本文將詳細介紹如何在控制臺進行模型調優任務,并幫助您選擇正確的調優方式與參數。
模型調優流程

步驟一:選擇調優方式
前往模型調優頁面,點擊“訓練新模型”按鈕。
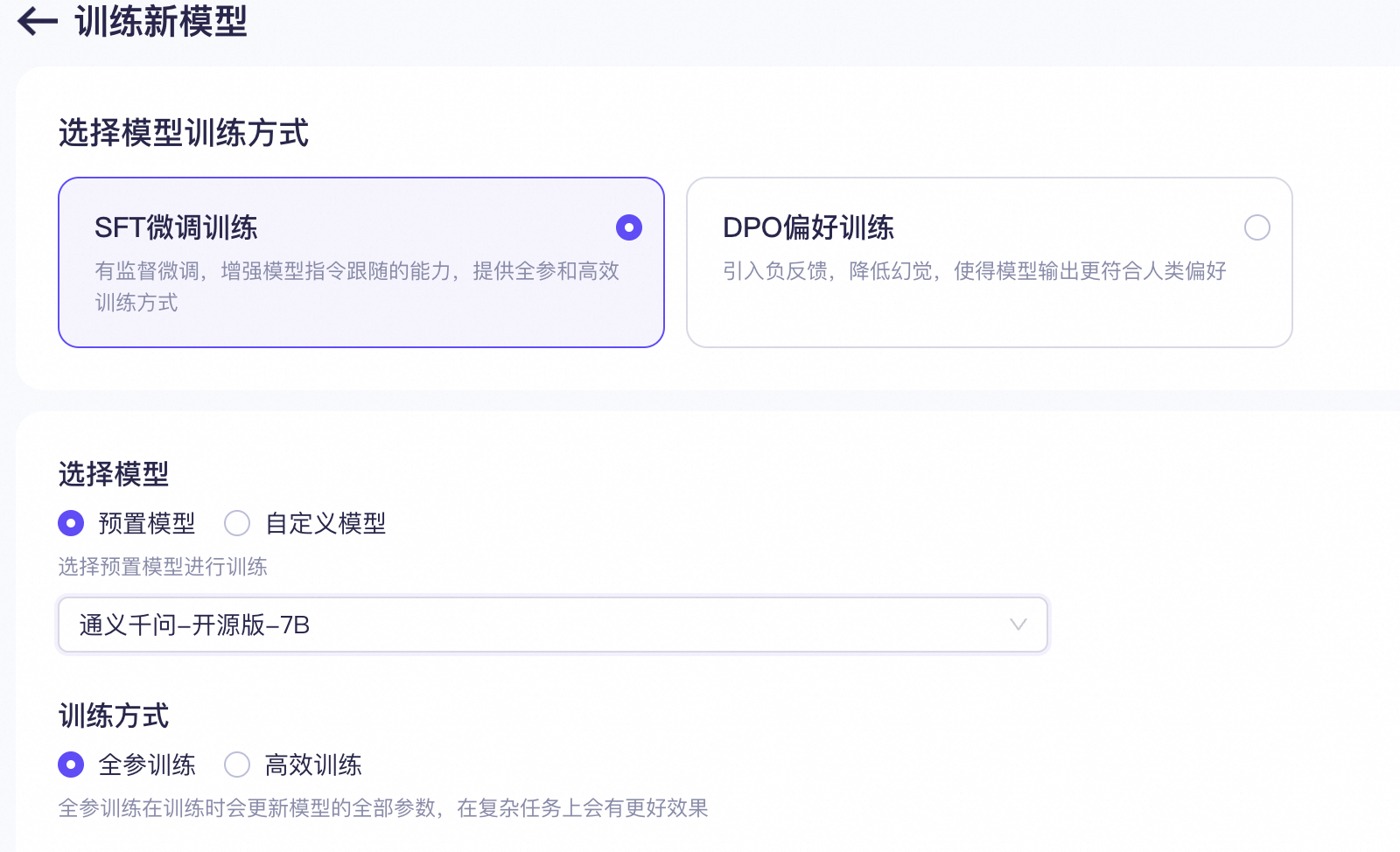
SFT 與 DPO 如何選擇
SFT(有監督微調,Supervised Fine-Tuning)目的是通過針對性的數據集和訓練,提升模型在特定場景/業務中的表現,適合基于大量數據為您的應用進行模型定制,訓練數據集數據只提供正樣本。
DPO(直接偏好優化,Direct Preference Optimization)訓練數據集數據同時提供正負樣本,目的是引入負反饋,降低幻覺,使得模型輸出對齊人類的價值觀或偏好,適合基于用戶反饋,在應用上線后快速迭代優化模型表現。
SFT 訓練集
SFT ChatML(Chat Markup Language)格式訓練數據,支持多輪對話和多種角色設置,一行訓練數據展開后結構如下:
{"messages": [
{"role": "system", "content": "<系統輸入1>"},
{"role": "user", "content": "<用戶輸入1>"},
{"role": "assistant", "content": "<模型期望輸出1>"},
{"role": "user", "content": "<用戶輸入2>"},
{"role": "assistant", "content": "<模型期望輸出2>"}
...
...
...
]
}system/user/assistant 區別請參見消息類型。
不支持OpenAI 的name、weight參數,所有的 assistant 輸出都會被訓練。
訓練數據集樣例:
SFT 圖像理解訓練集
SFT圖像理解 ChatML 格式訓練數據(圖片文件會與文本訓練數據在同一目錄下一起打包成 zip),一行訓練數據展開后結構如下:
{"messages":[
{"role":"user",
"content":[
{"text":"<用戶輸入1>"},
{"image":"<圖像文件名1>"}]},
{"role":"assistant",
"content":[
{"text":"<模型期望輸出1>"}]},
{"role":"user",
"content":[
{"text":"<用戶輸入2>"}]},
{"role":"assistant",
"content":[
{"text":"<模型期望輸出2>"}]},
...
...
...
]}system/user/assistant 區別請參見消息類型。
不支持OpenAI 的name、weight參數,所有的 assistant 輸出都會被訓練。

訓練數據集樣例:
DPO 數據集
DPO ChatML 格式訓練數據,一行訓練數據展開后結構如下:
{"messages":[
{"role":"system","content":"<系統輸入>"},
{"role":"user","content":"<用戶輸入1>"},
{"role":"assistant","content":"<模型輸出1>"},
{"role":"user","content":"<用戶輸入2>"},
{"role":"assistant","content":"<模型輸出2>"},
{"role":"user","content":"<用戶輸入3>"}],
"chosen":
{"role":"assistant","content":"<贊同的模型期望輸出3>"},
"rejected":
{"role":"assistant","content":"<反對的模型期望輸出3>"}}模型將 messages 內的所有內容均作為輸入,DPO 用于訓練模型對"<用戶輸入3>"的正負反饋。
system/user/assistant 區別請參見消息類型。
訓練數據集樣例:
兩種訓練方式的數據量要求請參見數據集的規模要求。
百煉推薦您以先 SFT 后 DPO 的順序使用模型調優:
在應用上線前,先收集足夠多(1000+)的特定場景/業務的正樣本,即收集場景/業務輸入+模型期望輸出,進行SFT 訓練。
您的應用試運行/上線后,收集足夠多(100+)的用戶反饋(如:點贊、點踩、反饋)或者 bad case,將這些數據制作成 DPO 訓練集,進行 DPO 訓練。
模型選擇
如果您是第一次進行模型調優,請選擇您期望的預置模型。
如果您是因為模型訓練效果不好需要再次訓練某個模型,請選擇自定義模型 > 您需要二次訓練的模型。
支持的預置模型:
模型名稱 | 模型代碼 | SFT全參訓練 (sft) | SFT高效訓練 (efficient_sft) | DPO全參訓練 (dpo_full) | DPO高效訓練 (dpo_lora) |
通義千問2.5-開源版-72B | qwen2.5-72b-instruct |
|
| ||
通義千問2.5-開源版-32B | qwen2.5-32b-instruct |
| |||
通義千問2.5-開源版-14B | qwen2.5-14b-instruct |
|
| ||
通義千問2-開源版-72B | qwen2-72b-instruct |
|
| ||
通義千問2-開源版-7B | qwen2-7b-instruct |
|
|
|
|
通義千問1.5-開源版-72B | qwen1.5-72b-chat |
| |||
通義千問1.5-開源版-14B | qwen1.5-14b-chat |
|
| ||
通義千問1.5-開源版-7B | qwen1.5-7b-chat |
|
| ||
通義千問-開源版-72B | qwen-72b-chat |
| |||
通義千問-開源版-14B | qwen-14b-chat |
|
| ||
通義千問-開源版-7B | qwen-7b-chat |
|
| ||
通義千問-Turbo(通義商業版) | qwen-turbo |
|
| ||
通義千問-Turbo-0624(通義商業版) | qwen-turbo-0624 |
|
|
|
|
通義千問-Plus-0723(通義商業版) | qwen-plus-0723 |
|
| ||
通義千問VL-Max-0201 | qwen-vl-max-0201 |
| |||
通義千問VL-Plus | qwen-vl-plus |
| |||
百川2-7B(開源) | baichuan2-7b-chat-v1 |
| |||
Llama2-13B | llama2-13b-chat-v2 |
| |||
Llama2-7B | llama2-7b-chat-v2 |
| |||
ChatGLM2-6B | chatglm-6b-v2 |
|
全參訓練與高效訓練
全參訓練通過全量更新模型參數的方式進行學習。
高效訓練采用低秩適應(Low-Rank Adaptation,LoRA)的方式,通過矩陣分解的方法,更新分解后的低秩部分參數。
由于兩種訓練方式的費用相同,百煉推薦您如果模型支持全參訓練,請優先選擇全參訓練,因為全參訓練效果比高效訓練效果要好,性價比更高。
步驟二:選擇訓練數據

數據集構建技巧請參考數據集構建技巧。上傳微調數據集請前往模型數據頁面。
選擇驗證數據 > 自動切分 的比例為訓練集 : 驗證集 = 8 : 2。 如果您希望改變這個比例,您可以手動從完整數據集中切分出驗證集單獨上傳, 然后 選擇驗證數據 > 選擇驗證集 > 選擇您手動切分上傳的驗證集。
步驟三(可選):添加混合訓練數據
百煉提供添加混合訓練數據功能,您可以將您的訓練數據與千問通用多領域、多行業、多場景數據混合訓練,從而提高訓練效果避免模型基礎能力的遺失。

百煉推薦根據您的實際業務或場景添加合適的混合訓練數據類目和比例,比如自定義場景數據:“中文-對話”場景 = 1 :1,您就可以把“中文-對話”場景倍率設為 1.0 倍。
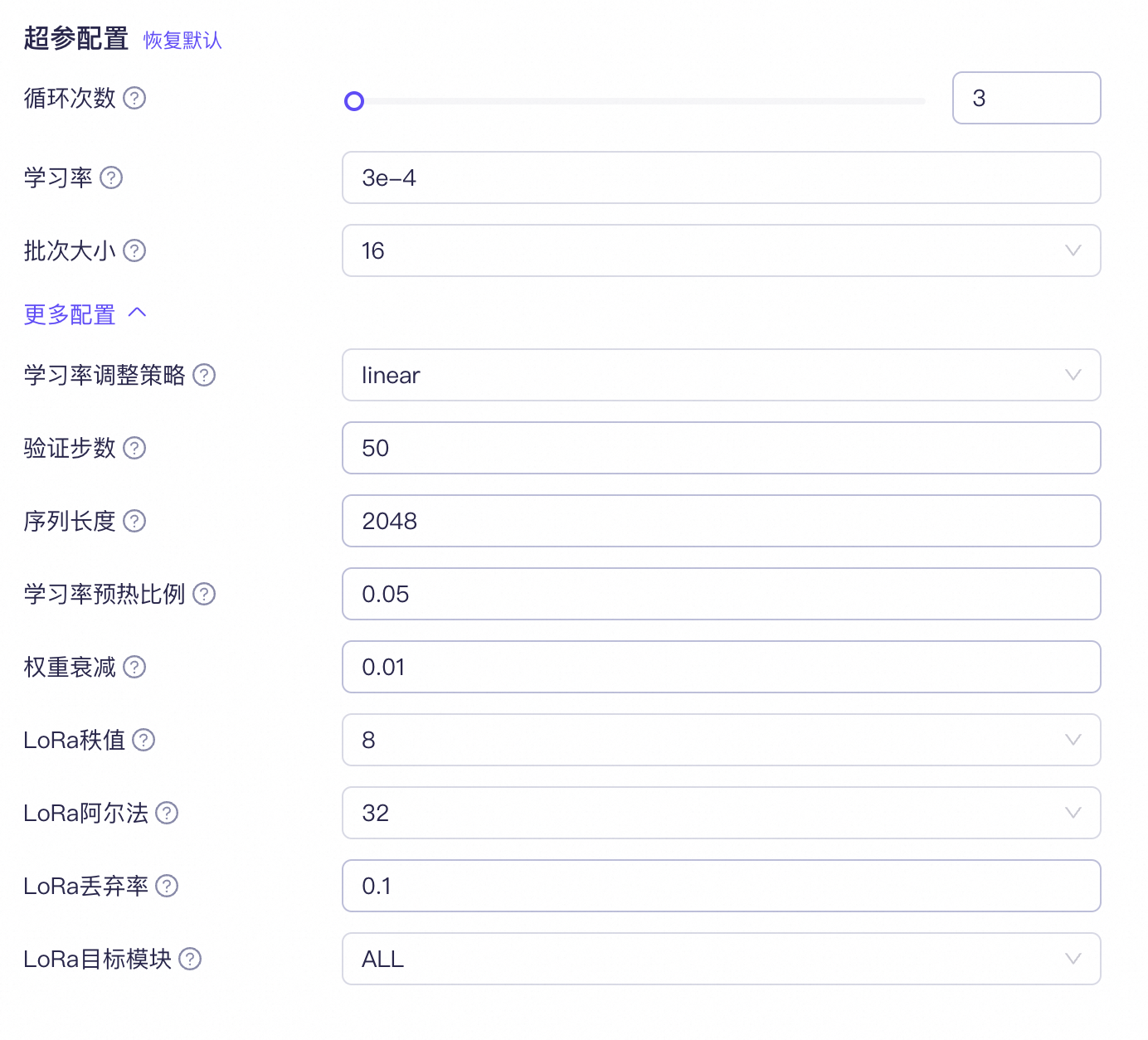
步驟四:配置超參
如果您沒有微調經驗,百煉推薦您盡量不要調整“更多配置”內的參數設置。
超參介紹:(并不是所有模型都支持所有參數的調節,請以控制臺顯示為準)
超參名稱 | 推薦設置 | 超參作用 | |
循環次數 | 數據量 < 10,000, 循環 3~5次 數據量 > 10,000, 循環 1~2次 具體需要結合實驗效果進行判斷 | 模型遍歷訓練的次數,請根據模型調優實際使用經驗進行調整。 模型訓練循環次數越多,訓練時間越長,訓練費用越高。 |
|
學習率 | 高效訓練:1e-4量級 全參訓練:1e-5量級 | 控制模型修正權重的強度。 如果學習率設置得太高,模型參數會劇烈變化,導致微調后的模型表現不一定更好,甚至變差; 如果學習率太低,微調后的模型表現不會有太大變化。 | |
批次大小 | 使用默認值 | 一次性送入模型進行訓練的數據條數,參數過小會顯著延長訓練時間,推薦使用默認值。 | |
學習率調整策略 | 推薦選擇“linear”或“Inverse_sqrt”。 | 在模型訓練中動態調整學習率的策略。 各策略詳情請參考學習率調整策略介紹。 | |
驗證步數 | 使用默認值 | 訓練階段針對模型的驗證間隔步長,用于階段性評估模型訓練準確率、訓練損失。 該參數影響模型調優進行時的 Validation Loss 和 Validation Token Accuracy 的顯示頻率。 | |
序列長度 | 設置為模型支持的最大值 | 指的是單條訓練數據 token 支持的最大長度。如果單條數據 token 長度超過設定值: SFT 微調會直接丟棄該條數據,不進行訓練; DPO 微調則會自動截斷超出配置長度的后續 token,截短后的數據仍會被訓練。 字符與 token 之間的關系請參考 Token和字符串之間怎么換算 | |
學習率預熱比例 | 使用默認值 | 學習率預熱占用總的訓練過程的比例。學習率預熱是指學習率在訓練開始后由一個較小值線性遞增至學習率設定值。 該參數主要是限制模型參數在訓練初始階段的變化幅度,從而幫助模型更穩定地進行訓練。 比例過大效果與過低的學習率相同,會導致微調后的模型表現不會有太大變化。 比例過小效果與過高的學習率相同,可能導致微調后的模型表現不一定更好,甚至變差。
| |
權重衰減 | 使用默認值 | L2正則化強度。L2正則化能在一定程度上保持模型的通用能力。數值過大會導致模型微調效果不明顯。 | |
LoRA秩值 | 設置為模型支持的最大值 | LoRA訓練中的低秩矩陣的秩大小。秩越大調優效果會更好一點,但訓練會略慢。 | |
LoRA阿爾法 | 使用默認值 | 用于控制原模型權重與LoRA的低秩修正項之間的結合縮放系數。 較大的Alpha值會給予LoRA修正項更多權重,使得模型更加依賴于微調任務的特定信息; 而較小的Alpha值則會讓模型更傾向于保留原始預訓練模型的知識。 | |
LoRA丟棄率 | 使用默認值 | LoRA訓練中的低秩矩陣值的丟棄率。 使用推薦數值能增強模型通用化能力。 數值過大會導致模型微調效果不明顯。 | |
LoRA目標模塊 | 推薦設置為 ALL | 選擇模型的全部或特定模塊層進行微調優化。 ALL是對所有的參數都加上 LoRA 訓練; AUTO是指模型的關鍵參數加上 LoRA 訓練。 |
學習率調整策略介紹
“學習率調整策略” 是在 超參配置 > 更多配置 下的第一個配置,配置包含8種不同的策略。
策略詳情請參見:
Linear:學習率線性遞減。 使用場景:適合訓練過程較短的任務。
| Polynomial:學習率按照一個預定義的多項式函數隨訓練迭代次數或周期數逐漸減少。 使用場景:Polynomial 可以更精細控制學習率減少速度,適用于任務比較復雜的場景。 但內置多項式系數為1,效果同 Linear,不推薦使用。
|
Cosine:學習率變化符合余弦函數曲線。 使用場景:適合需要進行精細調整、訓練過程較長的任務。 | Cosine_with_restarts:學習率按照余弦函數的形狀周期性地減少至某個最小值,而且在每個周期結束時,學習率會“重啟”成預設值,然后開啟下一周期。 使用場景:適用于需要模型從局部最優解中跳出來,嘗試尋找更好全局解的情況。 但經過實測,學習率并不會在函數曲線底部“重啟”成預設值,不推薦使用。 |
Constant:學習率不變, “學習率預熱比例”參數無效。 使用場景:適合初步探索模型性能。 | Constant_with_warmup:學習率不變,但“學習率預熱比例”參數有效。 使用場景:適合初步探索模型性能。 |
Inverse_sqrt:學習率逐漸減小,減小量與迭代次數的平方根的倒數正相關。 使用場景:適合于 SFT 微調,能較好地平衡學習效率與模型收斂。
| reduce_lr_on_plateau:當監控的指標(驗證損失或驗證準確率)在連續多個epoch內沒有顯著改進時,自動降低學習率。 使用場景:當模型很難進一步提高性能時,reduce_lr_on_plateau 可以幫助模型繼續優化和提升。
|

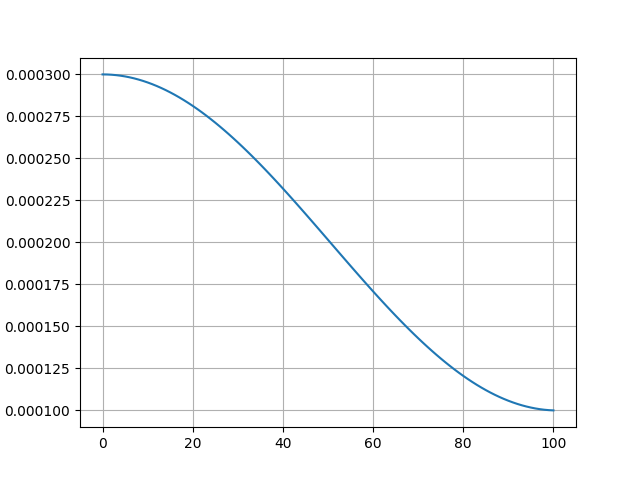

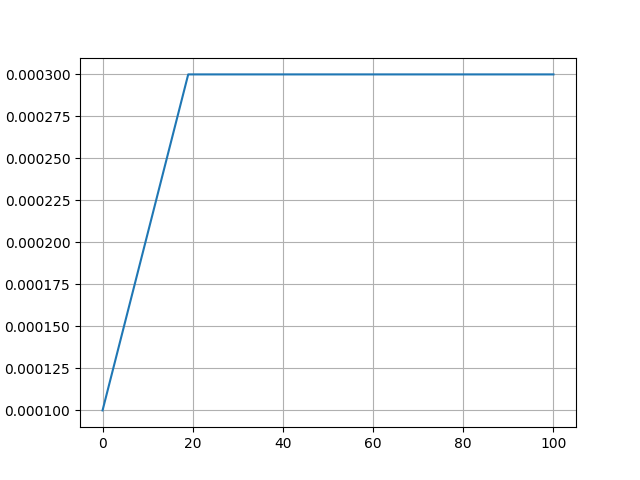

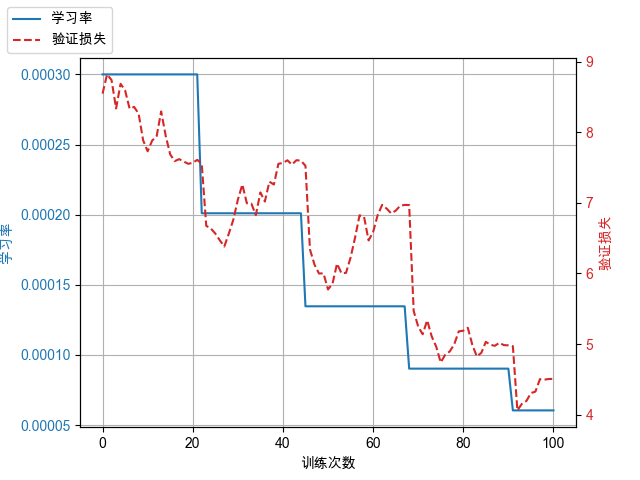
圖中學習率下限梯度、最小值均為示意,實際學習率下限梯度、最小值以實際使用為準。
步驟六:訓練模型
點擊“開始訓練” > 確認“模型調優計費提醒” > 模型開始訓練

特定模型訓練時點擊“查看”按鈕可以查詢模型訓練詳情,包括:訓練損失(Training Loss)、驗證損失(Validation Loss)、驗證準確率(Validation Token Accuracy)、模型訓練過程中實時產生的日志。
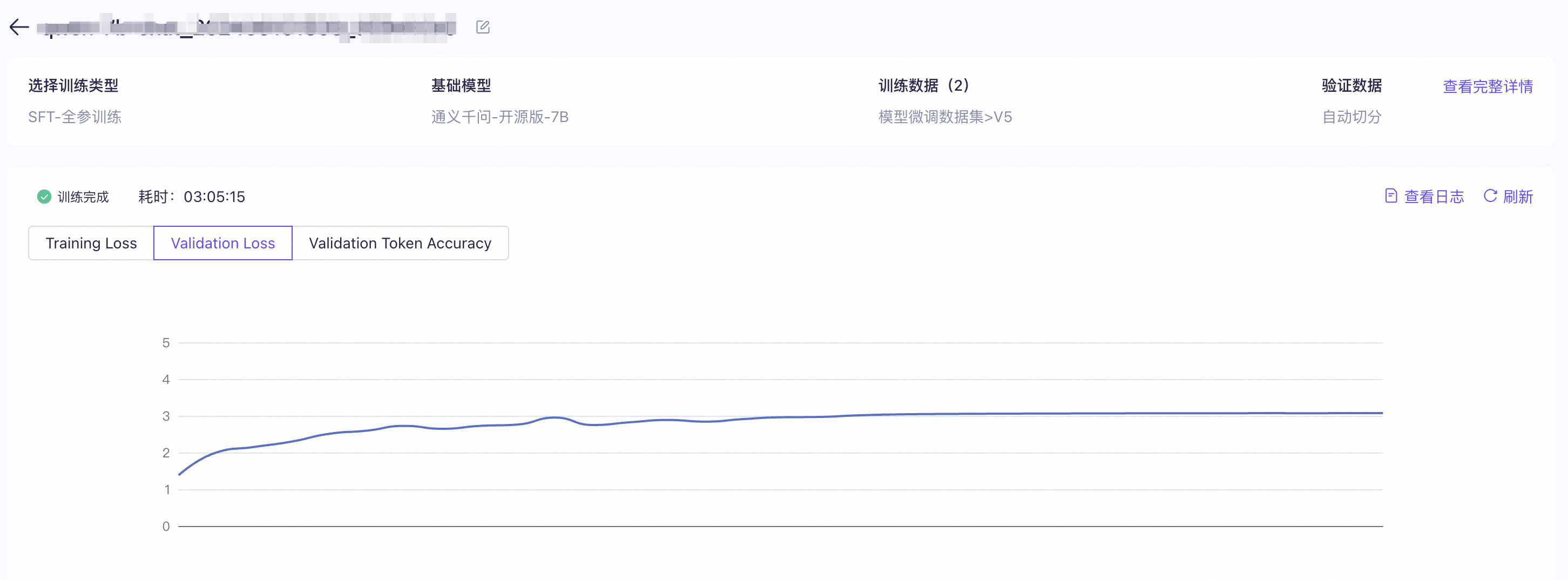
訓練完成后,請確認訓練損失(Training Loss)與驗證損失(Validation Loss)的差異變化趨勢。
如果訓練損失逐漸減小而驗證損失逐漸增大,說明模型已經過擬合訓練數據,訓練可能失敗,訓練效果可能不佳。建議按照以下推薦方法(推薦程度有先后順序)進行優化,重新訓練,提升訓練效果:
使用數據增強,增加訓練數據多樣性和數據量。
收集更多訓練數據,增加訓練數據多樣性和數據量。
調整超參,包括:減少“訓練次數”、減小“學習率”、減小“批次大小”、增大“權重衰減”、提高“LoRA丟棄率”、提高“學習率預熱比例”。
如果訓練損失沒有明顯變化或逐漸增大(不常見),說明模型欠擬合訓練數據,訓練失敗。建議按照以下推薦方法(推薦程度有先后順序)進行優化,繼續訓練:
檢查數據質量,確保數據清洗充分。
調整超參,包括:增大“訓練次數”、增大“學習率”、增大“批次大小”、減小“權重衰減”、降低“LoRA丟棄率”、降低“學習率預熱比例”。
如果沒有上述情況請繼續后續步驟。
步驟七:部署模型
使用百煉的模型部署功能部署訓練好的自定義模型,部署好后就可以對微調好的模型進行評測。模型部署相關信息請參見幫助中心:模型部署。
步驟八:評測模型
如果您有多個業務場景或者添加了混合訓練數據,在模型評測時,建議您根據場景拆分評測集,分別評測各個場景在微調后的表現是否滿足您的需求。
使用百煉模型評測功能評估自定義模型的訓練效果,相關信息請參見幫助中心:模型評測簡介。
評測方式
百煉支持以下三種評測方式:人工評測、自動評測和基線評測。
人工評測:由您本人或您邀請的業務專家參與,基于選定的評測維度,對待測模型的輸出效果進行人工評價。這種方式的優勢在于業務專家能夠通過實際操作產品等方式,來驗證輸出內容中的每個細節及步驟的正確性。但局限性也很明顯,即評測成本較高、效率低,并且多人評測時可能會受到主觀因素的干擾。
自動評測:全過程無需人工參與,百煉將基于內置的深度學習指標和AI評測器,自動對模型的輸出效果進行評分。這種方式的優勢在于高效率以及評測的公正性。局限性在于AI評測器的評測效果高度依賴于人為初始設定的評分維度、步驟和標準,并且它無法像人工評測那樣驗證輸出內容中每個細節和步驟的正確性。
基線評測:基于預置基線評測集(包括C-Eval/CMMLU等主流榜單評測集)對待測模型的各項基礎通用能力進行自動評測,適用于對已微調模型的基本效果進行回歸評測(雖然微調有可能提升模型在特定任務上的效果,但有時也會降低模型的通用能力),避免模型通用能力的下降和丟失。
通常最佳實踐是將上述三種評測方式結合起來。一個可能的場景是:先通過初始的人工評測確定一套評測維度,并形成配套可自動化執行的評分步驟和標準。再將這一整套評分體系應用于自動評測中,讓百煉按照設定進行自動評測,快速從多個候選模型中選出最優者。最后通過人工評測仔細對比模型輸出在結構組織、倫理合規等方面的細微差異。如果針對特定領域進行了模型微調,同時希望確保模型的通用能力沒有明顯下降,則可以進行基線評測。

常見問題
什么時候可以使用模型調優功能?
如果您并不是需要對文本生成模型進行調優,請直接前往Paraformer語音識別熱詞定制與管理頁面。
文本生成模型調優雖然能在特定業務/場景取得非常好的效果,但有以下限制:
百煉推薦您在考慮使用文本生成模型調優前先嘗試使用 Prompt 工程(Prompt Engineering)和插件調用(Function Calling)定制化您的應用,模型調優也通常作為改進模型表現“最后的手段”。因為:
在許多任務中,模型最初可能表現不佳,但通過應用正確的 Prompt 技巧可以改進結果,不一定需要使用模型調優。
迭代優化 Prompt、插件,比模型調優的迭代更敏捷、成本更低,因為模型調優的迭代可能需要重新收集數據、清洗優化數據、收集 bad case、發起客戶調研等。
即使最后一定要進行模型調優,最初的 Prompt 工程、插件迭代優化相關工作也不會浪費。您的這些前期工作可以充分地在構建調優數據集時復用(用于構建數據集的輸入)。
您可以前往百煉的Prompt 最佳實踐和插件概述學習相關知識,幫助您在不進行模型調優的情況下激發模型的最大潛力。
如果模型調優后,評測效果不好怎么辦?
如果您使用的是人工評測,請檢查評測維度是否符合業務或場景。
收集在模型評測時評測結果不佳的測試用例,統計分析評測結果不佳的原因,根據分析結果調整訓練數據集,繼續迭代微調模型。
根據評測結果不佳的用例生成 DPO 用例,對模型進行 DPO 訓練。
模型調優、模型部署、模型評測怎么收費?
模型調優計費方式與模型調用計費方式相同,但費用會更高。模型評測按照模型調用計費。訓練好的模型在部署后只收取部署費用,不收取模型的調用費用。詳細數據請參考計費項與定價。