模型調優簡介
當您在嘗試如 Prompt 工程、插件調用等優化方法后,模型表現仍然不及預期時,請使用百煉的模型調優。模型調優作為改進模型表現的核心策略,可以很好地提升模型表現,對齊人類偏好,降低輸出延遲。
模型調優介紹
模型調優作為重要的模型效果優化方式,可以:
提升模型在特定業務/場景表現
降低模型輸出延遲
抑制模型幻覺
對齊人類的價值觀或偏好
使用微調后的輕量級模型替代規模更大的模型
模型在微調過程中,會學習訓練數據中的語氣、表達習慣、自我認知等業務/場景特征(定制輸出)。也由于已經在訓練過程中學習到了大量特定場景的樣例,訓練后模型 One-Shot 或者 Zero-Shot 的 Prompt 效果會比訓練前 Few-Shot 效果更好,這樣可以節省大量輸入 token,從而降低模型輸出延遲。
模型調優流程

百煉模型調優功能還支持:Paraformer語音識別熱詞定制與管理
詳情參見:
支持的模型
文本生成
模型名稱 | 模型代碼 | SFT全參訓練 (sft) | SFT高效訓練 (efficient_sft) | DPO全參訓練 (dpo_full) | DPO高效訓練 (dpo_lora) |
通義千問2.5-開源版-72B | qwen2.5-72b-instruct |
|
| ||
通義千問2.5-開源版-32B | qwen2.5-32b-instruct |
| |||
通義千問2.5-開源版-14B | qwen2.5-14b-instruct |
|
| ||
通義千問2-開源版-72B | qwen2-72b-instruct |
|
| ||
通義千問2-開源版-7B | qwen2-7b-instruct |
|
|
|
|
通義千問1.5-開源版-72B | qwen1.5-72b-chat |
| |||
通義千問1.5-開源版-14B | qwen1.5-14b-chat |
|
| ||
通義千問1.5-開源版-7B | qwen1.5-7b-chat |
|
| ||
通義千問-開源版-72B | qwen-72b-chat |
| |||
通義千問-開源版-14B | qwen-14b-chat |
|
| ||
通義千問-開源版-7B | qwen-7b-chat |
|
| ||
通義千問-Turbo(通義商業版) | qwen-turbo |
|
| ||
通義千問-Turbo-0624(通義商業版) | qwen-turbo-0624 |
|
|
|
|
通義千問-Plus-0723(通義商業版) | qwen-plus-0723 |
|
| ||
通義千問VL-Max-0201 | qwen-vl-max-0201 |
| |||
通義千問VL-Plus | qwen-vl-plus |
| |||
百川2-7B(開源) | baichuan2-7b-chat-v1 |
| |||
Llama2-13B | llama2-13b-chat-v2 |
| |||
Llama2-7B | llama2-7b-chat-v2 |
| |||
ChatGLM2-6B | chatglm-6b-v2 |
|
SFT-有監督微調(Supervised Fine-Tuning)
DPO-直接偏好優化(Direct Preference Optimization)
全參訓練-訓練時間較長,收斂速度較慢,可實現模型新能力的學習和全局效果的優化提升。
高效訓練-訓練時間較短,收斂速度較快,適用于模型局部效果優化。
語音識別-熱詞定制與管理
模型代碼 | SFT 全參訓練 | SFT 高效訓練 | DPO 全參訓練 | DPO 高效訓練 | 熱詞定制與管理 |
paraformer-realtime-v1(僅API) |
| ||||
paraformer-realtime-8k-v1(僅API) |
| ||||
paraformer-8k-v1(僅API) |
| ||||
paraformer-v1(僅API) |
| ||||
paraformer-mtl-v1(僅API) |
| ||||
paraformer-v2(僅API) |
|
SFT-有監督微調(Supervised Fine-Tuning)
DPO-直接偏好優化(Direct Preference Optimization)
全參訓練-訓練時間較長,收斂速度較慢,可實現模型新能力的學習和全局效果的優化提升。
高效訓練-訓練時間較短,收斂速度較快,適用于模型局部效果優化。
熱詞定制與管理-管理熱詞表,提升熱詞表內詞匯的識別效果。
模型調優前必讀
如果您并不是需要對文本生成模型進行調優,請直接前往Paraformer語音識別熱詞定制與管理頁面。
文本生成模型調優雖然能在特定業務/場景取得非常好的效果,但有以下限制:
百煉推薦您在考慮使用文本生成模型調優前先嘗試使用 Prompt 工程(Prompt Engineering)和插件調用(Function Calling)定制化您的應用,模型調優也通常作為改進模型表現“最后的手段”。因為:
在許多任務中,模型最初可能表現不佳,但通過應用正確的 Prompt 技巧可以改進結果,不一定需要使用模型調優。
迭代優化 Prompt、插件,比模型調優的迭代更敏捷、成本更低,因為模型調優的迭代可能需要重新收集數據、清洗優化數據、收集 bad case、發起客戶調研等。
即使最后一定要進行模型調優,最初的 Prompt 工程、插件迭代優化相關工作也不會浪費。您的這些前期工作可以充分地在構建調優數據集時復用(用于構建數據集的輸入)。
您可以前往百煉的Prompt 最佳實踐和插件概述學習相關知識,幫助您在不進行模型調優的情況下激發模型的最大潛力。
快速開始
使用控制臺進行模型調優(微調)
控制臺只支持文本生成模型的調優,詳細使用信息請參見在控制臺使用模型調優。
調優步驟 |
|
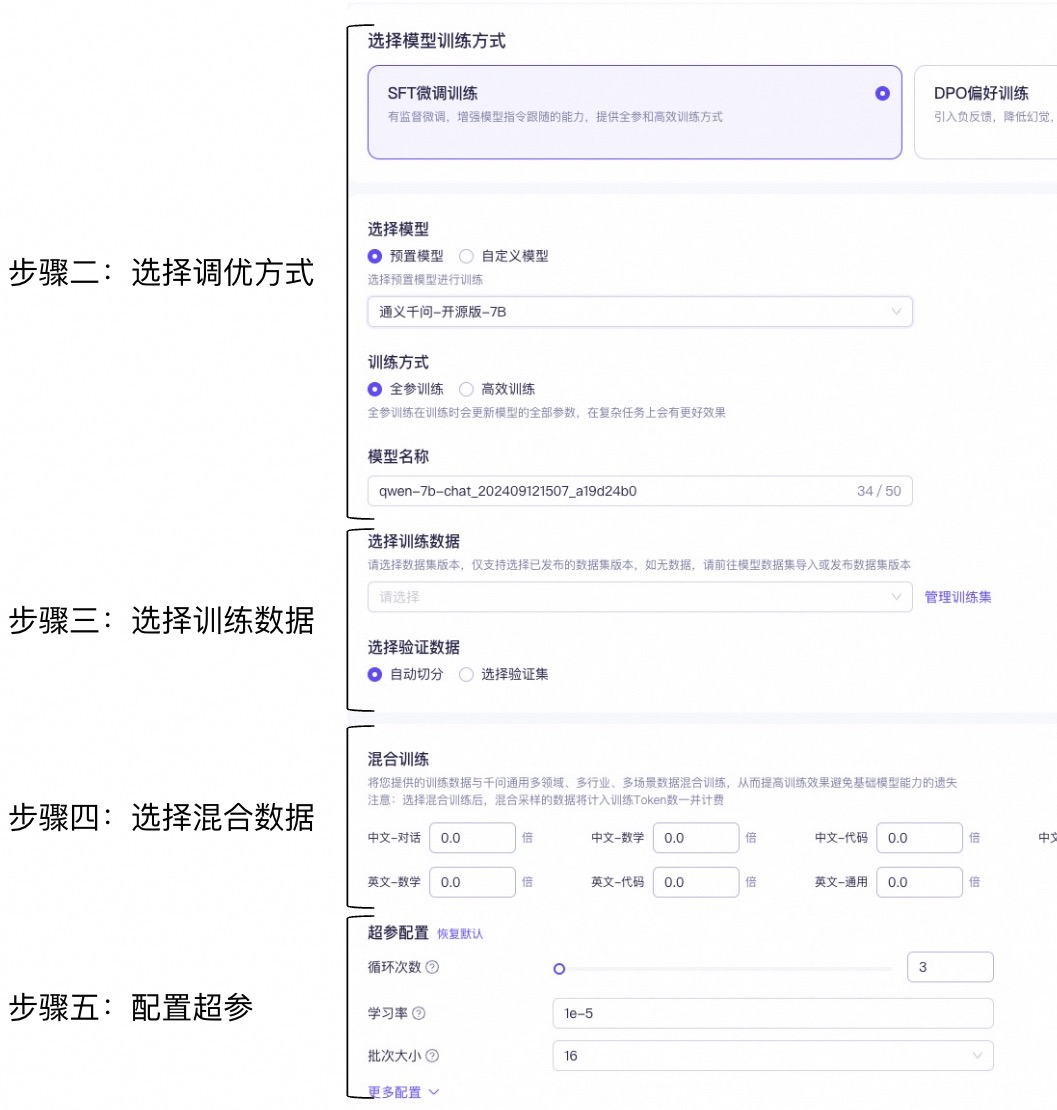
步驟一:前往模型調優頁面訓練新模型。 | |
步驟二:選擇調優方式,請使用 SFT + 高效訓練 + 您需要微調的模型。這個組合訓練時間短,數據要求低。 | |
步驟三:在平臺上選擇構建模型所需的已上傳調優數據集調優數據。 | |
步驟四(可選):選擇混合訓練數據,這里無需添加。 | |
步驟五:配置超參,使用默認參數,這里暫不進行修改。 | |
步驟六:點擊“開始訓練”后,等待模型訓練完畢。 | |
步驟七:使用百煉的模型部署功能部署訓練好的自定義模型,部署好后就可以對微調好的模型進行評測。模型部署相關信息請參見幫助中心:模型部署。 | |
使用命令行或 API 工具進行模型調優
API 支持各種調優功能,完整功能支持請參見使用 API 進行模型訓練。
上傳構建好的數據集
dashscope files.upload -f qwen-fine-tune-sample.jsonl -p fine_tune -d 'training dataset'curl --location --request POST \ 'https://dashscope.aliyuncs.com/api/v1/files' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --form 'files=@"./qwen-fine-tune-sample.jsonl"' \ --form 'descriptions="a sample fine-tune data file for qwen"'創建模型調優任務,將上一步的
response中data.uploaded_files.$.file_id放在training_file_ids中。dashscope fine_tunes.call -m qwen-turbo -t <替換為訓練數據集的file_id>curl --location 'https://dashscope.aliyuncs.com/api/v1/fine-tunes' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json' \ --data '{ "model":"qwen-turbo", "training_file_ids":[ "<替換為訓練數據集的file_id>" ], "hyper_parameters":{ }, "training_type":"sft" }'查看模型調優任務的狀態,在上一步的response中獲取到的
job_id字段,為本次模型調優任務的ID,您可以使用該ID來查詢此模型調優任務的狀態。dashscope fine_tunes.get -j <替換為您的調優任務 id>curl --location 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<替換為您的調優任務 id>' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json'查看模型調優的過程日志,待您查詢到模型調優任務的狀態為
SUCCEEDED時,表示該模型調優任務已完成。您可以通過如下方式查看模型調優任務的日志,用以觀察訓練的效果。dashscope fine_tunes.stream -j <替換為您的調優任務 id>curl --location 'https://dashscope.aliyuncs.com/api/v1/fine-tunes/<替換為您的調優任務 id>/logs?offset=0&line=1000' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json'進行模型部署,將調優模型部署為一個可供調用的服務,從上述調優任務的response中獲取到的
finetuned_output,作為創建模型服務的model_name參數。dashscope deployments.call -m <替換為上一步獲取的finetuned_output>curl --location 'https://dashscope.aliyuncs.com/api/v1/deployments' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json' \ --data '{ "model_name": "<替換為調優任務成功后的模型 ID>", "capacity":2}'查詢模型部署的狀態。部署模型需要一定時間,您可以通過如下方式檢查部署的狀態,當部署狀態為
RUNNING時,表示該模型當前可供調用。dashscope deployments.get -d <替換為部署任務成功后的模型實例 ID>curl --location 'https://dashscope.aliyuncs.com/api/v1/deployments/<替換為部署任務成功后的模型實例 ID>' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json'調用調優模型。當模型部署狀態為
RUNNING時,您可以進行模型的調用。dashscope generation.call -m <替換為部署任務成功后的模型實例 ID> -p '你是誰?'curl --location 'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation' \ --header 'Authorization: Bearer '${DASHSCOPE_API_KEY} \ --header 'Content-Type: application/json' \ --data '{ "model": "<替換為部署任務成功后的模型實例 ID>", "input":{ "messages":[ { "role": "user", "content": "你是誰?" } ] }, "parameters": { "result_format": "message" } }'
調優數據格式
SFT 訓練集
SFT ChatML(Chat Markup Language)格式訓練數據,支持多輪對話和多種角色設置,一行訓練數據展開后結構如下:
{"messages": [
{"role": "system", "content": "<系統輸入1>"},
{"role": "user", "content": "<用戶輸入1>"},
{"role": "assistant", "content": "<模型期望輸出1>"},
{"role": "user", "content": "<用戶輸入2>"},
{"role": "assistant", "content": "<模型期望輸出2>"}
...
...
...
]
}system/user/assistant 區別請參見消息類型。
不支持OpenAI 的name、weight參數,所有的 assistant 輸出都會被訓練。
訓練數據集樣例:
SFT 圖像理解訓練集
SFT圖像理解 ChatML 格式訓練數據(圖片文件會與文本訓練數據在同一目錄下一起打包成 zip),一行訓練數據展開后結構如下:
{"messages":[
{"role":"user",
"content":[
{"text":"<用戶輸入1>"},
{"image":"<圖像文件名1>"}]},
{"role":"assistant",
"content":[
{"text":"<模型期望輸出1>"}]},
{"role":"user",
"content":[
{"text":"<用戶輸入2>"}]},
{"role":"assistant",
"content":[
{"text":"<模型期望輸出2>"}]},
...
...
...
]}system/user/assistant 區別請參見消息類型。
不支持OpenAI 的name、weight參數,所有的 assistant 輸出都會被訓練。

訓練數據集樣例:
DPO 數據集
DPO ChatML 格式訓練數據,一行訓練數據展開后結構如下:
{"messages":[
{"role":"system","content":"<系統輸入>"},
{"role":"user","content":"<用戶輸入1>"},
{"role":"assistant","content":"<模型輸出1>"},
{"role":"user","content":"<用戶輸入2>"},
{"role":"assistant","content":"<模型輸出2>"},
{"role":"user","content":"<用戶輸入3>"}],
"chosen":
{"role":"assistant","content":"<贊同的模型期望輸出3>"},
"rejected":
{"role":"assistant","content":"<反對的模型期望輸出3>"}}模型將 messages 內的所有內容均作為輸入,DPO 用于訓練模型對"<用戶輸入3>"的正負反饋。
system/user/assistant 區別請參見消息類型。
訓練數據集樣例:
數據集構建技巧
數據集的規模要求
對于 SFT 來說,數據集最少需要上千條優質微調數據;對于 DPO 來說,數據集一般需要上百條人類偏好數據。如果數據調優后的模型評測結果不佳,最簡單的改進方法是收集更多數據進行訓練。
如果您缺乏數據,建議構建智能體應用,使用知識庫索引來增強模型能力。當然在很多復雜的業務場景,可以綜合采用模型調優和知識庫檢索結合的技術方案。
以客服場景為例,可以借助模型調優解決客服回答的語氣、表達習慣、自我認知等問題,場景涉及的專業知識可以結合知識庫,動態引入到模型上下文中。
百煉推薦您可以先構建 RAG 應用試運行,在收集到足夠的應用數據后再通過模型調優繼續提升模型表現。
您也可以采用以下策略擴充數據集:
讓大模型模擬生成特定業務/場景的相關內容,輔助您生成更多用于微調數據。(生成模型建議選取表現優異、規模更大的模型)
使用百煉的數據處理功能,對您的數據集進行數據清洗、數據增強。
通過應用場景收集、網絡爬蟲、社交媒體和在線論壇、公開數據集、合作伙伴與行業資源、用戶貢獻等各種方式,人工獲取更多數據。
數據的多樣性與均衡性
模型微調有不同場景,針對具體業務場景時,專業性更重要;而針對問答場景時通用性更重要。您需要根據模型負責的業務模塊或使用場景進行數據用例設計。因此訓練效果好壞并不是僅僅取決于數據量,更需要考慮針對場景的專業性和多樣性。
這里以智能 AI 對話場景為例,介紹一個專業、多樣的數據集應該包含的各種業務場景:
具體業務 | 多樣化場景/業務 |
電商客服 | 活動推送、售前咨詢、售中引導、售后服務、售后回訪、投訴處理等。 |
金融服務 | 貸款咨詢、投資理財顧問、信用卡服務、銀行賬戶管理等。 |
在線醫療 | 病癥咨詢、掛號預約、就診須知、藥品信息查詢、健康小建議等。 |
AI 秘書 | IT 信息、行政信息、HR 信息、員工福利解答、公司日歷查詢等。 |
旅游出行助手 | 旅行規劃、出入境指南、旅行保險咨詢、目的地風土人情介紹等。 |
企業法律顧問 | 合同審核、知識產權保護、合規性檢查、勞動法律答疑、跨境交易咨詢、個案法律分析等。 |
還請特別注意的是各個場景/業務的數據數量應相對均衡,數據比例符合實際場景比例,避免某一類數據過多導致模型偏向于學習該類特征,影響模型的泛化能力。
訓練集與驗證集拆分
當您使用控制臺進行模型調優時,支持自動將一個完整訓練數據集拆分,隨機抽取少量數據(20%)組成驗證集,控制臺也可以在訓練時及時方便地顯示驗證集 Loss 和 Token Accuracy。

使用 API 時,您必須將準備的數據拆分成訓練集和驗證集,推薦兩集合數據量分別為 80% 和 20%。驗證集最好隨機抽取,以保證驗證集在各個場景/業務中相對均衡。驗證集不用于訓練,而是作為模型評測時的評測數據集,驗證您模型調優的效果。
數據長度限制
字符與 token 的對應關系請參考字符串與Token之間的互相轉換。
模型名稱 | token 最大長度 |
通義千問-Plus(通義千問商業版) | 32,768 |
通義千問-Turbo(通義千問商業版) | 8,192 |
通義千問VL-Max | 8,192 |
通義千問VL-Plus | 8,192 |
通義千問2.5-開源版-72B | 13,1072 |
通義千問2.5-開源版-32B | 13,1072 |
通義千問2.5-開源版-14B | 13,1072 |
通義千問2-開源版-72B | 8,192 |
通義千問2-開源版-7B | 8,192 |
通義千問1.5-開源版-72B | 8,192 |
通義千問1.5-開源版-14B | 8,192 |
通義千問1.5-開源版-7B | 8,192 |
通義千問-開源版-72B | 8,192 |
通義千問-開源版-14B | 2,048 |
通義千問-開源版-7B | 2,048 |
在控制臺通過進行設置。

API 通過在模型訓練時使用--max_length(默認值為2048)參數設置。
如果單條數據 token 長度超過設定值,API 側 SFT 微調、API DPO 微調和控制臺 SFT 微調會直接丟棄該條數據,不進行訓練。控制臺 DPO 微調則會自動截斷超出配置長度的后續 token,截短后的數據仍參與訓練。