, item: "B", quantity: 30 },
]);
db.orders_may.insertMany([
{ _id:1, item: "C", quantity: 20 },
{ _id:2, item: "A", quantity: 50 },
]);
db.orders_june.insertMany([
{ _id:1, item: "C", quantity: 100 },
{ _id:2, item: "D", quantity: 10 },
]);假設需要列出第二季度中不同產品的銷量,在4.4版本之前,可能需要業務自己把數據都讀出來,然后在應用層面做聚合才能解決這個問題,或者依賴某種數據倉庫產品來做分析,而在4.4版本中只需要如下一條Aggregate語句即可解決問題:
db.orders_april.aggregate( [
{ $unionWith: "orders_may" },
{ $unionWith: "orders_june" },
{ $group: { _id: "$item", total: { $sum: "$quantity" } } },
{ $sort: { total: -1 }}
] )自定義Aggregation表達式(Custom Aggregation Expressions)
4.4之前的版本中,您可以通過find命令中的$where operator或者MapReduce功能來實現在Server端執行自定義的JavaScript腳本,進而提供更為復雜的查詢能力,但是這兩個功能并沒有做到和Aggregation Pipeline在使用上的統一。
在4.4版本中,MongoDB提供了$accumulator和$function這兩個新的Aggregation Pipeline Operator用來取代$where operator和MapReduce。借助于Server Side JavaScript來實現自定義的Aggregation Expression,這樣做到復雜查詢的功能接口都集中到Aggregation Pipeline中,完善接口統一性和用戶體驗的同時,也可以把Aggregation Pipeline本身的執行模型利用上,實現一舉多得的效果。
$accumulator和MapReduce功能有些相似,會先通過init函數定義一個初始的狀態,然后根據指定的accumulate函數更新每一個輸入文檔的狀態,并且根據需要決定是否執行merge函數。
例如,假設在分片集合上使用了$accumulator operator,則需要將在不同分片上執行完成的結果做merge,并且如果指定了finalize函數,那么在所有輸入文檔處理完成后,還會根據該函數將狀態轉換為最終的輸出。
$function和$where operator在功能上基本一致,但其強大之處在于可以和其他Aggregation Pipeline Operator配合使用,此外也可以在find命令中借助$expr operator來使用$function operator,等價于之前的$where operator,MongoDB官方在文檔中也建議優先使用$function operator。
其他易用性增強
除了上述$accumulator和$function operator,4.4版本中還新增了其他多個Aggregation Pipeline Operator,例如字符串處理、獲取數組收尾元素、還有用來獲取文檔或二進制串大小的操作符,具體請參見下表:
操作符 | 說明 |
$accumulator | 返回用戶定義的accumulator operator結果。 |
$binarySize | 返回指定字符串或二進制數據的大小(以字節為單位)。 |
$bsonSize | 返回編碼為BSON時指定文檔(即bsontype對象)的字節大小。 |
$first | 返回數組中的第一個元素。 |
$function | 用來自定義aggregation表達式。 |
$last | 返回數組中的最后一個元素。 |
$isNumber | 如果指定的表達式類型為整數、十進制、雙精度或長整型,則返回布爾值 |
$replaceOne | 替換第一個通過指定的字符串匹配到的實例。 |
$replaceAll | 替換所有通過指定的字符串匹配到的實例。 |
Connection Monitoring and Pooling
4.4版本的Driver中增加了對客戶端連接池的行為監控和自定義配置,通過標準的API來訂閱和連接池相關的事件,包括連接的關閉和開啟、連接池的清理。也可以通過API來配置連接池的一些行為,例如擁有的最大或最小連接數、每個連接的最大空閑時間、線程等待可用連接時的超時時間等。具體可以參見MongoDB官方文檔。
Global Read and Write Concerns
在4.4之前的版本中,如果執行的操作沒有顯式地指定readConcern或者writeConcern,則會有默認行為。例如:readConcern默認為local,writeConcern默認為{w: 1}。但這個默認行為不可以變更,如果用戶想讓所有insert操作的writeConcern默認為 {w: majority},那么只能在所有訪問MongoDB的代碼中顯式指定該值。
而在4.4版本中,可以通過setDefaultRWConcern命令來配置全局默認的readConcern和writeConcern。參考代碼:
db.adminCommand({
"setDefaultRWConcern" : 1,
"defaultWriteConcern" : {
"w" : "majority"
},
"defaultReadConcern" : { "level" : "majority" }
})您也可以通過getDefaultRWConcern命令獲取當前默認的readConcern和writeConcern。
此外,在4.4版本中記錄慢日志或診斷日志的時候,會記錄當前操作的readConcern或者writeConcern設置的來源,兩者共通的來源有如下三種:
來源 | 說明 |
clientSupplied | 由應用自己指定。 |
customDefault | 由用戶通過 |
implicitDefault | 完全沒做任何配置,Server默認行為。 |
writeConcern還有如下一種來源:
來源 | 說明 |
getLastErrorDefaults | 繼承自副本集的 |
New MongoDB Shell (beta)
對于MongoDB的運維人員來說,使用最多的工具可能就是Mongo Shell,4.4版本提供了新版本的Mongo Shell,增加了諸如代碼高亮、命令自動補全、更具可讀性的錯誤信息等非常人性化的功能。目前提供的是beta版本,很多命令還未提供支持,僅供體驗。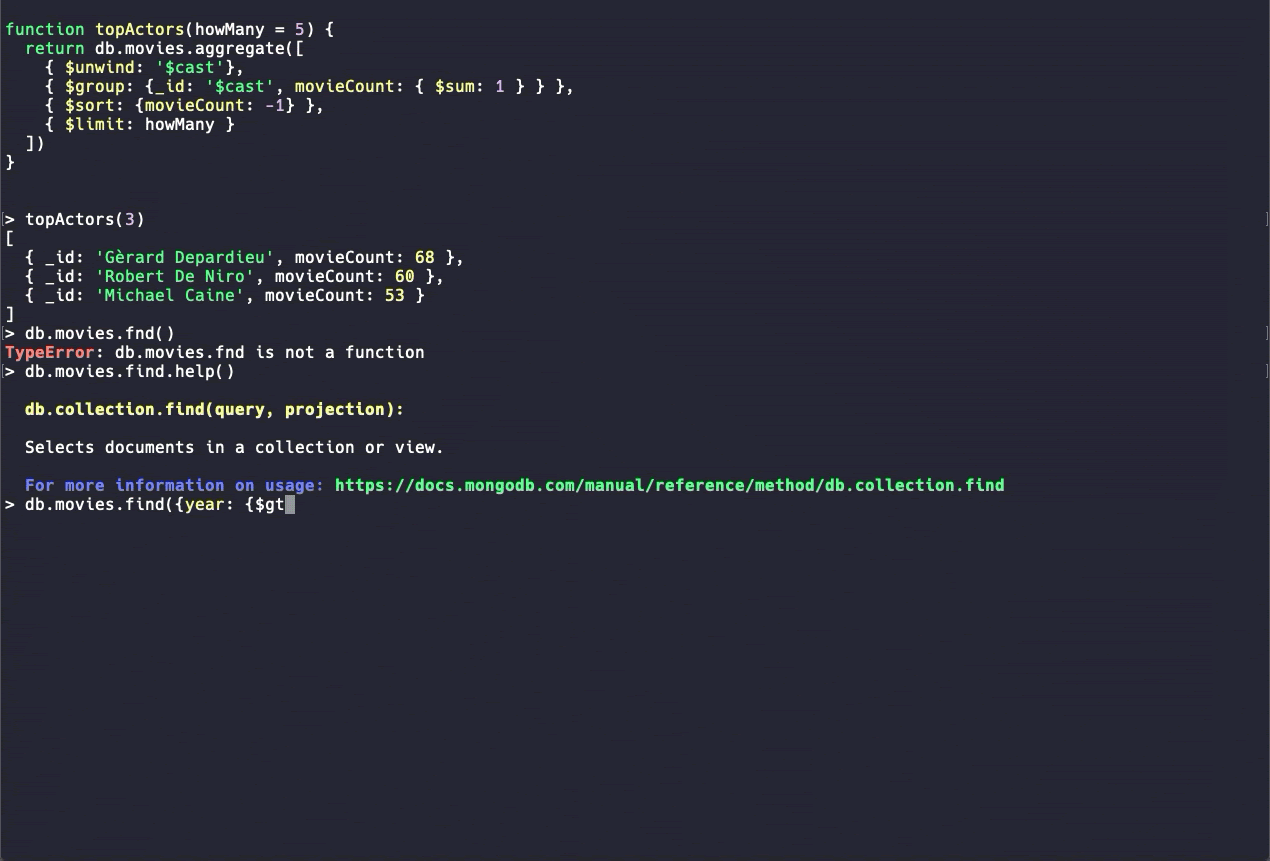
結語
本次發布的4.4版本主要是一個維護性的版本,除了上述解讀,還有很多其他小的優化,例如$indexStats優化、TCP Fast Open支持優化建連、索引刪除優化等等。還有一些相對大的增強,例如新的結構化日志LogV2、新的安全機制支持等。詳情請參見官方的Release Notes。