Logview診斷實(shí)踐
在實(shí)際業(yè)務(wù)開發(fā)過程中,企業(yè)通常要求作業(yè)能在期望的時(shí)間節(jié)點(diǎn)前產(chǎn)出結(jié)果,并根據(jù)結(jié)果做進(jìn)一步?jīng)Q策,這就需要作業(yè)開發(fā)人員及時(shí)關(guān)注作業(yè)運(yùn)行狀態(tài),識(shí)別并優(yōu)化慢作業(yè)。您可以通過MaxCompute的Logview功能診斷慢作業(yè)。本文為您介紹導(dǎo)致出現(xiàn)慢作業(yè)的原因及如何查看慢作業(yè)并提供對(duì)應(yīng)的解決措施。
分析運(yùn)行出錯(cuò)作業(yè)
作業(yè)運(yùn)行失敗時(shí),通過Logview中的Result頁(yè)簽可以查看出錯(cuò)信息,對(duì)于失敗的作業(yè),打開Logview默認(rèn)會(huì)跳轉(zhuǎn)到Result頁(yè)簽。
常見失敗原因包括:
SQL語(yǔ)法錯(cuò)誤,此時(shí)不會(huì)有DAG和Fuxi jobs,因?yàn)檫€未提交到計(jì)算集群執(zhí)行。
用戶UDF出錯(cuò),在Job Details頁(yè)簽中查看DAG圖,確定出問題的UDF,并查看StdOut或StdErr等報(bào)錯(cuò)信息。
其他報(bào)錯(cuò),可以參見文檔錯(cuò)誤碼以及解決方案。
分析運(yùn)行慢作業(yè)
編譯階段
作業(yè)處于編譯階段的特征是有Logview,但還未執(zhí)行計(jì)劃。根據(jù)Logview的子狀態(tài)(SubStatusHistory)可以進(jìn)一步細(xì)分為調(diào)度、優(yōu)化、生成物理執(zhí)行計(jì)劃、數(shù)據(jù)跨集群復(fù)制等子階段。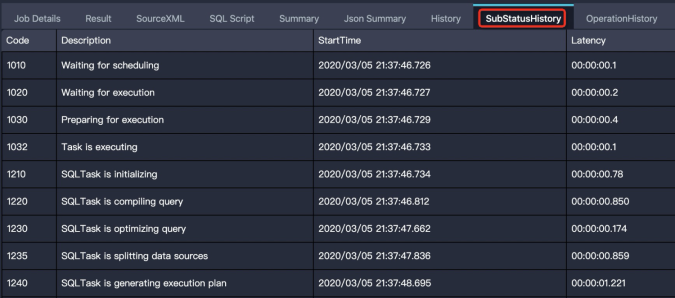 編譯階段的問題主要表現(xiàn)為在某個(gè)子階段卡住,即作業(yè)長(zhǎng)時(shí)間停留在某一個(gè)子階段。下面將介紹作業(yè)停留在每個(gè)子階段的可能原因和解決措施。
編譯階段的問題主要表現(xiàn)為在某個(gè)子階段卡住,即作業(yè)長(zhǎng)時(shí)間停留在某一個(gè)子階段。下面將介紹作業(yè)停留在每個(gè)子階段的可能原因和解決措施。
調(diào)度階段
問題現(xiàn)象:子狀態(tài)為
Waiting for cluster resource,作業(yè)排隊(duì)等待被編譯。產(chǎn)生原因:計(jì)算集群資源緊缺。
解決措施:查看計(jì)算集群的狀態(tài),需要等待計(jì)算集群的資源,如果是預(yù)付費(fèi)客戶可以綜合考慮,對(duì)資源進(jìn)行擴(kuò)容。
優(yōu)化階段
問題現(xiàn)象:子狀態(tài)為
SQLTask is optimizing query,優(yōu)化器正在優(yōu)化執(zhí)行計(jì)劃。產(chǎn)生原因:執(zhí)行計(jì)劃復(fù)雜,需要較長(zhǎng)時(shí)間做優(yōu)化。
解決措施:請(qǐng)耐心等待,正常不會(huì)超過10分鐘。
生成物理執(zhí)行計(jì)劃階段
問題現(xiàn)象:子狀態(tài)為
SQLTask is generating execution plan。產(chǎn)生原因一:讀取的分區(qū)過多。
解決措施:需要優(yōu)化設(shè)計(jì)SQL,減少分區(qū)的數(shù)量,包括:分區(qū)裁剪、過濾掉不需要讀的分區(qū)、把大作業(yè)拆成小作業(yè)。如何判斷SQL中分區(qū)剪裁是否生效,以及分區(qū)裁剪失效的常見場(chǎng)景請(qǐng)參考文章:分區(qū)剪裁合理性評(píng)估。
產(chǎn)生原因二:小文件過多。 產(chǎn)生小文件的原因主要有兩個(gè):
使用Tunnel上傳數(shù)據(jù)時(shí)操作不正確(例如每上傳一條數(shù)據(jù)就重新建一個(gè)
upload session),具體可以參考文檔:Tunnel命令常見問題。對(duì)分區(qū)表進(jìn)行
insert into操作時(shí),會(huì)在partition目錄下面生成一個(gè)新文件。
解決措施:
使用TunnelBufferedWriter接口,可以更簡(jiǎn)單地進(jìn)行上傳功能,同時(shí)避免存在過多小文件。
手工執(zhí)行一次小文件合并,把小文件Merge起來(lái),更多內(nèi)容請(qǐng)參考官方文檔:合并小文件。
說(shuō)明小文件個(gè)數(shù)在萬(wàn)以上可以執(zhí)行小文件合并動(dòng)作,系統(tǒng)每天會(huì)自動(dòng)進(jìn)行小文件合并,但是在一些特殊場(chǎng)景小文件合并失敗后,需要手工執(zhí)行合并。
數(shù)據(jù)跨集群復(fù)制階段
問題現(xiàn)象:子狀態(tài)列表里面出現(xiàn)多次
Task rerun,Result里有錯(cuò)誤信息FAILED: ODPS-0110141:Data version exception。作業(yè)看似失敗了,實(shí)際還在執(zhí)行,說(shuō)明作業(yè)正在做數(shù)據(jù)的跨集群復(fù)制。產(chǎn)生原因一:Project剛做集群遷移,往往前一兩天有大量需要跨集群復(fù)制的作業(yè)。
解決措施:這種情況是預(yù)期中的跨集群復(fù)制,需要用戶等待。
產(chǎn)生原因二:Project做過遷移,分區(qū)過濾未能處理好,導(dǎo)致讀取了比較老的分區(qū)。
解決措施:過濾掉不必要讀取的老分區(qū)。
執(zhí)行階段
Logview的Job Details界面有執(zhí)行計(jì)劃(執(zhí)行計(jì)劃沒有全部完畢),且作業(yè)狀態(tài)還是Running。執(zhí)行階段卡住或執(zhí)行時(shí)間比預(yù)期長(zhǎng)的主要原因有等待資源、數(shù)據(jù)傾斜、UDF執(zhí)行低效、數(shù)據(jù)膨脹等,下面將具體介紹每種情況的特征和解決思路。
等待資源
特征:Instance處于Ready狀態(tài),或部分Instance是Running狀態(tài),部分是Ready狀態(tài)。需要注意的是,如果Instance狀態(tài)是Ready,但有Debug歷史信息,那么可能是Instance Fail觸發(fā)重試,而不是在等待資源。
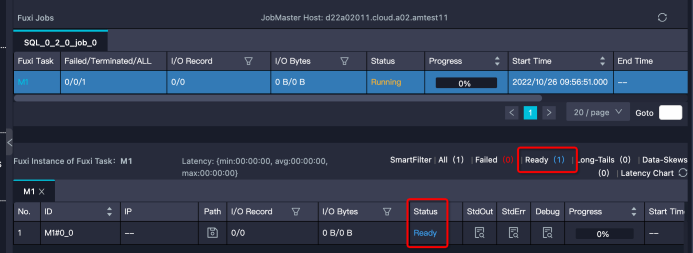
解決思路:。
確定排隊(duì)狀態(tài)是否正常。可以通過Logview的排隊(duì)信息
Queue Length查看作業(yè)在隊(duì)列的位置:如下圖所示。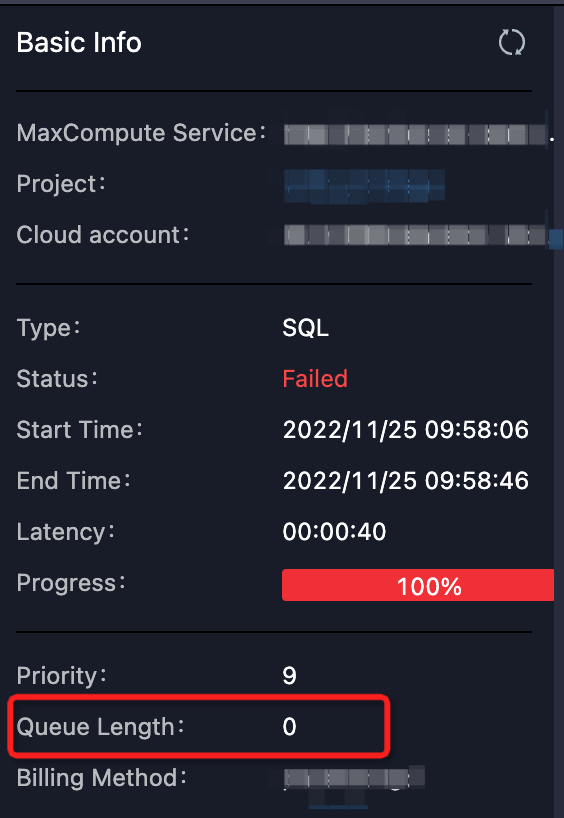 或者通過MaxCompute控制臺(tái)查看對(duì)應(yīng)Quota組的資源使用情況。
或者通過MaxCompute控制臺(tái)查看對(duì)應(yīng)Quota組的資源使用情況。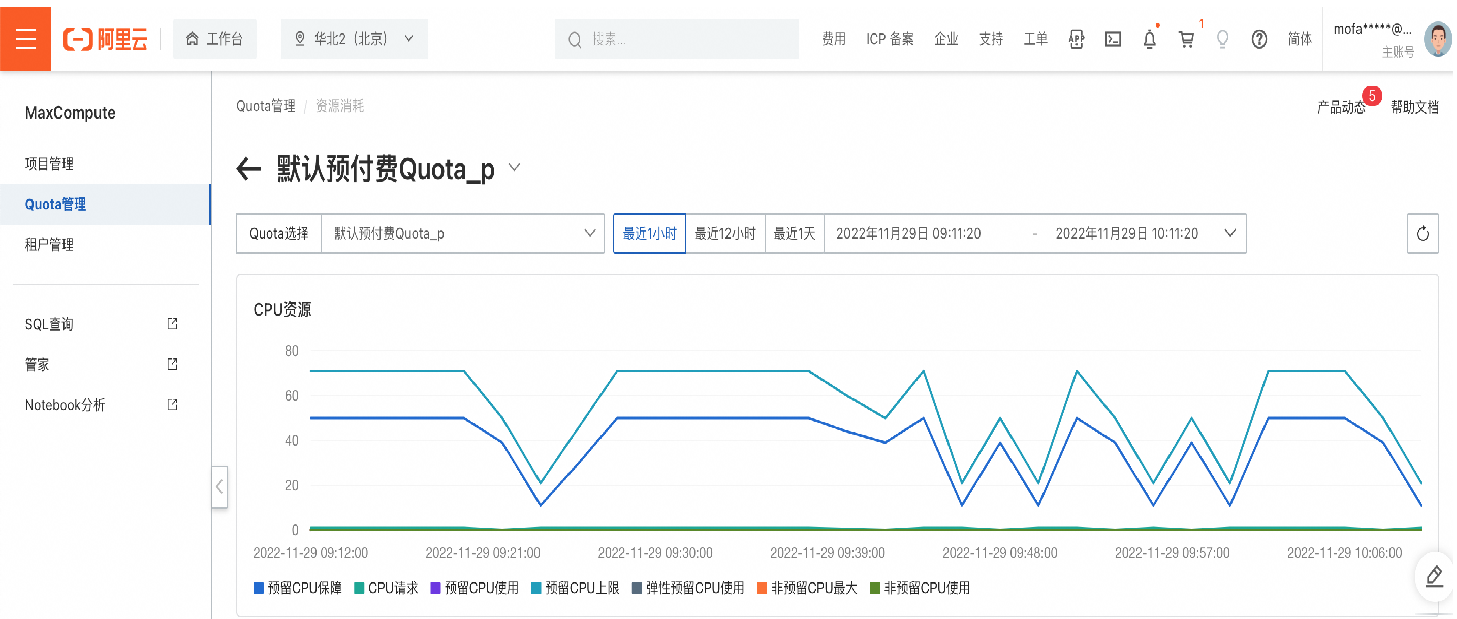 如果某項(xiàng)資源的使用率已經(jīng)接近甚至超過配額了,那么證明Quota組資源緊張,作業(yè)有排隊(duì)是正常的。作業(yè)的調(diào)度順序不僅與作業(yè)提交時(shí)間、優(yōu)先級(jí)有關(guān),還和作業(yè)所需內(nèi)存或CPU資源大小能否被滿足有關(guān)。
如果某項(xiàng)資源的使用率已經(jīng)接近甚至超過配額了,那么證明Quota組資源緊張,作業(yè)有排隊(duì)是正常的。作業(yè)的調(diào)度順序不僅與作業(yè)提交時(shí)間、優(yōu)先級(jí)有關(guān),還和作業(yè)所需內(nèi)存或CPU資源大小能否被滿足有關(guān)。查看Quota組中運(yùn)行的作業(yè)。
可能存在誤交了低優(yōu)先級(jí)的大作業(yè)(或批量提交了很多小作業(yè)),占用了大量的資源,可以和作業(yè)的負(fù)責(zé)人協(xié)商,先把作業(yè)終止掉,讓出資源。
考慮走其他Quota組的項(xiàng)目。
對(duì)資源進(jìn)行擴(kuò)容(包年包月客戶)。
數(shù)據(jù)傾斜
特征:Task中大多數(shù)Instance都已經(jīng)結(jié)束了,但仍有幾個(gè)Instance卻遲遲不結(jié)束(長(zhǎng)尾)。如下圖中大多數(shù)Instance都結(jié)束了,但是還有21個(gè)的狀態(tài)是Running,這些Instance運(yùn)行慢,可能是因?yàn)樘幚淼臄?shù)據(jù)較多。
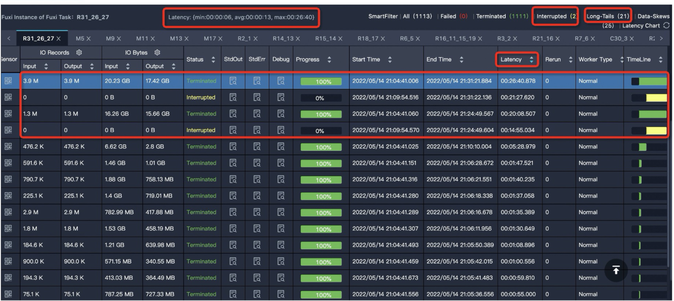
解決思路:您可參考數(shù)據(jù)傾斜調(diào)優(yōu),其中介紹了一些導(dǎo)致數(shù)據(jù)傾斜的常見原因及對(duì)應(yīng)的優(yōu)化思路。
UDF執(zhí)行低效
這里的UDF泛指各種用戶自定義的擴(kuò)展,包括UDF、UDAF、UDTF、UDJ和UDT等。
特征:某個(gè)Task執(zhí)行效率低,且該Task中有用戶自定義的擴(kuò)展。甚至是UDF的執(zhí)行超時(shí)報(bào)錯(cuò):
Fuxi job failed - WorkerRestart errCode:252,errMsg:kInstanceMonitorTimeout, usually caused by bad udf performance。排查方法:任務(wù)報(bào)錯(cuò)時(shí),可以在Logview的Job Details頁(yè)簽中,快速通過DAG圖判斷報(bào)錯(cuò)的Task中是否包含UDF。可以看到報(bào)錯(cuò)的Task R4_3包含用戶使用Java語(yǔ)言編寫的UDF,如下圖所示。
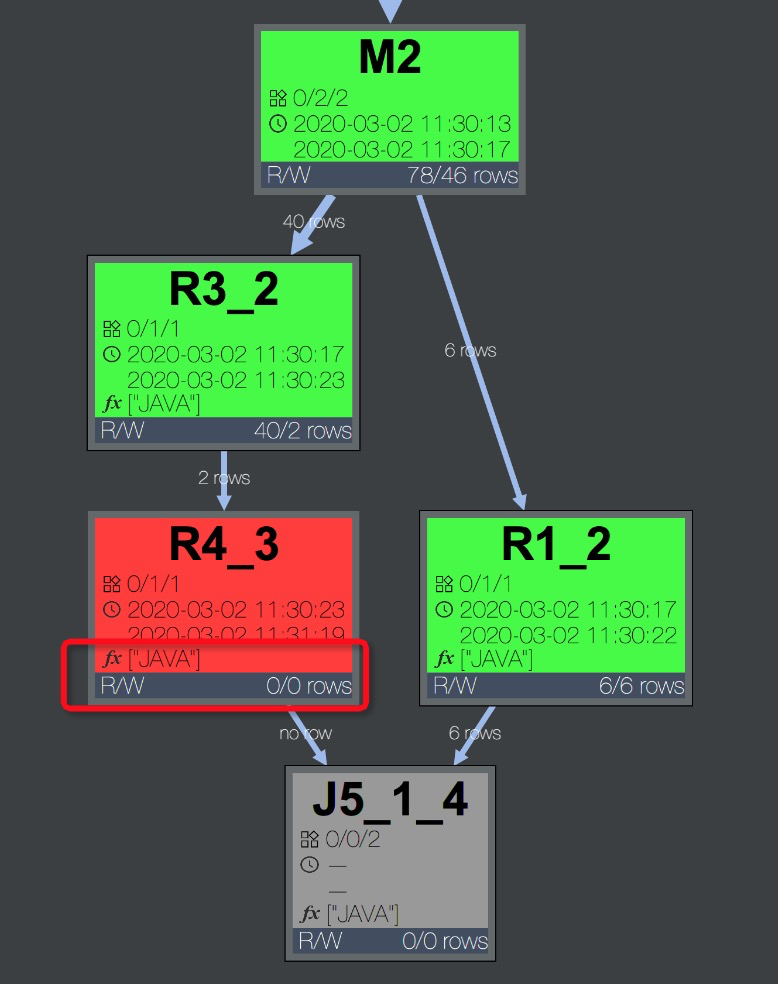 雙擊R4_3展開Operator視圖,可以看到該Task包含的所有UDF名稱,如下圖所示。
雙擊R4_3展開Operator視圖,可以看到該Task包含的所有UDF名稱,如下圖所示。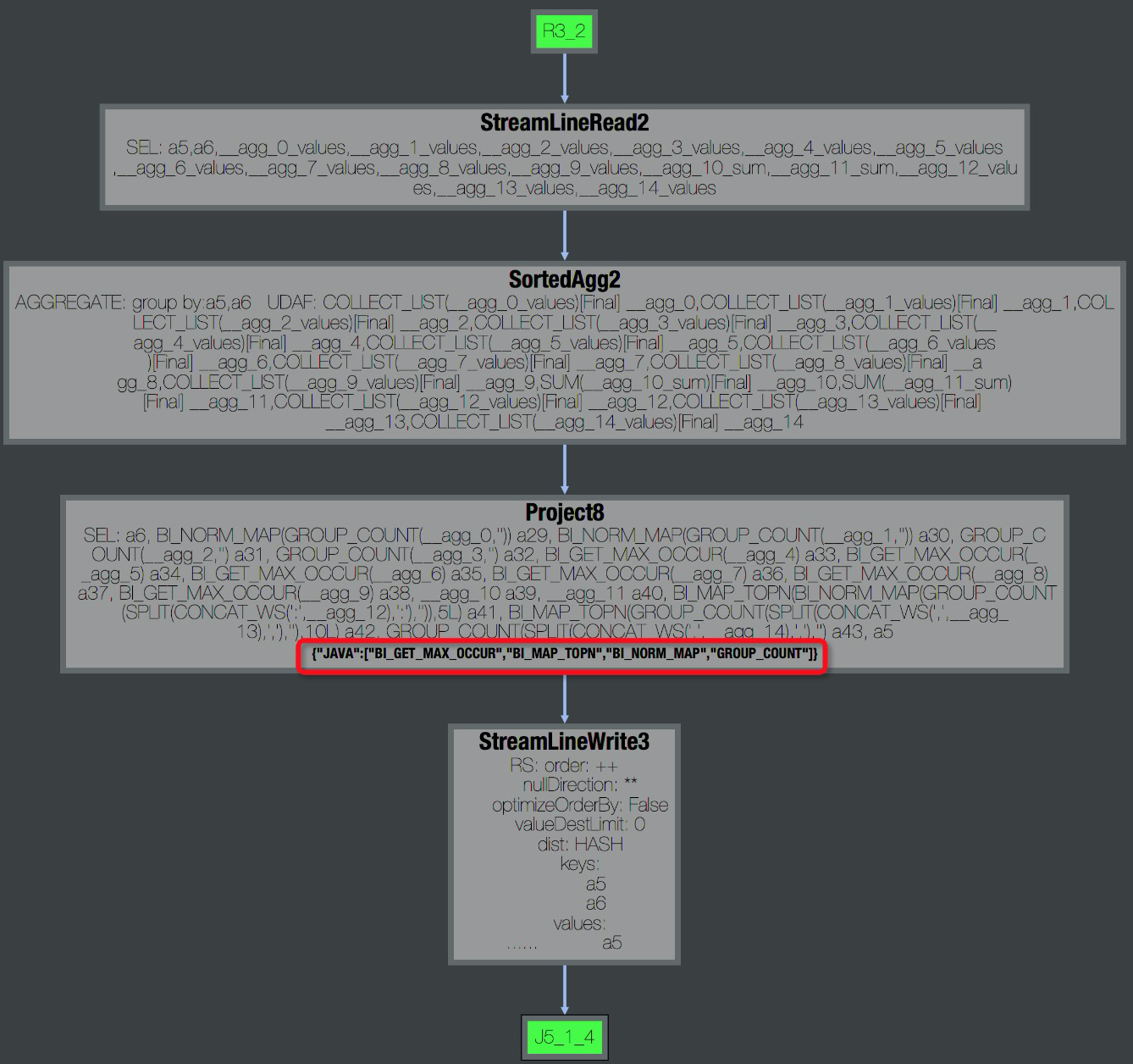 此外,在Task的StdOut日志里,UDF框架會(huì)打印UDF輸入的記錄數(shù)、輸出記錄數(shù)、以及處理時(shí)間,如下圖所示,通過這些數(shù)據(jù)可以看出UDF是否有性能問題。一般正常情況
此外,在Task的StdOut日志里,UDF框架會(huì)打印UDF輸入的記錄數(shù)、輸出記錄數(shù)、以及處理時(shí)間,如下圖所示,通過這些數(shù)據(jù)可以看出UDF是否有性能問題。一般正常情況Speed(records/s)在百萬(wàn)或者十萬(wàn)級(jí)別,如果降到萬(wàn)級(jí)別,那么基本上就存在性能問題了。
解決思路:當(dāng)出現(xiàn)性能問題時(shí),可以按照下述方法進(jìn)行排查和優(yōu)化:
檢查UDF是否出錯(cuò)。
有時(shí)候是由于某些特定的數(shù)據(jù)值引起的,比如出現(xiàn)某個(gè)值的時(shí)候會(huì)引起死循環(huán)。 MaxCompute Studio支持下載表的部分Sample數(shù)據(jù)到本地運(yùn)行,進(jìn)行排查,詳情請(qǐng)參考MaxCompute Studio開發(fā)手冊(cè):Java UDF、Python UDF 。
檢查UDF函數(shù)是否與內(nèi)置函數(shù)同名。
內(nèi)置函數(shù)是有可能被同名UDF覆蓋的,當(dāng)看到一個(gè)函數(shù)像是內(nèi)置函數(shù)時(shí),需要確定是否有同名UDF覆蓋了內(nèi)置函數(shù)。
使用內(nèi)置函數(shù)代替UDF。
有相似功能的內(nèi)置函數(shù)的情況下,盡可能不要使用UDF。內(nèi)置函數(shù)一般經(jīng)過驗(yàn)證,實(shí)現(xiàn)比較高效,并且內(nèi)置函數(shù)對(duì)優(yōu)化器而言是白盒,能夠做更多的優(yōu)化。更多內(nèi)置函數(shù)的用法請(qǐng)參考官方文檔:內(nèi)建函數(shù)。
將UDF函數(shù)進(jìn)行功能拆分,部分使用內(nèi)置函數(shù)替換,內(nèi)置函數(shù)無(wú)法實(shí)現(xiàn)的再使用UDF。
優(yōu)化UDF的evaluate方法。
evaluate中只做與參數(shù)相關(guān)的必要操作。因?yàn)閑valuate方法會(huì)被反復(fù)執(zhí)行,所以盡可能將一些初始化的操作,或者一些重復(fù)計(jì)算事先計(jì)算好。
預(yù)估UDF的執(zhí)行時(shí)間。
先在本地模擬1個(gè)Instance處理的數(shù)據(jù)量測(cè)試UDF的運(yùn)行時(shí)間,優(yōu)化UDF的實(shí)現(xiàn)。默認(rèn)UDF運(yùn)行時(shí)限是30分鐘,也就是30分鐘內(nèi)UDF必須要返回?cái)?shù)據(jù),或者用
context.progress()來(lái)報(bào)告心跳。如果UDF預(yù)計(jì)運(yùn)行時(shí)間本身就大于30分鐘,可以通過參數(shù)設(shè)置UDF超時(shí)時(shí)間:默認(rèn)為1800秒。取值范圍為1s~3600s --設(shè)置UDF超時(shí)時(shí)間,單位秒,默認(rèn)為600秒 --可手動(dòng)調(diào)整區(qū)間[0,3600]調(diào)整內(nèi)存參數(shù)。
UDF效率低的原因并不一定是計(jì)算復(fù)雜度,有可能是受存儲(chǔ)復(fù)雜度影響。比如:
某些UDF在內(nèi)存計(jì)算、排序的數(shù)據(jù)量比較大時(shí),會(huì)報(bào)內(nèi)存溢出錯(cuò)誤。
內(nèi)存不足引起GC頻率過高。
這時(shí)可以嘗試調(diào)整內(nèi)存參數(shù),不過此方法只能暫時(shí)緩解,具體的優(yōu)化還是需要從業(yè)務(wù)上去處理。示例如下:
set odps.sql.udf.jvm.memory= --設(shè)定UDF JVM Heap使用的最大內(nèi)存,單位M,默認(rèn)1024M --可手動(dòng)調(diào)整區(qū)間[256,12288]說(shuō)明目前如果使用了UDF可能會(huì)導(dǎo)致分區(qū)剪裁失效。從新版本開始,MaxCompute支持了
UdfProperty注解。UDF的作者在定義UDF時(shí),可以指定這個(gè)注解,讓編譯器知道這個(gè)函數(shù)是確定性的,如:@com.aliyun.odps.udf.annotation.UdfProperty(isDeterministic = true) public class AnnotatedUdf extends com.aliyun.odps.udf.UDF { public String evaluate(String x) { return x; } }改寫SQL語(yǔ)句為如下所示,就可以在分區(qū)過濾中使用UDF了。
--原來(lái)的寫法 SELECT * FROM t WHERE pt = udf('foo'); --pt 是 t 的一個(gè)分區(qū)列 --改成下面的樣子 SELECT * FROM t WHERE pt = (SELECT udf('foo')); --pt 是 t 的一個(gè)分區(qū)列
數(shù)據(jù)膨脹
特征:Task的輸出數(shù)據(jù)量比輸入數(shù)據(jù)量大很多。比如1 GB的數(shù)據(jù)經(jīng)過處理,變成了1 TB,在一個(gè)Instance下處理1 TB的數(shù)據(jù),運(yùn)行效率肯定會(huì)大大降低。作業(yè)運(yùn)行完成后輸入輸出數(shù)據(jù)量體現(xiàn)在Task的I/O Records中,如果作業(yè)在Join階段長(zhǎng)時(shí)間不結(jié)束,可以選擇幾個(gè)Running狀態(tài)的Fuxi Instance查看StdOut里的日志,如下圖所示:
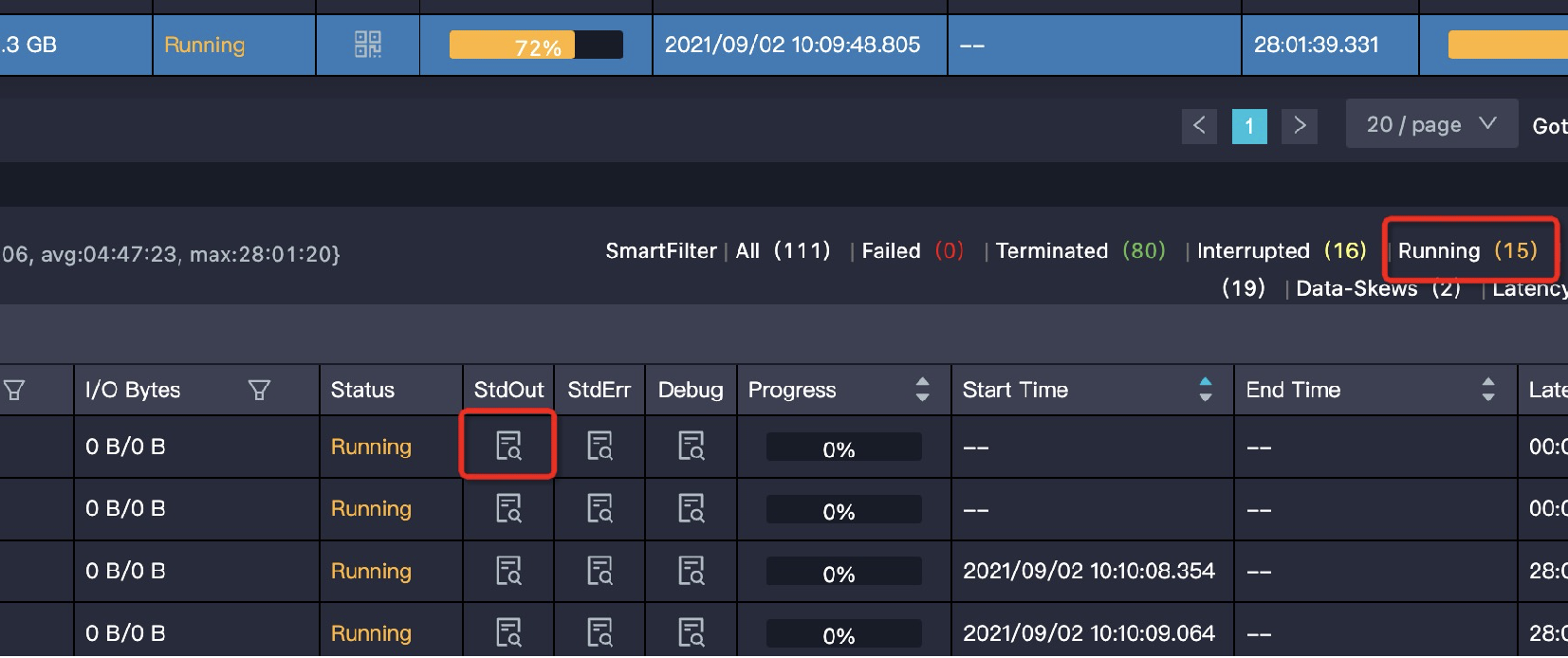 StdOut里一直在打印Merge Join的日志,說(shuō)明對(duì)應(yīng)的單個(gè)Worker一直執(zhí)行Merge Join,紅框中Merge Join輸出的數(shù)據(jù)條數(shù)已經(jīng)超過1433億條,有嚴(yán)重的數(shù)據(jù)膨脹,需要檢查JOIN條件和Join Key是否合理,如下圖所示:
StdOut里一直在打印Merge Join的日志,說(shuō)明對(duì)應(yīng)的單個(gè)Worker一直執(zhí)行Merge Join,紅框中Merge Join輸出的數(shù)據(jù)條數(shù)已經(jīng)超過1433億條,有嚴(yán)重的數(shù)據(jù)膨脹,需要檢查JOIN條件和Join Key是否合理,如下圖所示: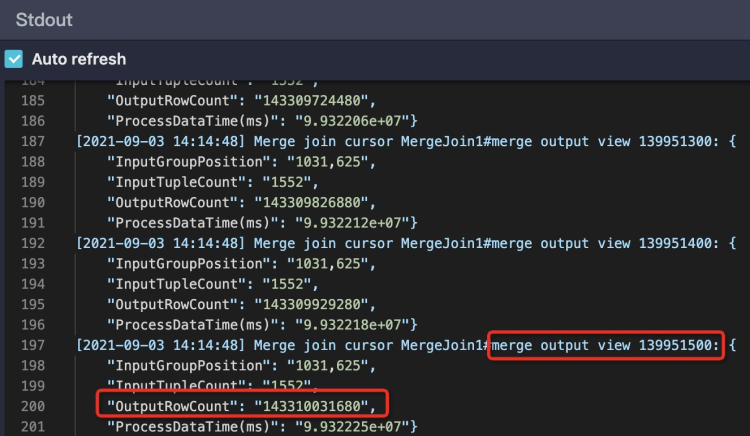
解決思路:
檢查代碼是否有誤:JOIN條件是否寫錯(cuò),是否寫成笛卡爾積了、UDTF是否正常,是否輸出過多數(shù)據(jù)。
檢查Aggregation引起的數(shù)據(jù)膨脹。
因?yàn)榇蠖鄶?shù)Aggregator是recursive的,中間結(jié)果先做了一層Merge,中間結(jié)果不大,而且大多數(shù)Aggregator的計(jì)算復(fù)雜度比較低,即使數(shù)據(jù)量不小,也能較快完成。所以通常情況下這些操作問題不大,如以下兩種情況:
SELECT中使用Aggregation按照不同維度做DISTINCT,每一次DISTINCT都會(huì)使數(shù)據(jù)做一次膨脹。
使用GROUPING SETS 、CUBE | ROLLUP,中間數(shù)據(jù)可能會(huì)擴(kuò)展很多倍。但是,有些操作如COLLECT_LIST、MEDIAN操作需要把全量中間數(shù)據(jù)都保留下來(lái),可能會(huì)產(chǎn)生問題。
避免Join引起的數(shù)據(jù)膨脹。
例如:兩個(gè)表Join,左表是人口數(shù)據(jù),數(shù)據(jù)量很大,但是由于并行度足夠,效率可觀。右表是個(gè)維表,記錄每種性別對(duì)應(yīng)的一些信息(比如每種性別可能的壞毛病),雖然只有兩種性別,但是每種都包含數(shù)百行。那么如果直接按照性別來(lái)Join,可能會(huì)讓左表膨脹數(shù)百倍。要解決這個(gè)問題,可以考慮先將右表的行做聚合,變成兩行數(shù)據(jù),這樣Join的結(jié)果就不會(huì)膨脹了。
由于Grouping Set導(dǎo)致的數(shù)據(jù)膨脹。Grouping Set操作會(huì)有一個(gè)擴(kuò)展過程,輸出數(shù)據(jù)會(huì)按照Group數(shù)倍增。 目前的plan沒有能力適配Grouping Set并做下游Task dop的調(diào)整,用戶可以手動(dòng)設(shè)置下游Task的dop。示例如下:
set odps.stage.reducer.num = xxx; set odps.stage.joiner.num = xxx;
結(jié)束階段
大部分SQL作業(yè)在Fuxi作業(yè)結(jié)束后即停止。但有時(shí)Fuxi作業(yè)結(jié)束時(shí),作業(yè)總體進(jìn)度仍然處于運(yùn)行狀態(tài)。如下圖中的Logview,右側(cè)Job Details頁(yè)面顯示Fuxi作業(yè)所有階段為Terminated,但左側(cè)代表作業(yè)整體進(jìn)度的Status仍然顯示Running: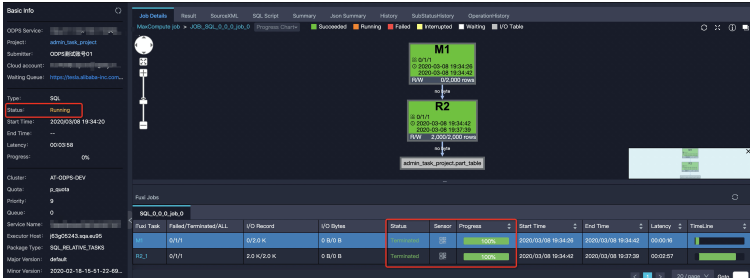 造成這種現(xiàn)象一般分為兩種情況:
造成這種現(xiàn)象一般分為兩種情況:
一個(gè)SQL作業(yè)可能包含多個(gè)Fuxi作業(yè),比如子查詢存在多階段執(zhí)行,作業(yè)輸出小文件過多導(dǎo)致的自動(dòng)合并作業(yè)。
SQL在結(jié)束階段運(yùn)行于控制集群的邏輯占用時(shí)間較長(zhǎng),比如更新動(dòng)態(tài)分區(qū)的元數(shù)據(jù),下面將舉例介紹幾種典型。
子查詢多階段執(zhí)行
大部分情況下,MaxCompute SQL的子查詢會(huì)被編譯進(jìn)同一個(gè)Fuxi DAG,即所有子查詢和主查詢都通過一個(gè)Fuxi作業(yè)完成。但也有一些特殊子查詢需要先將子查詢單獨(dú)執(zhí)行。如下示例:
SELECT product, sum(price) FROM sales WHERE ds in (SELECT DISTINCT ds FROM t_ds_set) GROUP BY product;子查詢
SELECT DISTINCT ds FROM t_ds_set先執(zhí)行,其結(jié)果需要被用來(lái)做分區(qū)裁剪,來(lái)優(yōu)化主查詢需要讀取的分區(qū)數(shù)。這兩次運(yùn)行分別是兩個(gè)Fuxi作業(yè),Logview中體現(xiàn)的是兩個(gè)tab頁(yè)來(lái)顯示:第一個(gè)tab頁(yè)顯示job_0全部成功,實(shí)際上第二個(gè)tab頁(yè)的job_1作業(yè)還正在執(zhí)行。如下圖所示: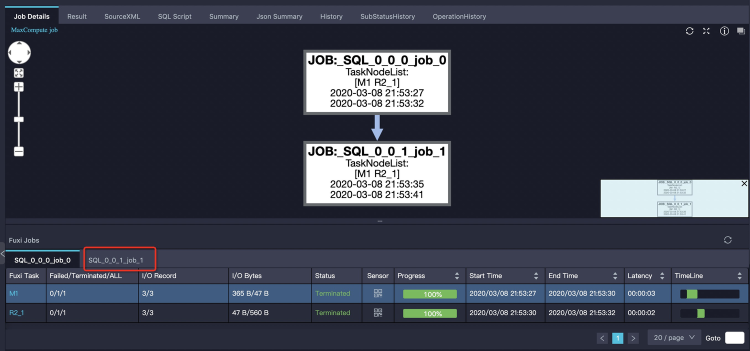 這時(shí)我們只需單擊第二個(gè)tab頁(yè)可以看到job_1的執(zhí)行情況,如下圖所示:
這時(shí)我們只需單擊第二個(gè)tab頁(yè)可以看到job_1的執(zhí)行情況,如下圖所示:
過多小文件
小文件主要帶來(lái)存儲(chǔ)和計(jì)算兩方面問題。
存儲(chǔ)方面:小文件過多會(huì)給Pangu文件系統(tǒng)帶來(lái)一定的壓力,且影響空間的有效利用。
計(jì)算方面:ODPS處理單個(gè)大文件比處理多個(gè)小文件效率高,小文件過多會(huì)影響整體的計(jì)算執(zhí)行性能。因此,為了避免系統(tǒng)產(chǎn)生過多小文件,SQL作業(yè)在結(jié)束時(shí)會(huì)針對(duì)一定條件自動(dòng)觸發(fā)合并小文件的操作。
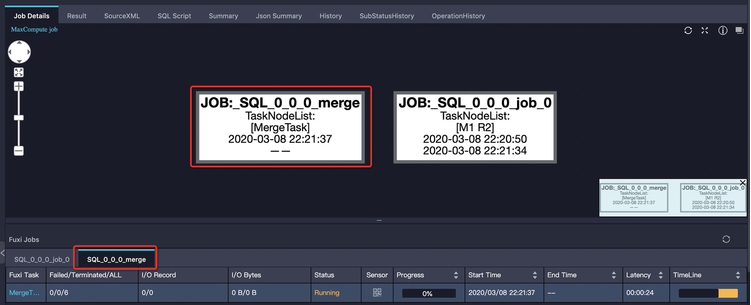
解決措施:通過Logview可以查看作業(yè)是否觸發(fā)了自動(dòng)合并小文件。與前面介紹過的子查詢多階段執(zhí)行類似,Merge作業(yè)也是作為一個(gè)單獨(dú)的tab頁(yè)顯示,自動(dòng)合并小文件多出來(lái)的Merge Task,雖然會(huì)增加當(dāng)前作業(yè)整體執(zhí)行時(shí)間,但是會(huì)讓結(jié)果表在合并后產(chǎn)生的文件數(shù)和文件大小更合理,從而避免對(duì)文件系統(tǒng)產(chǎn)生過大壓力,也使得表被后續(xù)的作業(yè)使用時(shí),擁有更好的讀取性能。如下圖所示:
小文件過多除了造成上文說(shuō)的問題外,還會(huì)導(dǎo)致SELECT屏顯也在作業(yè)結(jié)束階段長(zhǎng)時(shí)間運(yùn)行。因?yàn)樵趨R聚屏顯結(jié)果時(shí),需要打開大量小文件進(jìn)行讀取,耗費(fèi)大量時(shí)間在文件操作上。對(duì)于這種情況,需要盡量避免使用SELECT語(yǔ)句造成屏顯數(shù)量巨大的結(jié)果,如果需要大批量返回結(jié)果應(yīng)該使用Tunnel進(jìn)行下載數(shù)據(jù)。另外如果結(jié)果實(shí)際不大,但是文件數(shù)過多,那么最好是先檢查前文所述的小文件閾值配置是否正確。了解更多關(guān)于合并小文件的知識(shí),請(qǐng)查閱官方文檔:合并小文件。
動(dòng)態(tài)分區(qū)元數(shù)據(jù)更新
問題現(xiàn)象:Fuxi作業(yè)執(zhí)行完后,可能還有一些元數(shù)據(jù)操作。比如要把結(jié)果數(shù)據(jù)挪到特定目錄去,然后更新表的元數(shù)據(jù)。有可能動(dòng)態(tài)分區(qū)輸出了太多分區(qū),也會(huì)消耗一定的時(shí)間。例如,對(duì)分區(qū)表sales使用
insert into ... values命令新增2000個(gè)分區(qū),如下所示:INSERT INTO TABLE sales partition (ds)(ds, product, price) VALUES ('20170101','a',1),('20170102','b',2),('20170103','c',3), ...;Fuxi作業(yè)執(zhí)行結(jié)束后,仍需要一段時(shí)間進(jìn)行表的元數(shù)據(jù)更新。如下圖Logview的子狀態(tài)所示,可以看到作業(yè)卡在
SQLTask is updating meta information。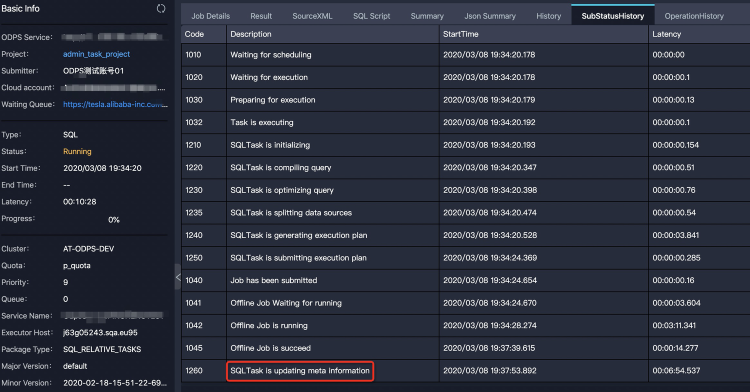
輸出文件size變大
問題現(xiàn)象:在輸入輸出條數(shù)相差不大的情況,可能存在結(jié)果膨脹幾倍。
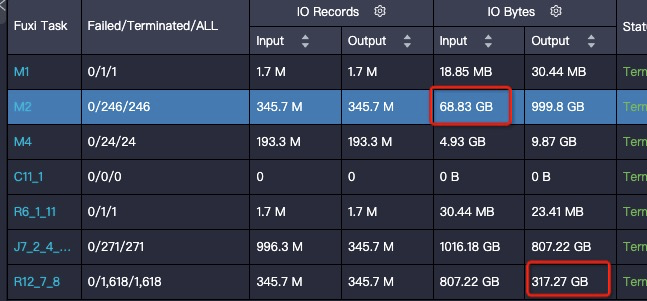
解決思路:一種情況是數(shù)據(jù)分布變化導(dǎo)致的,在向表中寫數(shù)據(jù)的過程中,會(huì)對(duì)數(shù)據(jù)進(jìn)行壓縮,而壓縮算法對(duì)于重復(fù)數(shù)據(jù)的壓縮率是最高的,所以在寫數(shù)據(jù)的過程中,如果相同的數(shù)據(jù)都排布在一起,就可以獲得很高的壓縮率。數(shù)據(jù)分布情況主要取決于數(shù)據(jù)寫入的階段(對(duì)應(yīng)上圖的R12)是如何Shuffle和排序的,上圖給出的SQL最后的操作是JOIN,JOIN Key為如下代碼:
on t1.query = t2.query and t1.item_id=t2.item_id研究一下數(shù)據(jù)的特征,大部分列都是item的屬性,即相同的
item_id其余的列都完全相同,按照Query排序會(huì)把item完全打亂,導(dǎo)致壓縮率降低非常多。這里調(diào)整JOIN順序?yàn)槿缦滤荆{(diào)整后數(shù)據(jù)減少到原來(lái)的三分之一。on t1.item_id=t2.item_id and t1.query = t2.query調(diào)整后數(shù)據(jù)減少到原來(lái)的三分之一。
另一種情況,JOIN或者
group by產(chǎn)生的Shuffle都沒有包含對(duì)壓縮來(lái)說(shuō)最理想的排序列,這時(shí)候也可以考慮使用Zorder的方式增加一個(gè)本地的排序,以較小的代價(jià)獲得較高的壓縮率。也可以單獨(dú)執(zhí)行distributed by sort by命令,手動(dòng)進(jìn)行重排布,但是這樣計(jì)算的代價(jià)會(huì)比較大。