分布式文件系統按塊(Block)存放數據,文件大小比塊大小(64MB)小的文件稱為小文件。分布式系統不可避免會產生小文件,比如SQL或其他分布式引擎的計算結果、Tunnel數據采集。合并小文件可以達到優化系統性能的目的。本文為您介紹如何在MaxCompute中合并小文件。
背景信息
小文件過多,會帶來以下問題:
MaxCompute處理單個大文件比處理多個小文件更有效率,小文件過多會影響整體的執行性能。
小文件過多會給Pangu文件系統帶來一定的壓力,影響存儲空間的有效利用。
因此從存儲和性能兩方面考慮,都需要將計算過程中產生的小文件合并。MaxCompute在小文件處理方面的功能日趨完善,主要體現在以下方面:
默認情況下,當作業完成之后,如果滿足一定的條件,系統會自動分配一個Fuxi Task進行小文件合并,即使用過程中經常看到的MergeTask。
默認情況下,一個Fuxi Instance不再只能處理一個小文件,而是最多可以處理100個小文件,同時可以通過
odps.sql.mapper.merge.limit.size參數來控制讀取文件總大小。MaxCompute后臺會定期掃描元數據庫,對小文件較多的表或分區進行小文件合并,這個合并過程對您透明。
但是通過元數據發現仍然存在大量的小文件未被合并掉,例如有的表一直在寫入,無法自動執行合并操作,需要您先將寫入作業停止,然后再手工進行小文件合并操作。
注意事項
使用合并小文件功能需要用到計算資源,如果您購買的實例是按量計費,會產生相關費用,具體計費規則與SQL按量計費保持一致,詳情請參見SQL作業按量付費。
合并小文件命令不支持Transactional表,如果需要對Transactional表進行小文件合并,請參見COMPACTION。
查看表的文件數
命令語法
您可以通過如下命令查看表的文件數:
desc extended <table_name> [partition (<pt_spec>)];參數說明
table_name:必填。待查看表的名稱。
pt_spec:可選。待查看分區表的指定分區。格式為
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。
結果示例
如下圖所示,
odl_bpm_wfc_task_log表的示例分區有3607個文件, 分區大小274MB (287869658Byte),平均文件大小約為0.07MB,需要進行小文件合并。
解決方案
通過元數據檢測,分區中含有100個以上的文件且平均文件大小小于64MB的都可以進行小文件合并,合并的方案有如下兩種。
即時合并
使用如下命令進行小文件即時合并。
ALTER TABLE <table_name> [partition (<pt_spec>)] MERGE SMALLFILES;對
odl_bpm_wfc_task_log表執行即時合并操作,完成后如下所示文件數減少為19個,存儲大小也減少到37MB,在合并小文件的同時,存儲效率也有了明顯提升。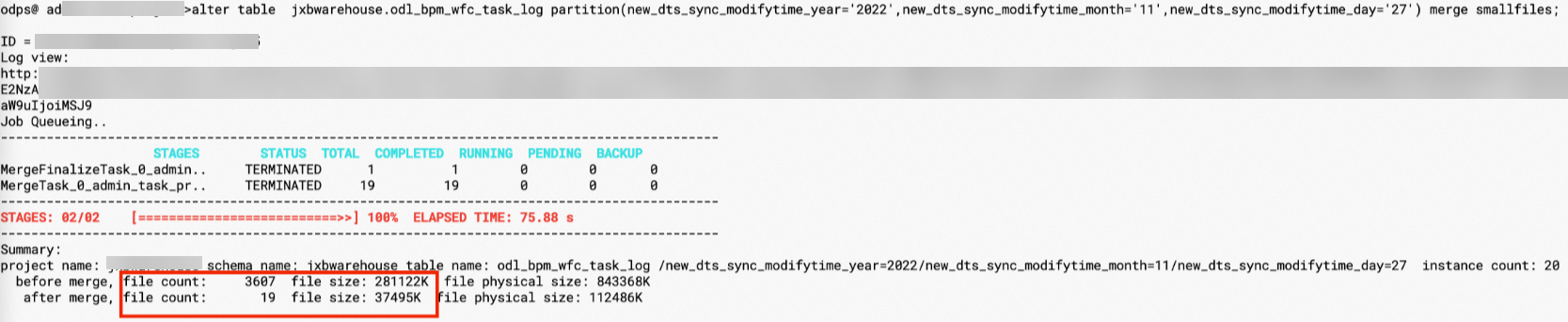
一般情況下,使用默認參數可以達到合并小文件的效果。但MaxCompute同時提供一些參數完成定制需求,常用的一些參數如下:
set odps.merge.cross.paths=true|false設置是否跨路徑合并,對于表下面有多個分區的情況,合并過程會將多個分區生成獨立的MergeAction進行合并,所以對于
odps.merge.cross.paths設置為true,并不會改變路徑個數,只是分別去合并每個路徑下的小文件。set odps.merge.smallfile.filesize.threshold = 64設置合并文件的小文件大小閾值,文件大小超過該閾值,則不進行合并,單位為MB。此參數可以不進行設置,不設置時,則使用全局變量
odps_g_merge_filesize_threshold,該參數值默認為32MB,設置時必須大于32MB。set odps.merge.maxmerged.filesize.threshold = 500設置合并輸出文件量的大小,輸出文件大于該閾值,則創建新的輸出文件,單位為MB。此參數可以不進行設置,不設置時,則使用全局變
odps_g_max_merged_filesize_threshold,該參數值默認為500MB,設置時必須大于500MB。
PyODPS腳本合并
通過PyODPS異步提交任務,合并前一天任務產出的小文件,腳本示例如下:
import os from odps import ODPS # 確保 ALIBABA_CLOUD_ACCESS_KEY_ID 環境變量設置為用戶 Access Key ID, # ALIBABA_CLOUD_ACCESS_KEY_SECRET 環境變量設置為用戶 Access Key Secret, # 不建議直接使用 Access Key ID / Access Key Secret 字符串 o = ODPS( os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID'), os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET'), project='your-default-project', endpoint='your-end-point', ) #注意需要替換$table_name為所需的表名 table_name = $table_name t = odps.get_table(table_name) #設置merge選項 hints = {'odps.merge.maxmerged.filesize.threshold': 256} #examples for multi partition insts = [] #iterate_partitions list列舉ds=$datetime下所有分區,分區格式也可能是其他格式 for partition in t.iterate_partitions(spec="ds=%s" % $datetime): instance=odps.run_merge_files(table_name, str(partition), hints=hints) #從這個logview的Waiting Queue點進去,才可以找到真正執行的logview print(instance.get_logview_address()) insts.append(instance) #等待分區結果 for inst in insts: inst.wait_for_completion()運行上述腳本需要提前安裝PyODPS,安裝方法請參見PyODPS。
使用案例
tbcdm.dwd_tb_log_pv_di是數據穩定性體系識別出來的需要合并小文件的物理表,通過元數據tbcdm.dws_rmd_merge_task_1d提供的信息,如下圖所示,可以看出此表相關分區的文件個數大部分都在1000以上,多的甚至達到7000以上,但平均文件大小有些還不到1MB。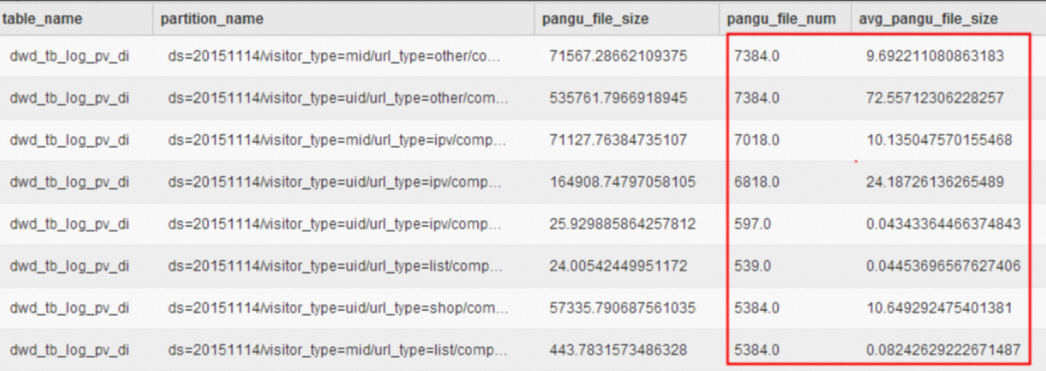 使用如下命令采用即時合并方案對其進行小文件合并。
使用如下命令采用即時合并方案對其進行小文件合并。
set odps.merge.cross.paths=true;
set odps.merge.smallfile.filesize.threshold=128;
set odps.merge.max.filenumber.per.instance = 2000;
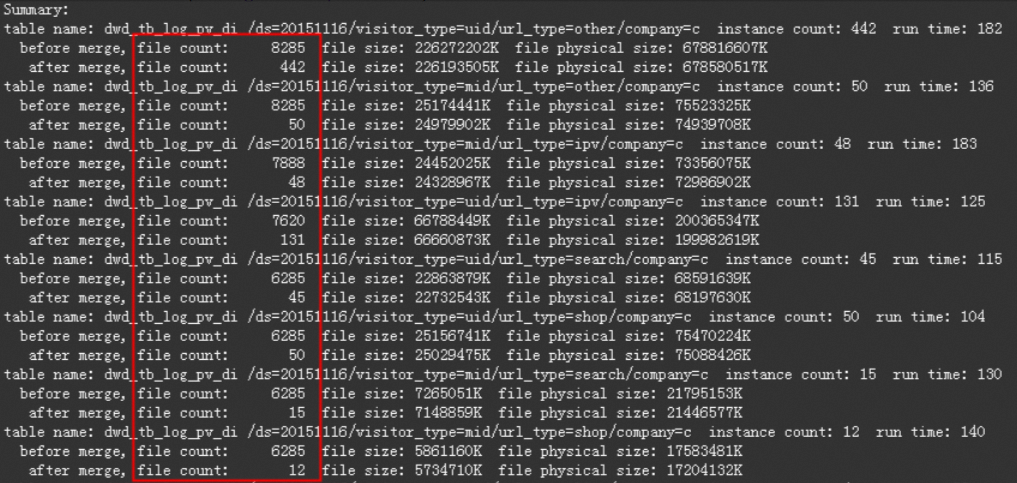
alter table tbcdm.dwd_tb_log_pv_di partition (ds='20151116') merge smallfiles;合并小文件后結果如下圖所示: