MaxCompute支持通過delete、update操作,在行級別刪除或更新Transactional表中的數據。
本文中的命令您可以在如下工具平臺執行:
前提條件
執行delete、update操作前需要具備目標Transactional表的讀取表數據權限(Select)及更新表數據權限(Update)。授權操作請參見MaxCompute權限。
功能介紹
MaxCompute的delete、update功能具備與傳統數據庫用法類似的刪除或更新表中指定行的能力。
實際使用delete、update功能時,系統會針對每一次刪除或更新操作自動生成用戶不可見的Delta文件,用于記錄刪除或更新的數據信息。具體實現原理如下:
delete:Delta文件中使用txnid(bigint)和rowid(bigint)字段標識Transactional表的Base文件(表在系統中的存儲形式)中的記錄在哪次刪除操作中被刪除。例如,表t1的Base文件為f1,且內容為
a, b, c, a, b,當執行delete from t1 where c1='a';命令后,系統會生成一個單獨的f1.delta文件。假設txnid是t0,則f1.delta的內容是((0, t0), (3, t0)),標識行0和行3,在txnt0中被刪除了。如果再執行一次delete操作,系統會又生成一個f2.delta文件,該文件仍然是根據Base文件f1編號,讀取文件時,基于Base文件f1和當前所有Delta文件的共同表示結果,讀取沒有被刪除的數據。update:update操作會轉換為delete+insert into的實現邏輯。
delete、update功能具備的優勢如下:
寫數據量下降
此前,MaxCompute通過
insert into或insert overwrite操作方式刪除或更新表數據,更多信息,請參見插入或覆寫數據(INSERT INTO | INSERT OVERWRITE)。當用戶需要更新表或分區中的少量數據時,如果通過insert操作實現,需要先讀取表的全量數據,然后通過select操作更新數據,最后通過insert操作將全量數據寫回表中,效率較低。使用delete、update功能后,系統無需寫回全部數據,寫數據量會顯著下降。說明對于按量計費場景,
delete、update和insert overwrite任務的寫數據部分不收費,但是delete、update任務需要按分區過濾讀取需要變更的數據,用于標注刪除的記錄或寫回更新的記錄,而讀取數據部分依然遵照SQL作業按量計費模型收費,所以delete、update任務相比insert overwrite任務,費用并不能因為寫數據量減少而減少。對于包年包月場景,
delete、update減少了寫數據資源消耗,與insert overwrite相比,相同資源可以運行更多的任務。
可直接讀取最新狀態的表
此前,MaxCompute在批量更新表數據場景使用的是拉鏈表,該方式需要在表中增加
start_date和end_date輔助列,標識某一行記錄的生命周期。當查詢表的最新狀態時,系統需要從大量數據中根據時間戳獲取表的最新狀態,使用起來不夠直觀。使用delete、update功能后,系統可以基于表的Base文件和Delta文件的共同表示結果,直接讀取最新狀態的表。
多次delete、update操作會使Transactional表的底層存儲增大,會提高存儲和后續查詢費用,且影響后續查詢效率,建議定期合并(Compact)后臺數據。更多合并操作信息,請參見合并Transactional表文件。
當作業并發運行且操作的目標表相同時,可能會出現作業沖突問題,更多信息,請參見ACID語義。
應用場景
delete、update功能適用于隨機、低頻刪除或更新表或分區中的少量數據。例如,按照T+1周期性地批量對表或分區中5%以下的行刪除或更新數據。
delete、update功能不適用于高頻更新、刪除數據或實時寫入目標表場景。
使用限制
delete、update功能及對應Transactional表、Delta Table表的使用限制如下:Delta Table表
Update語法不支持修改PK列。
注意事項
通過delete、update操作刪除或更新表或分區內的數據時,注意事項如下:
如果需要對表中較少數據進行刪除或更新操作,且操作和后續讀數據的頻率也不頻繁,建議使用
delete、update操作,并且在多次執行刪除或更新操作之后,請合并表的Base文件和Delta文件,降低表的實際存儲。更多信息,請參見合并Transactional表文件。如果刪除或更新行數較多(超過5%)并且操作不頻繁,但后續對該表的讀操作比較頻繁,建議使用
insert overwrite或insert into操作。更多信息,請參見插入或覆寫數據(INSERT INTO | INSERT OVERWRITE)。例如,某業務場景為每次刪除或更新10%的數據,一天更新10次。建議根據實際情況評估
delete、update操作產生的費用及后續對讀性能的消耗是否小于每次使用insert overwrite或insert into操作產生的費用及后續對讀性能的消耗,比較兩種方式在具體場景中的效率,選擇更優方案。刪除數據會生成Delta文件,所以刪除數據不一定能降低存儲,如果您希望通過
delete操作刪除數據來降低存儲,請合并表的Base文件和Delta文件,降低表的實際存儲。更多信息,請參見合并Transactional表文件。MaxCompute會按照批處理方式執行
delete、update作業,每一條語句都會使用資源并產生費用,建議您使用批量方式刪除或更新數據。例如您通過Python腳本生成并提交了大量行級別更新作業,且每條語句只操作一行或者少量行數據,則每條語句都會產生與SQL掃描輸入數據量對應的費用,并使用相應的計算資源,多條語句累加時將明顯增加費用成本,降低系統效率。命令示例如下。推薦方案:
UPDATE table1 SET col1= (SELECT value1 FROM table2 WHERE table1.id = table2.id AND table1.region = table2.region);不推薦方案:
UPDATE table1 SET col1=1 WHERE id='2021063001'AND region='beijing'; UPDATE table1 SET col1=2 WHERE id='2021063002'AND region='beijing';
刪除數據(DELETE)
delete操作用于刪除Transactional或Delta Table表中滿足指定條件的單行或多行數據。
命令格式
delete from <table_name> [where <where_condition>];參數說明
table_name:必填。待執行
delete操作的Transactional或Delta Table表名稱。where_condition:可選。WHERE子句,用于篩選滿足條件的數據。更多WHERE子句信息,請參見WHERE子句(where_condition)。如果不帶WHERE子句,會刪除表中的所有數據。
使用示例
示例1:創建非分區表acid_delete,并導入數據,執行
delete操作刪除滿足指定條件的行數據。命令示例如下:--創建Transactional表acid_delete。 create table if not exists acid_delete(id bigint) tblproperties ("transactional"="true"); --插入數據。 insert overwrite table acid_delete values(1),(2),(3),(2); --查看插入結果。 select * from acid_delete; --返回結果 +------------+ | id | +------------+ | 1 | | 2 | | 3 | | 2 | +------------+ --刪除id為2的行,如果在MaxCompute客戶端(odpscmd)執行,需要輸入yes|no確認。 delete from acid_delete where id = 2; --查看結果表中數據只有1、3。 select * from acid_delete; --返回結果 +------------+ | id | +------------+ | 1 | | 3 | +------------+示例2:創建分區表acid_delete_pt,并導入數據,執行
delete操作刪除滿足指定條件的行。命令示例如下:--創建Transactional表acid_delete_pt。 create table if not exists acid_delete_pt(id bigint) partitioned by(ds string) tblproperties ("transactional"="true"); --添加分區。 alter table acid_delete_pt add if not exists partition (ds= '2019'); alter table acid_delete_pt add if not exists partition (ds= '2018'); --插入數據。 insert overwrite table acid_delete_pt partition (ds='2019') values(1),(2),(3); insert overwrite table acid_delete_pt partition (ds='2018') values(1),(2),(3); --查看插入結果。 select * from acid_delete_pt; --返回結果 +------------+------------+ | id | ds | +------------+------------+ | 1 | 2018 | | 2 | 2018 | | 3 | 2018 | | 1 | 2019 | | 2 | 2019 | | 3 | 2019 | +------------+------------+ --刪除分區為2019且id為2的數據,如果在MaxCompute客戶端(odpscmd)執行,需要輸入yes|no確認。 delete from acid_delete_pt where ds='2019' and id = 2; --查看結果表中已刪除分區為2019且id為2的數據。 select * from acid_delete_pt; --返回結果 +------------+------------+ | id | ds | +------------+------------+ | 1 | 2018 | | 2 | 2018 | | 3 | 2018 | | 1 | 2019 | | 3 | 2019 | +------------+------------+示例3:創建目標表acid_delete_t和關聯表acid_delete_s,通過關聯操作刪除滿足指定條件的行。命令示例如下:
--創建目標Transactional表acid_delete_t和關聯表acid_delete_s。 create table if not exists acid_delete_t(id int,value1 int,value2 int) tblproperties ("transactional"="true"); create table if not exists acid_delete_s(id int,value1 int,value2 int); --插入數據。 insert overwrite table acid_delete_t values(2,20,21),(3,30,31),(4,40,41); insert overwrite table acid_delete_s values(1,100,101),(2,200,201),(3,300,301); --刪除acid_delete_t表中id與acid_delete_s表中id不匹配的行。如果在MaxCompute客戶端(odpscmd)執行,需要輸入yes|no確認。 delete from acid_delete_t where not exists (select * from acid_delete_s where acid_delete_t.id=acid_delete_s.id); --查看結果表中只有id為2、3的數據。 select * from acid_delete_t; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 20 | 21 | | 3 | 30 | 31 | +------------+------------+------------+示例4:創建Delta Table表mf_dt,并導入數據,執行
delete操作刪除滿足指定條件的行。命令示例如下:--創建目標Delta Table表mf_dt。 create table if not exists mf_dt (pk bigint not null primary key, val bigint not null) partitioned by (dd string, hh string) tblproperties ("transactional"="true"); --插入數據 insert overwrite table mf_dt partition (dd='01', hh='02') values (1, 1), (2, 2), (3, 3); --查看插入結果 select * from mf_dt where dd='01' and hh='02'; --返回結果 +------------+------------+----+----+ | pk | val | dd | hh | +------------+------------+----+----+ | 1 | 1 | 01 | 02 | | 3 | 3 | 01 | 02 | | 2 | 2 | 01 | 02 | +------------+------------+----+----+ --刪除分區為01和02,且val為2的數據。 delete from mf_dt where val = 2 and dd='01' and hh='02'; --查看結果表中只有val為1、3的數據 select * from mf_dt where dd='01' and hh='02'; --返回結果 +------------+------------+----+----+ | pk | val | dd | hh | +------------+------------+----+----+ | 1 | 1 | 01 | 02 | | 3 | 3 | 01 | 02 | +------------+------------+----+----+
清空列數據
使用clear column命令清空普通表的列,將不再使用的列數據從磁盤刪除并置NULL,從而達到降低存儲成本的目的。
命令格式
ALTER TABLE <table_name> [partition ( <pt_spec>[, <pt_spec>....] )] CLEAR COLUMN column1[, column2, column3, ...] [without touch];參數說明
table_name:將要執行清空列數據的表名稱。
column1 , column2 ...:將要被清空數據的列名稱。partition:指定分區,若未指定,則表示操作所有分區。
pt_spec:分區描述,格式為
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。without touch:表示不更新
LastDataModifiedTime;若未指定,則會更新LastDataModifiedTime。
說明目前默認指定without touch,計劃在下一階段支持未指定without touch的清空列數據行為,即若未指定without touch,則會更新
LastDataModifiedTime。使用限制
不支持對具有非空屬性的列進行clear column操作,可以手動取消not nullable屬性:
alter table <table_name> change column <old_col_name> null;ACID表不支持清空列數據。
Cluster不支持清空列數據。
不支持對嵌套類型內部執行清空列數據操作。
不支持清空所有列數據(DROP TABLE可以起到相同效果,且性能更好)。
注意事項
Clear Column操作不會改變表的Archive屬性。
對嵌套類型的列執行Clear Column操作可能會失敗。
失敗的情況為在列式(Columnar)嵌套類型關閉的情況下對含有Columnar嵌套類型的表做Clear Column操作。
Clear Column命令執行需要依賴Storage Service在線服務,在作業量多的情況下可能需要排隊導致任務變慢。
Clear Column操作需要使用計算資源對數據進行讀取與寫入,所以針對包年包月用戶,會占用計算資源,對按量付費用戶,會產生和SQL一樣的費用。(目前正在邀測中,暫時不進行收費。)
使用示例
--創建表 create table if not exists mf_cc(key string, value string, a1 BIGINT , a2 BIGINT , a3 BIGINT , a4 BIGINT) partitioned by(ds string, hr string); --添加分區 alter table mf_cc add if not exists partition (ds='20230509', hr='1641'); --插入數據 insert into mf_cc partition (ds='20230509', hr='1641') values("key","value",1,22,3,4); --查詢數據 select * from mf_cc where ds='20230509' and hr='1641'; --返回結果 +-----+-------+------------+------------+--------+------+---------+-----+ | key | value | a1 | a2 | a3 | a4 | ds | hr | +-----+-------+------------+------------+--------+------+---------+-----+ | key | value | 1 | 22 | 3 | 4 | 20230509| 1641| +-----+-------+------------+------------+--------+------+---------+-----+ --清空列數據 alter table mf_cc partition(ds='20230509', hr='1641') clear column key,a1 without touch; --查詢數據 select * from mf_cc where ds='20230509' and hr='1641'; --返回結果,key和a1的數據已經變成null +-----+-------+------------+------------+--------+------+---------+-----+ | key | value | a1 | a2 | a3 | a4 | ds | hr | +-----+-------+------------+------------+--------+------+---------+-----+ | null| value | null | 22 | 3 | 4 | 20230509| 1641| +-----+-------+------------+------------+--------+------+---------+-----+下圖為
lineitem表(aliorc格式)的總存儲大小隨著對每一列進行Clear Column后的變化過程。lineitem表共16列,有Bigint、Decimal、Char、Date、Varchar幾種類型。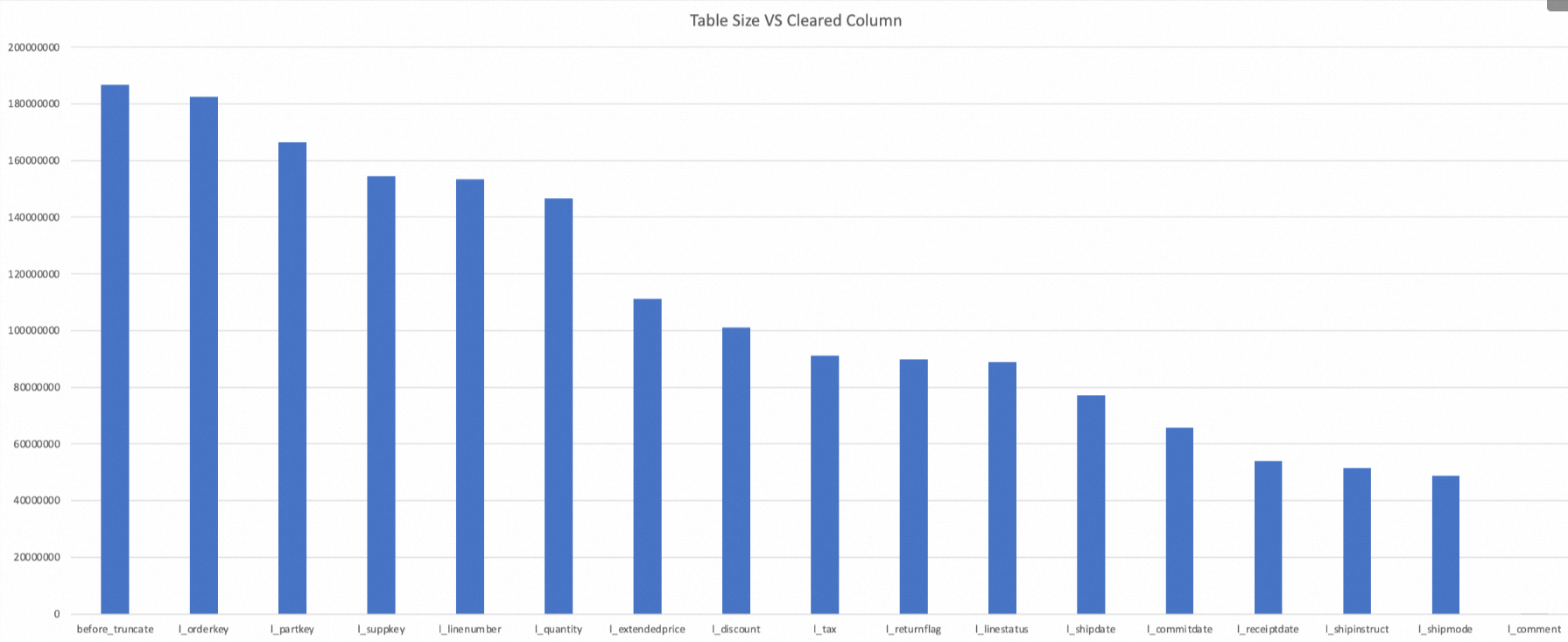
可以看出隨著表的16個列陸續被Clear Column命令置為Null,存儲空間總共下降了99.97%(由最初的186783526byte下降到了236715byte)。
說明列的數據類型和實際存儲的值和Clear Column操作節省的空間有關,比如在這個例子中,對Decimal類型的
l_extendedprice列,Clear Column操作節省了24.2%的空間(146538799 byte -> 111138117 byte)明顯好于平均水平。當所有列被置Null后表的大小是236715 byte,而不是0。這是因為表的文件結構還存在,Null字段會占用少量的存儲空間,系統也需要保留文件Footer信息。
更新數據(UPDATE)
update操作用于將Transactional表或Delta Table表中行對應的單列或多列數據更新為新值。
命令格式
--方式1 update <table_name> set <col1_name> = <value1> [, <col2_name> = <value2> ...] [WHERE <where_condition>]; --方式2 update <table_name> set (<col1_name> [, <col2_name> ...]) = (<value1> [, <value2> ...])[WHERE <where_condition>]; --方式3 UPDATE <table_name> SET <col1_name> = <value1> [ , <col2_name> = <value2> , ... ] [ FROM <additional_tables> ] [ WHERE <where_condition> ]參數說明
table_name:必填。待執行
update操作的Transactional表名稱。col1_name、col2_name:至少更新一個。待修改行對應的列名稱。
value1、value2:至少更新一個列值。修改后的新值。
where_condition:可選。WHERE子句,用于篩選滿足條件的數據。更多WHERE子句信息,請參見WHERE子句(where_condition)。如果不帶WHERE子句,會更新表中的所有數據。
additional_tables:可選,from子句。
update支持from子句,使用from子句時,update的使用會更加方便,不使用from子句與使用from子句的對比示例如下。場景
示例代碼
不使用from子句
update target set v = (select min(v) from src group by k where target.k = src.key) where target.k in (select k from src);使用from子句
update target set v = b.v from (select k, min(v) v from src group by k) b where target.k = b.k;從上述示例代碼可見:
當用源表的多行數據更新目標表的一行數據的時,由于不知道使用哪條源表的數據進行更新,所以遇到這種情況需要用戶寫聚合操作來保證數據源的unique性,可以看出不使用from子句時,代碼不夠簡潔,用from子句的寫比較簡潔易懂。
關聯更新的時候,如果只更新交集數據,不使用from子句時需要寫額外的where條件,相對于from語法而言也不太簡潔。
使用示例
示例1:創建非分區表acid_update,并導入數據,執行
update操作更新滿足指定條件的行對應的列數據。命令示例如下:--創建Transactional表acid_update。 create table if not exists acid_update(id bigint) tblproperties ("transactional"="true"); --插入數據。 insert overwrite table acid_update values(1),(2),(3),(2); --查看插入結果。 select * from acid_update; --返回結果 +------------+ | id | +------------+ | 1 | | 2 | | 3 | | 2 | +------------+ --將所有id為2的行,id值更新為4。 update acid_update set id = 4 where id = 2; --查看更新結果,2被更新為4。 select * from acid_update; --返回結果 +------------+ | id | +------------+ | 1 | | 3 | | 4 | | 4 | +------------+示例2:創建分區表acid_update,并導入數據,執行
update操作更新滿足指定條件的行對應的列數據。命令示例如下:--創建Transactional表acid_update_pt。 create table if not exists acid_update_pt(id bigint) partitioned by(ds string) tblproperties ("transactional"="true"); --添加分區。 alter table acid_update_pt add if not exists partition (ds= '2019'); --插入數據。 insert overwrite table acid_update_pt partition (ds='2019') values(1),(2),(3); --查看插入結果 select * from acid_update_pt where ds = '2019'; --返回結果 +------------+------------+ | id | ds | +------------+------------+ | 1 | 2019 | | 2 | 2019 | | 3 | 2019 | +------------+------------+ --更新指定行的一列數據,將分區為2019的所有id=2的行,id值更新為4。 update acid_update_pt set id = 4 where ds = '2019' and id = 2; --查看更新結果,2被更新為4。 select * from acid_update_pt where ds = '2019'; --返回結果 +------------+------------+ | id | ds | +------------+------------+ | 4 | 2019 | | 1 | 2019 | | 3 | 2019 | +------------+------------+示例3:創建目標表acid_update_t和關聯表acid_update_s,實現同時更新多列值。命令示例如下:
--創建待更新目標Transactional表acid_update_t和關聯表acid_update_s。 create table if not exists acid_update_t(id int,value1 int,value2 int) tblproperties ("transactional"="true"); create table if not exists acid_update_s(id int,value1 int,value2 int); --插入數據。 insert overwrite table acid_update_t values(2,20,21),(3,30,31),(4,40,41); insert overwrite table acid_update_s values(1,100,101),(2,200,201),(3,300,301); --方式一:用常量更新。 update acid_update_t set (value1, value2) = (60,61); --查詢方式一目標表結果數據。 select * from acid_update_t; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 60 | 61 | | 3 | 60 | 61 | | 4 | 60 | 61 | +------------+------------+------------+ --方式二:關聯更新,規則為acid_update_t表左關聯acid_update_s表。 update acid_update_t set (value1, value2) = (select value1, value2 from acid_update_s where acid_update_t.id = acid_update_s.id); --查詢方式二目標表結果數據。 select * from acid_update_t; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 200 | 201 | | 3 | 300 | 301 | | 4 | NULL | NULL | +------------+------------+------------+ --方式三:關聯更新,規則為增加過濾條件,只更新交集。 update acid_update_t set (value1, value2) = (select value1, value2 from acid_update_s where acid_update_t.id = acid_update_s.id) where acid_update_t.id in (select id from acid_update_s); --查詢方式三目標表結果數據。 select * from acid_update_t; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 200 | 201 | | 3 | 300 | 301 | | 4 | NULL | NULL | +------------+------------+------------+ --方式四:用匯總結果關聯更新。 update acid_update_t set (id, value1, value2) = (select id, max(value1),max(value2) from acid_update_s where acid_update_t.id = acid_update_s.id group by acid_update_s.id) where acid_update_t.id in (select id from acid_update_s); --查詢方式四目標表結果數據。 select * from acid_update_t; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 200 | 201 | | 3 | 300 | 301 | | 4 | NULL | NULL | +------------+------------+------------+示例4:涉及兩個表的簡單關聯查詢,示例命令如下:
--創建更新目標表acid_update_t和關聯表acid_update_s create table if not exists acid_update_t(id bigint,value1 bigint,value2 bigint) tblproperties ("transactional"="true"); create table if not exists acid_update_s(id bigint,value1 bigint,value2 bigint); --插入數據 insert overwrite table acid_update_t values(2,20,21),(3,30,31),(4,40,41); insert overwrite table acid_update_s values(1,100,101),(2,200,201),(3,300,301); --查詢acid_update_t表數據 select * from acid_update_t; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 20 | 21 | | 3 | 30 | 31 | | 4 | 40 | 41 | +------------+------------+------------+ --查詢acid_update_s表數據 select * from acid_update_s; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 1 | 100 | 101 | | 2 | 200 | 201 | | 3 | 300 | 301 | +------------+------------+------------+ --關聯更新,目標表增加過濾條件,只取交集 update acid_update_t set value1 = b.value1, value2 = b.value2 from acid_update_s b where acid_update_t.id = b.id; --查看更新結果,20被更新為200,21被更新為201,30被更新為300,31被更新為301 select * from acid_update_t; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 4 | 40 | 41 | | 2 | 200 | 201 | | 3 | 300 | 301 | +------------+------------+------------+示例5:涉及多個表的復雜關聯查詢,示例命令如下:
--創建更新目標表acid_update_t和關聯表acid_update_s create table if not exists acid_update_t(id bigint,value1 bigint,value2 bigint) tblproperties ("transactional"="true"); create table if not exists acid_update_s(id bigint,value1 bigint,value2 bigint); create table if not exists acid_update_m(id bigint,value1 bigint,value2 bigint); --插入數據 insert overwrite table acid_update_t values(2,20,21),(3,30,31),(4,40,41),(5,50,51); insert overwrite table acid_update_s values (1,100,101),(2,200,201),(3,300,301),(4,400,401),(5,500,501); insert overwrite table acid_update_m values(3,30,101),(4,400,201),(5,300,301); --查詢acid_update_t表數據 select * from acid_update_t; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 20 | 21 | | 3 | 30 | 31 | | 4 | 40 | 41 | | 5 | 50 | 51 | +------------+------------+------------+ --查詢acid_update_s表數據 select * from acid_update_s; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 1 | 100 | 101 | | 2 | 200 | 201 | | 3 | 300 | 301 | | 4 | 400 | 401 | | 5 | 500 | 501 | +------------+------------+------------+ --查詢acid_update_m表數據 select * from acid_update_m; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 3 | 30 | 101 | | 4 | 400 | 201 | | 5 | 300 | 301 | +------------+------------+------------+ --關聯更新,并且在where中同時對原表和目標表進行過濾 update acid_update_t set value1 = acid_update_s.value1, value2 = acid_update_s.value2 from acid_update_s where acid_update_t.id = acid_update_s.id and acid_update_s.id > 2 and acid_update_t.value1 not in (select value1 from acid_update_m where id = acid_update_t.id) and acid_update_s.value1 not in (select value1 from acid_update_m where id = acid_update_s.id); --查看更新結果,acid_update_t表只有id為5的數據符合條件,對應value1被更新尾500,valu2被更新尾501 select * from acid_update_t; --返回結果 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 5 | 500 | 501 | | 2 | 20 | 21 | | 3 | 30 | 31 | | 4 | 40 | 41 | +------------+------------+------------+示例6:創建Delta Table表mf_dt,并導入數據,執行
update操作刪除滿足指定條件的行。命令示例如下:--創建目標Delta Table表mf_dt。 create table if not exists mf_dt (pk bigint not null primary key, val bigint not null) partitioned by (dd string, hh string) tblproperties ("transactional"="true"); --插入數據 insert overwrite table mf_dt partition (dd='01', hh='02') values (1, 1), (2, 2), (3, 3); --查看插入結果 select * from mf_dt where dd='01' and hh='02'; --返回結果 +------------+------------+----+----+ | pk | val | dd | hh | +------------+------------+----+----+ | 1 | 1 | 01 | 02 | | 3 | 3 | 01 | 02 | | 2 | 2 | 01 | 02 | +------------+------------+----+----+ --更新指定行的一列數據,將分區為01和02的所有pk=3的行,val值更新為30。 --方法一 update mf_dt set val = 30 where pk = 3 and dd='01' and hh='02'; --方法二 update mf_dt set val = delta.val from (select pk, val from values (3, 30) t (pk, val)) delta where delta.pk = mf_dt.pk and mf_dt.dd='01' and mf_dt.hh='02'; --查看更新結果。 select * from mf_dt where dd='01' and hh='02'; --返回結果,pk=3的行val值被更新為30。 +------------+------------+----+----+ | pk | val | dd | hh | +------------+------------+----+----+ | 1 | 1 | 01 | 02 | | 3 | 30 | 01 | 02 | | 2 | 2 | 01 | 02 | +------------+------------+----+----+
合并Transactional表文件
Transactional表底層物理存儲為不支持直接讀取的Base文件和Delta文件。對Transactional表執行update或delete操作,不會修改Base文件,只會追加Delta文件,所以會出現更新或刪除次數越多,表實際占用存儲越大的情況,多次累積的Delta文件會產生較高的存儲和后續查詢費用。
對同一表或分區,執行多次update或delete操作,會生成較多Delta文件。系統讀數據時,需要加載這些Delta文件來確定哪些行被更新或刪除,較多的Delta文件會影響數據讀取效率。此時您可以將Base文件和Delta合并,減少存儲以便提升數據讀取效率。
命令格式
alter table <table_name> [partition (<partition_key> = '<partition_value>' [, ...])] compact {minor|major};參數說明
table_name:必填。待合并文件的Transactional表名稱。
partition_key:可選。當Transactional表為分區表時,指定分區列名。
partition_value:可選。當Transactional表為分區表時,指定分區列名對應的列值。
major|minor:至少選擇其中一個。二者的區別是:
minor:只將Base文件及其下所有的Delta文件合并,消除Delta文件。major:不僅將Base文件及其下所有的Delta文件合并,消除Delta文件,還會把表對應的Base文件中的小文件進行合并。當Base文件較小(小于32 MB)或有Delta文件的情況下,等價于重新對表執行insert overwrite操作,但當Base文件足夠大(大于等于32 MB ),且不存在Delta文件的情況下,不會重寫。
注意事項
通過Compact操作合并的小文件將在1天后被刪除。如果使用備份與恢復功能恢復歷史記錄,并且該歷史記錄依賴于這些小文件,將會因為小文件的缺失,導致恢復失敗。
使用示例
示例1:基于Transactional表acid_delete,合并表文件。命令示例如下:
alter table acid_delete compact minor;返回結果如下:
Summary: Nothing found to merge, set odps.merge.cross.paths=true if cross path merge is permitted. OK示例2:基于Transactional表acid_update_pt,合并表文件。命令示例如下:
alter table acid_update_pt partition (ds = '2019') compact major;返回結果如下:
Summary: table name: acid_update_pt /ds=2019 instance count: 2 run time: 6 before merge, file count: 8 file size: 2613 file physical size: 7839 after merge, file count: 2 file size: 679 file physical size: 2037 OK
常見問題
問題一:
問題現象:執行
update操作時,報錯ODPS-0010000:System internal error - fuxi job failed, caused by: Data Set should contain exactly one row。問題原因:待更新的行數據與子查詢結果中的數據無法一一對應,系統無法判斷對哪一行數據進行更新。命令示例如下:
update store set (s_county, s_manager) = (select d_country, d_manager from store_delta sd where sd.s_store_sk = store.s_store_sk) where s_store_sk in (select s_store_sk from store_delta);通過子查詢
select d_country, d_manager from store_delta sd where sd.s_store_sk = store.s_store_sk與store_delta關聯,并用store_delta的數據更新store。假設store的s_store_sk中有[1, 2, 3]三行數據,如果store_delta的s_store_sk有[1, 1]兩行數據,數據無法一一對應,執行報錯。解決措施:確保待更新的行數據與子查詢結果中的數據一一對應。
問題二:
問題現象:在DataWorks DataStudio中使用
compact命令時,報錯ODPS-0130161:[1,39] Parse exception - invalid token 'minor', expect one of 'StringLiteral','DoubleQuoteStringLiteral'。問題原因:DataWorks獨享資源組中的MaxCompute客戶端版本不支持
compact命令。解決措施:請通過DataWorks交流群聯系技術支持團隊升級獨享資源組中的MaxCompute客戶端版本。