本文為您介紹使用MaxCompute過程中常見的數據傾斜場景以及對應的解決方案。
MapReduce
在了解數據傾斜之前首先需要了解什么是MapReduce,MapReduce是一種典型的分布式計算框架,它采用分治法的思想,將一些規模較大或者難以直接求解的問題分割成較小規模或容易處理的若干子問題,對這些子問題進行求解后將結果合并成最終結果。MapReduce相較于傳統并行編程框架,具有高容錯性、易使用性以及較好的擴展性等優點。在MapReduce中實現并行程序無需考慮分布式集群中的編程無關問題,如數據存儲、節點間的信息交流和傳輸機制等,大大簡化了其用戶的分布式編程方式。
MapReduce的具體工作流程示意圖如下: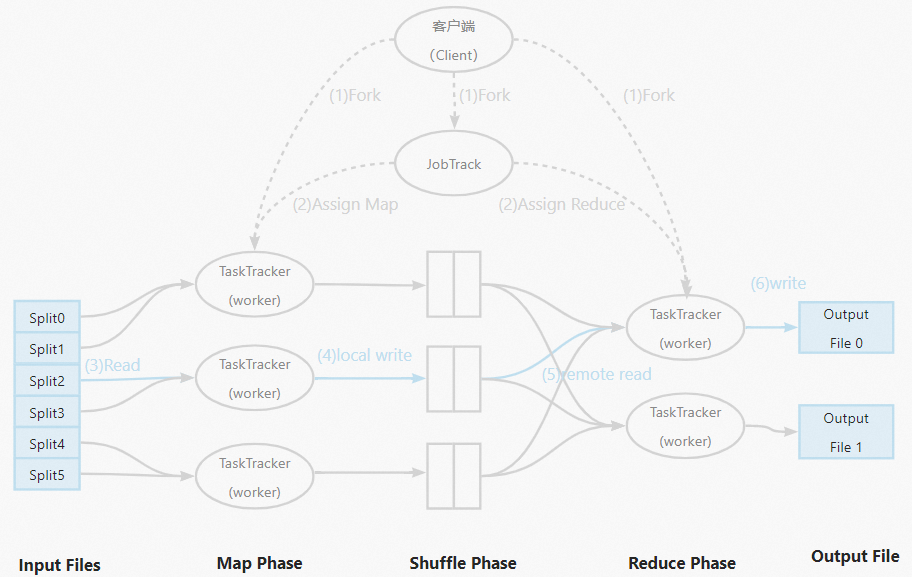
數據傾斜
數據傾斜多發生在Reducer端,Mapper按Input files切分,一般相對均勻,數據傾斜指表中數據分布不均衡的情況分配給不同的Worker。數據不均勻的時候,導致有的Worker很快就計算完成了,但是有的Worker卻需要運行很長時間。在實際生產中,大部分數據存在偏斜,這符合“二八”定律,例如一個論壇20%的活躍用戶貢獻了80%的帖子,或者一個網站80%的訪問量由20%的用戶提供。在數據量爆炸式增長的大數據時代,數據傾斜問題會嚴重影響分布式程序的執行效率。作業運行表現為作業的執行進度一直停留在99%,作業執行感覺被卡住了。
如何判斷發生數據傾斜
在MaxCompute中通過Logview可以很容易判斷數據傾斜,具體步驟如下:
在Fuxi Jobs中對運行時間Latency按照降序排列,選擇運行時間最長的Job Stage。
在Fuxi Instance of Fuxi Stage中對運行時間Latency按照降序排列,選擇運行時長遠大于平均時長的任務,一般選擇第一個進行鎖定,查看其對應的輸出日志StdOut。
根據StdOut中的反饋信息,查看對應的作業執行圖。
根據作業執行圖中的Key信息,可以進而定位到導致數據傾斜的SQL代碼片段。
使用示例如下。
通過任務的運行日志,找到對應的Logview日志,詳情請參見Logview入口。
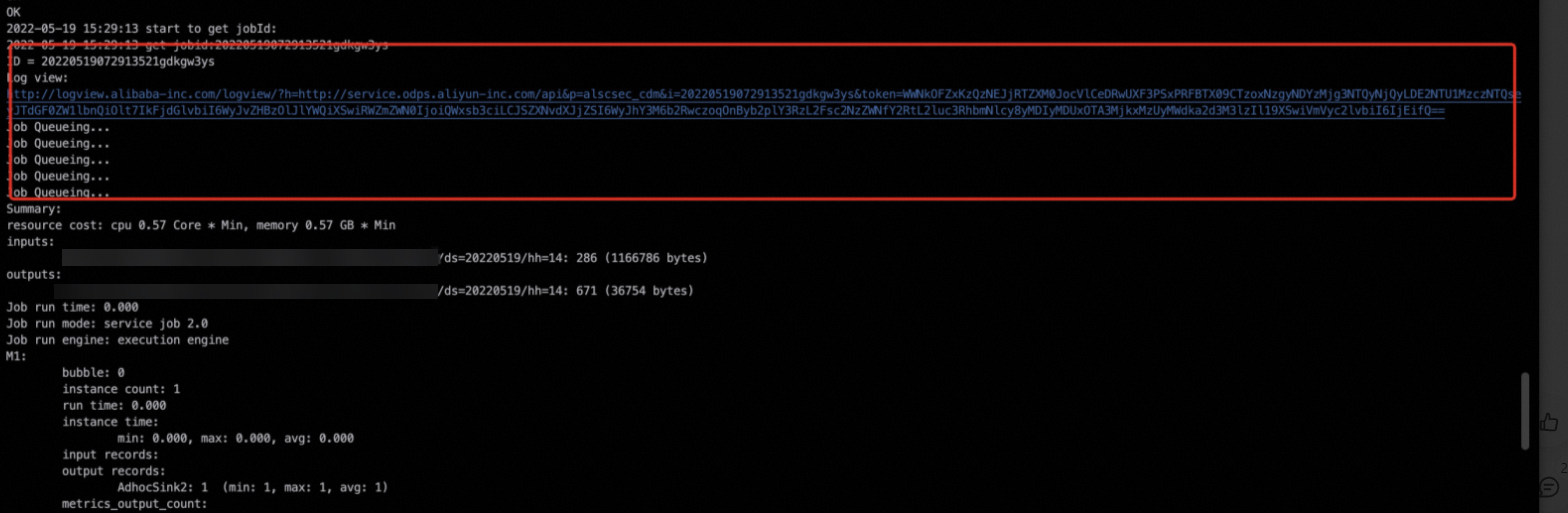
進入Logview界面,根據運行時間Latency按照降序排列,選擇時間最長的Fuxi Task,就可以快速鎖定問題。
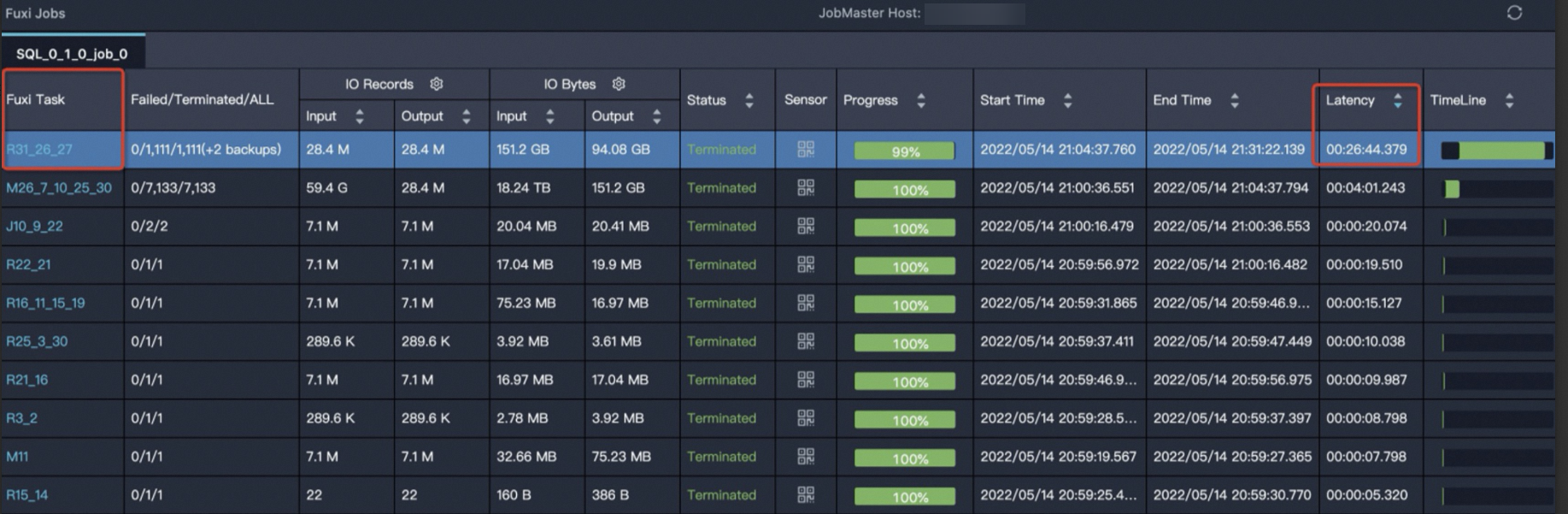
R31_26_27的運行時間最長,單擊R31_26_27任務,進入實例運行情況詳情頁,如下所示。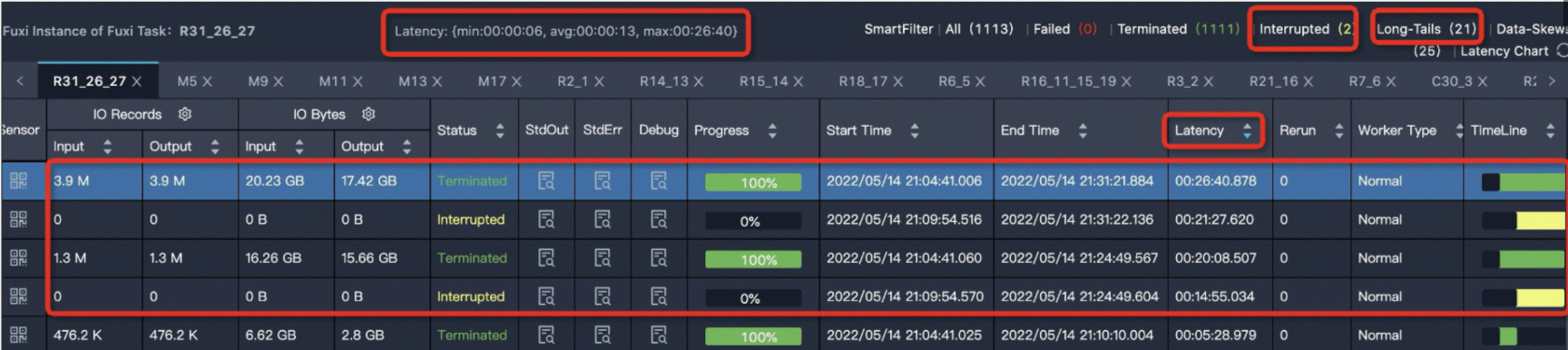
Latency: {min:00:00:06, avg:00:00:13, max:00:26:40}表示任務下的所有實例的最小運行時長是6s,平均運行時長是13s,最大運行時長是26分鐘40s。可以通過Latency(實例運行時長)進行降序排序,可以看到有四個運行時間比較長的實例。MaxCompute將Fuxi Instance耗費時長高于平均值2倍的實例判定為長尾,也就是說任務實例運行時長大于26s的都會判定為長尾(Long-Tails),此處有21個實例大于26s。有Long-Tails實例不一定代表任務傾斜,還需要看實例運行時間avg、max兩值的對比,對max值遠遠大于avg值的任務,也就是嚴重數據傾斜任務,對此任務需要進行治理。單擊StdOut列的
 圖標,查看輸出日志,示例如下。
圖標,查看輸出日志,示例如下。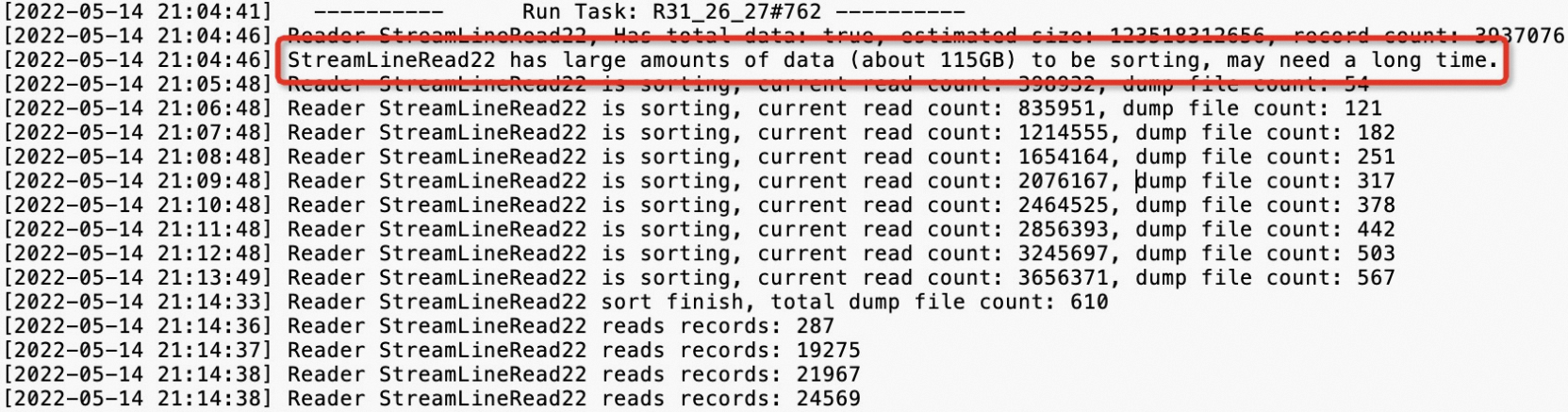
鎖定到問題后,在Job Details頁簽右鍵單擊
R31_26_27選擇expand all展開任務,詳情請參見使用Logview 2.0查看作業運行信息。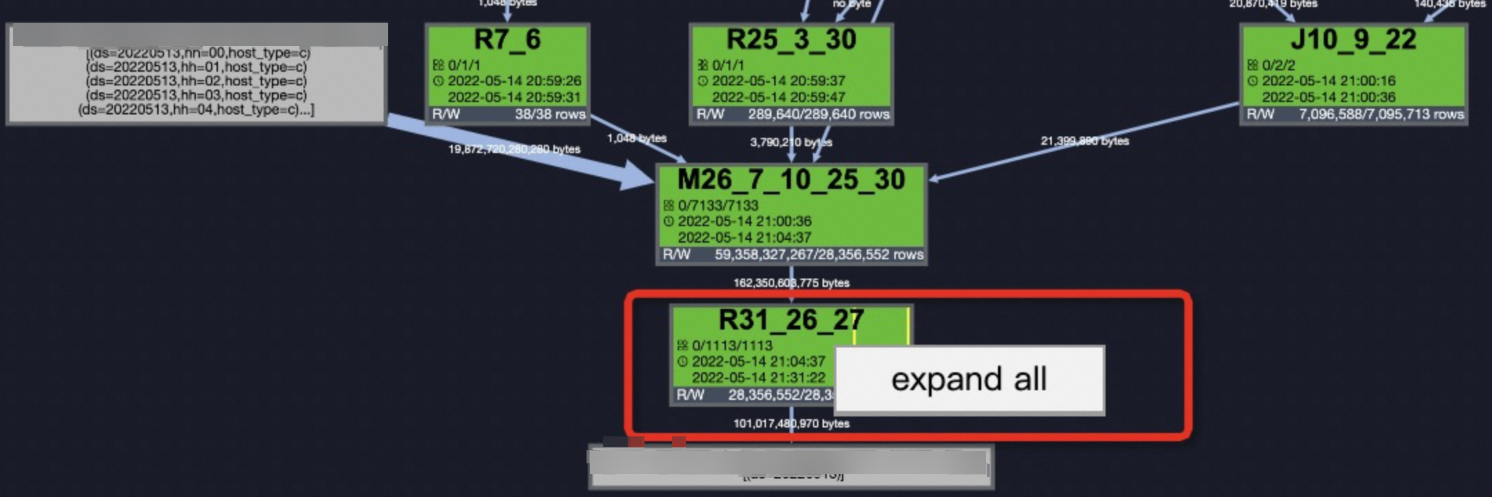 查看
查看StreamLineRead22的上一步StreamLineWriter21,即可定位到導致數據傾斜的Key:new_uri_path_structure、cookie_x5check_userid、cookie_userid。這樣也就定位到數據傾斜的SQL片段了。
數據傾斜排查及解決方法
根據使用經驗總結,引起數據傾斜的主要原因有如下幾類:
Join
GroupBy
Count(Distinct)
ROW_NUMBER(TopN)
動態分區
其中出現的頻率排序為JOIN > GroupBy > Count(Distinct) > ROW_NUMBER > 動態分區。
Join
針對Join端產生的數據傾斜,會存在多種不同的情況,例如大表和小表Join、大表和中表Join、Join熱值長尾。
大表Join小表。
數據傾斜示例。
如下示例中
t1是一張大表,t2、t3是小表。SELECT t1.ip ,t1.is_anon ,t1.user_id ,t1.user_agent ,t1.referer ,t2.ssl_ciphers ,t3.shop_province_name ,t3.shop_city_name FROM <viewtable> t1 LEFT OUTER JOIN <other_viewtable> t2 ON t1.header_eagleeye_traceid = t2.eagleeye_traceid LEFT OUTER JOIN ( SELECT shop_id ,city_name AS shop_city_name ,province_name AS shop_province_name FROM <tenanttable> WHERE ds = MAX_PT('<tenanttable>') AND is_valid = 1 ) t3 ON t1.shopid = t3.shop_id解決方案。
使用MAPJOIN HINT語法,如下所示。
SELECT /*+ mapjoin(t2,t3)*/ t1.ip ,t1.is_anon ,t1.user_id ,t1.user_agent ,t1.referer ,t2.ssl_ciphers ,t3.shop_province_name ,t3.shop_city_name FROM <viewtable> t1 LEFT OUTER JOIN (<other_viewtable>) t2 ON t1.header_eagleeye_traceid = t2.eagleeye_traceid LEFT OUTER JOIN ( SELECT shop_id ,city_name AS shop_city_name ,province_name AS shop_province_name FROM <tenanttable> WHERE ds = MAX_PT('<tenanttable>') AND is_valid = 1 ) t3 ON t1.shopid = t3.shop_id注意事項。
引用小表或子查詢時,需要引用別名。
MapJoin支持小表為子查詢。
在MapJoin中可以使用不等值連接或
or連接多個條件。您可以通過不寫on語句而通過mapjoin on 1 = 1的形式,實現笛卡爾乘積的計算。例如select /*+ mapjoin(a) */ a.id from shop a join table_name b on 1=1;,但此操作可能帶來數據量膨脹問題。MapJoin中多個小表用半角逗號(
,)分隔,例如/*+ mapjoin(a,b,c)*/。MapJoin在Map階段會將指定表的數據全部加載在內存中,因此指定的表僅能為小表,且表被加載到內存后占用的總內存不得超過512 MB。由于MaxCompute是壓縮存儲,因此小表在被加載到內存后,數據大小會急劇膨脹。此處的512 MB是指加載到內存后的空間大小。可以通過如下參數設置加大內存,最大為8192 MB。
SET odps.sql.mapjoin.memory.max=2048;
MapJoin中Join操作的限制。
left outer join的左表必須是大表。right outer join的右表必須是大表。不支持
full outer join。inner join的左表或右表均可以是大表。MapJoin最多支持指定128張小表,否則報語法錯誤。
大表Join中表。
數據傾斜示例。
如下示例中
t0為大表,t1為中表。SELECT request_datetime ,host ,URI ,eagleeye_traceid FROM <viewtable> t0 LEFT JOIN ( SELECT traceid, eleme_uid, isLogin_is FROM <servicetable> WHERE ds = '${today}' AND hh = '${hour}' ) t1 ON t0.eagleeye_traceid = t1.traceid WHERE ds = '${today}' AND hh = '${hour}'解決方案。
使用DISTRIBUTED MAPJOIN語法解決數據傾斜,如下所示。
SELECT /*+distmapjoin(t1)*/ request_datetime ,host ,URI ,eagleeye_traceid FROM <viewtable> t0 LEFT JOIN ( SELECT traceid, eleme_uid, isLogin_is FROM <servicetable> WHERE ds = '${today}' AND hh = '${hour}' ) t1 ON t0.eagleeye_traceid = t1.traceid WHERE ds = '${today}' AND hh = '${hour}'
Join熱值長尾。
數據傾斜示例
在下面這個表中,
eleme_uid中存在很多熱點數據,容易發生數據傾斜。SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> )t1 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> ) t2 ON t1.eleme_uid = t2.eleme_uid;解決方案。
可以通過如下四種方法來解決。
序號
方案
說明
方案一
手動切分熱值
將熱點值分析出來后,從主表中過濾出熱點值記錄,先進行MapJoin,再將剩余非熱點值記錄進行MergeJoin,最后合并兩部分的Join結果。
方案二
設置SkewJoin參數
set odps.sql.skewjoin=true;。方案三
SkewJoin Hint
使用Hint提示:
/*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/。SkewJoin Hint的方式相當于多了一次找傾斜Key的操作,會讓Query運行時間加長;如果用戶已經知道傾斜Key了,就可以通過設置SkewJoin參數的方式,能節省一些時間。方案四
倍數表取模相等Join
利用倍數表。
手動切分熱值。
將熱點值分析出來后,從主表中過濾出熱點值記錄,先進行MapJoin,再將剩余非熱點值記錄進行MergeJoin,最后合并兩部分的Join結果。具體可以參考如下代碼示例:
SELECT /*+ MAPJOIN (t2) */ eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> WHERE eleme_uid = <skewed_value> )t1 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> WHERE eleme_uid = <skewed_value> ) t2 ON t1.eleme_uid = t2.eleme_uid UNION ALL SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> WHERE eleme_uid != <skewed_value> )t3 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> WHERE eleme_uid != <skewed_value> ) t4 ON t3.eleme_uid = t4.eleme_uid設置SkewJoin參數。
該方案是一種比較常規的使用方案,MaxCompute提供數據傾斜設置參數
set odps.sql.skewjoin=true;開啟SkewJoin功能,但使用時如果只開啟SkewJoin,對于任務的運行并不會有任何影響,還必須設置odps.sql.skewinfo參數才會有效,odps.sql.skewinfo參數作用是設置Join優化具體信息,命令語法示例如下。SET odps.sql.skewjoin=true; SET odps.sql.skewinfo=skewed_src:(skewed_key)[("skewed_value")]; --skewed_src為流量表,skewed_value為熱點值使用示例如下:
--針對單個字段單個傾斜數值 SET odps.sql.skewinfo=src_skewjoin1:(key)[("0")]; --針對單個字段多個傾斜數值 SET odps.sql.skewinfo=src_skewjoin1:(key)[("0")("1")];SkewJoin Hint。
在
SELECT語句中使用如下Hint提示:/*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/才會執行MapJoin,其中table_name為傾斜表名,column_name為傾斜列名,value為傾斜Key值。使用示例如下。--方法1:Hint表名(注意Hint的是表的別名)。 SELECT /*+ skewjoin(a) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1; --方法2:Hint表名和認為可能產生傾斜的列,例如表a的c0和c1列存在數據傾斜。 SELECT /*+ skewjoin(a(c0, c1)) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1 AND a.c2 = b.c2; --方法3:Hint表名和列,并提供發生傾斜的key值。如果是STRING類型,需要加上引號。例如(a.c0=1 and a.c1="2")和(a.c0=3 and a.c1="4")的值都存在數據傾斜。 SELECT /*+ skewjoin(a(c0, c1)((1, "2"), (3, "4"))) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1 AND a.c2 = b.c2;說明SkewJoin Hint方法直接指定值的處理效率比手動切分熱值方法和設置SkewJoin參數方法(不指定值)高。
SkewJoin Hint支持的Join類型:
Inner Join可以對Join兩側表中的任意一側進行Hint。
Left Join、Semi Join和Anti Join只可以Hint左側表。
Right Join只可以Hint右側表。
Full Join不支持Skew Join Hint。
建議只對一定會出現數據傾斜的Join添加Hint,因為Hint會運行一個Aggregate,存在一定代價。
被Hint的Join的Left Side Join Key的類型需要與Right Side Join Key的類型一致,否則SkewJoin Hint不生效。例如上例中的
a.c0與b.c0的類型需要一致,a.c1與b.c1的類型需要一致。您可以通過在子查詢中將Join Key進行Cast從而保持一致。示例如下:CREATE TABLE T0(c0 int, c1 int, c2 int, c3 int); CREATE TABLE T1(c0 string, c1 int, c2 int); --方法1: SELECT /*+ skewjoin(a) */ * FROM T0 a JOIN T1 b ON cast(a.c0 AS string) = cast(b.c0 AS string) AND a.c1 = b.c1; --方法2: SELECT /*+ skewjoin(b) */ * FROM (SELECT cast(a.c0 AS string) AS c00 FROM T0 a) b JOIN T1 c ON b.c00 = c.c0;加SkewJoin Hint后,優化器會運行一個Aggregate獲取前20的熱值。
20是默認值,您可以通過set odps.optimizer.skew.join.topk.num = xx;進行設置。SkewJoin Hint只支持對Join其中一側進行Hint。
被Hint的Join一定要有
left key = right key,不支持笛卡爾積Join。MapJoin Hint的Join不能再添加SkewJoin Hint。
倍數表取模相等Join。
該方案和前三個方案的邏輯不同,不是分而治之的思路,而是利用一個倍數表,其值只有一列:int列,比如可以是從1到N(具體可根據傾斜程度確定),利用這個倍數表可以將用戶行為表放大N倍,然后Join時使用用戶ID和
number兩個關聯鍵。這樣原先只按照用戶ID分發導致的數據傾斜就會由于加入了number關聯條件而減少為原先的1/N。但是這樣做也會導致數據膨脹N倍。SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> )t1 LEFT JOIN( SELECT /*+mapjoin(<multipletable>)*/ eleme_uid, number ... FROM <customertable> JOIN <multipletable> ) t2 ON t1.eleme_uid = t2.eleme_uid AND mod(t1.<value_col>,10)+1 = t2.number;基于上面數據膨脹的情況,我們還可以將膨脹只局限作用于兩表中的熱點值記錄,其他非熱點值記錄不變。先找到熱點值記錄,然后分別處理流量表和用戶行為表,新增加一個
eleme_uid_join列,如果用戶ID是熱點值,concat一個隨機分配正整數(0到預定義的倍數之間,比如0~1000),如果不是則保持原用戶ID不變。在兩表Join時使用eleme_uid_join列。這樣既起到了放大熱點值倍數減小傾斜程度的作用,又減少了對非熱點值無效的膨脹。不過可想而知的是這樣的邏輯會將原先的業務邏輯SQL改得面目全非,因此不建議使用。
GroupBy
一個帶GroupBy的偽代碼示例如下。
SELECT shop_id
,sum(is_open) AS 營業天數
FROM table_xxx_di
WHERE dt BETWEEN '${bizdate_365}' AND '${bizdate}'
GROUP BY shop_id;當發生數據傾斜時,可以通過如下三種方案解決:
序號 | 方案 | 說明 |
方案一 | 設置Group By防傾斜的參數 |
|
方案二 | 添加隨機數 | 把引起長尾的Key進行拆分。 |
方案三 | 創建滾存表 | 降本提效。 |
方案一:設置Group By防傾斜的參數。
SET odps.sql.groupby.skewindata=true;方案二:添加隨機數。
相對于方案一,此解決方案對SQL進行改寫,添加隨機數,把引起長尾的Key進行拆分是解決Group By長尾的一種比較好的方法。
對于SQL:
Select Key,Count(*) As Cnt From TableName Group By Key;不考慮Combiner,M節點會Shuffle到R節點上,然后R節點再做Count操作,對應的執行計劃是M->R。假定已經找到了引起長尾的key,對長尾的Key再做一次工作再分配,就變成:
--假設長尾的Key已經找到是KEY001 SELECT a.Key ,SUM(a.Cnt) AS Cnt FROM(SELECT Key ,COUNT(*) AS Cnt FROM <TableName> GROUP BY Key ,CASE WHEN KEY = 'KEY001' THEN Hash(Random()) % 50 ELSE 0 END ) a GROUP BY a.Key;改完之后的執行計劃變成了
M->R->R,雖然執行步驟變長了,但是長尾的Key經過了2個步驟的處理,整體的時間消耗可能反而有所減少。資源消耗與耗時效果方面跟方案一基本持平,但實際場景中引發長尾的Key不止一個,再考慮尋找長尾Key和SQL改寫的投入成本,方案一會更低一些。創建滾存表。
核心降本提效,我們的核心訴求是取過去一年的商戶數據,對于線上任務而言,每次都要讀取
T-1至T-365的所有分區其實是對資源的很大浪費,創建滾存表可以減少分區的讀取但是又不影響過去一年的取數,示例如下。首次初始化365天的商戶營業數據(Group By匯總),標記數據更新日期,記為表
a;后續線上任務切換為T-2日表a關聯table_xxx_di表再Group By,這樣每天讀取的數據從365減少到了2個,主鍵shopid的重復性極大降低,對資源的消耗也會減少。--創建滾存表 CREATE TABLE IF NOT EXISTS m_xxx_365_df ( shop_id STRING COMMENT, last_update_ds COMMENT, 365d_open_days COMMENT ) PARTITIONED BY ( ds STRING COMMENT '日期分區' )LIFECYCLE 7; --假定365d是 2021.5.1-2022.5.1,先完成一次初始化 INSERT OVERWRITE TABLE m_xxx_365_df PARTITION(ds = '20220501') SELECT shop_id, max(ds) as last_update_ds, sum(is_open) AS 365d_open_days FROM table_xxx_di WHERE dt BETWEEN '20210501' AND '20220501' GROUP BY shop_id; --那么之后線上任務要執行的是 INSERT OVERWRITE TABLE m_xxx_365_df PARTITION(ds = '${bizdate}') SELECT aa.shop_id, aa.last_update_ds, 365d_open_days - COALESCE(is_open, 0) AS 365d_open_days --消除營業天數的無限滾存 FROM ( SELECT shop_id, max(last_update_ds) AS last_update_ds, sum(365d_open_days) AS 365d_open_days FROM ( SELECT shop_id, ds AS last_update_ds, sum(is_open) AS 365d_open_days FROM table_xxx_di WHERE ds = '${bizdate}' GROUP BY shop_id UNION ALL SELECT shop_id, last_update_ds, 365d_open_days FROM m_xxx_365_df WHERE dt = '${bizdate_2}' AND last_update_ds >= '${bizdate_365}' GROUP BY shop_id ) GROUP BY shop_id ) AS aa LEFT JOIN ( SELECT shop_id, is_open FROM table_xxx_di WHERE ds = '${bizdate_366}' ) AS bb ON aa.shop_id = bb.shop_id;
Count(Distinct)
假如一個表數據分布如下。
ds(分區) | cnt(記錄數) |
20220416 | 73025514 |
20220415 | 2292806 |
20220417 | 2319160 |
使用下面的語句就容易發生數據傾斜:
SELECT ds
,COUNT(DISTINCT shop_id) AS cnt
FROM demo_data0
GROUP BY ds;解決方案如下:
序號 | 方案 | 說明 |
方案一 | 參數設置調優 |
|
方案二 | 通用兩階段聚合 | 在partition字段值拼接隨機數。 |
方案三 | 類似兩階段聚合 | 先通過GroupBy兩分組字段 |
方案一:參數設置調優。
設置如下參數。
SET odps.sql.groupby.skewindata=true;方案二:通用兩階段聚合。
若
shop_id字段數據不均勻,則無法通過方案一優化,較通用的方式是在分區(partition)字段值中拼接隨機數。--方式1:拼接隨機數 CONCAT(ROUND(RAND(),1)*10,'_', ds) AS rand_ds SELECT SPLIT_PART(rand_ds, '_',2) ds ,COUNT(*) id_cnt FROM ( SELECT rand_ds ,shop_id FROM demo_data0 GROUP BY rand_ds,shop_id ) GROUP BY SPLIT_PART(rand_ds, '_',2); --方式2:新增隨機數字段 ROUND(RAND(),1)*10 AS randint10 SELECT ds ,COUNT(*) id_cnt FROM (SELECT ds ,randint10 ,shop_id FROM demo_data0 GROUP BY ds,randint10,shop_id ) GROUP BY ds;方案三:類似兩階段聚合。
如果GroupBy與Distinct的字段數據都均勻,則可以采用如下方式優化,先GroupBy兩分組字段(ds和shop_id)再使用
count(distinct)命令。SELECT ds ,COUNT(*) AS cnt FROM(SELECT ds ,shop_id FROM demo_data0 GROUP BY ds ,shop_id ) GROUP BY ds;
ROW_NUMBER(TopN)
Top10的示例如下。
SELECT main_id
,type
FROM (SELECT main_id
,type
,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn
FROM <data_demo2>
) A
WHERE A.rn <= 10;當發生數據傾斜時,可以通過以下幾種方式解決:
序號 | 方案 | 說明 |
方案一 | SQL寫法的兩階段聚合。 | 增加隨機列或拼接隨機數,將其作為分區(Partition)中一參數。 |
方案二 | UDAF寫法的兩階段聚合。 | 最小堆的隊列優先的通過UDAF的方式進行調優。 |
方案一:SQL寫法的兩階段聚合。
為使Map階段中Partition各分組數據盡可能均勻,增加隨機列,將其作為Partition中一參數。
SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn FROM (SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id,src_pt ORDER BY type DESC ) rn FROM (SELECT main_id ,type ,ceil(110 * rand()) % 11 AS src_pt FROM data_demo2 ) ) B WHERE B.rn <= 10 ) ) A WHERE A.rn <= 10; --2.隨機數直接自定義 SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn FROM (SELECT main_id ,type FROM(SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id,src_pt ORDER BY type DESC ) rn FROM (SELECT main_id ,type ,ceil(10 * rand()) AS src_pt FROM data_demo2 ) ) B WHERE B.rn <= 10 ) ) A WHERE A.rn <= 10;方案二:UDAF寫法的兩階段聚合。
SQL方式會有較多代碼,且可能不利于維護,此處將利用最小堆的隊列優先的通過UDAF的方式進行調優,即在
iterate階段僅取TopN,merge階段則均僅對N個元素融合,過程如下。iterate:將前K個元素進行push,K之后的元素通過不斷與最小頂比較交換堆中元素。merge:將兩堆merge后,原地返回前K個元素。terminate:數組形式返回堆。SQL中將數組拆為各行。
@annotate('* -> array<string>') class GetTopN(BaseUDAF): def new_buffer(self): return [[], None] def iterate(self, buffer, order_column_val, k): # heapq.heappush(buffer, order_column_val) # buffer = [heapq.nlargest(k, buffer), k] if not buffer[1]: buffer[1] = k if len(buffer[0]) < k: heapq.heappush(buffer[0], order_column_val) else: heapq.heappushpop(buffer[0], order_column_val) def merge(self, buffer, pbuffer): first_buffer, first_k = buffer second_buffer, second_k = pbuffer k = first_k or second_k merged_heap = first_buffer + second_buffer merged_heap.sort(reverse=True) merged_heap = merged_heap[0: k] if len(merged_heap) > k else merged_heap buffer[0] = merged_heap buffer[1] = k def terminate(self, buffer): return buffer[0] SET odps.sql.python.version=cp37; SELECT main_id,type_val FROM ( SELECT main_id ,get_topn(type, 10) AS type_array FROM data_demo2 GROUP BY main_id ) LATERAL VIEW EXPLODE(type_array)type_ar AS type_val;
動態分區
動態分區是指在往分區表里插入數據時,可以在分區中指定一個分區列名,但不給出具體值,而是在Select子句中的對應列來提供分區值的一種語法。 因此在SQL運行之前,是不知道會產生哪些分區,只有在SQL語句運行結束后,才能夠根據分區列產生的值確定會產生哪些分區,詳情請參見插入或覆寫動態分區數據(DYNAMIC PARTITION)。SQL示例如下。
CREATE TABLE total_revenues (revenue bigint) partitioned BY (region string);
INSERT overwrite TABLE total_revenues PARTITION(region)
SELECT total_price AS revenue,region
FROM sale_detail;很多場景會建立動態分區的表,也容易發生數據傾斜。當發生數據傾斜時,可以通過下面的解決方案來解決。
序號 | 方案 | 說明 |
方案一 | 參數配置優化 | 通過參數配置進行優化。 |
方案二 | 裁剪優化 | 通過查找到存在記錄數較多的分區裁剪后單獨插入的方式解決。 |
方案一:參數配置優化。
動態分區可以把符合不同條件的數據放到不同的分區,避免需要通過多次Insert OverWrite寫入到表中,特別是分區數比較多時,能夠很好的簡化代碼,但是動態分區也有可能會帶來小文件過多的困擾。
數據傾斜示例。
以如下最簡SQL為例。
INSERT INTO TABLE part_test PARTITION(ds) SELECT * FROM part_test;假設其有K個Map Instance,N個目標分區。
ds=1 cfile1 ds=2 ... X ds=3 cfilek ... ds=n最極端的情況下,可能產生
K*N個小文件,而過多的小文件會對文件系統造成巨大的管理壓力,因此MaxCompute對動態分區的處理是引入額外的一級Reduce Task, 把相同的目標分區交由同一個(或少量幾個) Reduce Instance來寫入, 避免小文件過多,并且這個Reduce肯定是最后一個Reduce Task操作。在MaxCompute中默認開啟此功能,也就是如下參數設置為True。SET odps.sql.reshuffle.dynamicpt=true;默認開啟該功能,解決了小文件過多的問題,不會因為單個Instance產生文件數過多而導致任務出錯,但也引入了新的問題:數據傾斜,并且額外引入一級Reduce操作也耗費計算資源,因此如何保持這兩者的平衡,需要認真權衡。
解決方案。
解決方案:對于開啟
set odps.sql.reshuffle.dynamicpt=true;這個參數引入額外一級的Reduce的初衷是為了解決小文件數過多的問題,那么如果目標分區數比較少、根本就不會存在小文件過多的困擾,這時候默認開啟該功能不僅浪費了計算資源,還降低了性能。相反,在此種情況下關閉此功能,即設置:set odps.sql.reshuffle.dynamicpt=false;反而能夠大幅提高性能,示例如下。INSERT overwrite TABLE ads_tb_cornucopia_pool_d PARTITION (ds, lv, tp) SELECT /*+ mapjoin(t2) */ '20150503' AS ds, t1.lv AS lv, t1.type AS tp FROM (SELECT ... FROM tbbi.ads_tb_cornucopia_user_d WHERE ds = '20150503' AND lv IN ('flat', '3rd') AND tp = 'T' AND pref_cat2_id > 0 ) t1 JOIN (SELECT ... FROM tbbi.ads_tb_cornucopia_auct_d WHERE ds = '20150503' AND tp = 'T' AND is_all = 'N' AND cat2_id > 0 ) t2 ON t1.pref_cat2_id = t2.cat2_id;對于上面一段代碼如果使用默認參數,整個任務的運行時長約為1小時30分鐘,其中最后一個Reduce的運行時長約為1小時20分鐘,占到總運行時長的
90%左右。由于引入額外的一個Reduce以后,使得每個Reduce Instance的數據分布特別不均勻,導致了數據長尾。
對于上述示例,我們通過統計歷史動態分區產生的個數發現,每天產生的動態分區個數都只有2個左右,因此完全可以設置
set odps.sql.reshuffle.dynamicpt=false;。該任務的運行只需9分鐘就可以運行完成,因此在這種情況下設置這個參數為false反而能大幅度提高性能,節約計算時間和計算資源,并且邊際收益特別高,僅僅這是設置一個參數。其實不僅僅對于運行時長占用資源比較的大任務,對于普通的執行時長比較端消耗資源比較小的小任務,只要是用到了動態分區,并且動態分區的個數不多,都可以將該
odps.sql.reshuffle.dynamicpt參數設置為false,并且都能夠節約資源,提高性能。滿足如下三個條件的節點,都是可以被優化的,不管節點任務的時間長短。
使用了動態分區
動態分區個數<=50
沒有set odps.sql.reshuffle.dynamicpt=false;
并且表根據最后一個Fuxi Instance的執行時長來判斷該節點是否需要設置該參數的迫切程度,通過
diag_level字段來標識別,規則如下:Last_Fuxi_Inst_Time大于30分鐘:Diag_Level=4('嚴重')。Last_Fuxi_Inst_Time在20到30分鐘之間:Diag_Level=3 ('高')。Last_Fuxi_Inst_Time在10到20分鐘之間:Diag_Level=2 ('中')。Last_Fuxi_Inst_Time小于10分鐘:Diag_Level=1('低')。
方案二:裁剪優化。
根據動態分區插數據時Map階段就存在的數據傾斜問題,可通過查找到存在記錄數較多的分區裁剪后單獨插入的方式解決。基于案例實際情況可修改Map階段的參數配置,如下所示:
SET odps.sql.mapper.split.size=128; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi;由結果知,全過程進行了全表掃描,進一步優化,可通過關閉系統引入的Reduce Job優化,過程如下:
SET odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi;根據動態分區插數據時Map階段就存在的數據傾斜問題,可通過查找到存在記錄數較多的分區裁剪后單獨插入的方式解決,具體步驟如下。
使用如下命令示例查詢記錄數較多的特定分區。
SELECT ds ,hh ,COUNT(*) AS cnt FROM dwd_alsc_ent_shop_info_hi GROUP BY ds ,hh ORDER BY cnt DESC;部分分區如下:
ds
hh
cnt
20200928
17
1052800
20191017
17
1041234
20210928
17
1034332
20190328
17
1000321
20210504
1
19
20191003
20
18
20200522
1
18
20220504
1
18
使用如下命令示例過濾上述分區插入后,再單獨插入大記錄數分區數據。
SET odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi WHERE CONCAT(ds,hh) NOT IN ('2020092817','2019101717','2021092817','2019032817'); set odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi WHERE CONCAT(ds,hh) IN ('2020092817','2019101717','2021092817','2019032817'); SELECT ds ,hh,COUNT(*) AS cnt FROM dwd_alsc_ent_shop_info_hi GROUP BY ds,hh ORDER BY cnt desc;