查看Worker傾斜關(guān)系
當Hologres響應速度變慢且您Hologres實例監(jiān)控指標中某個或者某幾個Worker的CPU使用率相比其他Worker的低時,此時可能出現(xiàn)了計算資源傾斜,Hologres建立了新的系統(tǒng)視圖hologres.hg_worker_info,通過此視圖可以查詢當前數(shù)據(jù)庫Worker、Table Group和Shard之間的關(guān)系,便于您判斷資源傾斜等關(guān)系,解決資源負載不均問題,提高資源利用率。本文為您介紹如何通過hologres.hg_worker_info查看傾斜關(guān)系。
背景信息
Hologres中Worker、Table Group和Shard的概念及關(guān)系請參見產(chǎn)品架構(gòu)和基本概念。Shard Count與Worker個數(shù)存在一定的分配關(guān)系。如果Worker個數(shù)與Shard數(shù)分配不均,那么很容易出現(xiàn)Worker資源傾斜,導致負載不均,資源得不到高效利用。同時管理控制臺監(jiān)控指標已經(jīng)透出Worker概念,為了便于判斷資源傾斜等關(guān)系,Hologres從 V1.3版本開始提供系統(tǒng)視圖hologres.hg_worker_info,方便您查詢當前數(shù)據(jù)庫的Worker、Table Group和Shard之間的關(guān)系。
使用限制
僅Hologres V1.3.23及以上版本支持使用系統(tǒng)視圖hologres.hg_worker_info,請在Hologres管理控制臺的實例詳情頁查看當前實例版本,若實例版本較低,請您使用自助升級或加入Hologres釘釘交流群反饋,詳情請參見如何獲取更多的在線支持?。
hologres.hg_worker_info展示的是實時Worker與Shard的關(guān)系,不支持展示歷史關(guān)系。
新建的Table Group需要一些時延才能獲取
worker_id的信息,一般時延在10-20s左右,如果新建Table Group后立即查找該系統(tǒng)視圖,可能會出現(xiàn)worker_id為空的情況。Table Group中沒有表,那么Worker就會無法分配資源,查詢結(jié)果中
worker_id會展示為id/0。Hologres從 V2.1版本開始,如果Worker沒有分配Shard,也會展示worker_id,結(jié)果為空,代表該Worker在該數(shù)據(jù)庫未分配Shard。僅支持查詢當前數(shù)據(jù)庫的Worker、Table Group和Shard信息,不支持跨數(shù)據(jù)庫查詢。
使用說明
系統(tǒng)視圖hologres.hg_worker_info主要包含字段信息如下。
字段 | 類型 | 說明 |
worker_id | TEXT | 當前數(shù)據(jù)庫所屬Worker的ID。 |
table_group_name | TEXT | 當前數(shù)據(jù)庫包含Table Group的名稱。 |
shard_id | BIGINT | Table Group下Shard的ID。 |
使用如下命令查詢hologres.hg_worker_info,查看每個Shard在Worker上的分布情況。
select * from hologres.hg_worker_info;查詢結(jié)果示例如下:
查詢結(jié)果中xx_tg_internal為實例的內(nèi)置Table Group,用于管理元數(shù)據(jù)等信息,無需特別關(guān)注。
worker_id | table_group_name | shard_id
------------+------------------+----------
bca90a00ef | tg1 | 0
ea405b4a9c | tg1 | 1
bca90a00ef | tg1 | 2
ea405b4a9c | tg1 | 3
bca90a00ef | db2_tg_default | 0
ea405b4a9c | db2_tg_default | 1
bca90a00ef | db2_tg_default | 2
ea405b4a9c | db2_tg_default | 3
ea405b4a9c | db2_tg_internal | 3
最佳實踐:解決計算資源傾斜(Worker負載不均)問題
在Hologres中數(shù)據(jù)分片(Shard)決定了數(shù)據(jù)的分布情況,一個Worker在計算時可能會訪問一個或者多個Shard的數(shù)據(jù)。同一個實例中一個Shard同一時間只能被一個Worker訪問,不能同時被多個Worker訪問。如果實例中每個Worker訪問的Shard總數(shù)不同,那么就有可能出現(xiàn)Worker資源負載不均的情況,主要表現(xiàn)為Worker節(jié)點CPU使用率監(jiān)控指標中某個或者某幾個Worker的CPU使用率較低,如下圖所示。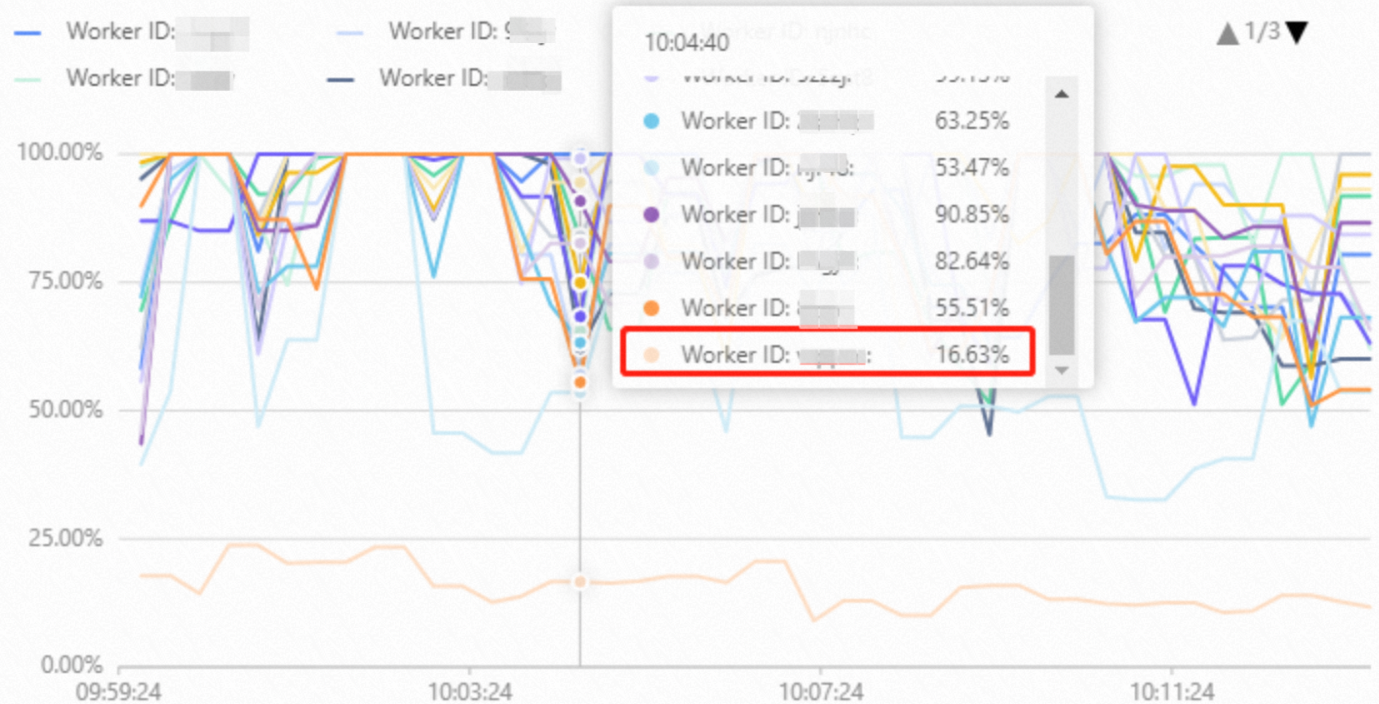 Worker負載不均會有多種原因?qū)е拢梢酝ㄟ^系統(tǒng)視圖hologres.hg_worker_info做進一步分析。一般情況下原因和排查手段如下:
Worker負載不均會有多種原因?qū)е拢梢酝ㄟ^系統(tǒng)視圖hologres.hg_worker_info做進一步分析。一般情況下原因和排查手段如下:
原因1:有Worker Failover后導致Shard分配不均。
如基本概念所述,當有Worker因為OOM等原因而出現(xiàn)Failover時,為了能快速恢復Worker的查詢,系統(tǒng)會將該Worker對應的Shard,快速遷移至其他Worker。當被終止的Worker恢復,系統(tǒng)會再分配部分Shard給它,從而出現(xiàn)Worker間Shard分配不均的現(xiàn)象。通過hologres.hg_worker_info可以查看當前數(shù)據(jù)庫下每個Worker上分配的Shard數(shù),從而判斷計算資源是否有分配傾斜的情況,但需要注意的是:hologres.hg_worker_info查詢的是當前數(shù)據(jù)庫下Shard與Worker的關(guān)系,而計算Worker是實例共享的,因此需要查看傾斜關(guān)系時,需要查詢每個數(shù)據(jù)庫中Shard與Worker的關(guān)系,得出實例維度每個Worker對應的總Shard數(shù),以此綜合判斷傾斜情況。
命令示例:
select worker_id, count(1) as shard_count from hologres.hg_worker_info group by worker_id;查詢結(jié)果示例:
--假設(shè)實例只有1個數(shù)據(jù)庫,示例查詢結(jié)果如下 worker_id | shard_count ------------+------------- bca90a | 4 ea405b | 4 tkn4vc | 4 bqw5cq | 3 mbbrf6 | 3 hsx66f | 1 (6 rows)結(jié)果解讀:
實例只有6個Worker,但是6個Worker上分配的Shard數(shù)并不相同,查看管控臺監(jiān)控指標,發(fā)現(xiàn)較少Shard數(shù)的Worker對應的CPU使用率明顯低于其他Worker,說明實例的計算資源分配不均。
解決方法:
重啟實例,讓計算Worker重新分配Shard,保證各個Shard在Worker上能夠盡量均勻的分配。如果不重啟實例,當另外的Worker出現(xiàn)Failover時,較空閑的Worker就會分配到更多的資源。
原因2:數(shù)據(jù)傾斜導致計算資源傾斜。
如果業(yè)務數(shù)據(jù)存在嚴重的傾斜,就會導致數(shù)據(jù)會分布在某些Shard,在查詢時Worker負載就會訪問固定的Shard,導致出現(xiàn)CPU負載不均的情況。可以通過hologres.hg_worker_info與hologres.hg_table_properties兩個系統(tǒng)視圖結(jié)合查詢,根據(jù)表傾斜的數(shù)據(jù)對應的
worker id,從而判斷是否是因為數(shù)據(jù)傾斜導致的計算資源傾斜,步驟如下。查看數(shù)據(jù)傾斜情況。
通過以下SQL查看表是否存在數(shù)據(jù)傾斜的情況,如果某個Shard的數(shù)據(jù)與其他Shard的數(shù)據(jù)相差較大,則說明這個表的數(shù)據(jù)存在傾斜。
select hg_shard_id,count(1) from <table_name> group by hg_shard_id order by 2; --示例結(jié)果:shard 39的count值較大,存在傾斜 hg_shard_id | count -------------+-------- 53 | 29130 65 | 28628 66 | 26970 70 | 28767 77 | 28753 24 | 30310 15 | 29550 39 | 164983通過數(shù)據(jù)傾斜的
hg_shard_id查詢對應的worker_id。上一步驟得出哪個Shard數(shù)據(jù)存在傾斜,可以通過
hg_shard_id結(jié)合hologres.hg_worker_info與hologres.hg_table_properties兩個系統(tǒng)視圖,查詢出傾斜的Shard對應的worker_id,命令示例如下 。SELECT distinct b.table_name, a.worker_id, a.table_group_name,a.shard_id from hologres.hg_worker_info a join (SELECT property_value, table_name FROM hologres.hg_table_properties WHERE property_key = 'table_group') b on a.table_group_name = b.property_value and b.table_name = '<tablename>' and shard_id=<shard_id>; --查詢結(jié)果示例 table_name | worker_id | table_group_name | shard_id ------------+------------+-------------------+------------------ table03 | bca90a00ef | db2_tg_default | 39通過結(jié)果中的
worker_id,結(jié)合Worker節(jié)點CPU使用率監(jiān)控指標,如果該Worker的負載情況明顯高于其他Worker,則說明是數(shù)據(jù)傾斜導致的資源傾斜。
解決方法:
設(shè)置合適的Distribution Key,讓數(shù)據(jù)盡可能的在Shard間分布均勻,詳情請參見優(yōu)化內(nèi)部表的性能。
如果是業(yè)務的數(shù)據(jù)傾斜比較嚴重,例如直播訂單表的商品交易總額(GMV),可能存在不同主播數(shù)據(jù)有明顯的差異,可以考慮拆分成多個表來實現(xiàn)。
原因3:Shard數(shù)設(shè)置不合理
建議Shard數(shù)盡量與Worker的個數(shù)存在一定的倍數(shù)關(guān)系,這樣才能使得Worker間的負載盡量均衡,如果Shard數(shù)設(shè)置不夠合理,會導致Worker負載可能出現(xiàn)不均的情況。可以通過hologres.hg_worker_info查看當前數(shù)據(jù)庫下TableGroup設(shè)置的Shard數(shù)是否合理。
命令示例
select table_group_name, worker_id, count(1) as shard_count from hologres.hg_worker_info group by table_group_name, worker_id order by table_group_name desc;示例結(jié)果
table_group_name | worker_id | shard_count ------------------+------------+------------- tg2 | ea405b4a9c | 1 tg2 | bca90a00ef | 2 tg1 | ea405b4a9c | 5 tg1 | bca90a00ef | 6 db2_tg_default | bca90a00ef | 4 db2_tg_default | ea405b4a9c | 4 db2_tg_internal | bca90a00ef | 1 (7 rows)結(jié)果解讀(假設(shè)實例只有2個Worker)
tg2設(shè)置了3個Shard,其中一個Worker會少分配一個Shard,如果性能不滿足預期,建議優(yōu)化Shard數(shù)或者擴容。tg1設(shè)置了11個Shard,其中一個Worker會少分配一個Shard,如果性能不滿足預期,建議優(yōu)化Shard數(shù)或者擴容。默認Table Group
db2_tg_default設(shè)置了8個Shard,Worker分配的Shard較均勻。
解決方法
如果是Shard數(shù)設(shè)置不合理導致Worker資源傾斜,可以根據(jù)業(yè)務情況綜合評估Shard數(shù)的設(shè)置,建議設(shè)置成Worker個數(shù)的倍數(shù)。